 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators
Jul 16, 2020
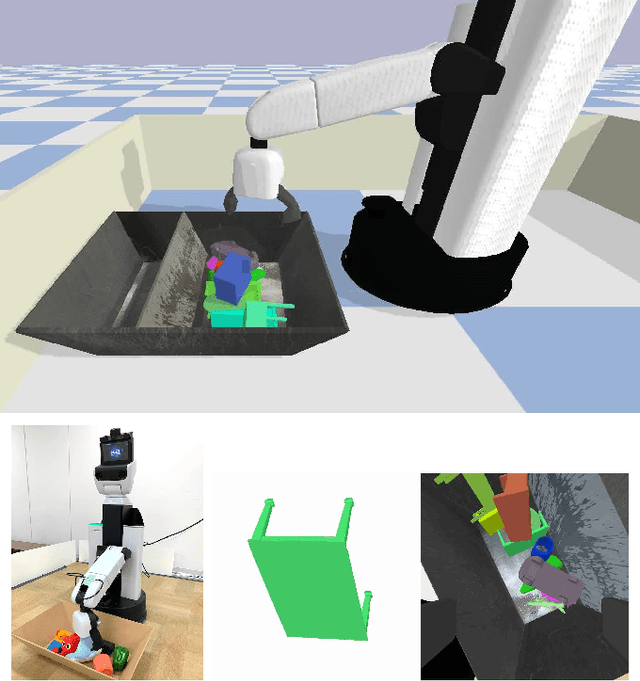
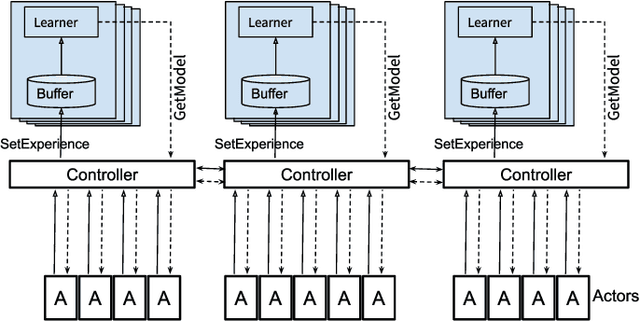
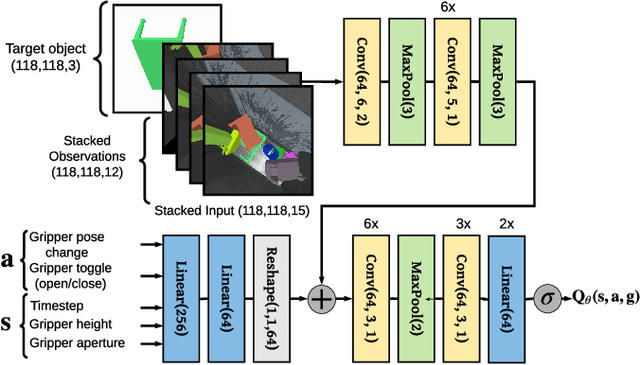
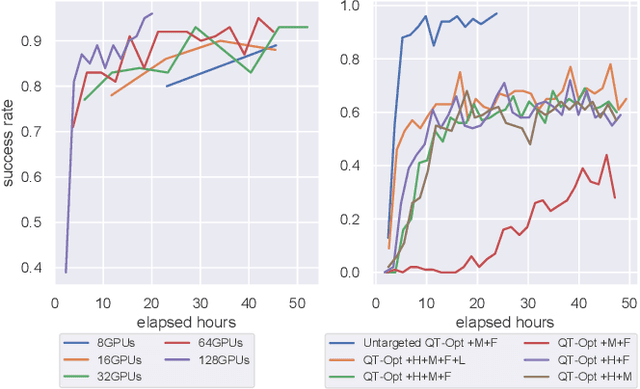
Developing personal robots that can perform a diverse range of manipulation tasks in unstructured environments necessitates solving several challenges for robotic grasping systems. We take a step towards this broader goal by presenting the first RL-based system, to our knowledge, for a mobile manipulator that can (a) achieve targeted grasping generalizing to unseen target objects, (b) learn complex grasping strategies for cluttered scenes with occluded objects, and (c) perform active vision through its movable wrist camera to better locate objects. The system is informed of the desired target object in the form of a single, arbitrary-pose RGB image of that object, enabling the system to generalize to unseen objects without retraining. To achieve such a system, we combine several advances in deep reinforcement learning and present a large-scale distributed training system using synchronous SGD that seamlessly scales to multi-node, multi-GPU infrastructure to make rapid prototyping easier. We train and evaluate our system in a simulated environment, identify key components for improving performance, analyze its behaviors, and transfer to a real-world setup.
