 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variational Quantum Singular Value Decomposition
Jun 03, 2020
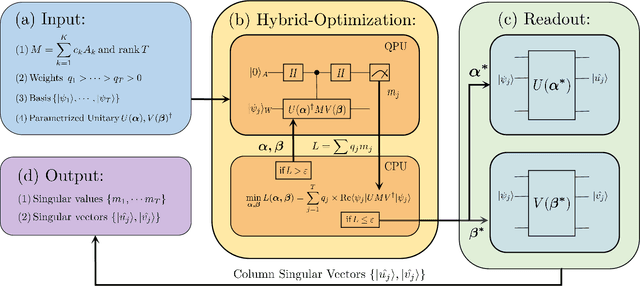
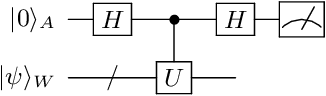
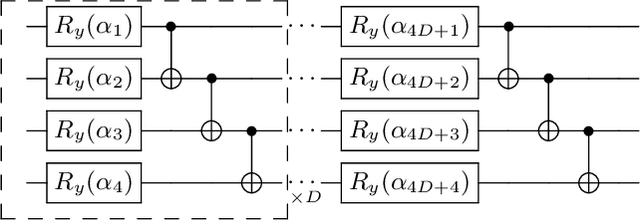
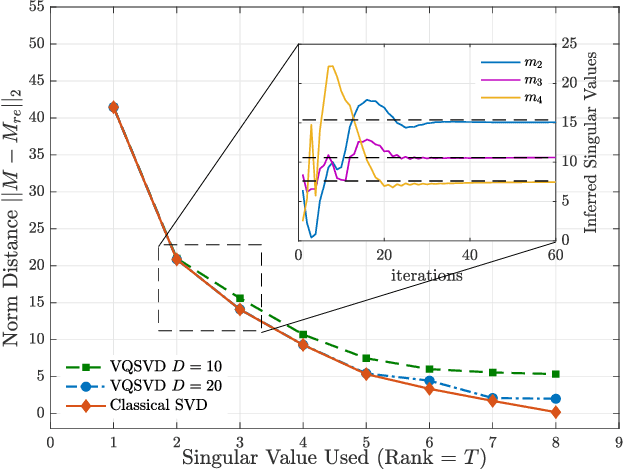
Singular value decomposition is central to many problems in both engineering and scientific fields. Several quantum algorithms have been proposed to determine the singular values and their associated singular vectors of a given matrix. Although these quantum algorithms are promising, the required quantum subroutines and resources are too costly on near-term quantum devices. In this work, we propose a variational quantum algorithm for singular value decomposition (VQSVD). By exploiting the variational principles for singular values and the Ky Fan Theorem, we design a novel loss function such that two quantum neural networks or parameterized quantum circuits could be trained to learn the singular vectors and output the corresponding singular values. We further conduct numerical simulations of the algorithm for singular-value decomposition of random matrices as well as its applications in image compression of handwritten digits. Finally, we discuss the applications of our algorithm in systems of linear equations, least squares estimation, and recommendation systems.
