 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explicit topological priors for deep-learning based image segmentation using persistent homology
Jan 29, 2019
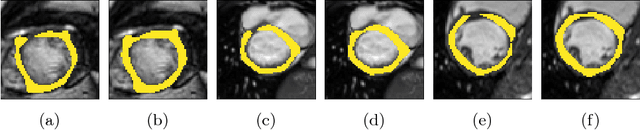
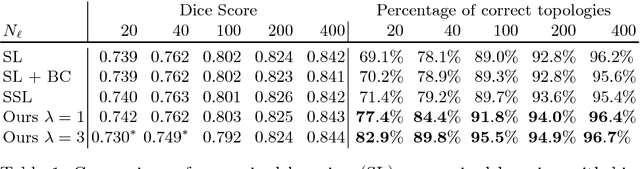
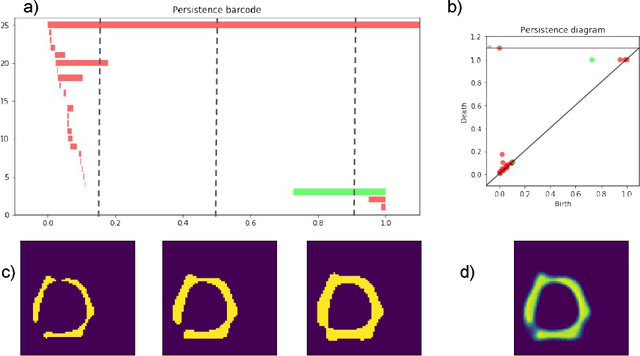
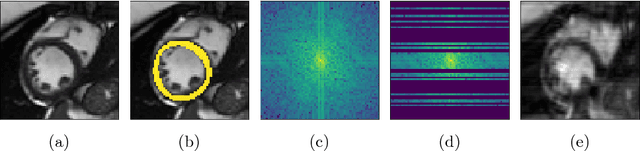
We present a novel method to explicitly incorporate topological prior knowledge into deep learning based segmentation, which is, to our knowledge, the first work to do so. Our method uses the concept of persistent homology, a tool from topological data analysis, to capture high-level topological characteristics of segmentation results in a way which is differentiable with respect to the pixelwise probability of being assigned to a given class. The topological prior knowledge consists of the sequence of desired Betti numbers of the segmentation. As a proof-of-concept we demonstrate our approach by applying it to the problem of left-ventricle segmentation of cardiac MR images of 500 subjects from the UK Biobank dataset, where we show that it improves segmentation performance in terms of topological correctness without sacrificing pixelwise accuracy.
Towards Robust Learning-Based Pose Estimation of Noncooperative Spacecraft
Sep 01, 2019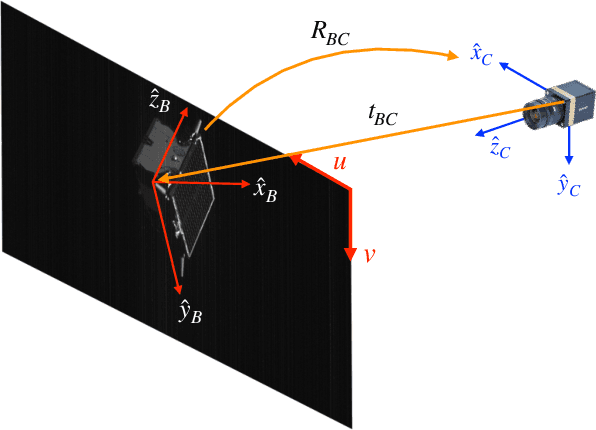

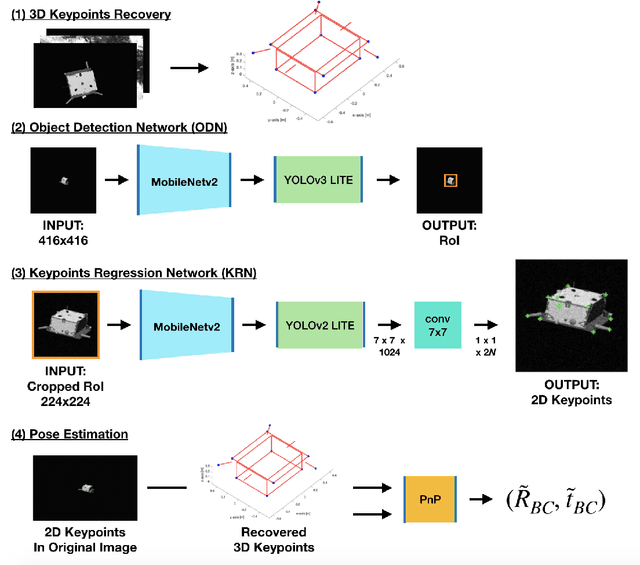

This work presents a novel Convolutional Neural Network (CNN) architecture and a training procedure to enable robust and accurate pose estimation of a noncooperative spacecraft. First, a new CNN architecture is introduced that has scored a fourth place in the recent Pose Estimation Challenge hosted by Stanford's Space Rendezvous Laboratory (SLAB) and the Advanced Concepts Team (ACT) of the European Space Agency (ESA). The proposed architecture first detects the object by regressing a 2D bounding box, then a separate network regresses the 2D locations of the known surface keypoints from an image of the target cropped around the detected Region-of-Interest (RoI). In a single-image pose estimation problem, the extracted 2D keypoints can be used in conjunction with corresponding 3D model coordinates to compute relative pose via the Perspective-n-Point (PnP) problem. These keypoint locations have known correspondences to those in the 3D model, since