HyperTune: Dynamic Hyperparameter Tuning For Efficient Distribution of DNN Training Over Heterogeneous Systems
Jul 16, 2020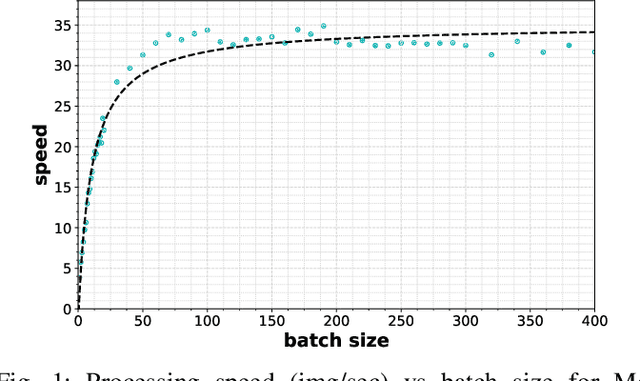
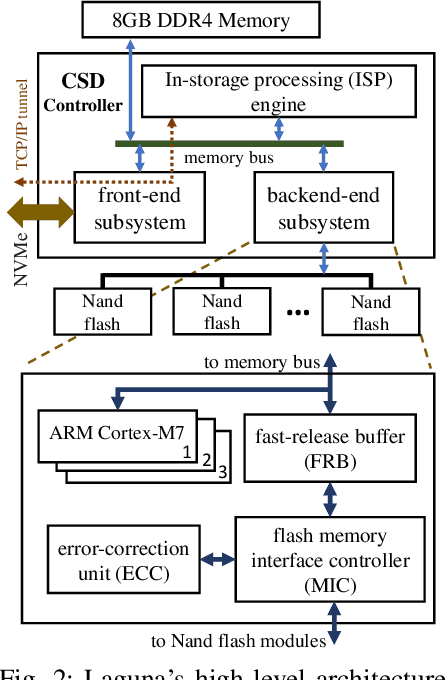
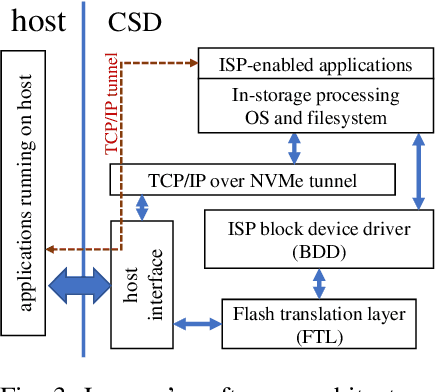

Distributed training is a novel approach to accelerate Deep Neural Networks (DNN) training, but common training libraries fall short of addressing the distributed cases with heterogeneous processors or the cases where the processing nodes get interrupted by other workloads. This paper describes distributed training of DNN on computational storage devices (CSD), which are NAND flash-based, high capacity data storage with internal processing engines. A CSD-based distributed architecture incorporates the advantages of federated learning in terms of performance scalability, resiliency, and data privacy by eliminating the unnecessary data movement between the storage device and the host processor. The paper also describes Stannis, a DNN training framework that improves on the shortcomings of existing distributed training frameworks by dynamically tuning the training hyperparameters in heterogeneous systems to maintain the maximum overall processing speed in term of processed images per second and energy efficiency. Experimental results on image classification training benchmarks show up to 3.1x improvement in performance and 2.45x reduction in energy consumption when using Stannis plus CSD compare to the generic systems.