A Method for Estimating Reflectance map and Material using Deep Learning with Synthetic Dataset
Jan 15, 2020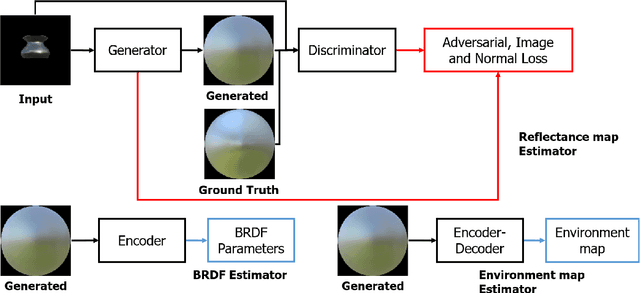
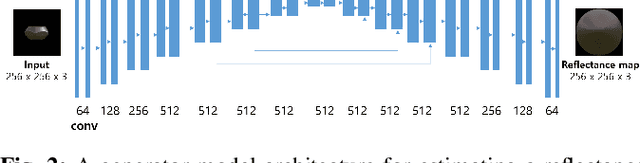
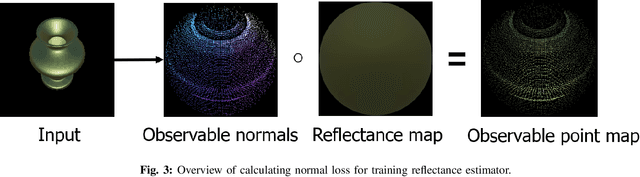
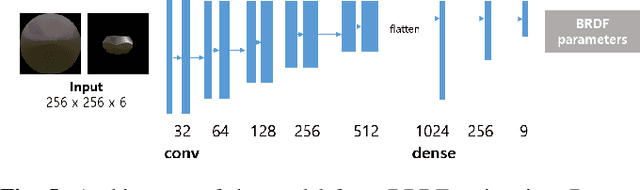
The process of decomposing target images into their internal properties is a difficult task due to the inherent ill-posed nature of the problem. The lack of data required to train a network is a one of the reasons why the decomposing appearance task is difficult. In this paper, we propose a deep learning-based reflectance map prediction system for material estimation of target objects in the image, so as to alleviate the ill-posed problem that occurs in this image decomposition operation. We also propose a network architecture for Bidirectional Reflectance Distribution Function (BRDF) parameter estimation, environment map estimation. We also use synthetic data to solve the lack of data problems. We get out of the previously proposed Deep Learning-based network architecture for reflectance map, and we newly propose to use conditional Generative Adversarial Network (cGAN) structures for estimating the reflectance map, which enables better results in many applications. To improve the efficiency of learning in this structure, we newly utilized the loss function using the normal map of the target object.
Computational Techniques in Multispectral Image Processing: Application to the Syriac Galen Palimpsest
Jan 31, 2017Multispectral and hyperspectral image analysis has experienced much development in the last decade. The application of these methods to palimpsests has produced significant results, enabling researchers to recover texts that would be otherwise lost under the visible overtext, by improving the contrast between the undertext and the overtext. In this paper we explore an extended number of multispectral and hyperspectral image analysis methods, consisting of supervised and unsupervised dimensionality reduction techniques, on a part of the Syriac Galen Palimpsest dataset (www.digitalgalen.net). Of this extended set of methods, eight methods gave good results: three were supervised methods Generalized Discriminant Analysis (GDA), Linear Discriminant Analysis (LDA), and Neighborhood Component Analysis (NCA); and the other five methods were unsupervised methods (but still used in a supervised way) Gaussian Process Latent Variable Model (GPLVM), Isomap, Landmark Isomap, Principal Component Analysis (PCA), and Probabilistic Principal Component Analysis (PPCA). The relative success of these methods was determined visually, using color pictures, on the basis of whether the undertext was distinguishable from the overtext, resulting in the following ranking of the methods: LDA, NCA, GDA, Isomap, Landmark Isomap, PPCA, PCA, and GPLVM. These results were compared with those obtained using the Canonical Variates Analysis (CVA) method on the same dataset, which showed remarkably accuracy (LDA is a particular case of CVA where the objects are classified to two classes).
