 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structural Similarity based Anatomical and Functional Brain Imaging Fusion
Aug 14, 2019
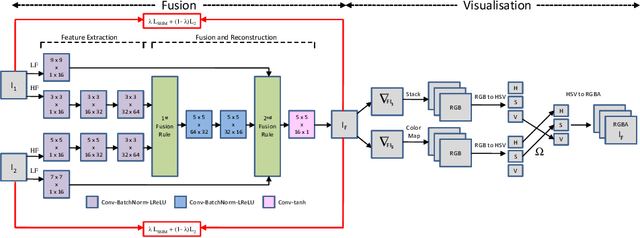
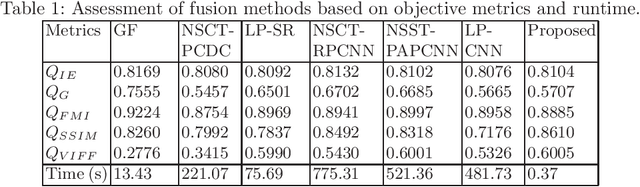
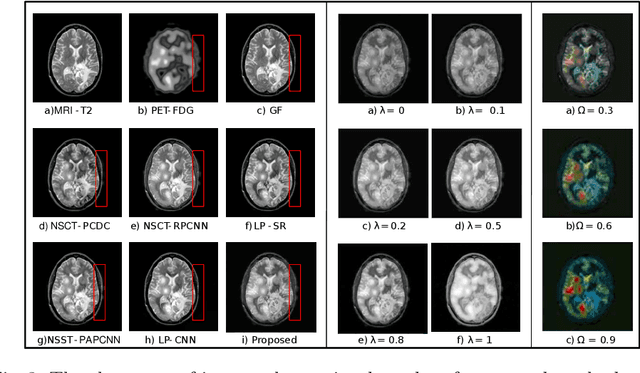
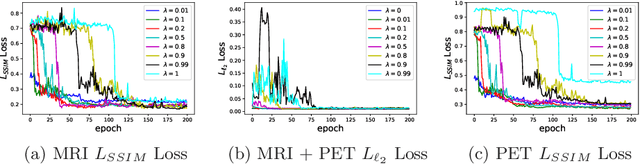
Multimodal medical image fusion helps in combining contrasting features from two or more input imaging modalities to represent fused information in a single image. One of the pivotal clinical applications of medical image fusion is the merging of anatomical and functional modalities for fast diagnosis of malignant tissues. In this paper, we present a novel end-to-end unsupervised learning-based Convolutional Neural Network (CNN) for fusing the high and low frequency components of MRI-PET grayscale image pairs, publicly available at ADNI, by exploiting Structural Similarity Index (SSIM) as the loss function during training. We then apply color coding for the visualization of the fused image by quantifying the contribution of each input image in terms of the partial derivatives of the fused image. We find that our fusion and visualization approach results in better visual perception of the fused image, while also comparing favorably to previous methods when applying various quantitative assessment metrics.
Can weight sharing outperform random architecture search? An investigation with TuNAS
Aug 13, 2020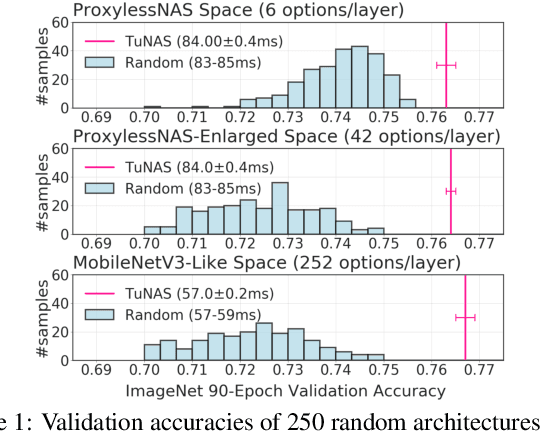


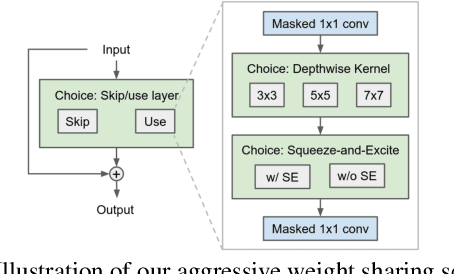
Efficient Neural Architecture Search methods based on weight sharing have shown good promise in democratizing Neural Architecture Search for computer vision models. There is, however, an ongoing debate whether these efficient methods are significantly better than random search. Here we perform a thorough comparison between efficient and random search methods on a family of progressively larger and more challenging search spaces for image classification and detection on ImageNet and COCO. While the efficacies of both methods are problem-dependent, our