the CNN is trained to predict the corners in a pre-defined order, allowing for bypassing the computationally expensive feature matching processes. This work also introduces and explores the texture randomization to train a CNN for spaceborne applications. Specifically, Neural Style Transfer (NST) is applied to randomize the texture of the spacecraft in synthetically rendered images. It is shown that using the texture-randomized images of spacecraft for training improves the network's performance on spaceborne images without exposure to them during training. It is also shown that when using the texture-randomized spacecraft images during training, regressing 3D bounding box corners leads to better performance on spaceborne images than regressing surface keypoints, as NST inevitably distorts the spacecraft's geometric features to which the surface keypoints have closer relation.
Recognizing Images with at most one Spike per Neuron
Jan 21, 2020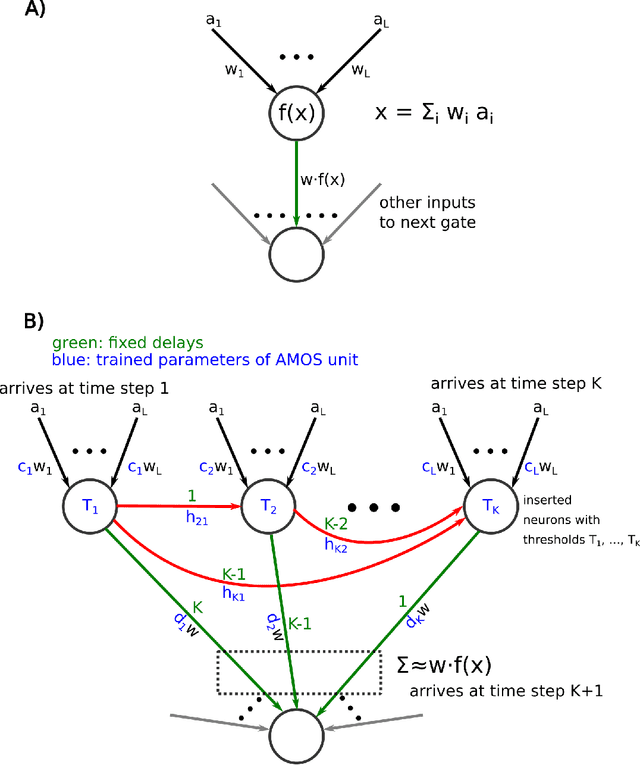

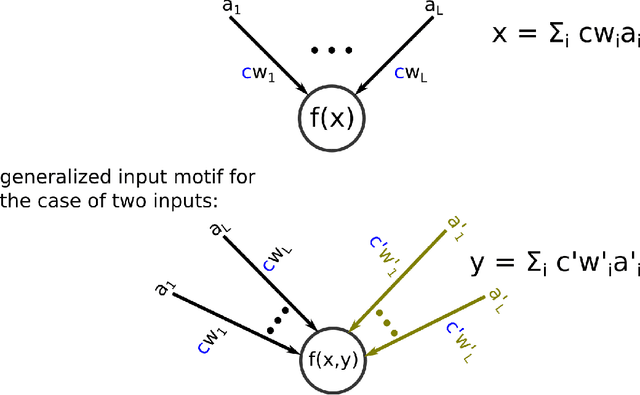

In order to port the performance of trained artificial neural networks (ANNs) to spiking neural networks (SNNs), which can be implemented in neuromorphic hardware with a drastically reduced energy consumption, an efficient ANN to SNN conversion is needed. Previous conversion schemes focused on the representation of the analog output of a rectified linear (ReLU) gate in the ANN by the firing rate of a spiking neuron. But this is not possible for other commonly used ANN gates, and it reduces the throughput even for ReLU gates. We introduce a new conversion method where a gate in the ANN, which can basically be of any type, is emulated by a small circuit of spiking neurons, with At Most One Spike (AMOS) per neuron. We show that this AMOS conversion improves the accuracy of SNNs for ImageNet from 74.60% to 80.97%, thereby bringing it within reach of the best available ANN accuracy (85.0%). The Top5 accuracy of SNNs is raised to 95.82%, getting even closer to the best Top5 performance of 97.2% for ANNs. In addition, AMOS conversion improves latency and throughput of spike-based image classification by several orders of magnitude. Hence these results suggest that SNNs provide a viable direction for developing highly energy efficient hardware for AI that combines high performance with versatility of applications.