Deep Learning Models for Visual Inspection on Automotive Assembling Line
Jul 02, 2020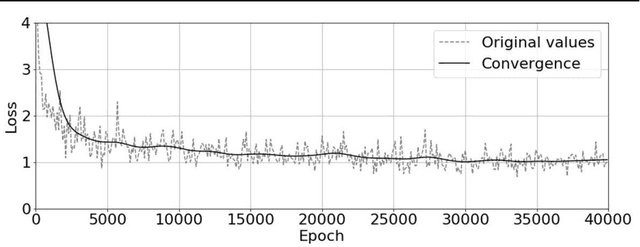

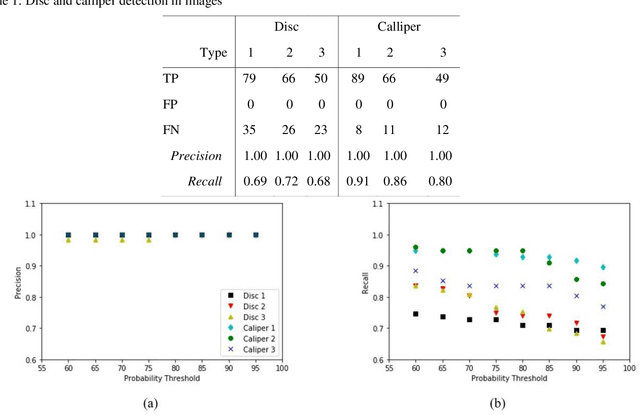

Automotive manufacturing assembly tasks are built upon visual inspections such as scratch identification on machined surfaces, part identification and selection, etc, which guarantee product and process quality. These tasks can be related to more than one type of vehicle that is produced within the same manufacturing line. Visual inspection was essentially human-led but has recently been supplemented by the artificial perception provided by computer vision systems (CVSs). Despite their relevance, the accuracy of CVSs varies accordingly to environmental settings such as lighting, enclosure and quality of image acquisition. These issues entail costly solutions and override part of the benefits introduced by computer vision systems, mainly when it interferes with the operating cycle time of the factory. In this sense, this paper proposes the use of deep learning-based methodologies to assist in visual inspection tasks while leaving very little footprints in the manufacturing environment and exploring it as an end-to-end tool to ease CVSs setup. The proposed approach is illustrated by four proofs of concept in a real automotive assembly line based on models for object detection, semantic segmentation, and anomaly detection.
* arXiv admin note: text overlap with arXiv:1802.08717, arXiv:1703.05921 by other authors
Blind Analysis of CT Image Noise Using Residual Denoised Images
May 24, 2016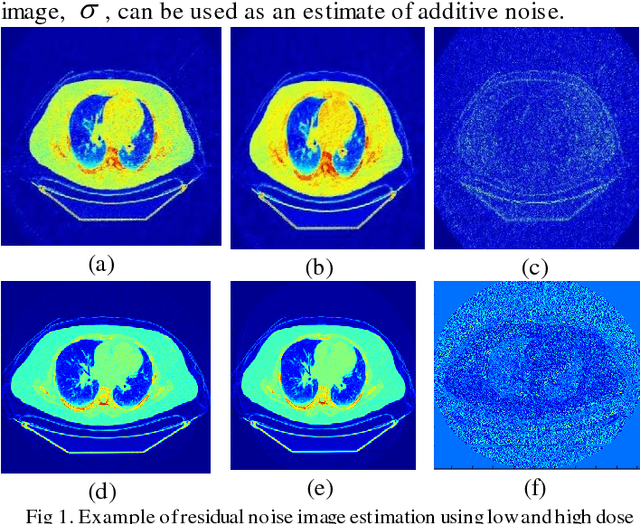
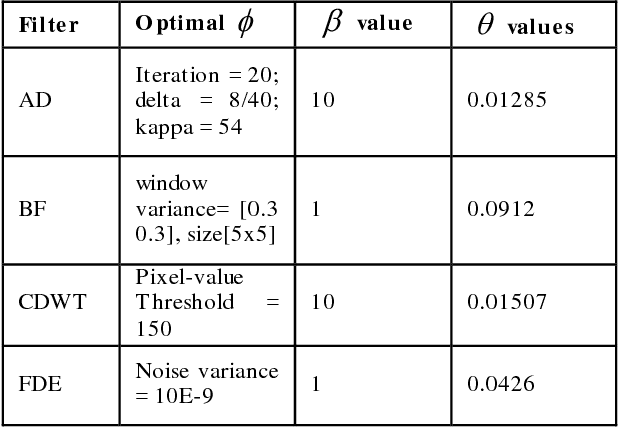
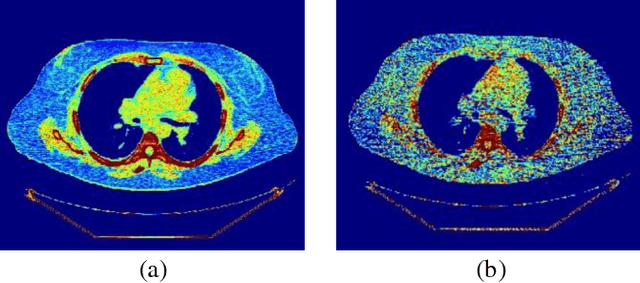
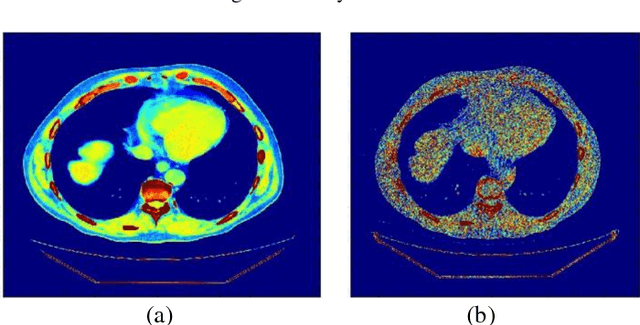
CT protocol design and quality control would benefit from automated tools to estimate the quality of generated CT images. These tools could be used to identify erroneous CT acquisitions or refine protocols to achieve certain signal to noise characteristics. This paper investigates blind estimation methods to determine global signal strength and noise levels in chest CT images. Methods: We propose novel performance