 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Segmentation by Using Threshold Techniques
May 21, 2010
This paper attempts to undertake the study of segmentation image techniques by using five threshold methods as Mean method, P-tile method, Histogram Dependent Technique (HDT), Edge Maximization Technique (EMT) and visual Technique and they are compared with one another so as to choose the best technique for threshold segmentation techniques image. These techniques applied on three satellite images to choose base guesses for threshold segmentation image.
* http://www.journalofcomputing.org
Robust Eye Centers Localization with Zero--Crossing Encoded Image Projections
Mar 26, 2015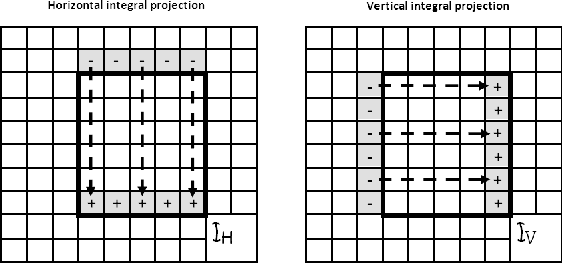
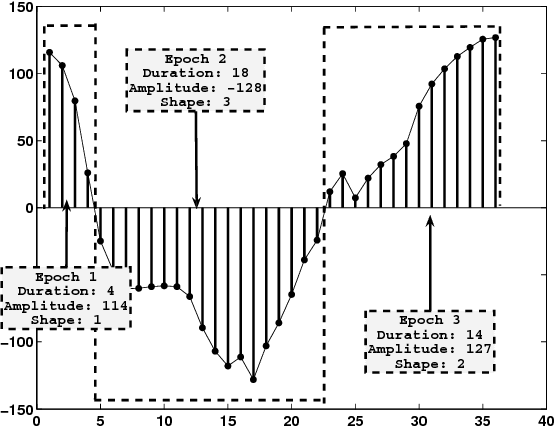
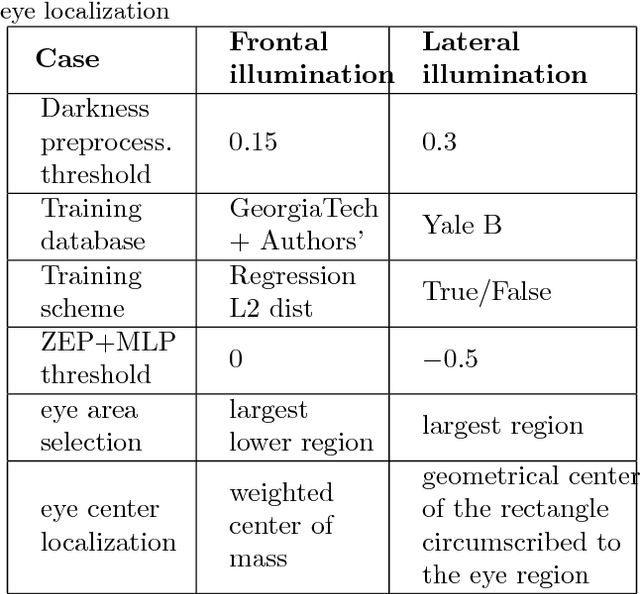
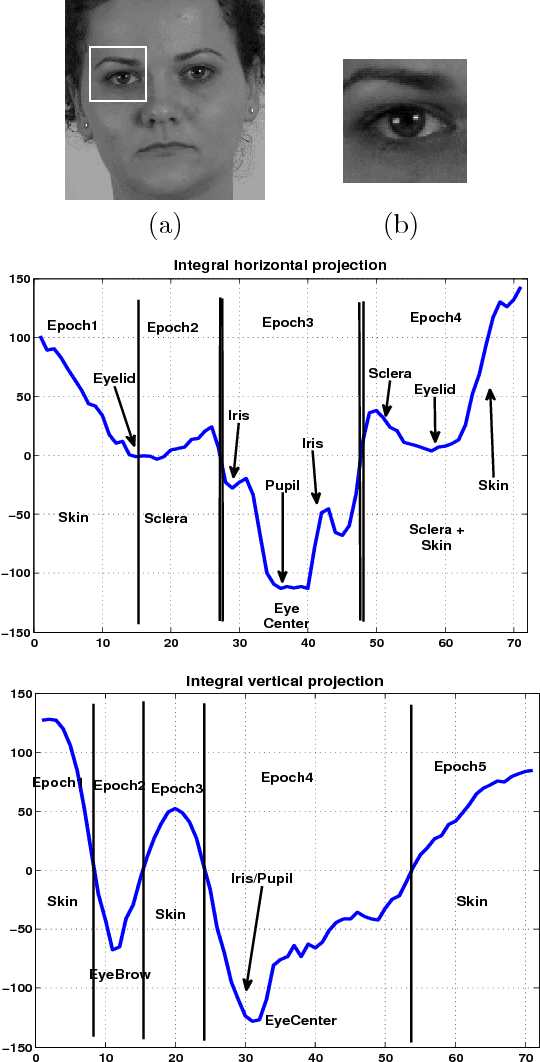
This paper proposes a new framework for the eye centers localization by the joint use of encoding of normalized image projections and a Multi Layer Perceptron (MLP) classifier. The encoding is novel and it consists in identifying the zero-crossings and extracting the relevant parameters from the resulting modes. The compressed normalized projections produce feature descriptors that are inputs to a properly-trained MLP, for discriminating among various categories of image regions. The proposed framework forms a fast and reliable system for the eye centers localization, especially