 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Geometric Texture Synthesis
Jun 30, 2020


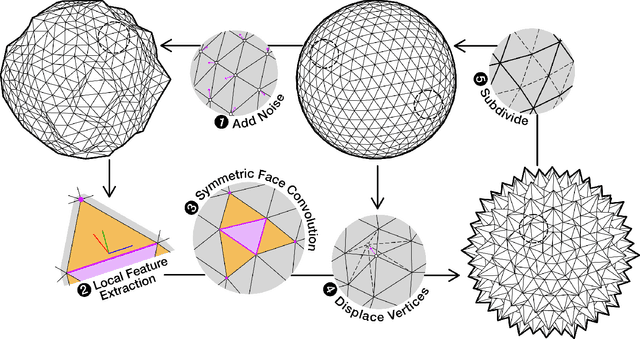
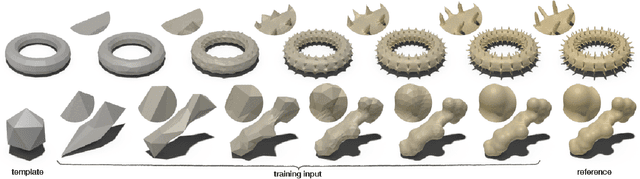
Recently, deep generative adversarial networks for image generation have advanced rapidly; yet, only a small amount of research has focused on generative models for irregular structures, particularly meshes. Nonetheless, mesh generation and synthesis remains a fundamental topic in computer graphics. In this work, we propose a novel framework for synthesizing geometric textures. It learns geometric texture statistics from local neighborhoods (i.e., local triangular patches) of a single reference 3D model. It learns deep features on the faces of the input triangulation, which is used to subdivide and generate offsets across multiple scales, without parameterization of the reference or target mesh. Our network displaces mesh vertices in any direction (i.e., in the normal and tangential direction), enabling synthesis of geometric textures, which cannot be expressed by a simple 2D displacement map. Learning and synthesizing on local geometric patches enables a genus-oblivious framework, facilitating texture transfer between shapes of different genus.
The structure of optimal parameters for image restoration problems
May 08, 2015

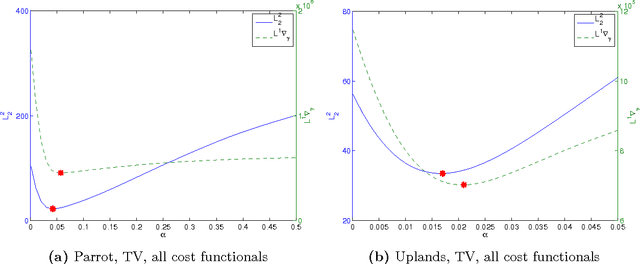
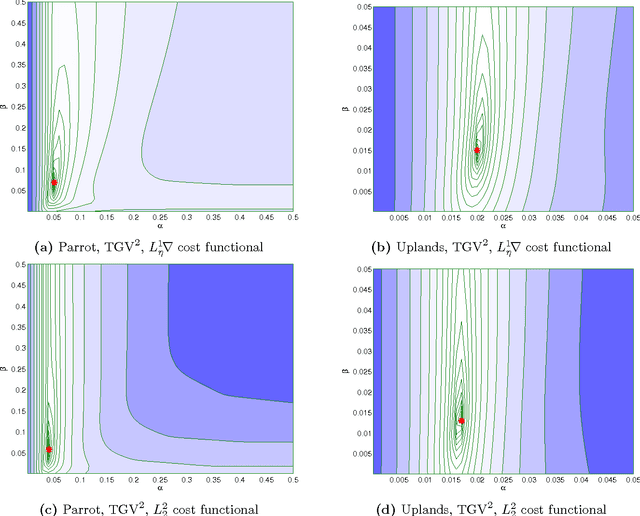
We study the qualitative properties of optimal regularisation parameters in variational models for image restoration. The parameters are solutions of bilevel optimisation problems with the image restoration problem as constraint. A general type of regulariser is considered, which encompasses total variation (TV), total generalized variation (TGV) and infimal-convolution total variation (ICTV). We prove that under certain conditions on the given data optimal parameters derived by bilevel optimisation problems exist. A crucial point in the existence proof turns out to be the boundedness of the optimal parameters away from $0$ which we prove in this paper. The analysis is done on the original -- in image restoration typically non-smooth variational problem -- as well as on a smoothed approximation set in Hilbert space which is the one considered in numerical computations. For the smoothed bilevel problem we also prove that it $\Gamma$ converges to the original problem as the smoothing vanishes. All analysis is done in function spaces rather than on the discretised learning problem.