Spatio-temporal Attention Model for Tactile Texture Recognition
Aug 10, 2020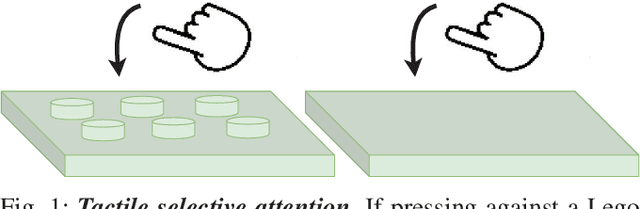
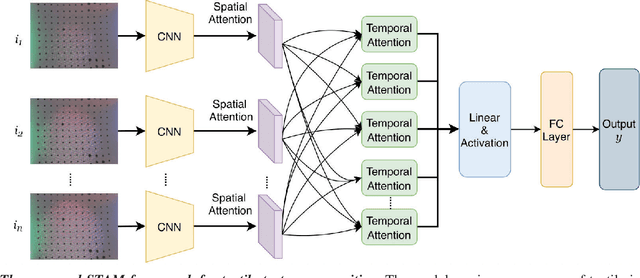
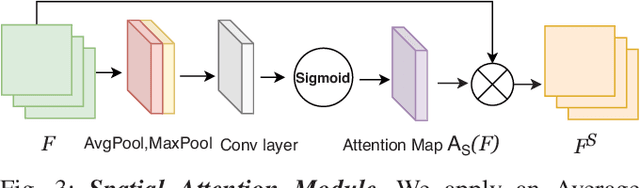
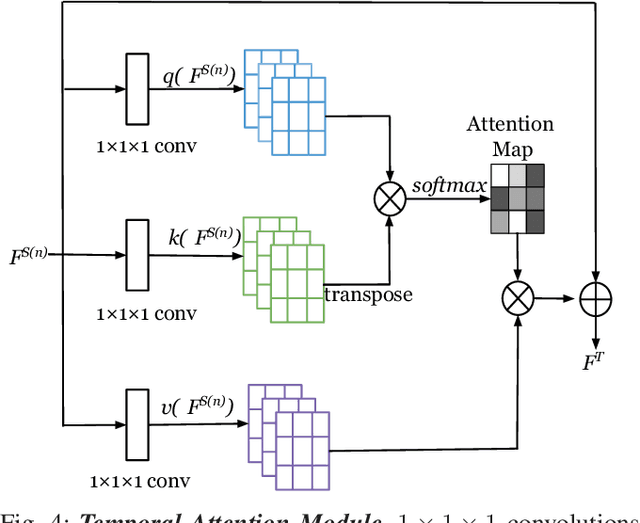
Recently, tactile sensing has attracted great interest in robotics, especially for facilitating exploration of unstructured environments and effective manipulation. A detailed understanding of the surface textures via tactile sensing is essential for many of these tasks. Previous works on texture recognition using camera based tactile sensors have been limited to treating all regions in one tactile image or all samples in one tactile sequence equally, which includes much irrelevant or redundant information. In this paper, we propose a novel Spatio-Temporal Attention Model (STAM) for tactile texture recognition, which is the very first of its kind to our best knowledge. The proposed STAM pays attention to both spatial focus of each single tactile texture and the temporal correlation of a tactile sequence. In the experiments to discriminate 100 different fabric textures, the spatially and temporally selective attention has resulted in a significant improvement of the recognition accuracy, by up to 18.8%, compared to the non-attention based models. Specifically, after introducing noisy data that is collected before the contact happens, our proposed STAM can learn the salient features efficiently and the accuracy can increase by 15.23% on average compared with the CNN based baseline approach. The improved tactile texture perception can be applied to facilitate robot tasks like grasping and manipulation.
NDD20: A large-scale few-shot dolphin dataset for coarse and fine-grained categorisation
May 27, 2020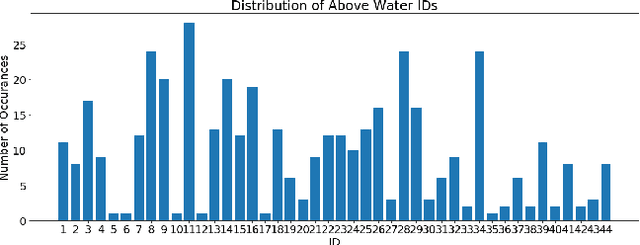

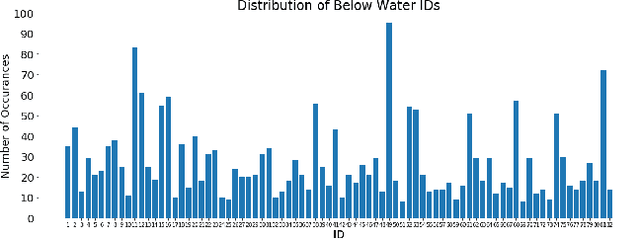

We introduce the Northumberland Dolphin Dataset 2020 (NDD20), a challenging image dataset annotated for both coarse and fine-grained instance segmentation and categorisation. This dataset, the first release of the NDD, was created in response to the rapid expansion of computer vision into conservation research and the production of field-deployable systems suited to extreme environmental conditions -- an area with few open source datasets. NDD20 contains a large collection of above and below water images of two different dolphin species for traditional coarse and fine-grained segmentation. All data contained in NDD20 was obtained via manual collection in the North Sea around the Northumberland coastline, UK. We present experimentation using standard deep learning network architecture trained using NDD20 and report baselines results.
