 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Dermoscopic Image Segmentation with Enhanced Convolutional-Deconvolutional Networks
Sep 28, 2017
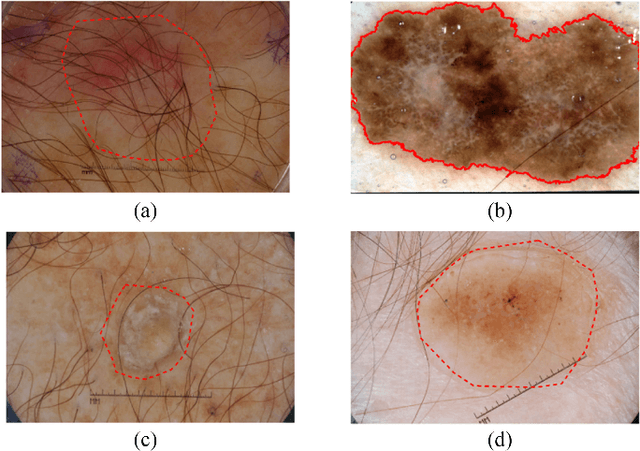
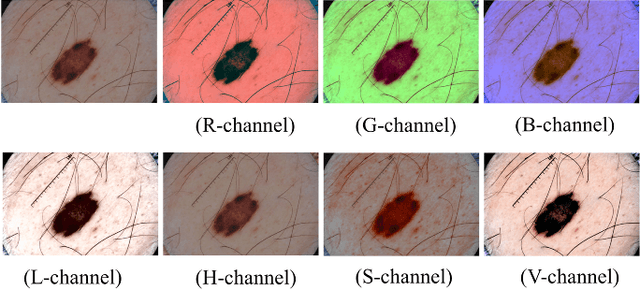
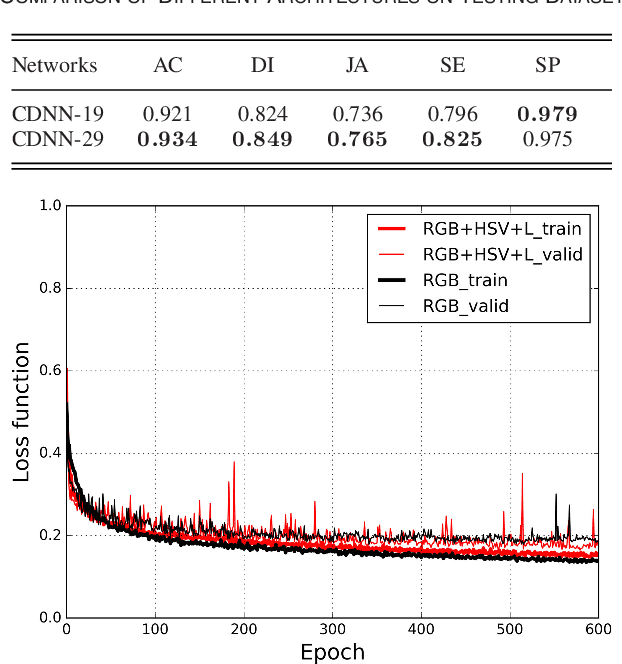
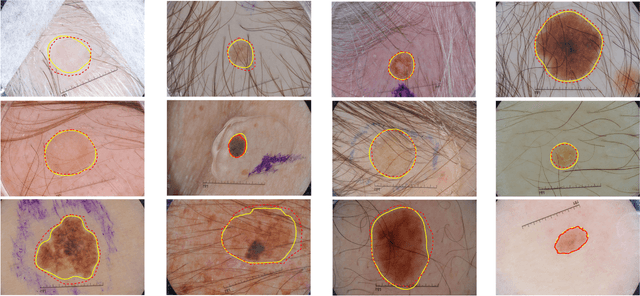
Automatic skin lesion segmentation on dermoscopic images is an essential step in computer-aided diagnosis of melanoma. However, this task is challenging due to significant variations of lesion appearances across different patients. This challenge is further exacerbated when dealing with a large amount of image data. In this paper, we extended our previous work by developing a deeper network architecture with smaller kernels to enhance its discriminant capacity. In addition, we explicitly included color information from multiple color spaces to facilitate network training and thus to further improve the segmentation performance. We extensively evaluated our method on the ISBI 2017 skin lesion segmentation challenge. By