metrics corresponding to the accuracy of noise and signal estimation. We implement and evaluate the noise estimation performance of six spatial- and frequency- based methods, derived from conventional image filtering algorithms. Algorithms were tested on patient data sets from whole-body repeat CT acquisitions performed with a higher and lower dose technique over the same scan region. Results: The proposed performance metrics can evaluate the relative tradeoff of filter parameters and noise estimation performance. The proposed automated methods tend to underestimate CT image noise at low-flux levels. Initial application of methodology suggests that anisotropic diffusion and Wavelet-transform based filters provide optimal estimates of noise. Furthermore, methodology does not provide accurate estimates of absolute noise levels, but can provide estimates of relative change and/or trends in noise levels.
Two-Stream CNN with Loose Pair Training for Multi-modal AMD Categorization
Jul 28, 2019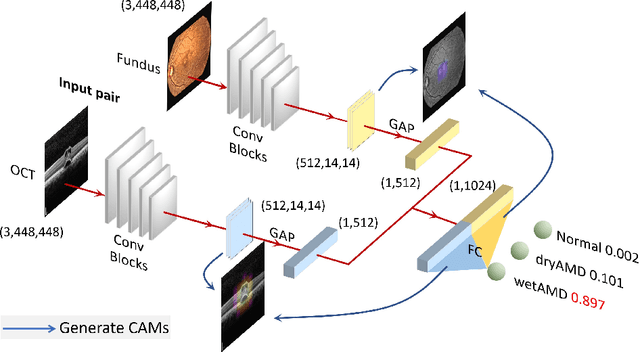

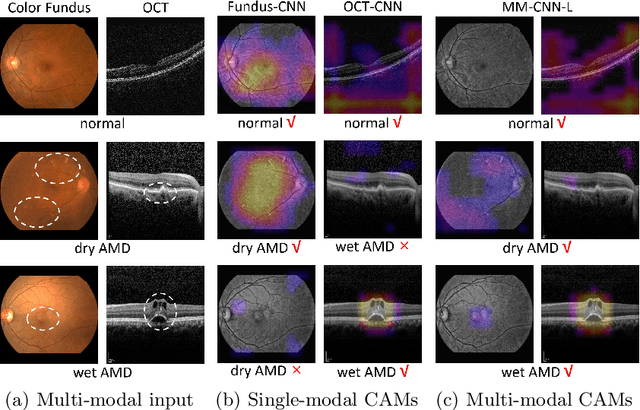
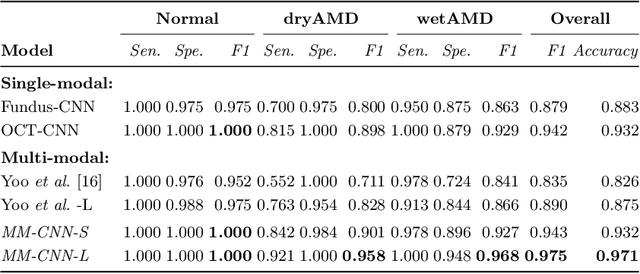
This paper studies automated categorization of age-related macular degeneration (AMD) given a multi-modal input, which consists of a color fundus image and an optical coherence tomography (OCT) image from a specific eye. Previous work uses a traditional method, comprised of feature extraction and classifier training that cannot be optimized jointly. By contrast, we propose a two-stream convolutional neural network (CNN) that is end-to-end. The CNN's fusion layer is tailored to the need of fusing information from the fundus and OCT streams. For generating more multi-modal training instances, we introduce Loose Pair training, where a fundus image and an OCT image are paired based on class labels rather than eyes. Moreover, for a visual interpretation of how the individual modalities make contributions, we extend the class activation mapping technique to the multi-modal scenario. Experiments on a real-world dataset collected from an outpatient clinic justify the viability of our proposal for multi-modal AMD categorization.