in the context of face expression analysis in unconstrained environments. We successfully test the proposed method on a wide variety of databases including BioID, Cohn-Kanade, Extended Yale B and Labelled Faces in the Wild (LFW) databases.
SketchGCN: Semantic Sketch Segmentation with Graph Convolutional Networks
Mar 02, 2020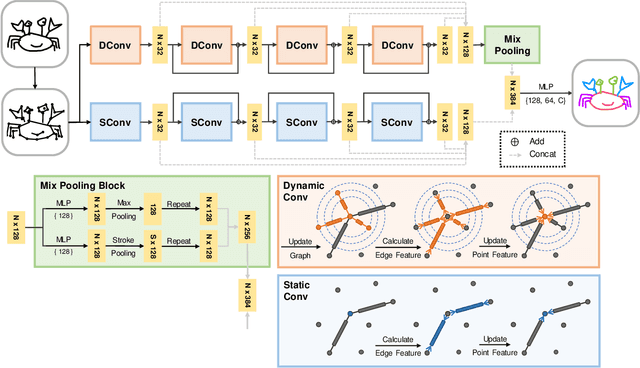
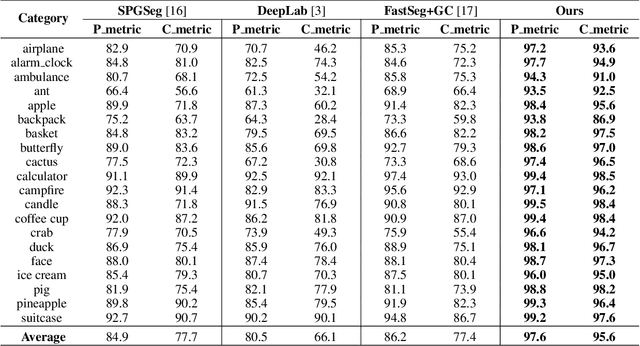
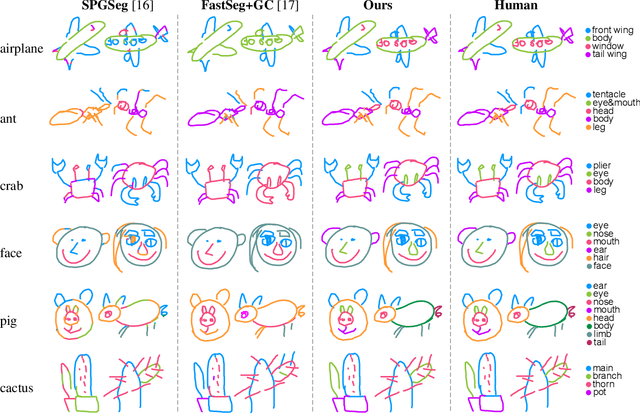
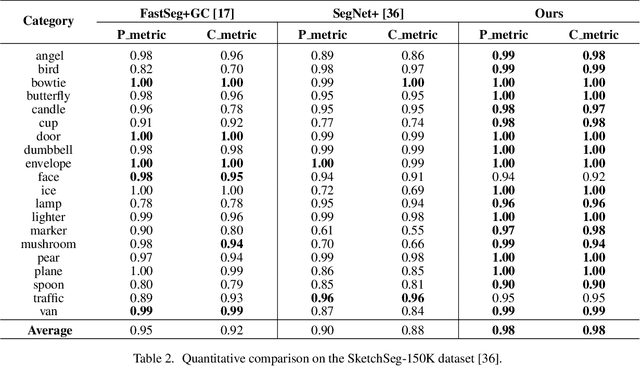
We introduce SketchGCN, a graph convolutional neural network for semantic segmentation and labeling of free-hand sketches. We treat an input sketch as a 2D pointset, and encode the stroke structure information into graph node/edge representations. To predict the per-point labels, our SketchGCN uses graph convolution and a global-local branching network architecture to extract both intra-stroke and inter-stroke features. SketchGCN significantly improves the accuracy of the state-of-the-art methods for semantic sketch segmentation (by 11.4% in the pixel-basedmetric and 18.2% in the component-based metric over a large-scale challenging SPG dataset) and has magnitudes fewer parameters than both image-based and sequence-based methods.
Kernel principal component analysis network for image classification