Unsupervised Domain Adaptive Object Detection using Forward-Backward Cyclic Adaptation
Feb 03, 2020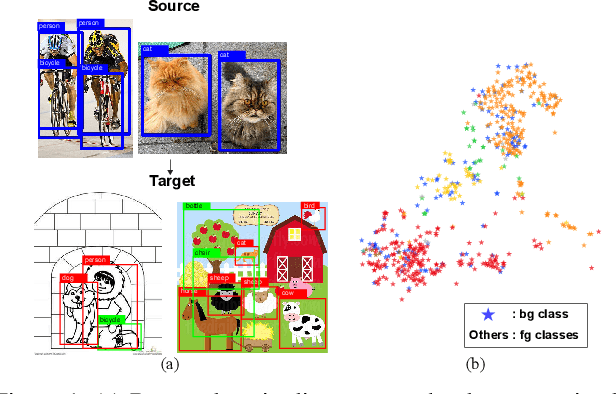

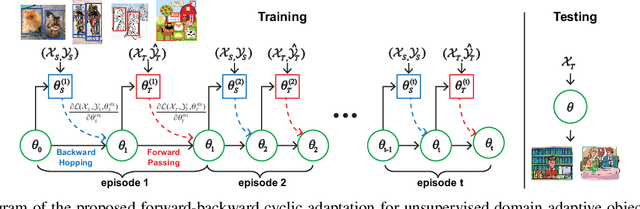
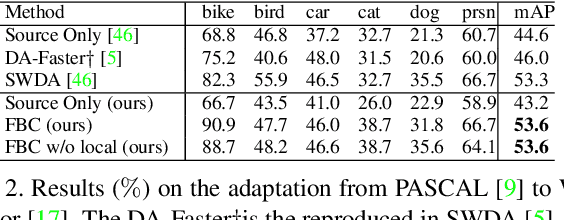
We present a novel approach to perform the unsupervised domain adaptation for object detection through forward-backward cyclic (FBC) training. Recent adversarial training based domain adaptation methods have shown their effectiveness on minimizing domain discrepancy via marginal feature distributions alignment. However, aligning the marginal feature distributions does not guarantee the alignment of class conditional distributions. This limitation is more evident when adapting object detectors as the domain discrepancy is larger compared to the image classification task, e.g. various number of objects exist in one image and the majority of content in an image is the background. This motivates us to learn domain invariance for category level semantics via gradient alignment. Intuitively, if the gradients of two domains point in similar directions, then the learning of one domain can improve that of another domain. To achieve gradient alignment, we propose Forward-Backward Cyclic Adaptation, which iteratively computes adaptation from source to target via backward hopping and from target to source via forward passing. In addition, we align low-level features for adapting holistic color/texture via adversarial training. However, the detector performs well on both domains is not ideal for target domain. As such, in each cycle, domain diversity is enforced by maximum entropy regularization on the source domain to penalize confident source-specific learning and minimum entropy regularization on target domain to intrigue target-specific learning. Theoretical analysis of the training process is provided, and extensive experiments on challenging cross-domain object detection datasets have shown the superiority of our approach over the state-of-the-art.
Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization
Aug 21, 2019
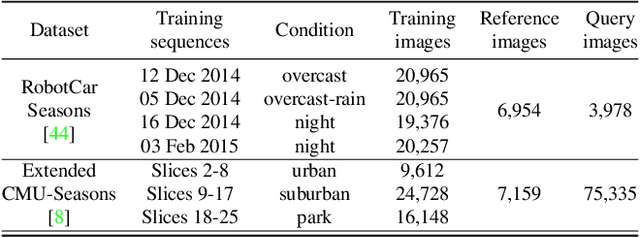
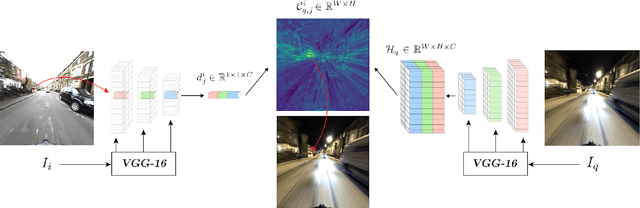
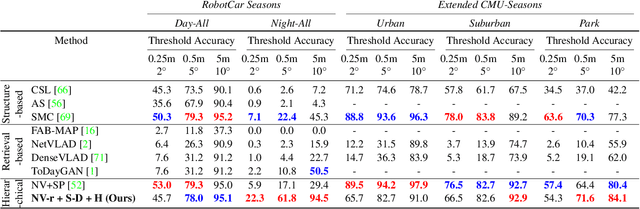
We propose a novel approach to feature point matching, suitable for robust and accurate outdoor visual localization in long-term scenarios. Given a query image, we first match it against a database of registered reference images, using recent retrieval techniques. This gives us a first estimate of the camera pose. To refine this estimate, like previous approaches, we match 2D points across the query image and the retrieved reference image. This step, however, is prone to fail as it is still very difficult to detect and match sparse feature points across images captured in potentially very different conditions. Our key contribution is to show that we need to extract sparse feature points only in the retrieved reference image: We then search for the corresponding 2D locations in the query image exhaustively. This search can be performed efficiently using convolutional operations, and robustly by using hypercolumn descriptors, i.e. image features computed for retrieval. We refer to this method as Sparse-to-Dense Hypercolumn Matching. Because we know the 3D locations of the sparse feature points in the reference images thanks to an offline reconstruction stage, it is then possible to accurately estimate the camera pose from these matches. Our experiments show that this method allows us to outperform the state-of-the-art on several challenging outdoor datasets.
Style Transfer for Light Field Photography
Feb 25, 2020
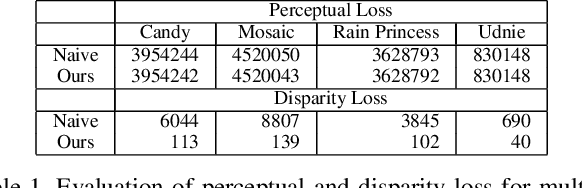

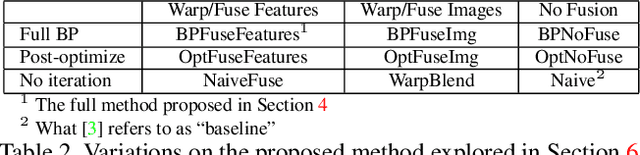
As light field images continue to increase in use and application, it becomes necessary to adapt existing image processing methods to this unique form of photography. In this paper we explore methods for applying neural style transfer to light field images. Feed-forward style transfer networks provide fast, high-quality results for monocular images, but no such networks exist for full light field images. Because of the size of these images, current light field data sets are small and are insufficient for training purely feed-forward style-transfer networks from scratch. Thus, it is necessary to adapt existing monocular style transfer networks in a way that allows for the stylization of each view of the light field while maintaining visual consistencies between views. Instead, the proposed method backpropagates the loss through the network, and the process is iterated to optimize (essentially overfit) the resulting stylization for a single light field image alone. The network architecture allows for the incorporation of pre-trained fast monocular stylization networks while avoiding the need for a large light field training set.