UWGAN: Underwater GAN for Real-world Underwater Color Restoration and Dehazing
Dec 21, 2019In real-world underwater environment, exploration of seabed resources, underwater archaeology, and underwater fishing rely on a variety of sensors, vision sensor is the most important one due to its high information content, non-intrusive, and passive nature. However, wavelength-dependent light attenuation and back-scattering result in color distortion and haze effect, which degrade the visibility of images. To address this problem, firstly, we proposed an unsupervised generative adversarial network (GAN) for generating realistic underwater images (color distortion and haze effect) from in-air image and depth map pairs based on improved underwater imaging model. Secondly, U-Net, which is trained efficiently using synthetic underwater dataset, is adopted for color restoration and dehazing. Our model directly reconstructs underwater clear images using end-to-end autoencoder networks, while maintaining scene content structural similarity. The results obtained by our method were compared with existing methods qualitatively and quantitatively. Experimental results obtained by the proposed model demonstrate well performance on open real-world underwater datasets, and the processing speed can reach up to 125FPS running on one NVIDIA 1060 GPU. Source code, sample datasets are made publicly available at https://github.com/infrontofme/UWGAN_UIE.
RayTracer.jl: A Differentiable Renderer that supports Parameter Optimization for Scene Reconstruction
Aug 03, 2019
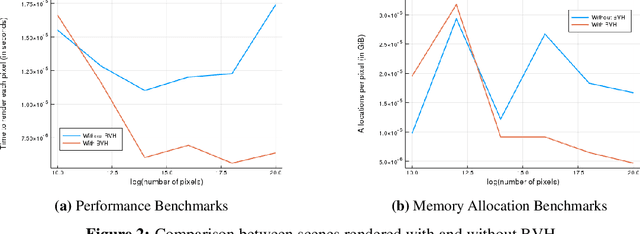
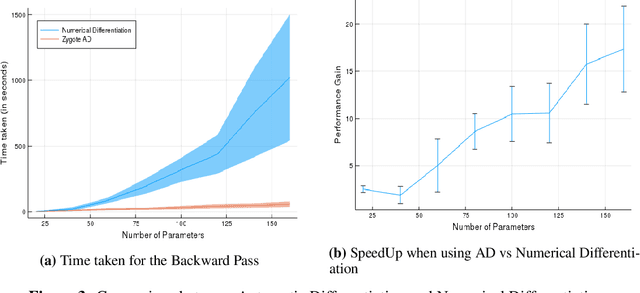
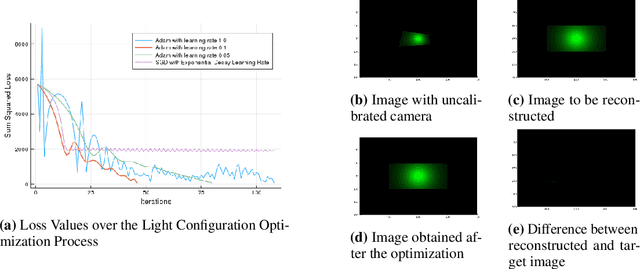
In this paper, we present RayTracer.jl, a renderer in Julia that is fully differentiable using source-to-source Automatic Differentiation (AD). This means that RayTracer not only renders 2D images from 3D scene parameters, but it can be used to optimize for model parameters that generate a target image in a Differentiable Programming (DP) pipeline. We interface our renderer with the deep learning library Flux for use in combination with neural networks. We demonstrate the use of this differentiable renderer in rendering tasks and in solving inverse graphics problems.