Dec 20, 2015In order to classify the nonlinear feature with linear classifier and improve the classification accuracy, a deep learning network named kernel principal component analysis network (KPCANet) is proposed. First, mapping the data into higher space with kernel principal component analysis to make the data linearly separable. Then building a two-layer KPCANet to obtain the principal components of image. Finally, classifying the principal components with linearly classifier. Experimental results show that the proposed KPCANet is effective in face recognition, object recognition and hand-writing digits recognition, it also outperforms principal component analysis network (PCANet) generally as well. Besides, KPCANet is invariant to illumination and stable to occlusion and slight deformation.
AdvGAN++ : Harnessing latent layers for adversary generation
Aug 02, 2019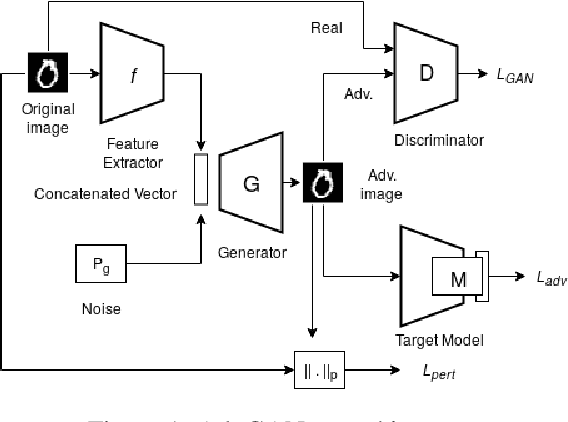
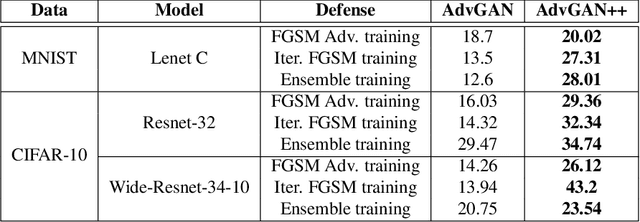
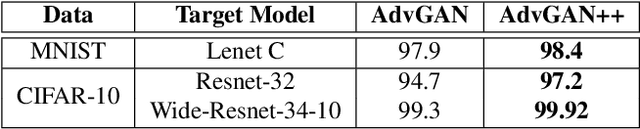

Adversarial examples are fabricated examples, indistinguishable from the original image that mislead neural networks and drastically lower their performance. Recently proposed AdvGAN, a GAN based approach, takes input image as a prior for generating adversaries to target a model. In this work, we show how latent features can serve as better priors than input images for adversary generation by proposing AdvGAN++, a version of AdvGAN that achieves higher attack rates than AdvGAN and at the same time generates perceptually realistic images on MNIST and CIFAR-10 datasets.