SCREENet: A Multi-view Deep Convolutional Neural Network for Classification of High-resolution Synthetic Mammographic Screening Scans
Sep 18, 2020
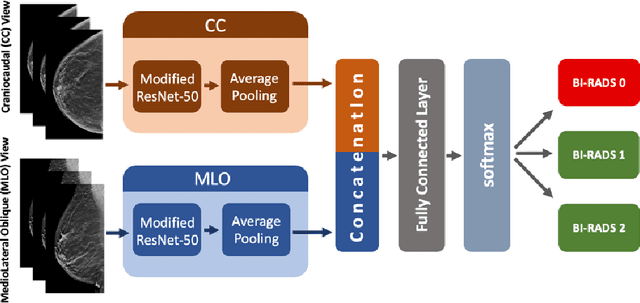
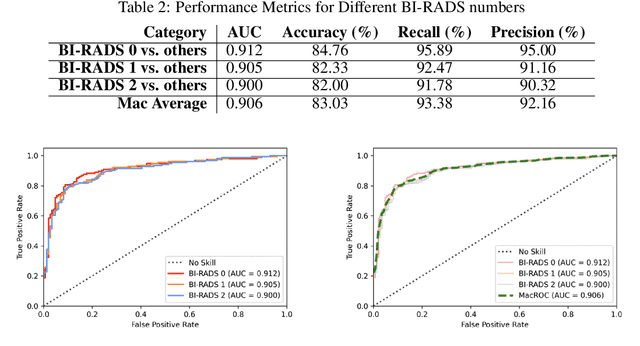
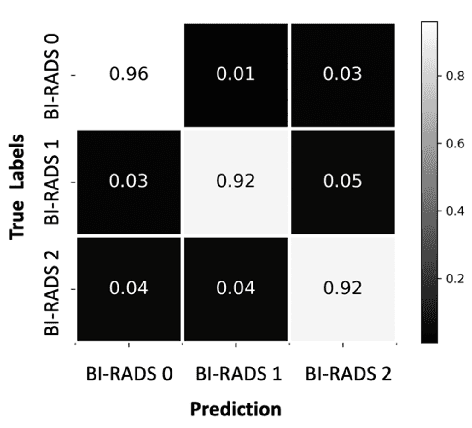
Purpose: To develop and evaluate the accuracy of a multi-view deep learning approach to the analysis of high-resolution synthetic mammograms from digital breast tomosynthesis screening cases, and to assess the effect on accuracy of image resolution and training set size. Materials and Methods: In a retrospective study, 21,264 screening digital breast tomosynthesis (DBT) exams obtained at our institution were collected along with associated radiology reports. The 2D synthetic mammographic images from these exams, with varying resolutions and data set sizes, were used to train a multi-view deep convolutional neural network (MV-CNN) to classify screening images into BI-RADS classes (BI-RADS 0, 1 and 2) before evaluation on a held-out set of exams. Results: Area under the receiver operating characteristic curve (AUC) for BI-RADS 0 vs non-BI-RADS 0 class was 0.912 for the MV-CNN trained on the full dataset. The model obtained accuracy of 84.8%, recall of 95.9% and precision of 95.0%. This AUC value decreased when the same model was trained with 50% and 25% of images (AUC = 0.877, P=0.010 and 0.834, P=0.009 respectively). Also, the performance dropped when the same model was trained using images that were under-sampled by 1/2 and 1/4 (AUC = 0.870, P=0.011 and 0.813, P=0.009 respectively). Conclusion: This deep learning model classified high-resolution synthetic mammography scans into normal vs needing further workup using tens of thousands of high-resolution images. Smaller training data sets and lower resolution images both caused significant decrease in performance.
