 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A General Framework for Saliency Detection Methods
Dec 27, 2019

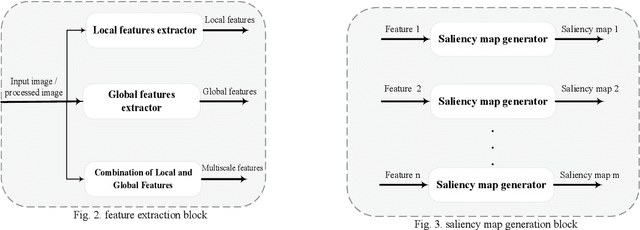
Saliency detection is one of the most challenging problems in the fields of image analysis and computer vision. Many approaches propose different architectures based on the psychological and biological properties of the human visual attention system. However, there is not still an abstract framework, which summarized the existed methods. In this paper, we offered a general framework for saliency models, which consists of five main steps: pre-processing, feature extraction, saliency map generation, saliency map combination, and post-processing. Also, we study different saliency models containing each level and compare their performance together. This framework helps researchers to have a comprehensive view of studying new methods.
VideoSSL: Semi-Supervised Learning for Video Classification
Feb 29, 2020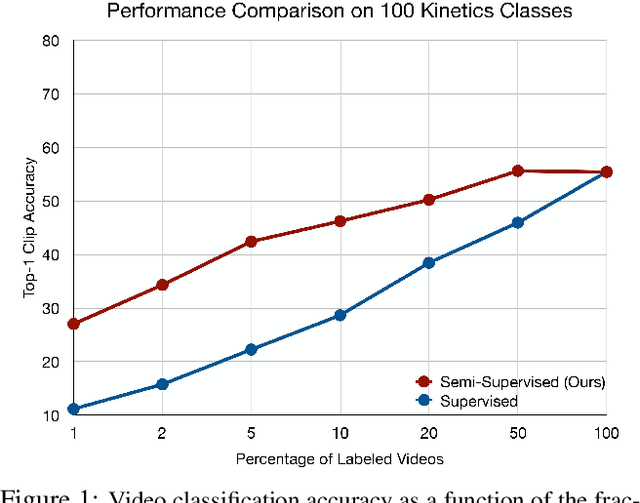



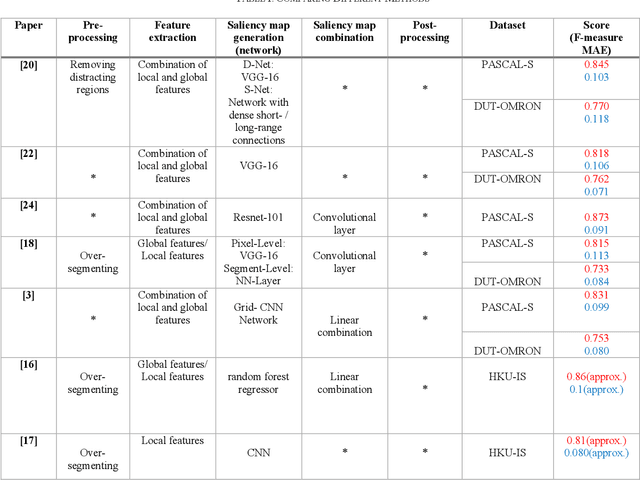
We propose a semi-supervised learning approach for video classification, VideoSSL, using convolutional neural networks (CNN). Like other computer vision tasks, existing supervised video classification methods demand a large amount of labeled data to attain good performance. However, annotation of a large dataset is expensive and time consuming. To minimize the dependence on a large annotated dataset, our proposed semi-supervised method trains from a small number of labeled examples and exploits two regulatory signals from unlabeled data. The first signal is the pseudo-labels of unlabeled examples computed from the confidences of the CNN being trained. The other is the normalized probabilities, as predicted by an image classifier CNN, that captures the information about appearances of the interesting objects in the video. We show that, under the supervision of these guiding signals from unlabeled examples, a video classification CNN can achieve impressive performances utilizing a small fraction of annotated examples on three publicly available datasets: UCF101, HMDB51 and Kinetics.