Reducing Overlearning through Disentangled Representations by Suppressing Unknown Tasks
May 20, 2020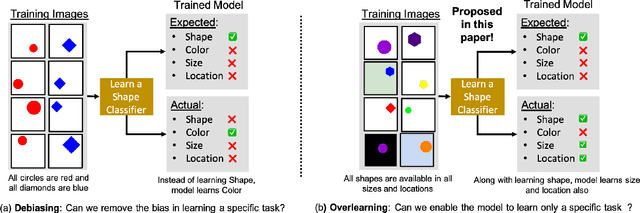
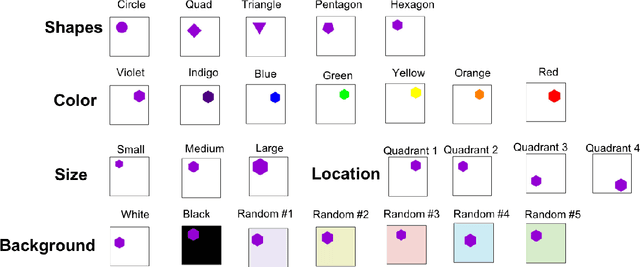
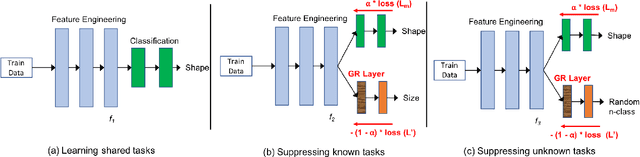
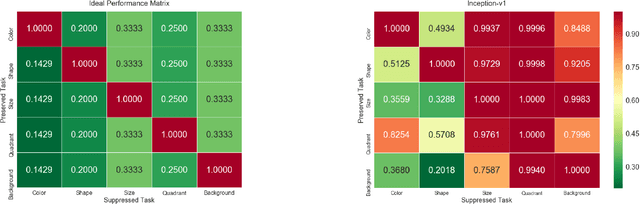
Existing deep learning approaches for learning visual features tend to overlearn and extract more information than what is required for the task at hand. From a privacy preservation perspective, the input visual information is not protected from the model; enabling the model to become more intelligent than it is trained to be. Current approaches for suppressing additional task learning assume the presence of ground truth labels for the tasks to be suppressed during training time. In this research, we propose a three-fold novel contribution: (i) a model-agnostic solution for reducing model overlearning by suppressing all the unknown tasks, (ii) a novel metric to measure the trust score of a trained deep learning model, and (iii) a simulated benchmark dataset, PreserveTask, having five different fundamental image classification tasks to study the generalization nature of models. In the first set of experiments, we learn disentangled representations and suppress overlearning of five popular deep learning models: VGG16, VGG19, Inception-v1, MobileNet, and DenseNet on PreserverTask dataset. Additionally, we show results of our framework on color-MNIST dataset and practical applications of face attribute preservation in Diversity in Faces (DiF) and IMDB-Wiki dataset.
