 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Object Detection in Large Images using Deep Reinforcement Learning
Dec 09, 2019
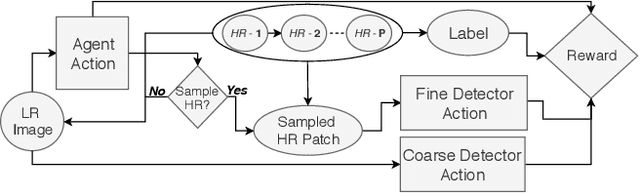
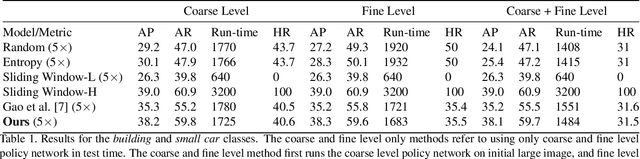
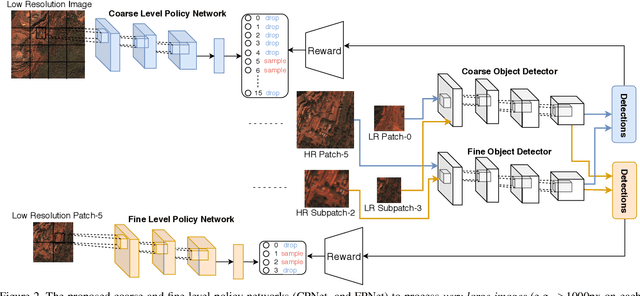
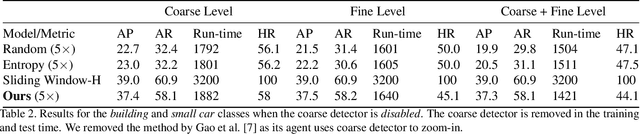
Traditionally, an object detector is applied to every part of the scene of interest, and its accuracy and computational cost increases with higher resolution images. However, in some application domains such as remote sensing, purchasing high spatial resolution images is expensive. To reduce the large computational and monetary cost associated with using high spatial resolution images, we propose a reinforcement learning agent that adaptively selects the spatial resolution of each image that is provided to the detector. In particular, we train the agent in a dual reward setting to choose low spatial resolution images to be run through a coarse level detector when the image is dominated by large objects, and high spatial resolution images to be run through a fine level detector when it is dominated by small objects. This reduces the dependency on high spatial resolution images for building a robust detector and increases run-time efficiency. We perform experiments on the xView dataset, consisting of large images, where we increase run-time efficiency by 50% and use high resolution images only 30% of the time while maintaining similar accuracy as a detector that uses only high resolution images.
One Size Fits All: Can We Train One Denoiser for All Noise Levels?
May 19, 2020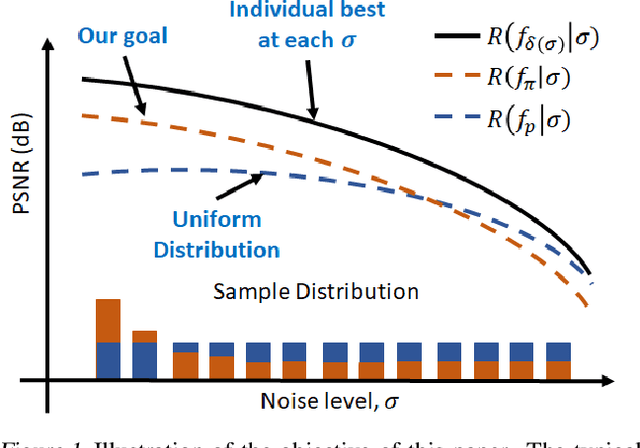
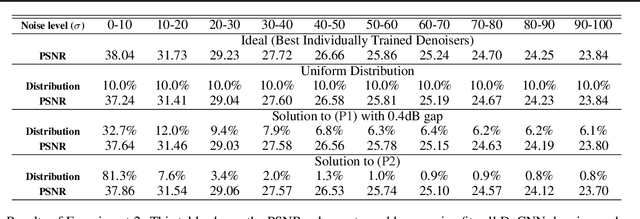
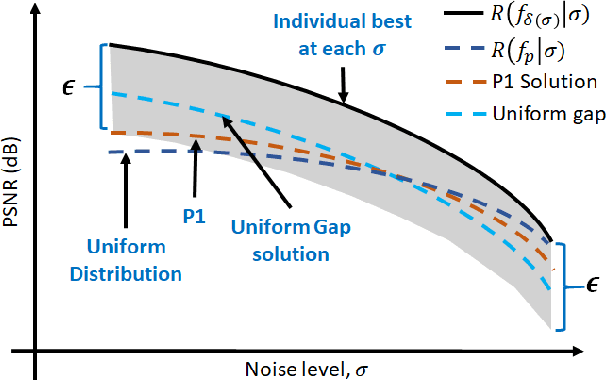
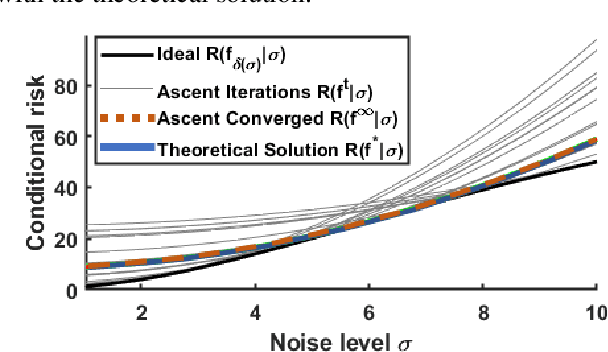
When training an estimator such as a neural network for tasks like image denoising, it is generally preferred to train \emph{one} estimator and apply it to \emph{all} noise levels. The de facto training protocol to achieve this goal is to train the estimator with noisy samples whose noise levels are uniformly distributed across the range of interest. However, why should