Chained Representation Cycling: Learning to Estimate 3D Human Pose and Shape by Cycling Between Representations
Jan 06, 2020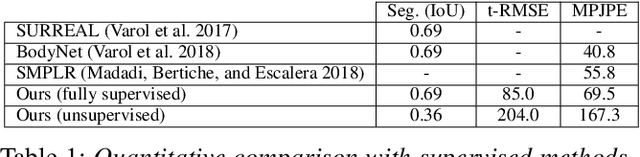
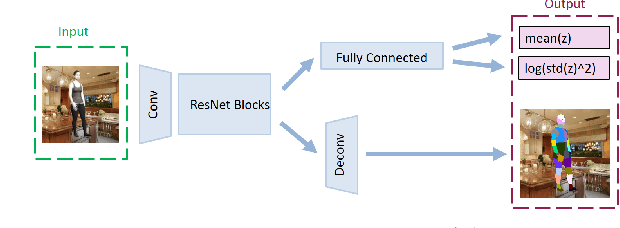
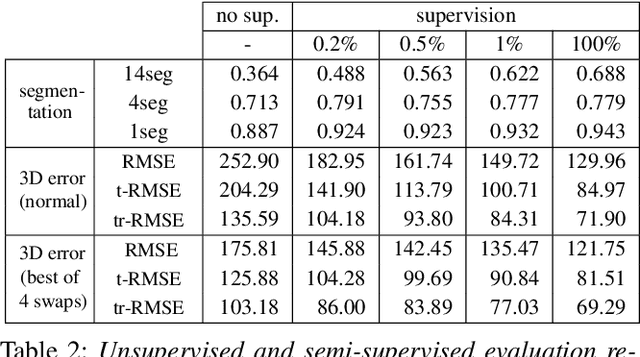
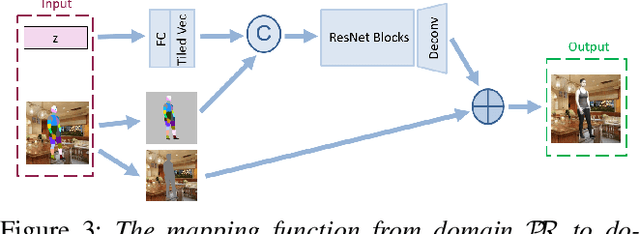
The goal of many computer vision systems is to transform image pixels into 3D representations. Recent popular models use neural networks to regress directly from pixels to 3D object parameters. Such an approach works well when supervision is available, but in problems like human pose and shape estimation, it is difficult to obtain natural images with 3D ground truth. To go one step further, we propose a new architecture that facilitates unsupervised, or lightly supervised, learning. The idea is to break the problem into a series of transformations between increasingly abstract representations. Each step involves a cycle designed to be learnable without annotated training data, and the chain of cycles delivers the final solution. Specifically, we use 2D body part segments as an intermediate representation that contains enough information to be lifted to 3D, and at the same time is simple enough to be learned in an unsupervised way. We demonstrate the method by learning 3D human pose and shape from un-paired and un-annotated images. We also explore varying amounts of paired data and show that cycling greatly alleviates the need for paired data. While we present results for modeling humans, our formulation is general and can be applied to other vision problems.