training with the 2000 challenge training images, our method achieved an average Jaccard Index (JA) of 0.765 on the 600 challenge testing images, which ranked itself in the first place in the challenge
Self-Driving Car Steering Angle Prediction Based on Image Recognition
Dec 11, 2019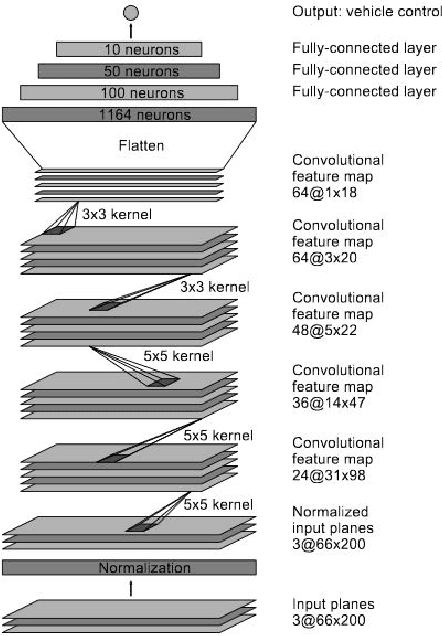
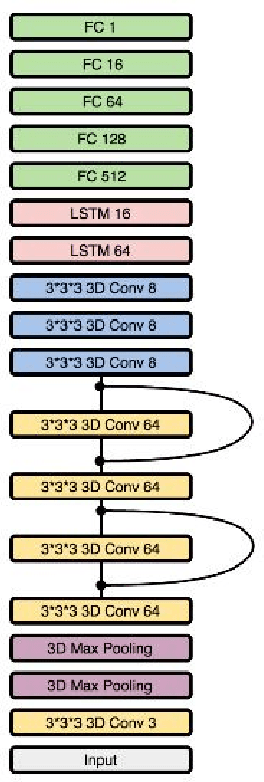
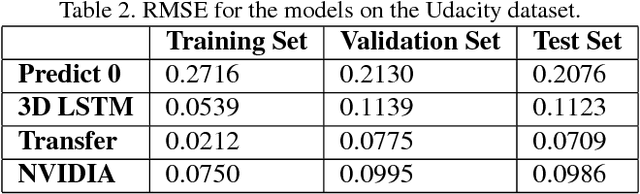
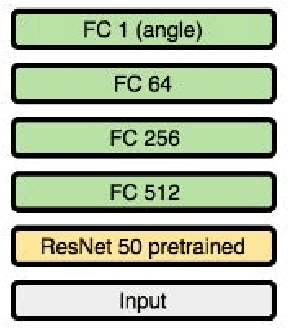
Self-driving vehicles have expanded dramatically over the last few years. Udacity has release a dataset containing, among other data, a set of images with the steering angle captured during driving. The Udacity challenge aimed to predict steering angle based on only the provided images. We explore two different models to perform high quality prediction of steering angles based on images using different deep learning techniques including Transfer Learning, 3D CNN, LSTM and ResNet. If the Udacity challenge was still ongoing, both of our models would have placed in the top ten of all entries.