we allocate the samples uniformly? Can we have more training samples that are less noisy, and fewer samples that are more noisy? What is the optimal distribution? How do we obtain such a distribution? The goal of this paper is to address this training sample distribution problem from a minimax risk optimization perspective. We derive a dual ascent algorithm to determine the optimal sampling distribution of which the convergence is guaranteed as long as the set of admissible estimators is closed and convex. For estimators with non-convex admissible sets such as deep neural networks, our dual formulation converges to a solution of the convex relaxation. We discuss how the algorithm can be implemented in practice. We evaluate the algorithm on linear estimators and deep networks.
Dual Embedding Expansion for Vehicle Re-identification
Apr 18, 2020
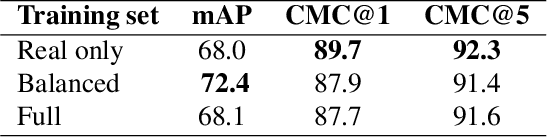
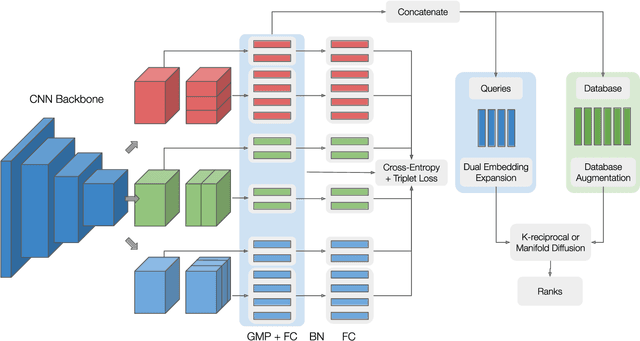
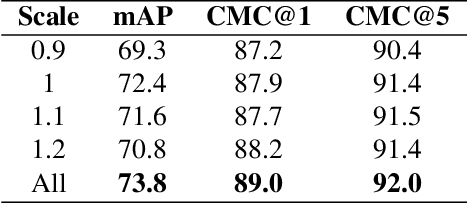
Vehicle re-identification plays a crucial role in the management of transportation infrastructure and traffic flow. However, this is a challenging task due to the large view-point variations in appearance, environmental and instance-related factors. Modern systems deploy CNNs to produce unique representations from the images of each vehicle instance. Most work focuses on leveraging new losses and network architectures to improve the descriptiveness of these representations. In contrast, our work concentrates on re-ranking and embedding expansion techniques. We propose an efficient approach for combining the outputs of multiple models at various scales while exploiting tracklet and neighbor information, called dual embedding expansion (DEx). Additionally, a comparative study of several common image retrieval techniques is presented in the context of vehicle re-ID. Our system yields competitive performance in the 2020 NVIDIA AI City Challenge with promising results. We demonstrate that DEx when combined with other re-ranking techniques, can produce an even larger gain without any additional attribute labels or manual supervision.