Improving the Detection of Burnt Areas in Remote Sensing using Hyper-features Evolved by M3GP
Jan 31, 2020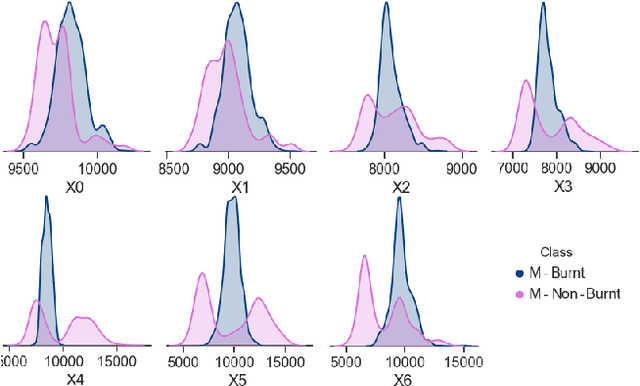
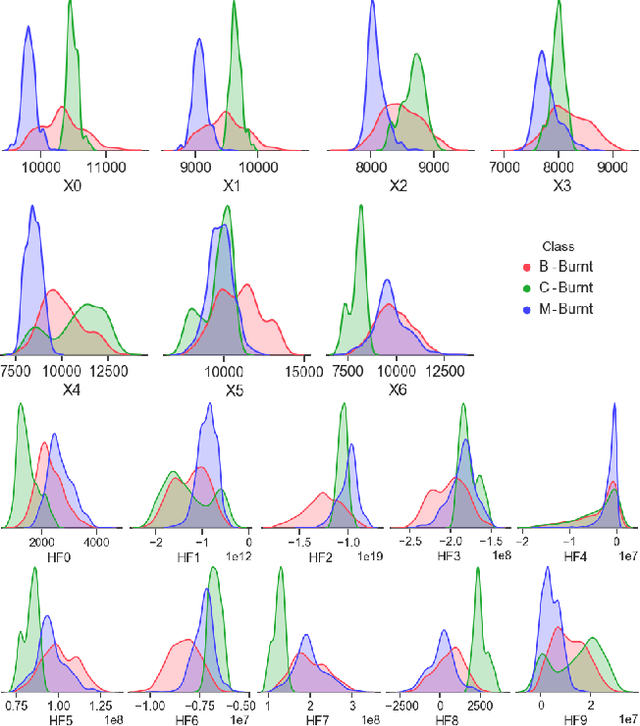
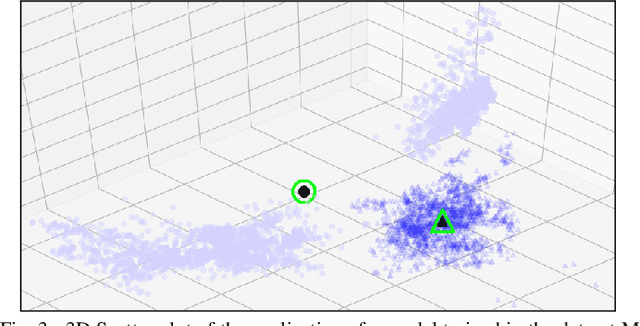
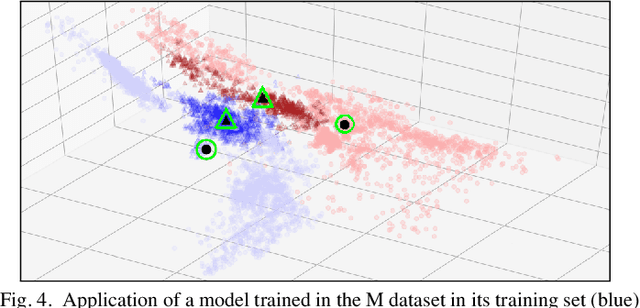
One problem found when working with satellite images is the radiometric variations across the image and different images. Intending to improve remote sensing models for the classification of burnt areas, we set two objectives. The first is to understand the relationship between feature spaces and the predictive ability of the models, allowing us to explain the differences between learning and generalization when training and testing in different datasets. We find that training on datasets built from more than one image provides models that generalize better. These results are explained by visualizing the dispersion of values on the feature space. The second objective is to evolve hyper-features that improve the performance of different classifiers on a variety of test sets. We find the hyper-features to be beneficial, and obtain the best models with XGBoost, even if the hyper-features are optimized for a different method.