Deep Learning of Dynamic Subsurface Flow via Theory-guided Generative Adversarial Network
Jun 02, 2020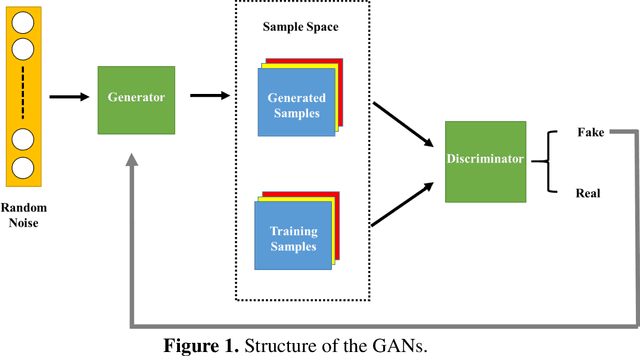

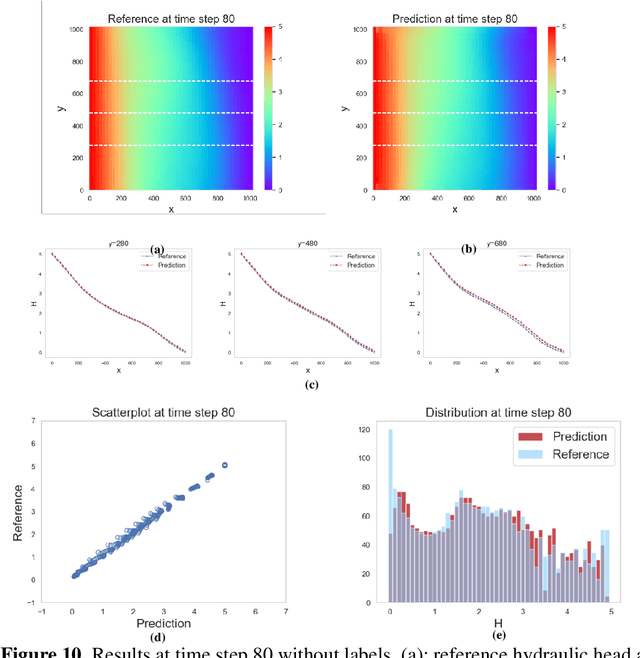
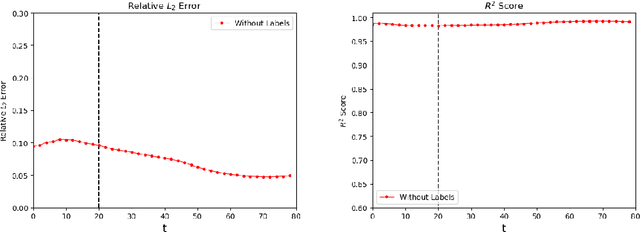
Generative adversarial network (GAN) has been shown to be useful in various applications, such as image recognition, text processing and scientific computing, due its strong ability to learn complex data distributions. In this study, a theory-guided generative adversarial network (TgGAN) is proposed to solve dynamic partial differential equations (PDEs). Different from standard GANs, the training term is no longer the true data and the generated data, but rather their residuals. In addition, such theories as governing equations, other physical constraints and engineering controls, are encoded into the loss function of the generator to ensure that the prediction does not only honor the training data, but also obey these theories. TgGAN is proposed for dynamic subsurface flow with heterogeneous model parameters, and the data at each time step are treated as a two-dimensional image. In this study, several numerical cases are introduced to test the performance of the TgGAN. Predicting the future response, label-free learning and learning from noisy data can be realized easily by the TgGAN model. The effects of the number of training data and the collocation points are also discussed. In order to improve the efficiency of TgGAN, the transfer learning algorithm is also employed. Numerical results demonstrate that the TgGAN model is robust and reliable for deep learning of dynamic PDEs.