SSHFD: Single Shot Human Fall Detection with Occluded Joints Resilience
Apr 02, 2020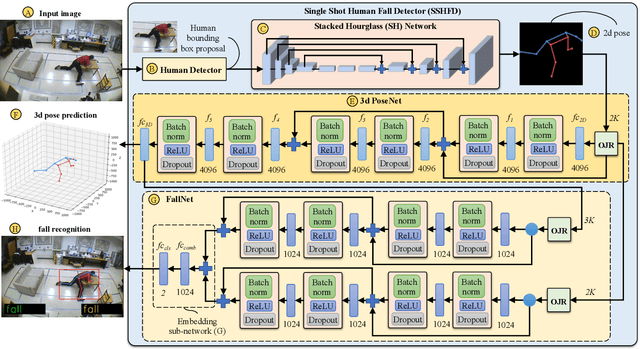
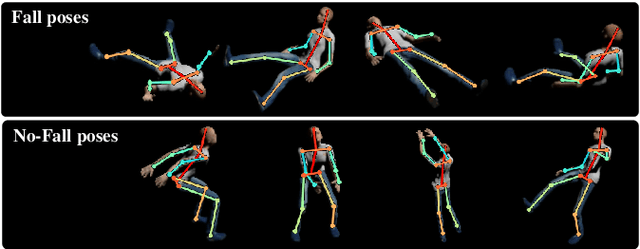
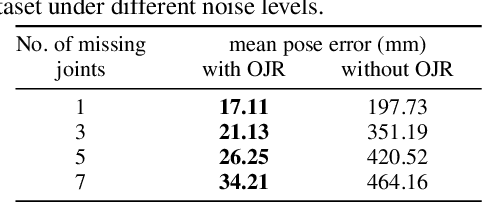

Falling can have fatal consequences for elderly people especially if the fallen person is unable to call for help due to loss of consciousness or any injury. Automatic fall detection systems can assist through prompt fall alarms and by minimizing the fear of falling when living independently at home. Existing vision-based fall detection systems lack generalization to unseen environments due to challenges such as variations in physical appearances, different camera viewpoints, occlusions, and background clutter. In this paper, we explore ways to overcome the above challenges and present Single Shot Human Fall Detector (SSHFD), a deep learning based framework for automatic fall detection from a single image. This is achieved through two key innovations. First, we present a human pose based fall representation which is invariant to appearance characteristics. Second, we present neural network models for 3d pose estimation and fall recognition which are resilient to missing joints due to occluded body parts. Experiments on public fall datasets show that our framework successfully transfers knowledge of 3d pose estimation and fall recognition learnt purely from synthetic data to unseen real-world data, showcasing its generalization capability for accurate fall detection in real-world scenarios.
Self-Supervised Learning from Web Data for Multimodal Retrieval
Jan 07, 2019

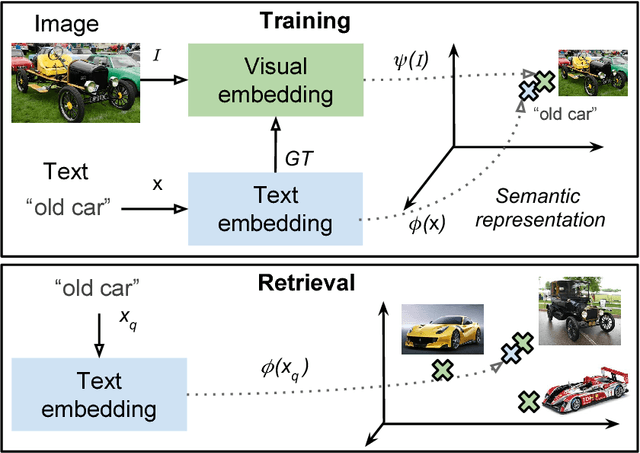
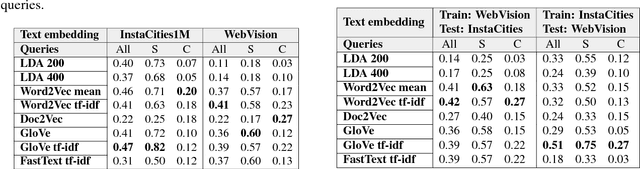
Self-Supervised learning from multimodal image and text data allows deep neural networks to learn powerful features with no need of human annotated data. Web and Social Media platforms provide a virtually unlimited amount of this multimodal data. In this work we propose to exploit this free available data to learn a multimodal image and text embedding, aiming to leverage the semantic knowledge learnt in the text domain and transfer it to a visual model for semantic image retrieval. We demonstrate that the proposed pipeline can learn from images with associated textwithout supervision and analyze the semantic structure of the learnt joint image and text embedding space. We perform a thorough analysis and performance comparison of five different state of the art text embeddings in three different benchmarks. We show that the embeddings learnt with Web and Social Media data have competitive performances over supervised methods in the text based image retrieval task, and we clearly outperform state of the art in the MIRFlickr dataset when training in the target data. Further, we demonstrate how semantic multimodal image retrieval can be performed using the learnt embeddings, going beyond classical instance-level retrieval problems. Finally, we present a new dataset, InstaCities1M, composed by Instagram images and their associated texts that can be used for fair comparison of image-text embeddings.