Quantitative and Qualitative Evaluation of Explainable Deep Learning Methods for Ophthalmic Diagnosis
Sep 26, 2020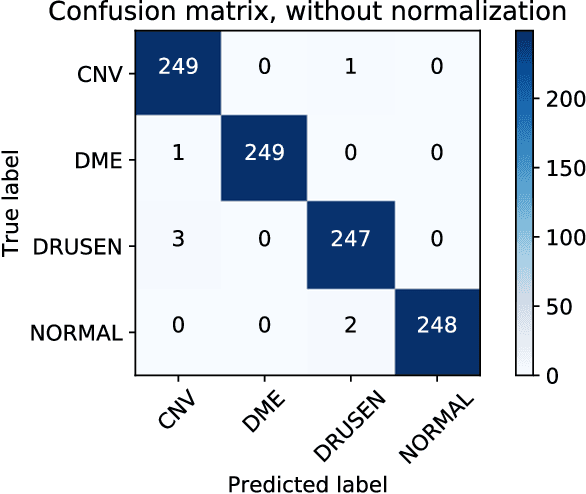
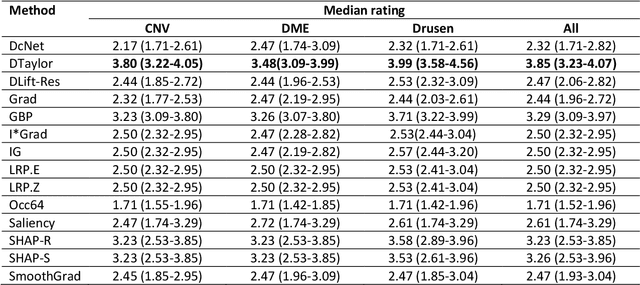
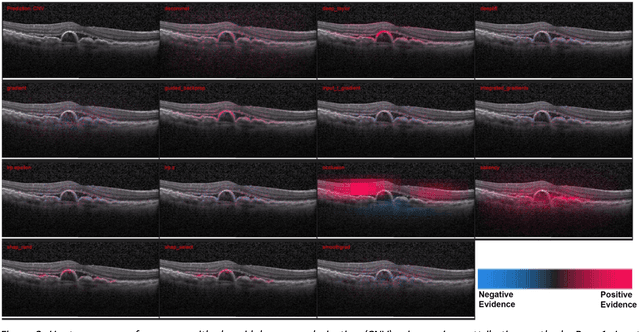
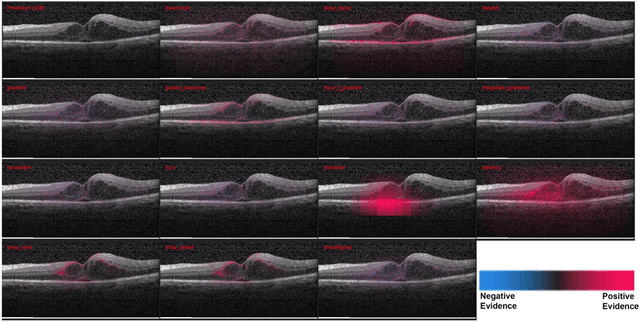
Background: The lack of explanations for the decisions made by algorithms such as deep learning has hampered their acceptance by the clinical community despite highly accurate results on multiple problems. Recently, attribution methods have emerged for explaining deep learning models, and they have been tested on medical imaging problems. The performance of attribution methods is compared on standard machine learning datasets and not on medical images. In this study, we perform a comparative analysis to determine the most suitable explainability method for retinal OCT diagnosis. Methods: A commonly used deep learning model known as Inception v3 was trained to diagnose 3 retinal diseases - choroidal neovascularization (CNV), diabetic macular edema (DME), and drusen. The explanations from 13 different attribution methods were rated by a panel of 14 clinicians for clinical significance. Feedback was obtained from the clinicians regarding the current and future scope of such methods. Results: An attribution method based on a Taylor series expansion, called Deep Taylor was rated the highest by clinicians with a median rating of 3.85/5. It was followed by two other attribution methods, Guided backpropagation and SHAP (SHapley Additive exPlanations). Conclusion: Explanations of deep learning models can make them more transparent for clinical diagnosis. This study compared different explanations methods in the context of retinal OCT