Pixel-wise Conditioning of Generative Adversarial Networks
Nov 02, 2019
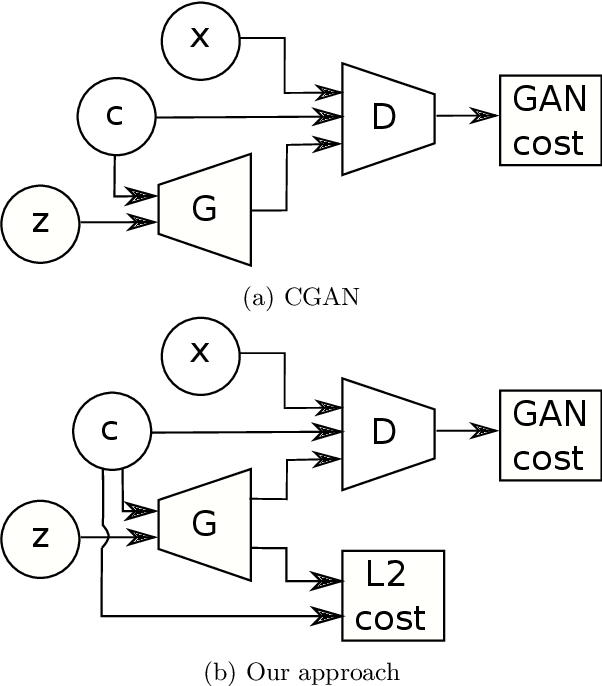
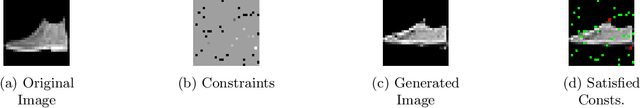
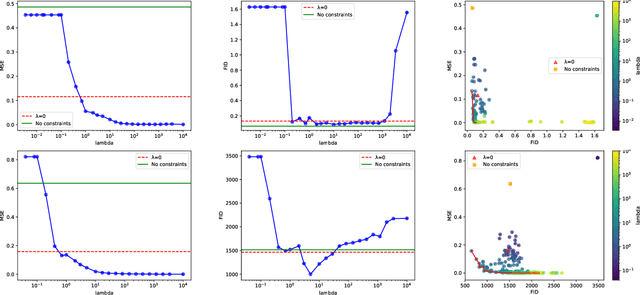
Generative Adversarial Networks (GANs) have proven successful for unsupervised image generation. Several works extended GANs to image inpainting by conditioning the generation with parts of the image one wants to reconstruct. However, these methods have limitations in settings where only a small subset of the image pixels is known beforehand. In this paper, we study the effectiveness of conditioning GANs by adding an explicit regularization term to enforce pixel-wise conditions when very few pixel values are provided. In addition, we also investigate the influence of this regularization term on the quality of the generated images and the satisfaction of the conditions. Conducted experiments on MNIST and FashionMNIST show evidence that this regularization term allows for controlling the trade-off between quality of the generated images and constraint satisfaction.
Generating Binary Tags for Fast Medical Image Retrieval Based on Convolutional Nets and Radon Transform
Apr 16, 2016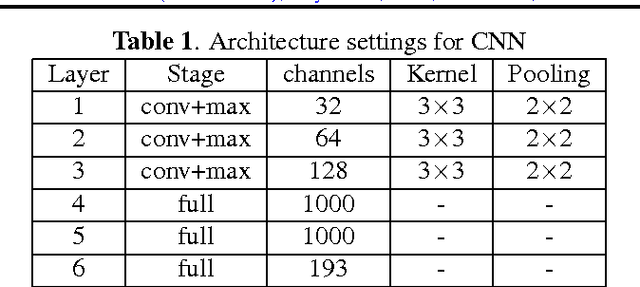
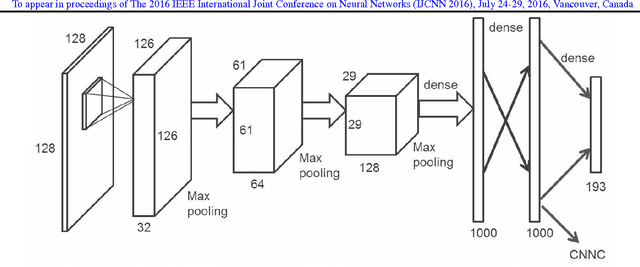
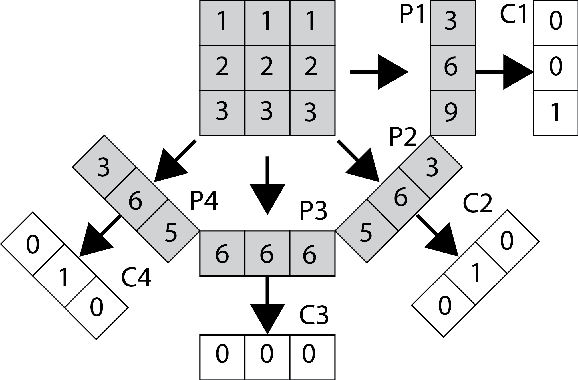
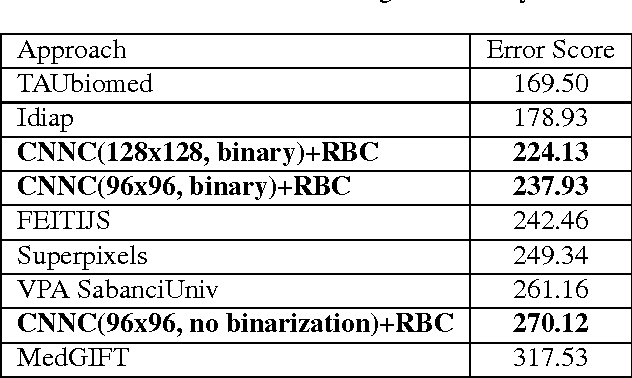
Content-based image retrieval (CBIR) in large medical image archives is a challenging and necessary task. Generally, different feature extraction methods are used to assign expressive and invariant features to each image such that the search for similar images comes down to feature classification and/or matching. The present work introduces a