Gradient-based Data Augmentation for Semi-Supervised Learning
Apr 02, 2020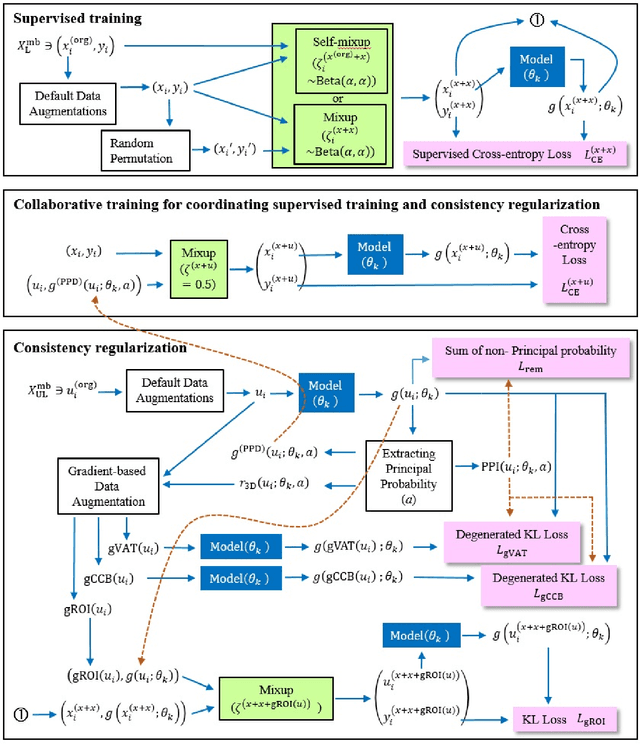
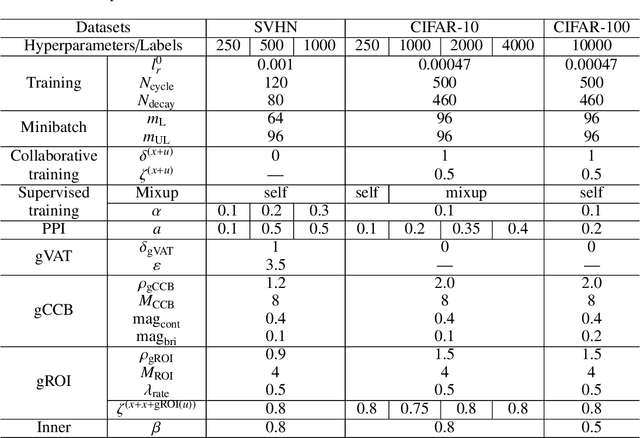
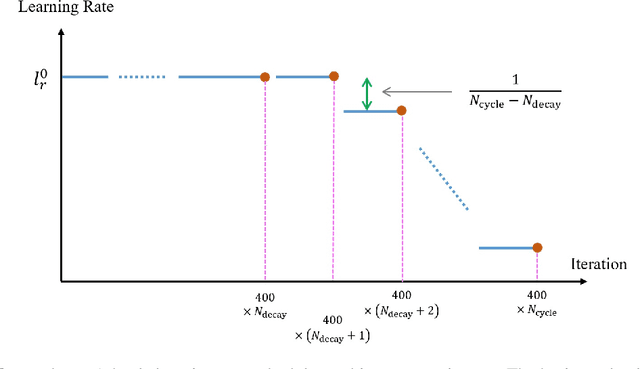
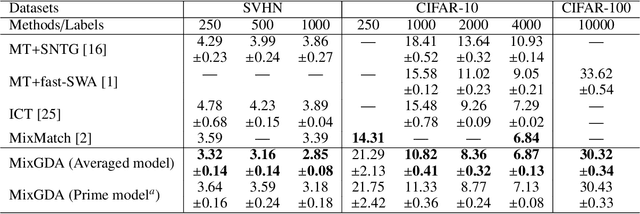
In semi-supervised learning (SSL), a technique called consistency regularization (CR) achieves high performance. It has been proved that the diversity of data used in CR is extremely important to obtain a model with high discrimination performance by CR. We propose a new data augmentation (Gradient-based Data Augmentation (GDA)) that is deterministically calculated from the image pixel value gradient of the posterior probability distribution that is the model output. We aim to secure effective data diversity for CR by utilizing three types of GDA. On the other hand, it has been demonstrated that the mixup method for labeled data and unlabeled data is also effective in SSL. We propose an SSL method named MixGDA by combining various mixup methods and GDA. The discrimination performance achieved by MixGDA is evaluated against the 13-layer CNN that is used as standard in SSL research. As a result, for CIFAR-10 (4000 labels), MixGDA achieves the same level of performance as the best performance ever achieved. For SVHN (250 labels, 500 labels and 1000 labels) and CIFAR-100 (10000 labels), MixGDA achieves state-of-the-art performance.