Revisiting Modulated Convolutions for Visual Counting and Beyond
Apr 24, 2020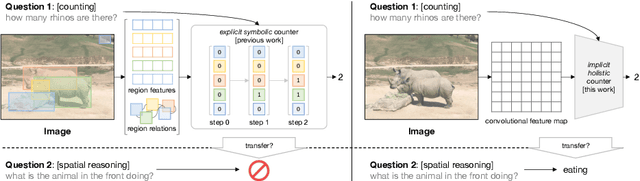
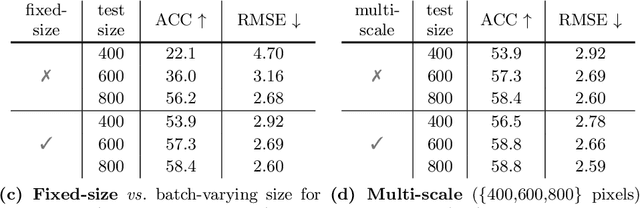
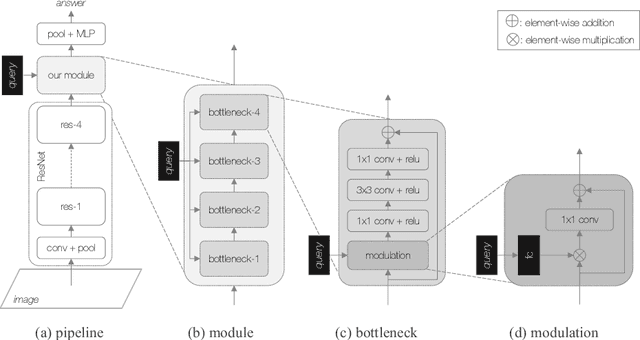
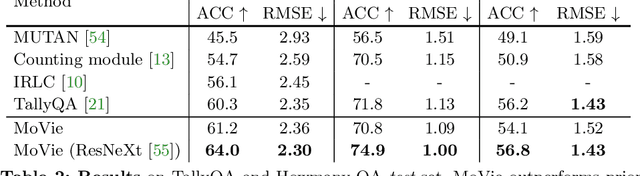
This paper targets at visual counting, where the setup is to estimate the total number of occurrences in a natural image given an input query (e.g. a question or a category). Most existing work for counting focuses on explicit, symbolic models that iteratively examine relevant regions to arrive at the final number, mimicking the intuitive process specifically for counting. However, such models can be computationally expensive, and more importantly place a limit on their generalization to other reasoning tasks. In this paper, we propose a simple and effective alternative for visual counting by revisiting modulated convolutions that fuse query and image locally. The modulation is performed on a per-bottleneck basis by fusing query representations with input convolutional feature maps of that residual bottleneck. Therefore, we call our method MoVie, short for Modulated conVolutional bottleneck. Notably, MoVie reasons implicitly and holistically for counting and only needs a single forward-pass during inference. Nevertheless, MoVie showcases strong empirical performance. First, it significantly advances the state-of-the-art accuracies on multiple counting-specific Visual Question Answering (VQA) datasets (i.e., HowMany-QA and TallyQA). Moreover, it also works on common object counting, outperforming prior-art on difficult benchmarks like COCO. Third, integrated as a module, MoVie can be used to improve number-related questions for generic VQA models. Finally, we find MoVie achieves similar, near-perfect results on CLEVR and competitive ones on GQA, suggesting modulated convolutions as a mechanism can be useful for more general reasoning tasks beyond counting.