new image retrieval method for medical applications that employs a convolutional neural network (CNN) with recently introduced Radon barcodes. We combine neural codes for global classification with Radon barcodes for the final retrieval. We also examine image search based on regions of interest (ROI) matching after image retrieval. The IRMA dataset with more than 14,000 x-rays images is used to evaluate the performance of our method. Experimental results show that our approach is superior to many published works.
MHSA-Net: Multi-Head Self-Attention Network for Occluded Person Re-Identification
Aug 11, 2020
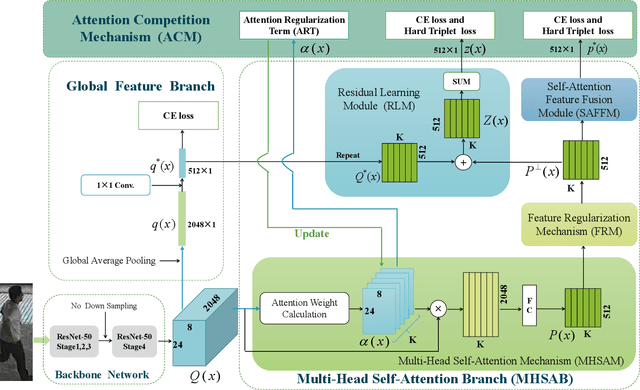
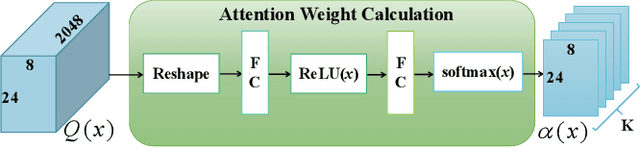
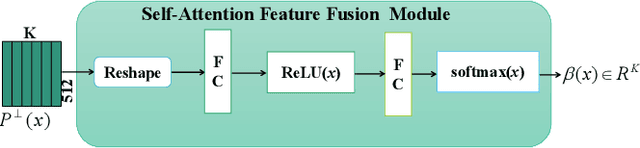
This paper presents a novel person re-identification model, named Multi-Head Self-Attention Network (MHSA-Net), to prune unimportant information and capture key local information from person images. MHSA-Net contains two main novel components: Multi-Head Self-Attention Branch (MHSAB) and Attention Competition Mechanism (ACM). The MHSAM adaptively captures key local person information, and then produces effective diversity embeddings of an image for the person matching. The ACM further helps filter out attention noise and non-key information. Through extensive ablation studies, we verified that the Structured Self-Attention Branch and Attention Competition Mechanism both contribute to the performance improvement of the MHSA-Net. Our MHSA-Net achieves state-of-the-art performance especially on images with occlusions. We have released our models (and will release the source codes after the paper is accepted) on https://github.com/hongchenphd/MHSA-Net.