Bi-Level Image Thresholding obtained by means of Kaniadakis Entropy
Feb 22, 2015In this paper we are proposing the use of Kaniadakis entropy in the bi-level thresholding of images, in the framework of a maximum entropy principle. We discuss the role of its entropic index in determining the threshold and in driving an "image transition", that is, an abrupt transition in the appearance of the corresponding bi-level image. Some examples are proposed to illustrate the method and for comparing it to the approach which is using the Tsallis entropy.
Localization and Mapping of Sparse Geologic Features with Unpiloted Aircraft Systems
Jul 02, 2020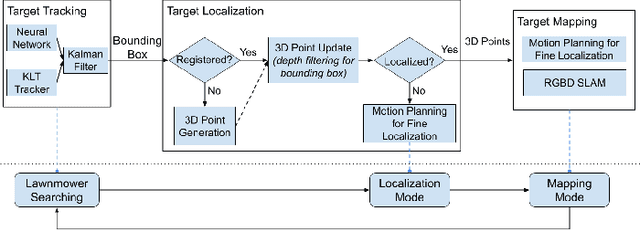

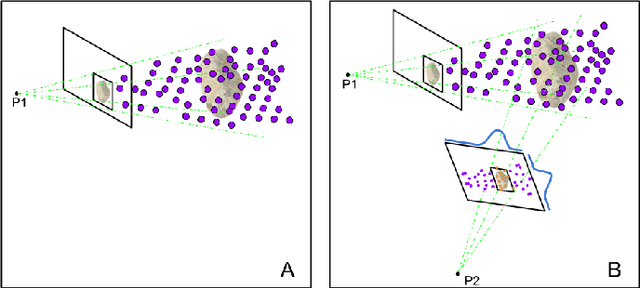
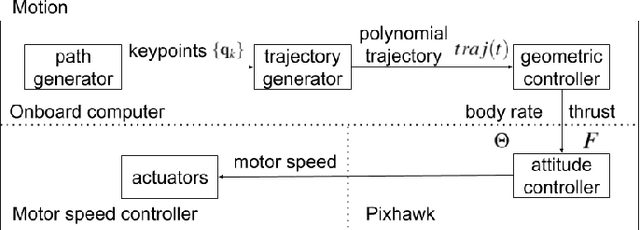
Robotic mapping is attractive in many science applications that involve environmental surveys. This paper presents a system for localization and mapping of sparsely distributed surface features such as precariously balanced rocks (PBRs), whose geometric fragility (stability) parameters provide valuable information on earthquake processes. With geomorphology as the test domain, we carry out a lawnmower search pattern using an Unpiloted Aerial Vehicle (UAV) equipped with a GPS module, stereo camera, and onboard computers. Once a target is detected by a deep neural network, we track its bounding box in the image coordinates by applying a Kalman filter that fuses the deep learning detection with KLT tracking. The target is localized in world coordinates using depth filtering where a set of 3D points are filtered by object bounding boxes from different camera perspectives. The 3D points also provide a strong prior on target shape, which is used for UAV path planning to accurately map the target using RGBD SLAM. After target mapping, the UAS resumes the lawnmower search pattern to locate the next target. Our end goal is a real-time mapping methodology for sparsely distributed surface features on earth or on extraterrestrial surfaces.