Conditional Coupled Generative Adversarial Networks for Zero-Shot Domain Adaptation
Sep 11, 2020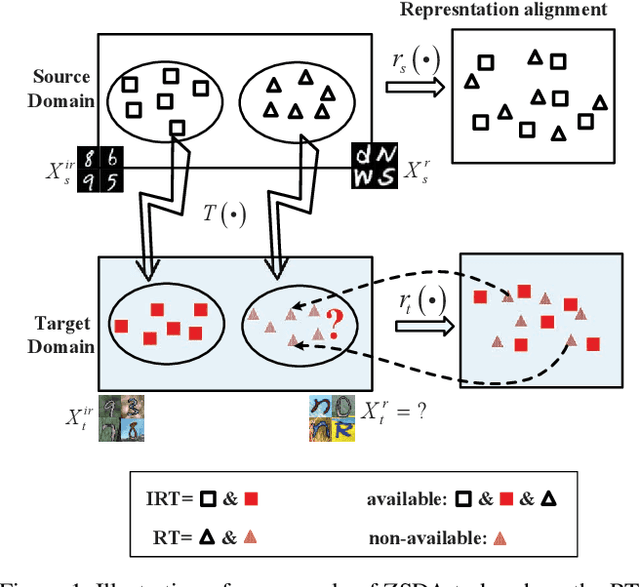
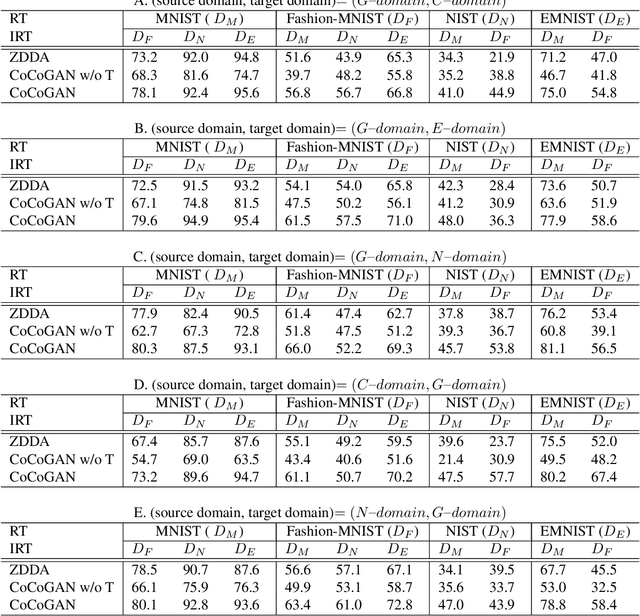
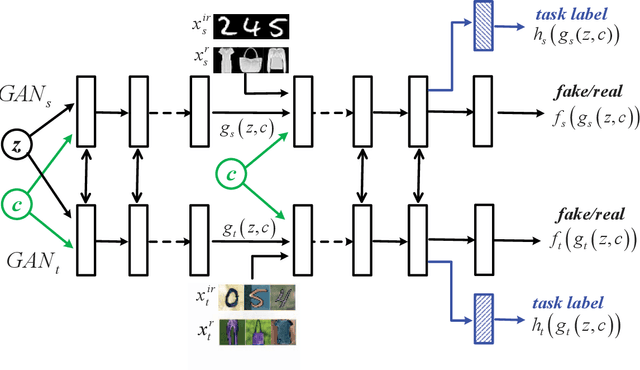

Machine learning models trained in one domain perform poorly in the other domains due to the existence of domain shift. Domain adaptation techniques solve this problem by training transferable models from the label-rich source domain to the label-scarce target domain. Unfortunately, a majority of the existing domain adaptation techniques rely on the availability of target-domain data, and thus limit their applications to a small community across few computer vision problems. In this paper, we tackle the challenging zero-shot domain adaptation (ZSDA) problem, where target-domain data is non-available in the training stage. For this purpose, we propose conditional coupled generative adversarial networks (CoCoGAN) by extending the coupled generative adversarial networks (CoGAN) into a conditioning model. Compared with the existing state of the arts, our proposed CoCoGAN is able to capture the joint distribution of dual-domain samples in two different tasks, i.e. the relevant task (RT) and an irrelevant task (IRT). We train CoCoGAN with both source-domain samples in RT and dual-domain samples in IRT to complete the domain adaptation. While the former provide high-level concepts of the non-available target-domain data, the latter carry the sharing correlation between the two domains in RT and IRT. To train CoCoGAN in the absence of target-domain data for RT, we propose a new supervisory signal, i.e. the alignment between representations across tasks. Extensive experiments carried out demonstrate that our proposed CoCoGAN outperforms existing state of the arts in image classifications.