Orientation-aware Vehicle Re-identification with Semantics-guided Part Attention Network
Aug 26, 2020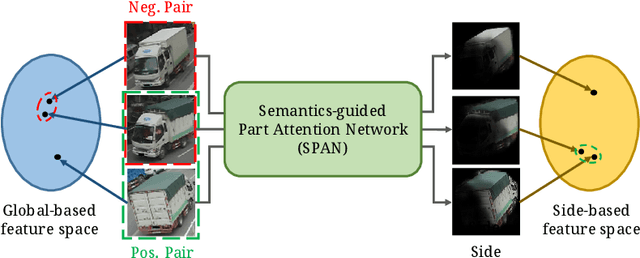


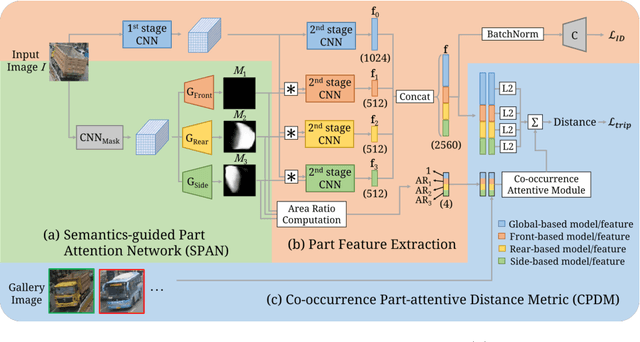
Vehicle re-identification (re-ID) focuses on matching images of the same vehicle across different cameras. It is fundamentally challenging because differences between vehicles are sometimes subtle. While several studies incorporate spatial-attention mechanisms to help vehicle re-ID, they often require expensive keypoint labels or suffer from noisy attention mask if not trained with expensive labels. In this work, we propose a dedicated Semantics-guided Part Attention Network (SPAN) to robustly predict part attention masks for different views of vehicles given only image-level semantic labels during training. With the help of part attention masks, we can extract discriminative features in each part separately. Then we introduce Co-occurrence Part-attentive Distance Metric (CPDM) which places greater emphasis on co-occurrence vehicle parts when evaluating the feature distance of two images. Extensive experiments validate the effectiveness of the proposed method and show that our framework outperforms the state-of-the-art approaches.
Label Efficient Visual Abstractions for Autonomous Driving
May 20, 2020
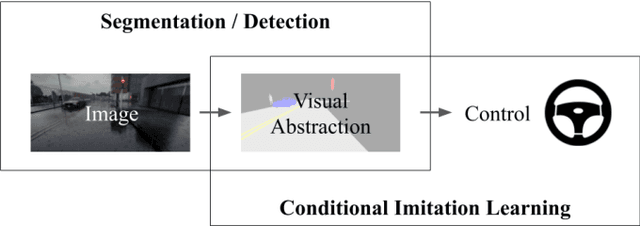
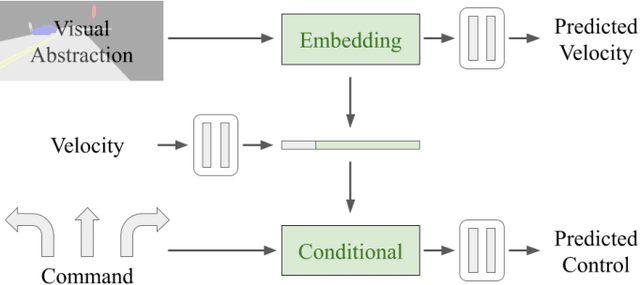
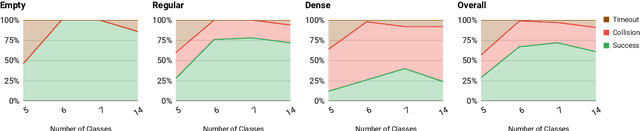
It is well known that semantic segmentation can be used as an effective intermediate representation for learning driving policies. However, the task of street scene semantic segmentation requires expensive annotations. Furthermore, segmentation algorithms are often trained irrespective of the actual driving task, using auxiliary image-space loss functions which are not guaranteed to maximize driving metrics such as safety or distance traveled per intervention. In this work, we seek to quantify the impact of reducing segmentation annotation costs on learned behavior cloning agents. We analyze several segmentation-based intermediate representations. We use these visual abstractions to systematically study the trade-off between annotation efficiency and driving performance, i.e., the types of classes labeled, the number of image samples used to learn the visual abstraction model, and their granularity (e.g., object masks vs. 2D bounding boxes). Our analysis uncovers several practical insights into how segmentation-based visual abstractions can be exploited in a more label efficient manner. Surprisingly, we find that state-of-the-art driving performance can be achieved with orders of magnitude reduction in annotation cost. Beyond label efficiency, we find several additional training benefits when leveraging visual abstractions, such as a significant reduction in the variance of the learned policy when compared to state-of-the-art end-to-end driving models.