Boundary-Aware Feature Propagation for Scene Segmentation
Aug 31, 2019



In this work, we address the challenging issue of scene segmentation. To increase the feature similarity of the same object while keeping the feature discrimination of different objects, we explore to propagate information throughout the image under the control of objects' boundaries. To this end, we first propose to learn the boundary as an additional semantic class to enable the network to be aware of the boundary layout. Then, we propose unidirectional acyclic graphs (UAGs) to model the function of undirected cyclic graphs (UCGs), which structurize the image via building graphic pixel-by-pixel connections, in an efficient and effective way. Furthermore, we propose a boundary-aware feature propagation (BFP) module to harvest and propagate the local features within their regions isolated by the learned boundaries in the UAG-structured image. The proposed BFP is capable of splitting the feature propagation into a set of semantic groups via building strong connections among the same segment region but weak connections between different segment regions. Without bells and whistles, our approach achieves new state-of-the-art segmentation performance on three challenging semantic segmentation datasets, i.e., PASCAL-Context, CamVid, and Cityscapes.
Toward Automated Classroom Observation: Multimodal Machine Learning to Estimate CLASS Positive Climate and Negative Climate
May 19, 2020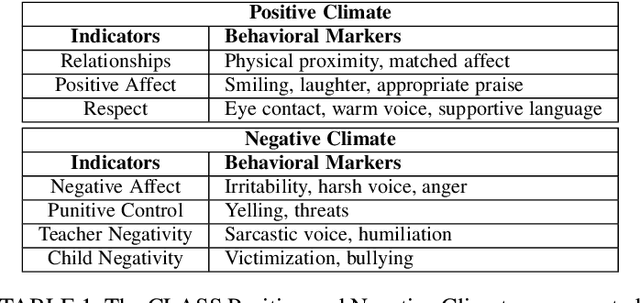
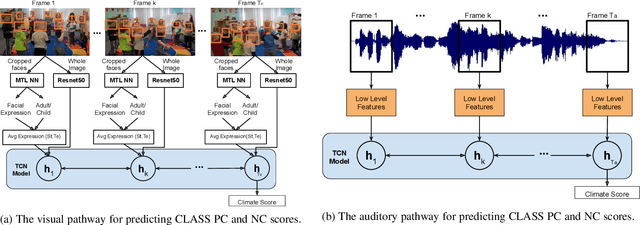
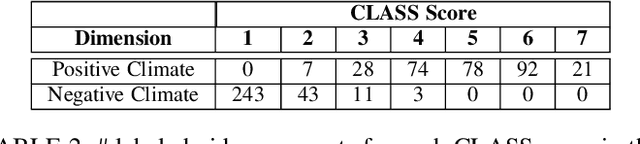

In this work we present a multi-modal machine learning-based system, which we call ACORN, to analyze videos of school classrooms for the Positive Climate (PC) and Negative Climate (NC) dimensions of the CLASS observation protocol that is widely used in educational research. ACORN uses convolutional neural networks to analyze spectral audio features, the faces of teachers and students, and the pixels of each image frame, and then integrates this information over time using Temporal Convolutional Networks. The audiovisual ACORN's PC and NC predictions have Pearson correlations of $0.55$ and $0.63$ with ground-truth scores provided by expert CLASS coders on the UVA Toddler dataset (cross-validation on $n=300$ 15-min video segments), and a purely auditory ACORN predicts PC and NC with correlations of $0.36$ and $0.41$ on the MET dataset (test set of $n=2000$ videos segments). These numbers are similar to inter-coder reliability of human coders. Finally, using Graph Convolutional Networks we make early strides (AUC=$0.70$) toward predicting the specific moments (45-90sec clips) when the PC is particularly weak/strong. Our findings inform the design of automatic classroom observation and also more general video activity recognition and summary recognition systems.