Content Based Image Retrieval System using Feature Classification with Modified KNN Algorithm
Jul 17, 2013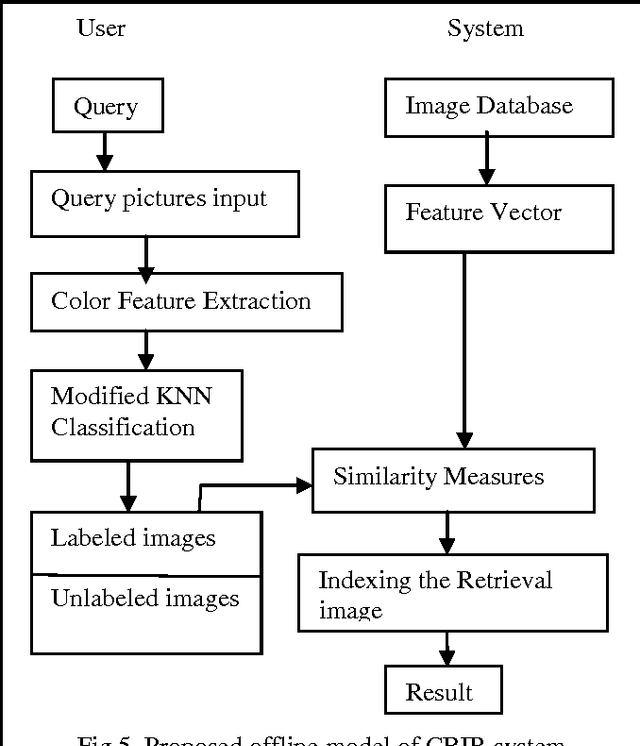

Feature means countenance, remote sensing scene objects with similar characteristics, associated to interesting scene elements in the image formation process. They are classified into three types in image processing, that is low, middle and high. Low level features are color, texture and middle level feature is shape and high level feature is semantic gap of objects. An image retrieval system is a computer system for browsing, searching and retrieving images from a large image database. Content Based Image Retrieval is a technique which uses visual features of image such as color, shape, texture to search user required image from large image database according to user requests in the form of a query. MKNN is an enhancing method of KNN. The proposed KNN classification is called MKNN. MKNN contains two parts for processing, they are validity of the train samples and applying weighted KNN. The validity of each point is computed according to its neighbors. In our proposal, Modified K-Nearest Neighbor can be considered a kind of weighted KNN so that the query label is approximated by weighting the neighbors of the query.
Interpretable Time-series Classification on Few-shot Samples
Jun 03, 2020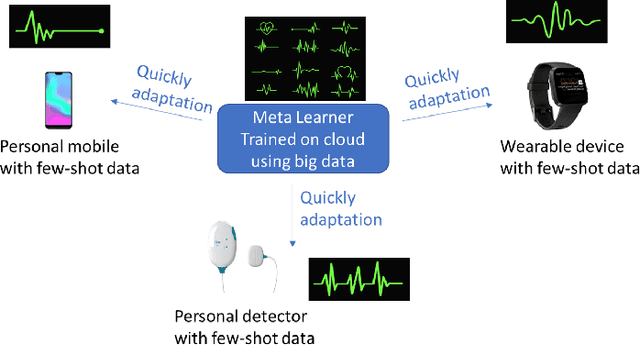
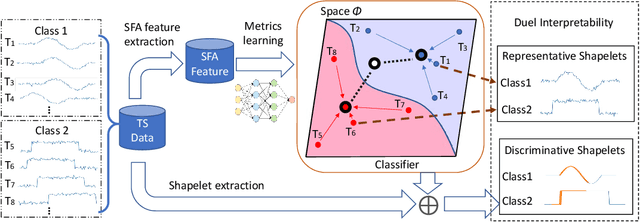
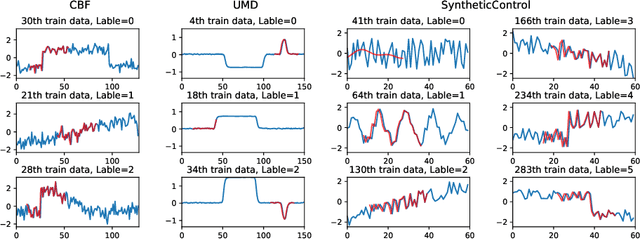
Recent few-shot learning works focus on training a model with prior meta-knowledge to fast adapt to new tasks with unseen classes and samples. However, conventional time-series classification algorithms fail to tackle the few-shot scenario. Existing few-shot learning methods are proposed to tackle image or text data, and most of them are neural-based models