Consistent Multiple Sequence Decoding
Apr 02, 2020
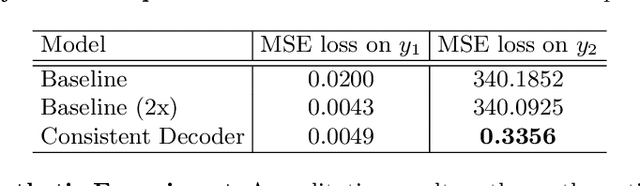
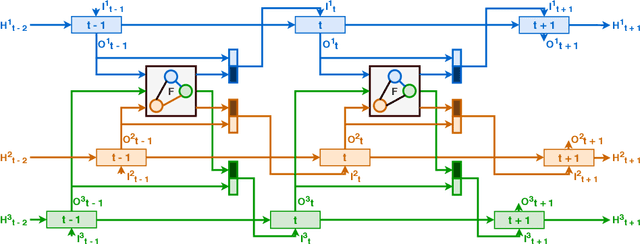
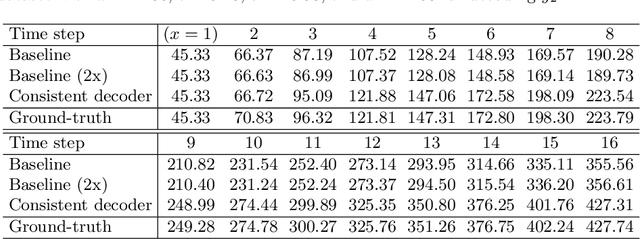
Sequence decoding is one of the core components of most visual-lingual models. However, typical neural decoders when faced with decoding multiple, possibly correlated, sequences of tokens resort to simple independent decoding schemes. In this paper, we introduce a consistent multiple sequence decoding architecture, which is while relatively simple, is general and allows for consistent and simultaneous decoding of an arbitrary number of sequences. Our formulation utilizes a consistency fusion mechanism, implemented using message passing in a Graph Neural Network (GNN), to aggregate context from related decoders. This context is then utilized as a secondary input, in addition to previously generated output, to make a prediction at a given step of decoding. Self-attention, in the GNN, is used to modulate the fusion mechanism locally at each node and each step in the decoding process. We show the efficacy of our consistent multiple sequence decoder on the task of dense relational image captioning and illustrate state-of-the-art performance (+ 5.2% in mAP) on the task. More importantly, we illustrate that the decoded sentences, for the same regions, are more consistent (improvement of 9.5%), while across images and regions maintain diversity.