Unbalanced GANs: Pre-training the Generator of Generative Adversarial Network using Variational Autoencoder
Feb 06, 2020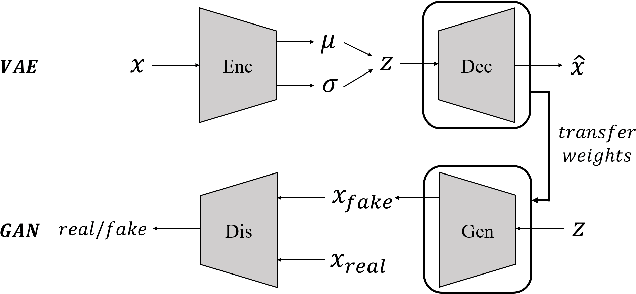
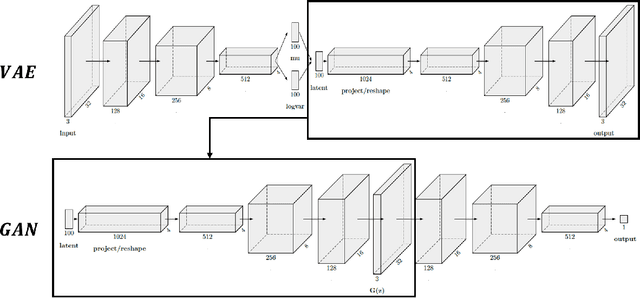
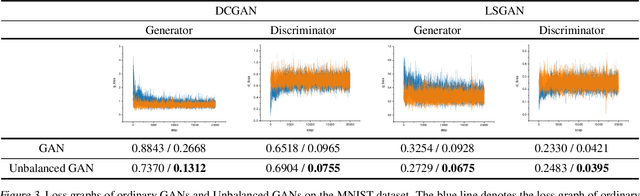

We propose Unbalanced GANs, which pre-trains the generator of the generative adversarial network (GAN) using variational autoencoder (VAE). We guarantee the stable training of the generator by preventing the faster convergence of the discriminator at early epochs. Furthermore, we balance between the generator and the discriminator at early epochs and thus maintain the stabilized training of GANs. We apply Unbalanced GANs to well known public datasets and find that Unbalanced GANs reduce mode collapses. We also show that Unbalanced GANs outperform ordinary GANs in terms of stabilized learning, faster convergence and better image quality at early epochs.
Learning from Small Data Through Sampling an Implicit Conditional Generative Latent Optimization Model
Mar 31, 2020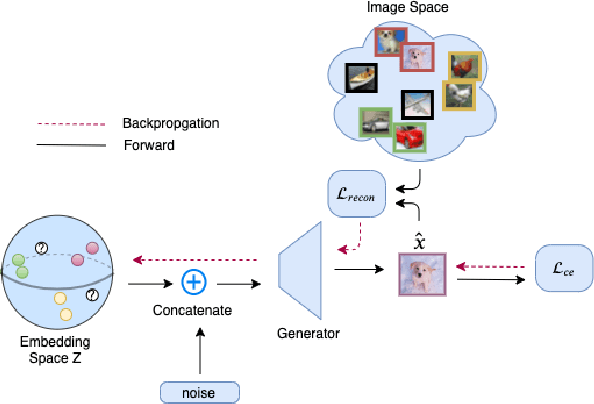

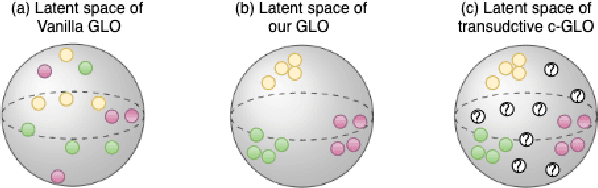

We revisit the long-standing problem of \emph{learning from small sample}. In recent years major efforts have been invested into the generation of new samples from a small set of training data points. Some use classical transformations, others synthesize new examples. Our approach belongs to the second one. We propose a new model based on conditional Generative Latent Optimization (cGLO). Our model learns to synthesize completely new samples for every class just by interpolating between samples in the latent space. The proposed method samples the learned latent space using spherical interpolations (\emph{slerp}) and generates a new sample using the trained generator. Our empirical results show that the new sampled set is diverse enough, leading to improvement in image classification in comparison to the state of the art, when trained on small samples of CIFAR-100 and CUB-200.