that lack interpretability. This paper proposes an interpretable neural-based framework, namely \textit{Dual Prototypical Shapelet Networks (DPSN)} for few-shot time-series classification, which not only trains a neural network-based model but also interprets the model from dual granularity: 1) global overview using representative time series samples, and 2) local highlights using discriminative shapelets. In particular, the generated dual prototypical shapelets consist of representative samples that can mostly demonstrate the overall shapes of all samples in the class and discriminative partial-length shapelets that can be used to distinguish different classes. We have derived 18 few-shot TSC datasets from public benchmark datasets and evaluated the proposed method by comparing with baselines. The DPSN framework outperforms state-of-the-art time-series classification methods, especially when training with limited amounts of data. Several case studies have been given to demonstrate the interpret ability of our model.
Characterizing the Variability in Face Recognition Accuracy Relative to Race
May 08, 2019
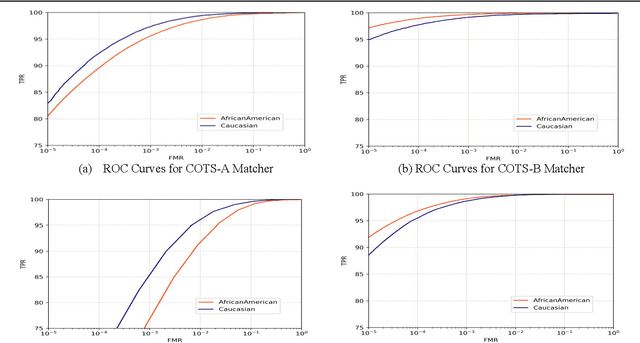
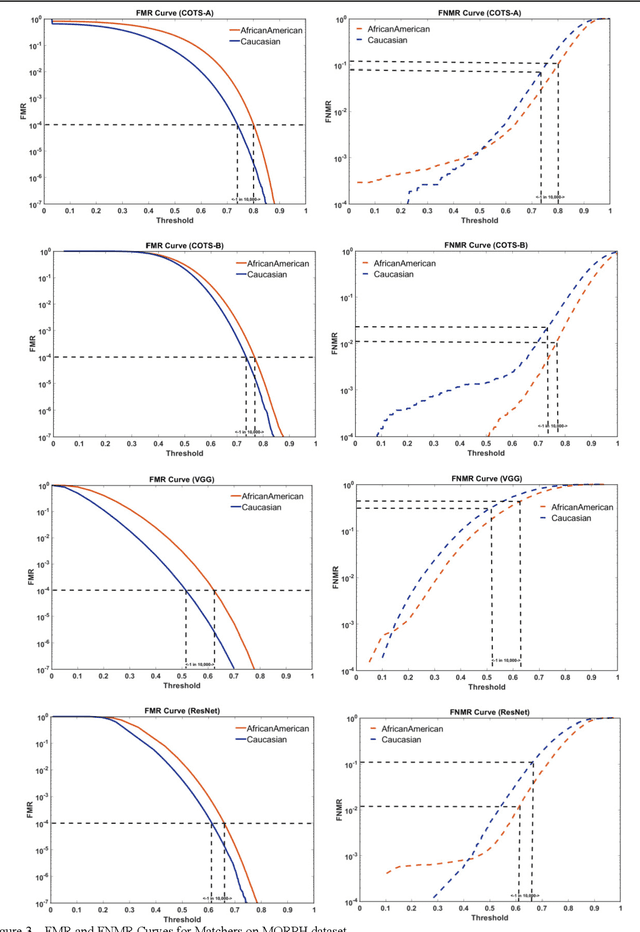
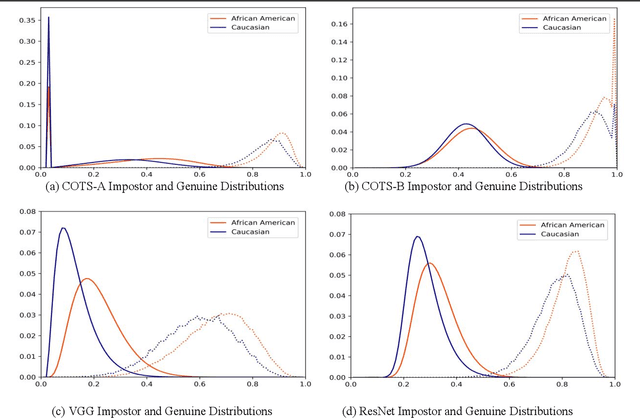
Many recent news headlines have labeled face recognition technology as biased or racist. We report on a methodical investigation into differences in face recognition accuracy between African-American and Caucasian image cohorts of the MORPH dataset. We find that, for all four matchers considered, the impostor and the genuine distributions are statistically significantly different between cohorts. For a fixed decision threshold, the African-American image cohort has a higher false match rate and a lower false non-match rate. ROC curves compare verification rates at the same false match