diagnosis and found that the best performing method may not be the one considered best for other deep learning tasks. Overall, there was a high degree of acceptance from the clinicians surveyed in the study. Keywords: explainable AI, deep learning, machine learning, image processing, Optical coherence tomography, retina, Diabetic macular edema, Choroidal Neovascularization, Drusen
MCU-Net: A framework towards uncertainty representations for decision support system patient referrals in healthcare contexts
Jul 08, 2020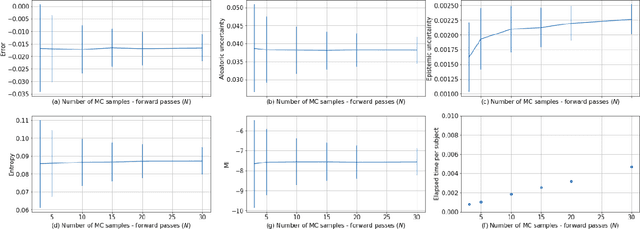
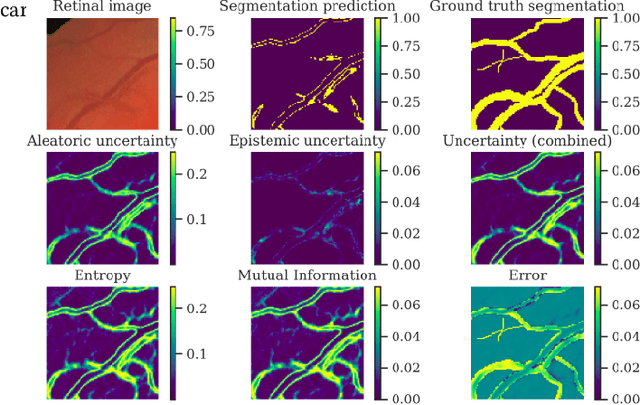
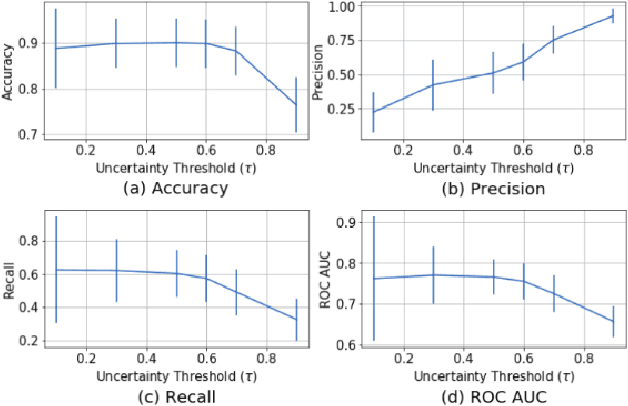
Incorporating a human-in-the-loop system when deploying automated decision support is critical in healthcare contexts to create trust, as well as provide reliable performance on a patient-to-patient basis. Deep learning methods while having high performance, do not allow for this patient-centered approach due to the lack of uncertainty representation. Thus, we present a framework of uncertainty representation evaluated for medical image segmentation, using MCU-Net which combines a U-Net with Monte Carlo Dropout, evaluated with four different uncertainty metrics. The framework augments this by adding a human-in-the-loop aspect based on an uncertainty threshold for automated referral of uncertain cases to a medical professional. We demonstrate that MCU-Net combined with epistemic uncertainty and an uncertainty threshold tuned for this application maximizes automated performance on an individual patient level, yet refers truly uncertain cases. This is a step towards uncertainty representations when deploying machine learning based decision support in healthcare settings.