BTEL: A Binary Tree Encoding Approach for Visual Localization
Jun 27, 2019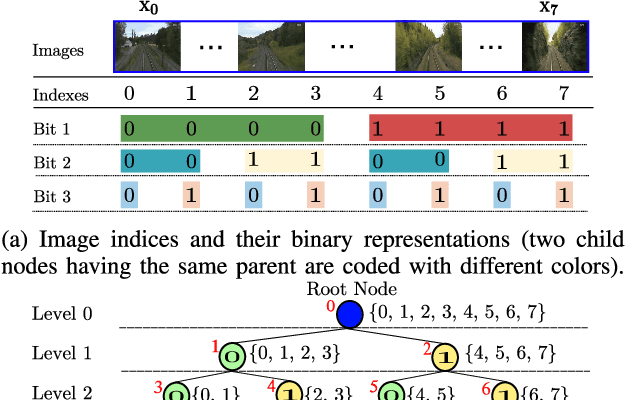
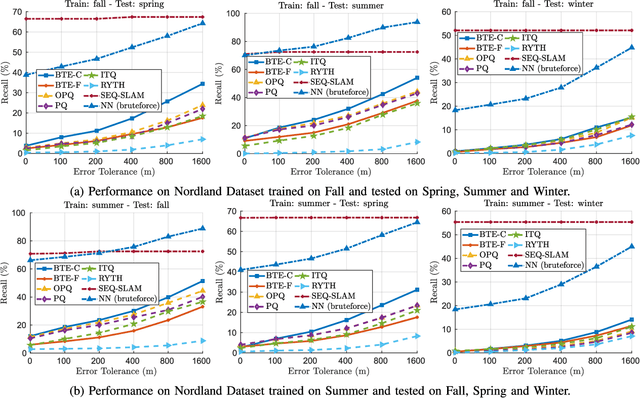
Visual localization algorithms have achieved significant improvements in performance thanks to recent advances in camera technology and vision-based techniques. However, there remains one critical caveat: all current approaches that are based on image retrieval currently scale at best linearly with the size of the environment with respect to both storage, and consequentially in most approaches, query time. This limitation severely curtails the capability of autonomous systems in a wide range of compute, power, storage, size, weight or cost constrained applications such as drones. In this work, we present a novel binary tree encoding approach for visual localization which can serve as an alternative for existing quantization and indexing techniques. The proposed tree structure allows us to derive a compressed training scheme that achieves sub-linearity in both required storage and inference time. The encoding memory can be easily configured to satisfy different storage constraints. Moreover, our approach is amenable to an optional sequence filtering mechanism to further improve the localization results, while maintaining the same amount of storage. Our system is entirely agnostic to the front-end descriptors, allowing it to be used on top of recent state-of-the-art image representations. Experimental results show that the proposed method significantly outperforms state-of-the-art approaches under limited storage constraints.
Supporting DNN Safety Analysis and Retraining through Heatmap-based Unsupervised Learning
Feb 03, 2020
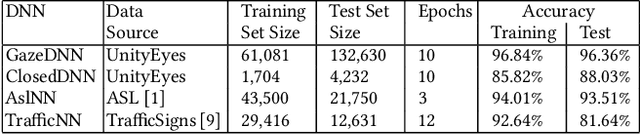
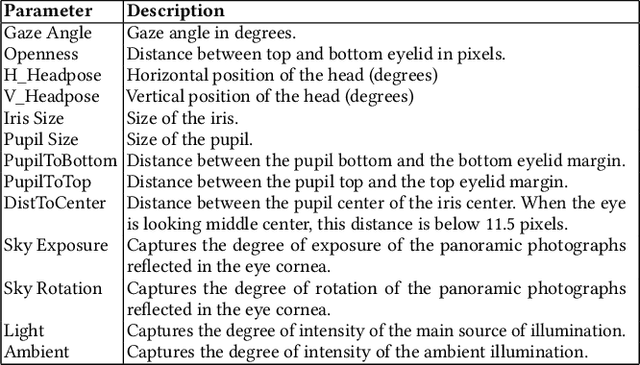
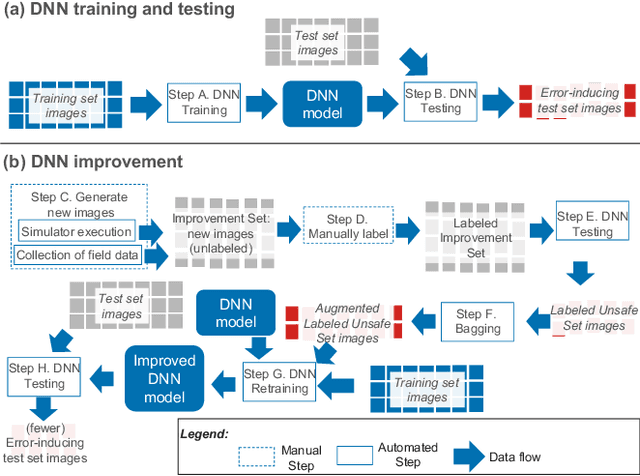