Distributed Learning and Inference with Compressed Images
Apr 22, 2020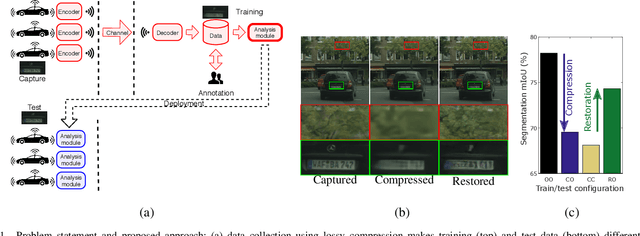
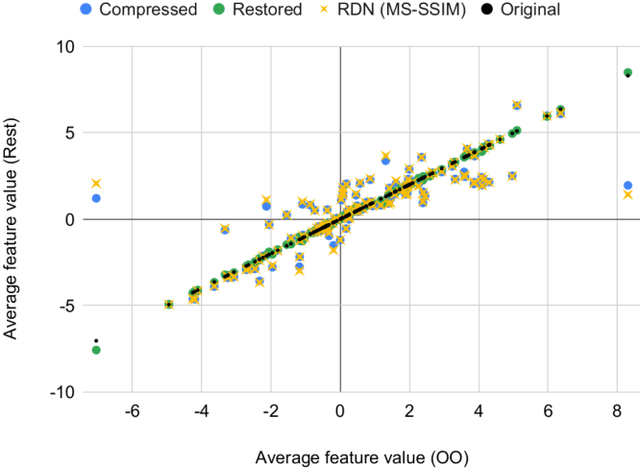

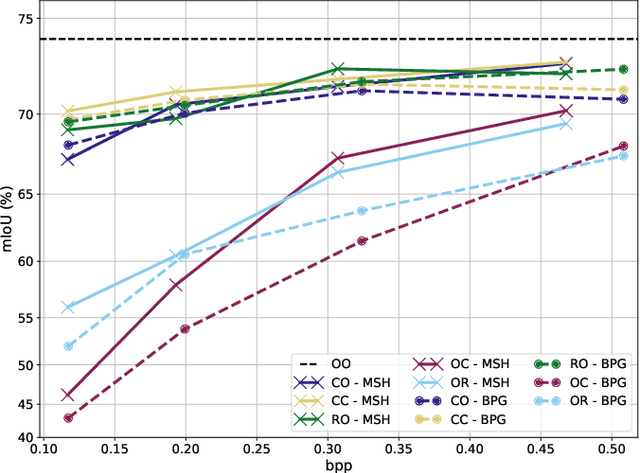
Modern computer vision requires processing large amounts of data, both while training the model and/or during inference, once the model is deployed. Scenarios where images are captured and processed in physically separated locations are increasingly common (e.g. autonomous vehicles, cloud computing). In addition, many devices suffer from limited resources to store or transmit data (e.g. storage space, channel capacity). In these scenarios, lossy image compression plays a crucial role to effectively increase the number of images collected under such constraints. However, lossy compression entails some undesired degradation of the data that may harm the performance of the downstream analysis task at hand, since important semantic information may be lost in the process. Moreover, we may only have compressed images at training time but are able to use original images at inference time, or vice versa, and in such a case, the downstream model suffers from covariate shift. In this paper, we analyze this phenomenon, with a special focus on vision-based perception for autonomous driving as a paradigmatic scenario. We see that loss of semantic information and covariate shift do indeed exist, resulting in a drop in performance that depends on the compression rate. In order to address the problem, we propose dataset restoration, based on image restoration with generative adversarial networks (GANs). Our method is agnostic to both the particular image compression method and the downstream task; and has the advantage of not adding additional cost to the deployed models, which is particularly important in resource-limited devices. The presented experiments focus on semantic segmentation as a challenging use case, cover a broad range of compression rates and diverse datasets, and show how our method is able to significantly alleviate the negative effects of compression on the downstream visual task.