Smart Hypothesis Generation for Efficient and Robust Room Layout Estimation
Oct 27, 2019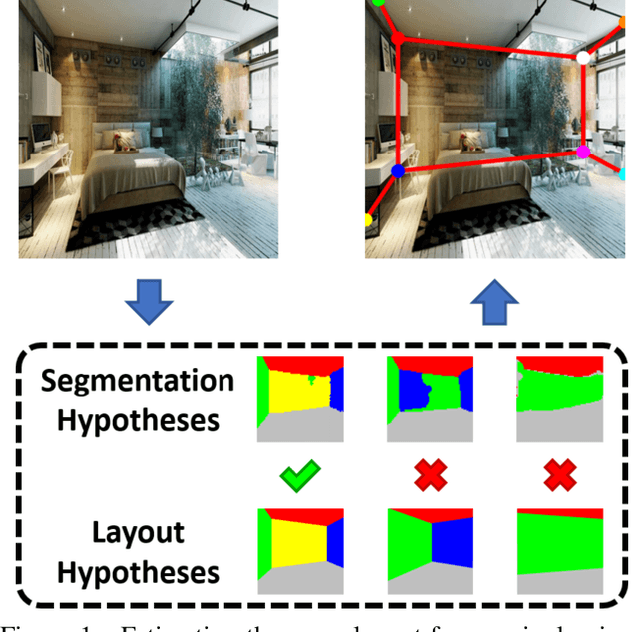
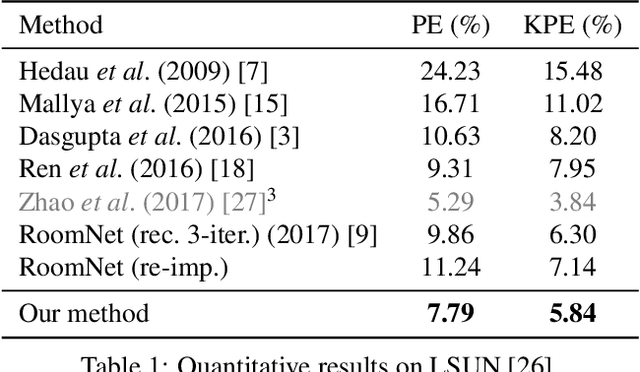

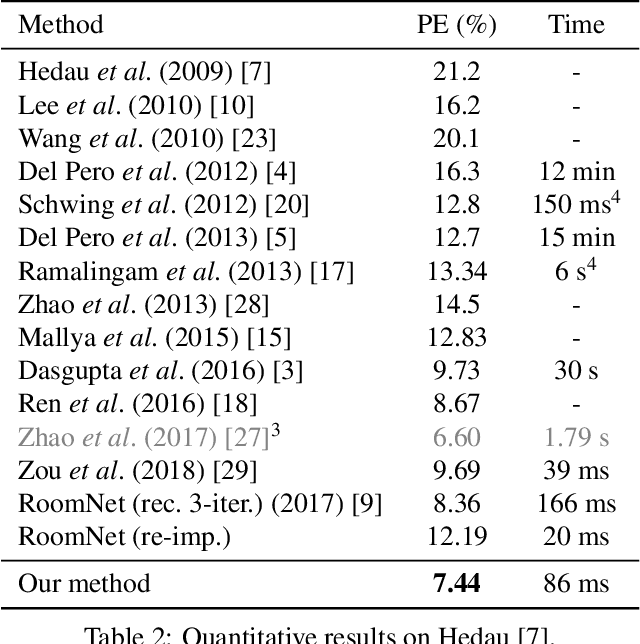
We propose a novel method to efficiently estimate the spatial layout of a room from a single monocular RGB image. As existing approaches based on low-level feature extraction, followed by a vanishing point estimation are very slow and often unreliable in realistic scenarios, we build on semantic segmentation of the input image. To obtain better segmentations, we introduce a robust, accurate and very efficient hypothesize-and-test scheme. The key idea is to use three segmentation hypotheses, each based on a different number of visible walls. For each hypothesis, we predict the image locations of the room corners and select the hypothesis for which the layout estimated from the room corners is consistent with the segmentation. We demonstrate the efficiency and robustness of our method on three challenging benchmark datasets, where we significantly outperform the state-of-the-art.