Deep neural networks (DNNs) are increasingly critical in modern safety-critical systems, for example in their perception layer to analyze images. Unfortunately, there is a lack of methods to ensure the functional safety of DNN-based components. The machine learning literature suggests one should trust DNNs demonstrating high accuracy on test sets. In case of low accuracy, DNNs should be retrained using additional inputs similar to the error-inducing ones. We observe two major challenges with existing practices for safety-critical systems: (1) scenarios that are underrepresented in the test set may represent serious risks, which may lead to safety violations, and may not be noticed; (2) debugging DNNs is poorly supported when error causes are difficult to visually detect. To address these problems, we propose HUDD, an approach that automatically supports the identification of root causes for DNN errors. We automatically group error-inducing images whose results are due to common subsets of selected DNN neurons. HUDD identifies root causes by applying a clustering algorithm to matrices (i.e., heatmaps) capturing the relevance of every DNN neuron on the DNN outcome. Also, HUDD retrains DNNs with images that are automatically selected based on their relatedness to the identified image clusters. We have evaluated HUDD with DNNs from the automotive domain. The approach was able to automatically identify all the distinct root causes of DNN errors, thus supporting safety analysis. Also, our retraining approach has shown to be more effective at improving DNN accuracy than existing approaches.
A deep learning based tool for automatic brain extraction from functional magnetic resonance images in rodents
Dec 03, 2019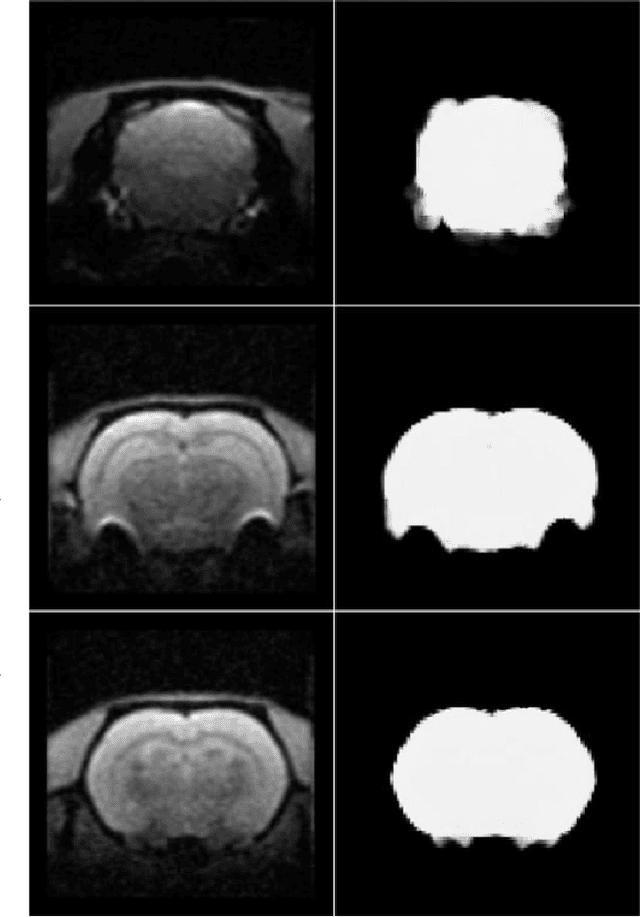
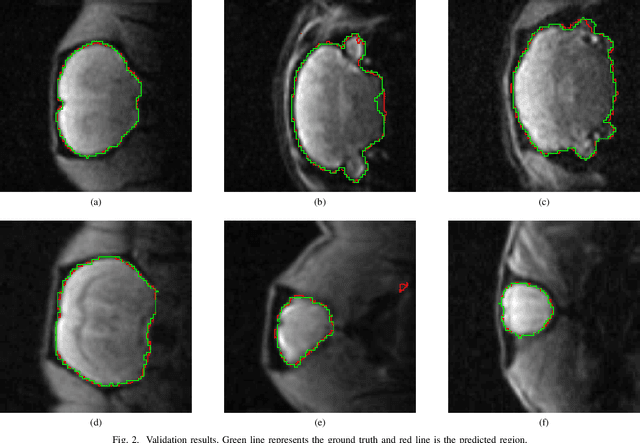
Removing skull artifacts from functional magnetic images (fMRI) is a well understood and frequently encountered problem. Because the fMRI field has grown mostly due to human studies, many new tools were developed to handle human data. Nonetheless, these tools are not equally useful to handle the data derived from animal studies, especially from rodents. This represents a major problem to the field because rodent studies generate larger datasets from larger