Adversarial Robustness Through Local Lipschitzness
Apr 16, 2020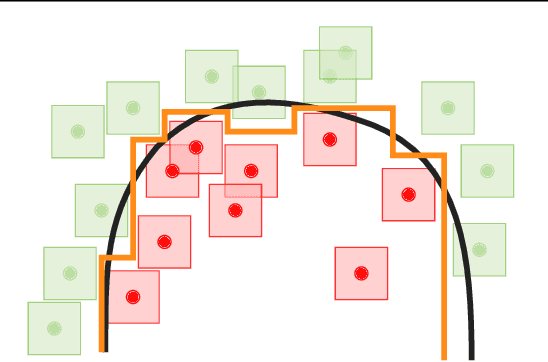
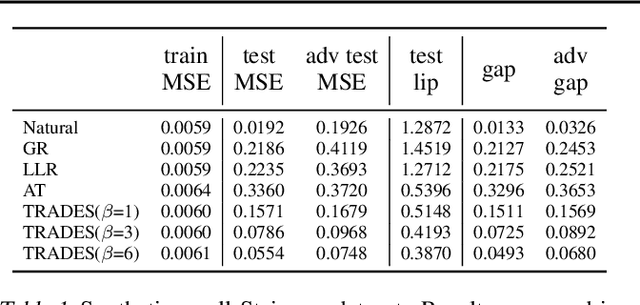
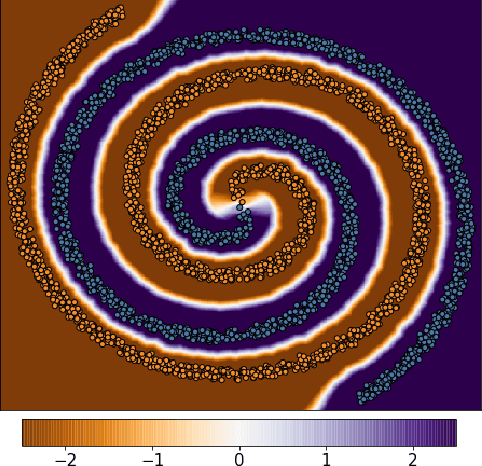
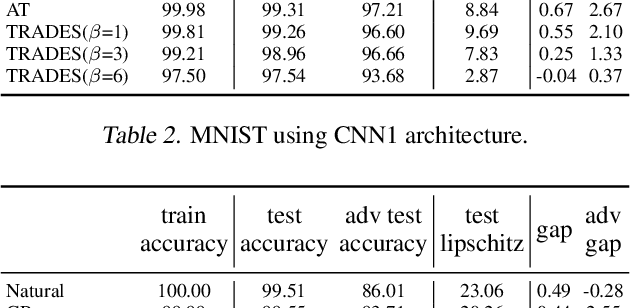
A standard method for improving the robustness of neural networks is adversarial training, where the network is trained on adversarial examples that are close to the training inputs. This produces classifiers that are robust, but it often decreases clean accuracy. Prior work even posits that the tradeoff between robustness and accuracy may be inevitable. We investigate this tradeoff in more depth through the lens of local Lipschitzness. In many image datasets, the classes are separated in the sense that images with different labels are not extremely close in $\ell_\infty$ distance. Using this separation as a starting point, we argue that it is possible to achieve both accuracy and robustness by encouraging the classifier to be locally smooth around the data. More precisely, we consider classifiers that are obtained by rounding locally Lipschitz functions. Theoretically, we show that such classifiers exist for any dataset such that there is a positive distance between the support of different classes. Empirically, we compare the local Lipschitzness of classifiers trained by several methods. Our results show that having a small Lipschitz constant correlates with achieving high clean and robust accuracy, and therefore, the smoothness of the classifier is an important property to consider in the context of adversarial examples. Code available at https://github.com/yangarbiter/robust-local-lipschitz .
CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples
Sep 07, 2016
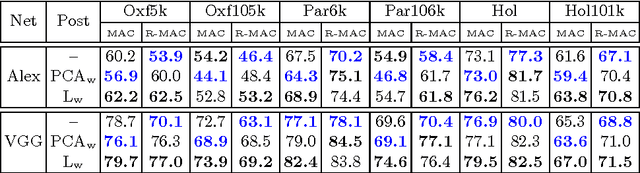

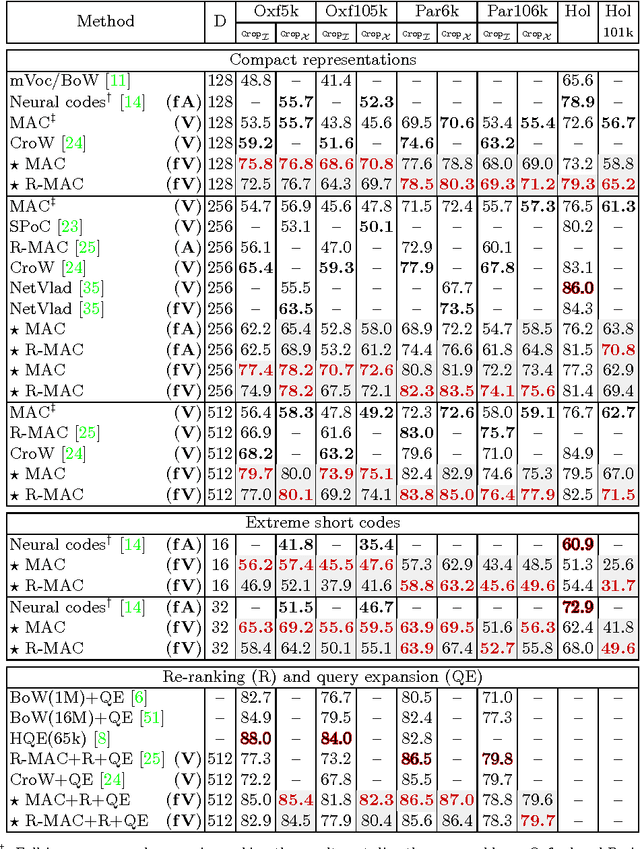
Convolutional Neural Networks (CNNs) achieve state-of-the-art performance in many computer vision tasks. However, this achievement is preceded by extreme manual annotation in order to perform either training from scratch or fine-tuning for the target task. In this work, we propose to fine-tune CNN for image retrieval from a large collection of unordered images in a fully automated manner. We employ state-of-the-art retrieval and Structure-from-Motion (SfM) methods to obtain 3D models, which are used to guide the selection of the training data for CNN fine-tuning. We show that both hard positive and hard negative examples enhance the final performance in particular object retrieval with compact codes.
Deep Learning Models for Digital Pathology
Oct 29, 2019

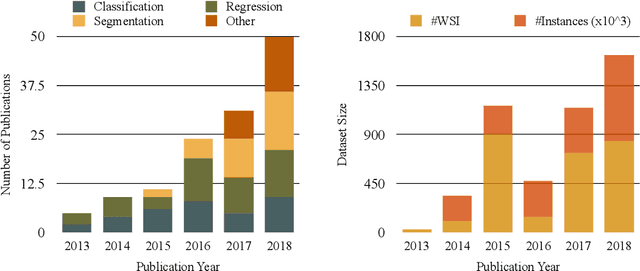
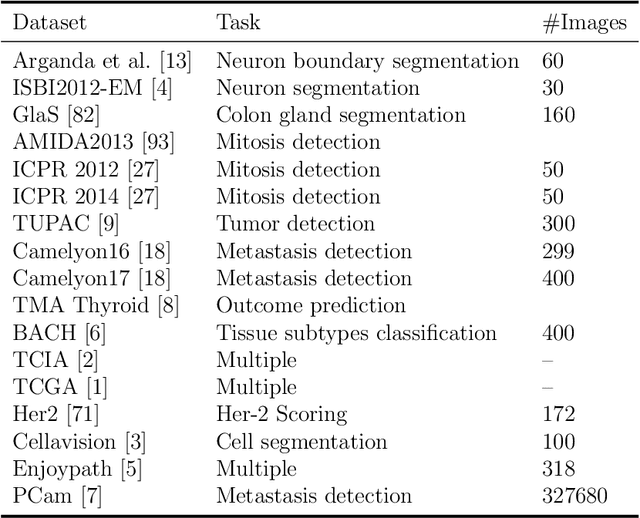
Histopathology images; microscopy images of stained tissue biopsies contain fundamental prognostic information that forms the foundation of pathological analysis and diagnostic medicine. However, diagnostics from histopathology images generally rely on a visual cognitive assessment of tissue slides which implies an inherent element of interpretation and hence subjectivity. Access to digitized histopathology images enabled the development of computational systems aiming at reducing manual intervention and automating parts of pathologists' workflow. Specifically, applications of deep learning to histopathology image analysis now offer opportunities for better quantitative modeling of disease appearance and hence possibly improved prediction of disease aggressiveness and patient outcome. However digitized histopathology tissue slides are unique in a variety of ways and come with their own set of computational challenges. In this survey, we summarize the different challenges facing computational systems for digital pathology and provide a review of state-of-the-art works that developed deep learning-based solutions for the predictive modeling of histopathology images from a detection, stain normalization, segmentation, and tissue classification perspective. We then discuss the challenges facing the validation and integration of such deep learning-based computational systems in clinical workflow and reflect on future opportunities for histopathology derived image measurements and better predictive modeling.