Neural Architecture Search with an Efficient Multiobjective Evolutionary Framework
Nov 09, 2020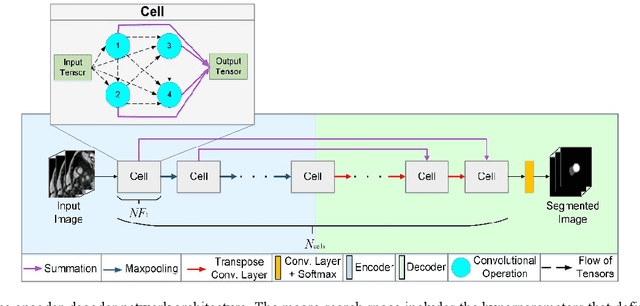

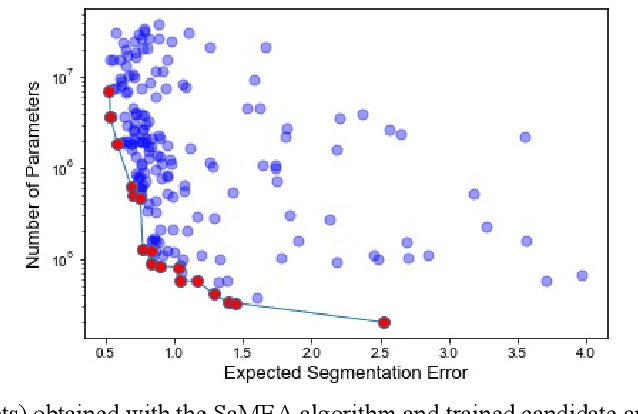
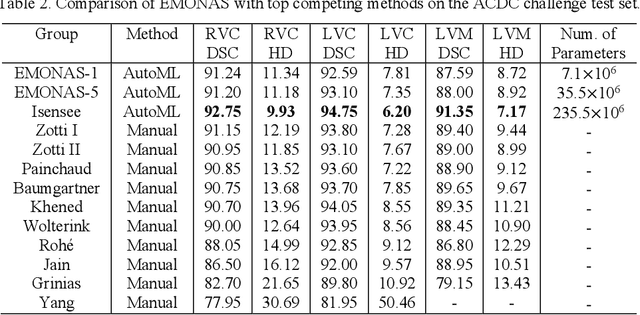
Deep learning methods have become very successful at solving many complex tasks such as image classification and segmentation, speech recognition and machine translation. Nevertheless, manually designing a neural network for a specific problem is very difficult and time-consuming due to the massive hyperparameter search space, long training times, and lack of technical guidelines for the hyperparameter selection. Moreover, most networks are highly complex, task specific and over-parametrized. Recently, multiobjective neural architecture search (NAS) methods have been proposed to automate the design of accurate and efficient architectures. However, they only optimize either the macro- or micro-structure of the architecture requiring the unset hyperparameters to be manually defined, and do not use the information produced during the optimization process to increase the efficiency of the search. In this work, we propose EMONAS, an Efficient MultiObjective Neural Architecture Search framework for the automatic design of neural architectures while optimizing the network's accuracy and size. EMONAS is composed of a search space that considers both the macro- and micro-structure of the architecture, and a surrogate-assisted multiobjective evolutionary based algorithm that efficiently searches for the best hyperparameters using a Random Forest surrogate and guiding selection probabilities. EMONAS is evaluated on the task of 3D cardiac segmentation from the MICCAI ACDC challenge, which is crucial for disease diagnosis, risk evaluation, and therapy decision. The architecture found with EMONAS is ranked within the top 10 submissions of the challenge in all evaluation metrics, performing better or comparable to other approaches while reducing the search time by more than 50% and having considerably fewer number of parameters.