Attention-Based Query Expansion Learning
Jul 15, 2020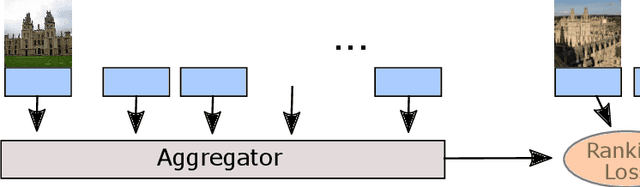

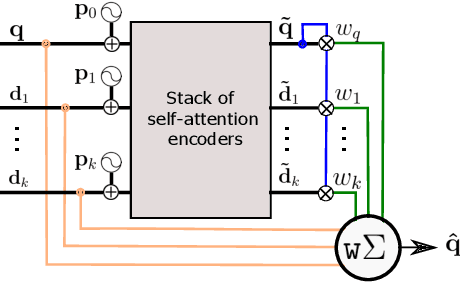
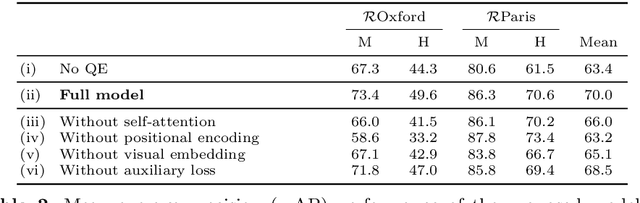
Query expansion is a technique widely used in image search consisting in combining highly ranked images from an original query into an expanded query that is then reissued, generally leading to increased recall and precision. An important aspect of query expansion is choosing an appropriate way to combine the images into a new query. Interestingly, despite the undeniable empirical success of query expansion, ad-hoc methods with different caveats have dominated the landscape, and not a lot of research has been done on learning how to do query expansion. In this paper we propose a more principled framework to query expansion, where one trains, in a discriminative manner, a model that learns how images should be aggregated to form the expanded query. Within this framework, we propose a model that leverages a self-attention mechanism to effectively learn how to transfer information between the different images before aggregating them. Our approach obtains higher accuracy than existing approaches on standard benchmarks. More importantly, our approach is the only one that consistently shows high accuracy under different regimes, overcoming caveats of existing methods.
Fast acoustic scattering using convolutional neural networks
Nov 06, 2019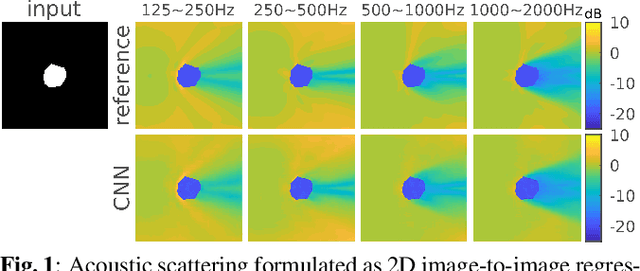
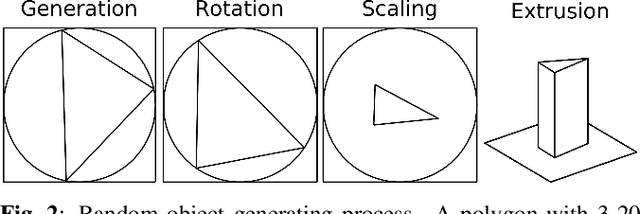
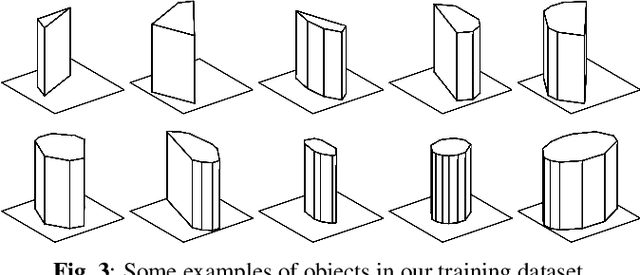
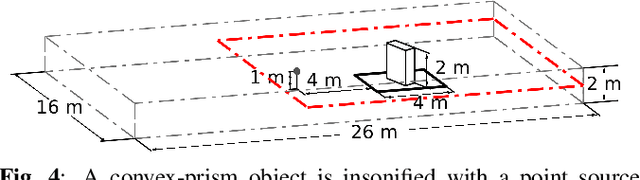
Diffracted scattering and occlusion are important acoustic effects in interactive auralization and noise control applications, typically requiring expensive numerical simulation. We propose training a convolutional neural network to map from a convex scatterer's cross-section to a 2D slice of the resulting spatial loudness distribution. We show that employing a full-resolution residual network for the resulting image-to-image regression problem yields spatially detailed loudness fields with a root-mean-squared error of less than 1 dB, at over 100* speedup compared to full wave simulation.
Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Jul 01, 2020
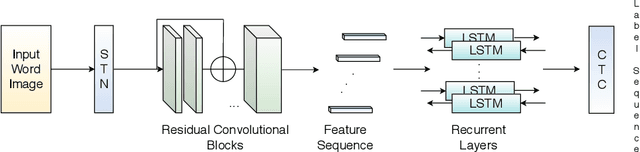

Recognition and retrieval of textual content from the large document collections have been a powerful use case for the document image analysis community. Often the word is the basic unit for recognition as well as retrieval. Systems that rely only on the text recogniser (OCR) output are not robust enough in many situations, especially when the word recognition rates are poor, as in the case of historic documents or digital libraries. An alternative has been word spotting based methods that retrieve/match words based on a holistic representation of the word. In this paper, we fuse the noisy output of text recogniser with a deep embeddings representation derived out of the entire word. We use average and max fusion for improving the ranked results in the case of retrieval. We validate our methods on a collection of Hindi documents. We improve word recognition rate by 1.4 and retrieval by 11.13 in the mAP.
Gaussian Smoothen Semantic Features (GSSF) -- Exploring the Linguistic Aspects of Visual Captioning in Indian Languages (Bengali) Using MSCOCO Framework
Feb 16, 2020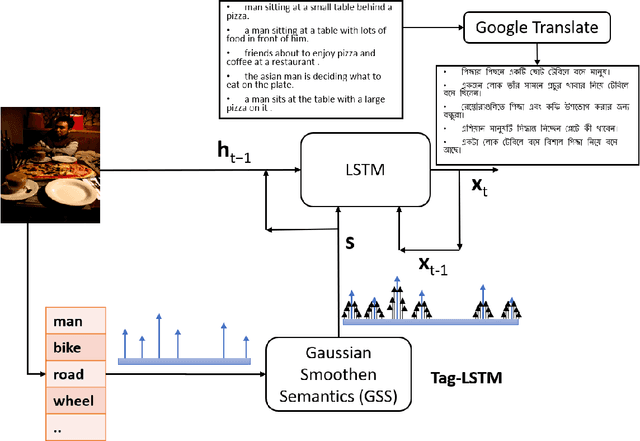

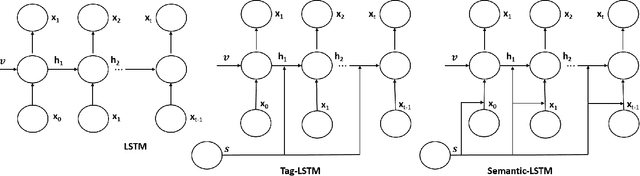
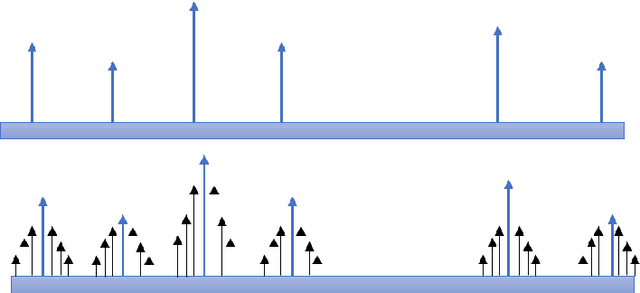
In this work, we have introduced Gaussian Smoothen Semantic Features (GSSF) for Better Semantic Selection for Indian regional language-based image captioning and introduced a procedure where we used the existing translation and English crowd-sourced sentences for training. We have shown that this architecture is a promising alternative source, where there is a crunch in resources. Our main contribution of this work is the development of deep learning architectures for the Bengali language (is the fifth widely spoken language in the world) with a completely different grammar and language attributes. We have shown that these are working well for complex applications like language generation from image contexts and can diversify the representation through introducing constraints, more extensive features, and unique feature spaces. We also established that we could achieve absolute precision and diversity when we use smoothened semantic tensor with the traditional LSTM and feature decomposition networks. With better learning architecture, we succeeded in establishing an automated algorithm and assessment procedure that can help in the evaluation of competent applications without the requirement for expertise and human intervention.