rate, but the different cohorts achieve the same false match rate at different thresholds. This means that ROC comparisons are not relevant to operational scenarios that use a fixed decision threshold. We show that, for the ResNet matcher, the two cohorts have approximately equal separation of impostor and genuine distributions. Using ICAO compliance as a standard of image quality, we find that the initial image cohorts have unequal rates of good quality images. The ICAO-compliant subsets of the original image cohorts show improved accuracy, with the main effect being to reducing the low-similarity tail of the genuine distributions.
A Sub-block Based Image Retrieval Using Modified Integrated Region Matching
Jul 05, 2013

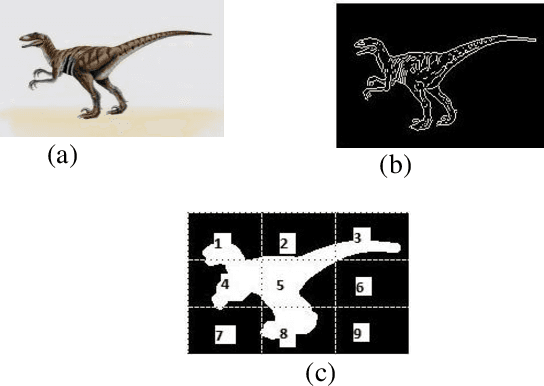
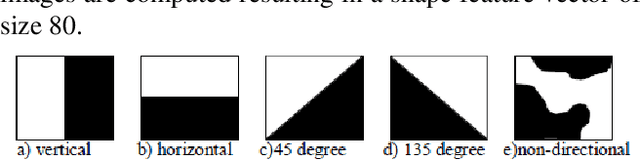
This paper proposes a content based image retrieval (CBIR) system using the local colour and texture features of selected image sub-blocks and global colour and shape features of the image. The image sub-blocks are roughly identified by segmenting the image into partitions of different configuration, finding the edge density in each partition using edge thresholding followed by morphological dilation. The colour and texture features of the identified regions are computed from the histograms of the quantized HSV colour space and Gray Level Co- occurrence Matrix (GLCM) respectively. The colour and texture feature vectors is computed for each region. The shape features are computed from the Edge Histogram Descriptor (EHD). A modified Integrated Region Matching (IRM) algorithm is used for finding the minimum distance between the sub-blocks of the query and target image. Experimental results show that the proposed method provides better retrieving result than retrieval using some of the existing methods.
* 7 pages