Are Accelerometers for Activity Recognition a Dead-end?
Jan 22, 2020

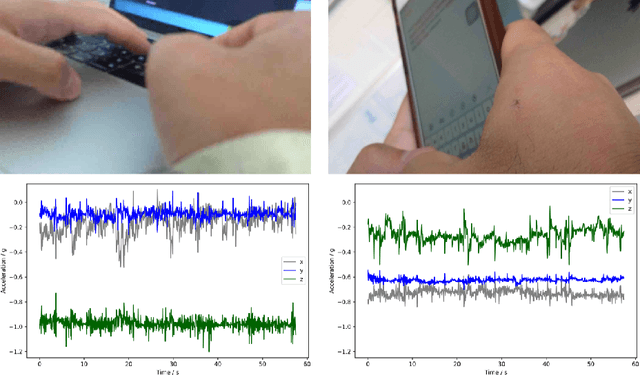
Accelerometer-based (and by extension other inertial sensors) research for Human Activity Recognition (HAR) is a dead-end. This sensor does not offer enough information for us to progress in the core domain of HAR---to recognize everyday activities from sensor data. Despite continued and prolonged efforts in improving feature engineering and machine learning models, the activities that we can recognize reliably have only expanded slightly and many of the same flaws of early models are still present today. Instead of relying on acceleration data, we should instead consider modalities with much richer information---a logical choice are images. With the rapid advance in image sensing hardware and modelling techniques, we believe that a widespread adoption of image sensors will open many opportunities for accurate and robust inference across a wide spectrum of human activities. In this paper, we make the case for imagers in place of accelerometers as the default sensor for human activity recognition. Our review of past works has led to the observation that progress in HAR had stalled, caused by our reliance on accelerometers. We further argue for the suitability of images for activity recognition by illustrating their richness of information and the marked progress in computer vision. Through a feasibility analysis, we find that deploying imagers and CNNs on device poses no substantial burden on modern mobile hardware. Overall, our work highlights the need to move away from accelerometers and calls for further exploration of using imagers for activity recognition.
Selective Synthetic Augmentation with Quality Assurance
Dec 09, 2019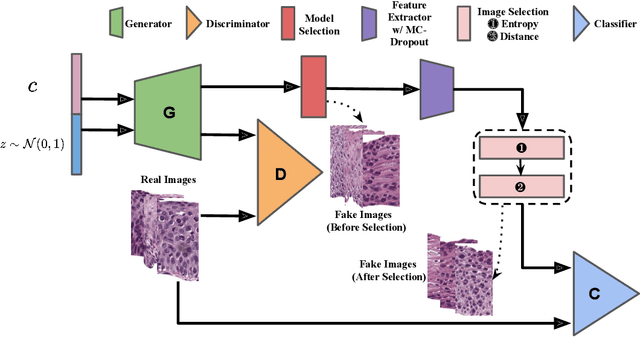
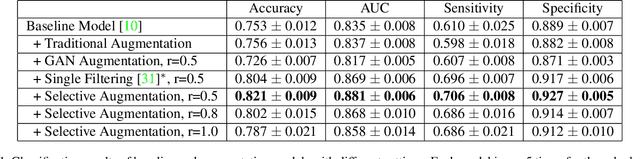
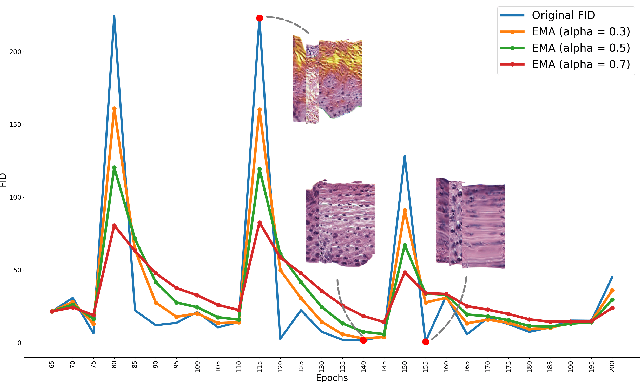

Supervised training of an automated medical image analysis system often requires a large amount of expert annotations that are hard to collect. Moreover, the proportions of data available across different classes may be highly imbalanced for rare diseases. To mitigate these issues, we investigate a novel data augmentation pipeline that selectively adds new synthetic images generated by conditional Adversarial Networks (cGANs), rather than extending directly the training set with synthetic images. The selection mechanisms that we introduce to the synthetic augmentation pipeline are motivated by the observation that, although cGAN-generated images can be visually appealing, they are not guaranteed to contain essential features for classification performance improvement. By selecting synthetic images based on the confidence of their assigned labels and their feature similarity to real labeled images, our framework provides quality assurance to synthetic augmentation by ensuring that adding the selected synthetic images to the training set will improve performance. We evaluate our model on a medical histopathology dataset, and two natural image classification benchmarks, CIFAR10 and SVHN. Results on these datasets show significant and consistent improvements in classification performance (with 6.8%, 3.9%, 1.6% higher accuracy, respectively) by leveraging cGAN generated images with selective augmentation.