Filter Design and Performance Evaluation for Fingerprint Image Segmentation
Jan 09, 2015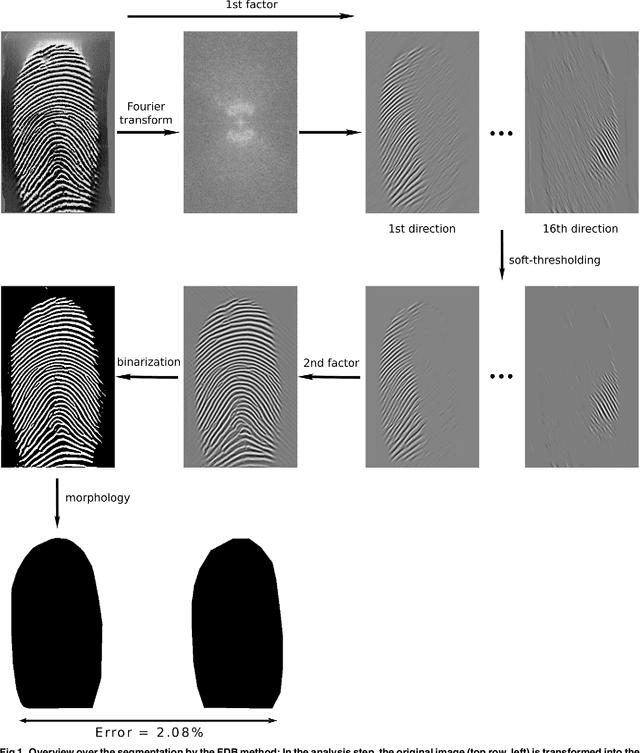
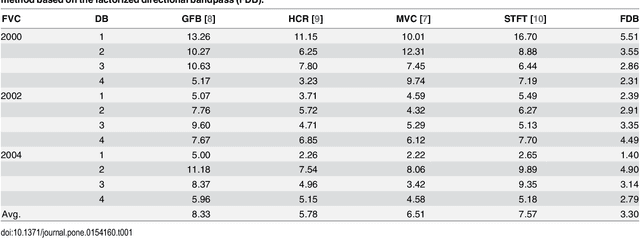
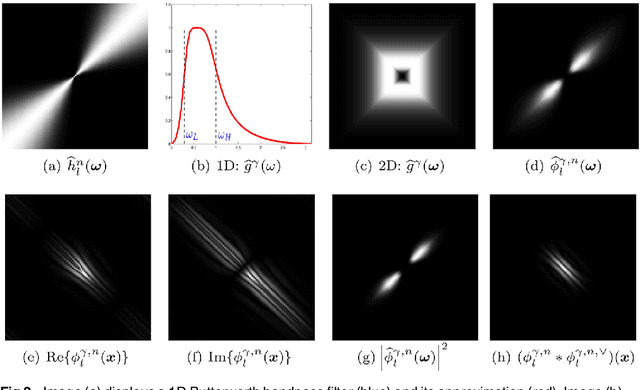

Fingerprint recognition plays an important role in many commercial applications and is used by millions of people every day, e.g. for unlocking mobile phones. Fingerprint image segmentation is typically the first processing step of most fingerprint algorithms and it divides an image into foreground, the region of interest, and background. Two types of error can occur during this step which both have a negative impact on the recognition performance: 'true' foreground can be labeled as background and features like minutiae can be lost, or conversely 'true' background can be misclassified as foreground and spurious features can be introduced. The contribution of this paper is threefold: firstly, we propose a novel factorized directional bandpass (FDB) segmentation method for texture extraction based on the directional Hilbert transform of a Butterworth bandpass (DHBB) filter interwoven with soft-thresholding. Secondly, we provide a manually marked ground truth segmentation for 10560 images as an evaluation benchmark. Thirdly, we conduct a systematic performance comparison between the FDB method and four of the most often cited fingerprint segmentation algorithms showing that the FDB segmentation method clearly outperforms these four widely used methods. The benchmark and the implementation of the FDB method are made publicly available.