populations, which implies that preprocessing these images manually to remove the skull becomes a bottleneck in the data analysis pipeline. In this study, we address this problem by implementing a neural network based method that uses a U-Net architecture to segment the brain area into a mask and removing the skull and other tissues from the image. We demonstrate several strategies to speed up the process of generating the training dataset using watershedding and several strategies for data augmentation that allowed to train faster the U-Net to perform the segmentation. Finally, we deployed the trained network freely available.
FDSNet: Finger dorsal image spoof detection network using light field camera
Dec 18, 2018
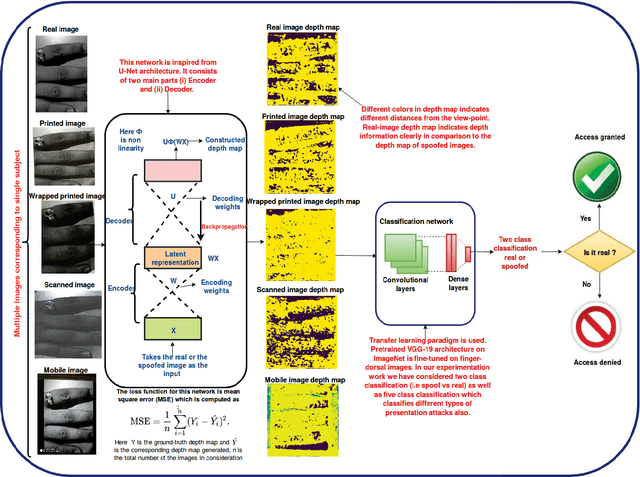
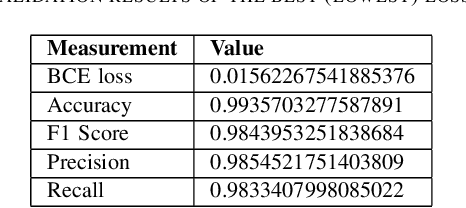
At present spoofing attacks via which biometric system is potentially vulnerable against a fake biometric characteristic, introduces a great challenge to recognition performance. Despite the availability of a broad range of presentation attack detection (PAD) or liveness detection algorithms, fingerprint sensors are vulnerable to spoofing via fake fingers. In such situations, finger dorsal images can be thought of as an alternative which can be captured without much user cooperation and are more appropriate for outdoor security applications. In this paper, we present a first feasibility study of spoofing attack scenarios on finger dorsal authentication system, which include four types of presentation attacks such as printed paper, wrapped printed paper, scan and mobile. This study also presents a CNN based spoofing attack detection method which employ state-of-the-art deep learning techniques along with transfer learning mechanism. We have collected 196 finger dorsal real images from 33 subjects, captured with a Lytro camera and also created a set of 784 finger dorsal spoofing images. Extensive experimental results have been performed that demonstrates the superiority of the proposed approach for various spoofing attacks.