Recurrent Quantum Neural Networks
Jun 25, 2020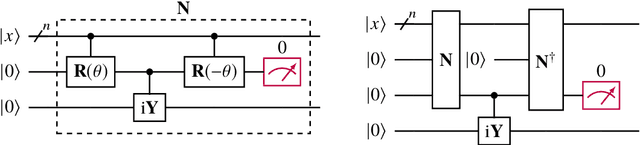
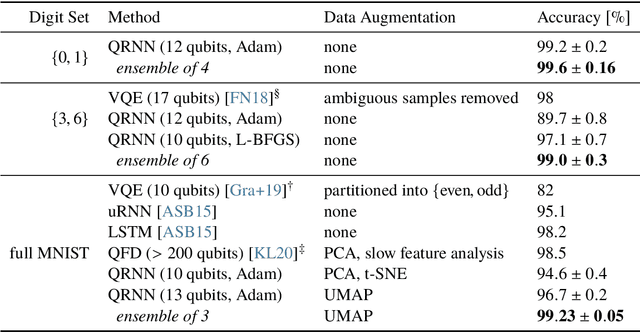
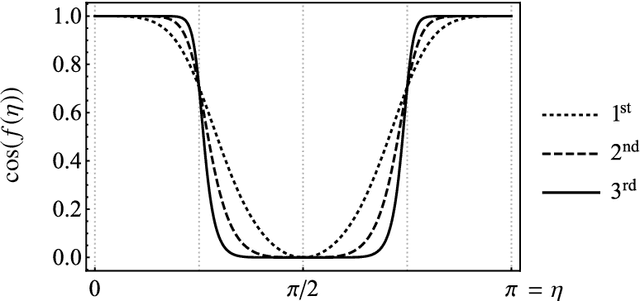

Recurrent neural networks are the foundation of many sequence-to-sequence models in machine learning, such as machine translation and speech synthesis. In contrast, applied quantum computing is in its infancy. Nevertheless there already exist quantum machine learning models such as variational quantum eigensolvers which have been used successfully e.g. in the context of energy minimization tasks. In this work we construct a quantum recurrent neural network (QRNN) with demonstrable performance on non-trivial tasks such as sequence learning and integer digit classification. The QRNN cell is built from parametrized quantum neurons, which, in conjunction with amplitude amplification, create a nonlinear activation of polynomials of its inputs and cell state, and allow the extraction of a probability distribution over predicted classes at each step. To study the model's performance, we provide an implementation in pytorch, which allows the relatively efficient optimization of parametrized quantum circuits with thousands of parameters. We establish a QRNN training setup by benchmarking optimization hyperparameters, and analyse suitable network topologies for simple memorisation and sequence prediction tasks from Elman's seminal paper (1990) on temporal structure learning. We then proceed to evaluate the QRNN on MNIST classification, both by feeding the QRNN each image pixel-by-pixel; and by utilising modern data augmentation as preprocessing step. Finally, we analyse to what extent the unitary nature of the network counteracts the vanishing gradient problem that plagues many existing quantum classifiers and classical RNNs.