Color Image Enhancement In the Framework of Logarithmic Models
Dec 17, 2014In this paper, we propose a mathematical model for color image processing. It is a logarithmical one. We consider the cube (-1,1)x(-1,1)x(-1,1) as the set of values for the color space. We define two operations: addition <+> and real scalar multiplication <x>. With these operations the space of colors becomes a real vector space. Then, defining the scalar product (.|.) and the norm || . ||, we obtain a (logarithmic) Euclidean space. We show how we can use this model for color image enhancement and we present some experimental results.
Describing Colors, Textures and Shapes for Content Based Image Retrieval - A Survey
Feb 25, 2015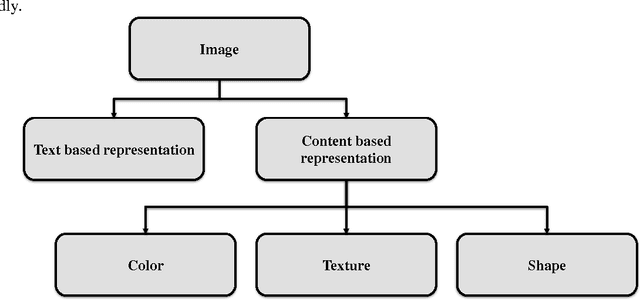
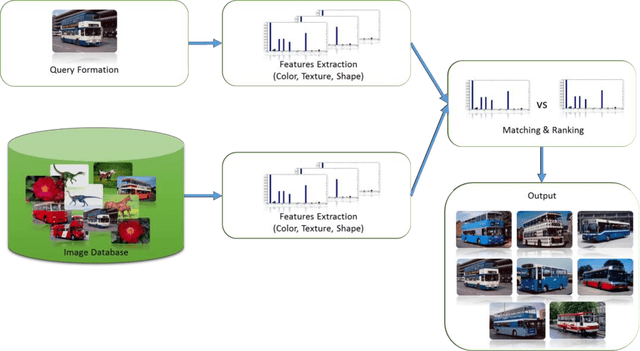
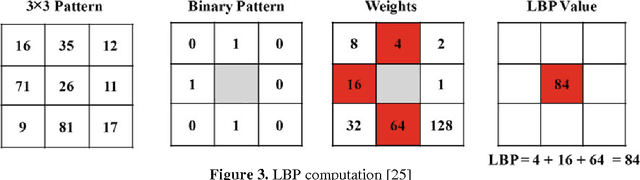
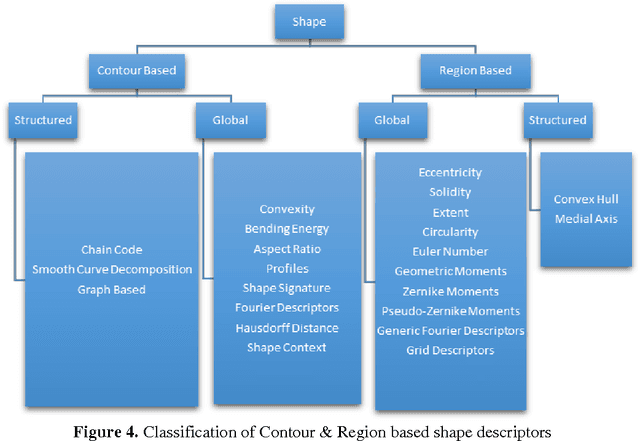
Visual media has always been the most enjoyed way of communication. From the advent of television to the modern day hand held computers, we have witnessed the exponential growth of images around us. Undoubtedly it's a fact that they carry a lot of information in them which needs be utilized in an effective manner. Hence intense need has been felt to efficiently index and store large image collections for effective and on- demand retrieval. For this purpose low-level features extracted from the image contents like color, texture and shape has been used. Content based image retrieval systems employing these features has proven very successful. Image retrieval has promising applications in numerous fields and hence has motivated researchers all over the world. New and improved ways to represent visual content are being developed each day. Tremendous amount of research has been carried out in the last decade. In this paper we will present a detailed overview of some of the powerful color, texture and shape descriptors for content based image retrieval. A comparative analysis will also be carried out for providing an insight into outstanding challenges in this field.