experiments demonstrate that there are large, realistic tasks where efficient search methods can provide substantial gains over random search. In addition, we propose and evaluate techniques which improve the quality of searched architectures and reduce the need for manual hyper-parameter tuning. Source code and experiment data are available at https://github.com/google-research/google-research/tree/master/tunas
* Published at CVPR 2020
Deep Learning Based Vehicle Tracking System Using License Plate Detection And Recognition
May 10, 2020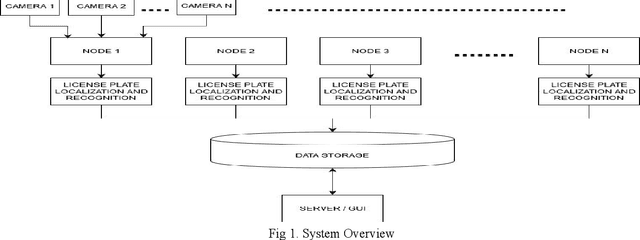
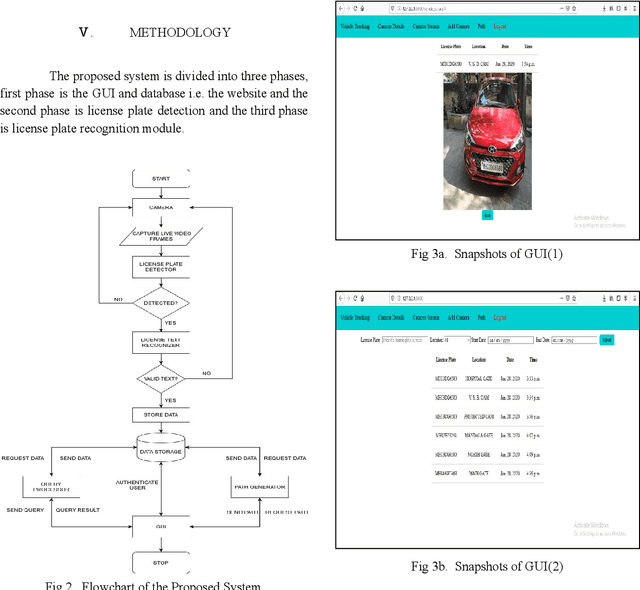
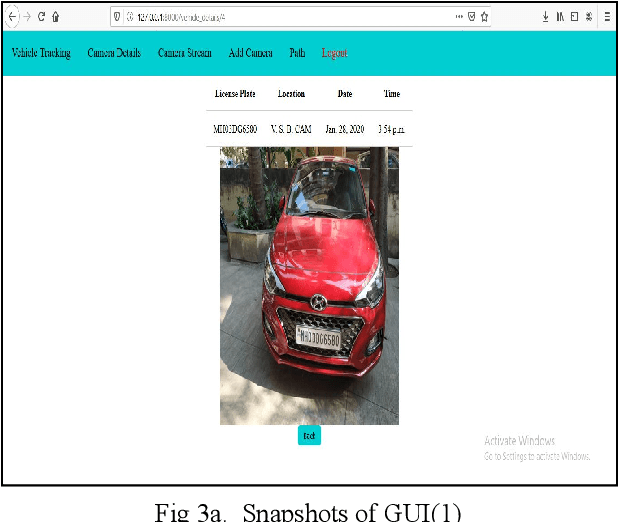
Vehicle tracking is an integral part of intelligent traffic management systems. Previous implementations of vehicle tracking used Global Positioning System(GPS) based systems that gave location of the vehicle of an individual on their smartphones.The proposed system uses a novel approach to vehicle tracking using Vehicle License plate detection and recognition (VLPR) technique, which can be integrated on a large scale with traffic management systems. Initial methods of implementing VLPR used simple image processing techniques which were quite experimental and heuristic. With the onset of Deep learning and Computer Vision, one can create robust VLPR systems that can produce results close to human efficiency. Previous implementations, based on deep learning, made use of object detection and support vector machines for detection and a heuristic image processing based approach for recognition. The proposed system makes use of scene text detection model architecture for License plate detection and for recognition it uses the Optical character recognition engine (OCR) Tesseract. The proposed system obtained extraordinary results when it was tested on a highway video using NVIDIA Ge-force RTX 2080ti GPU, results were obtained at a speed of 30 frames per second with accuracy close to human.
ProAlignNet : Unsupervised Learning for Progressively Aligning Noisy Contours
May 23, 2020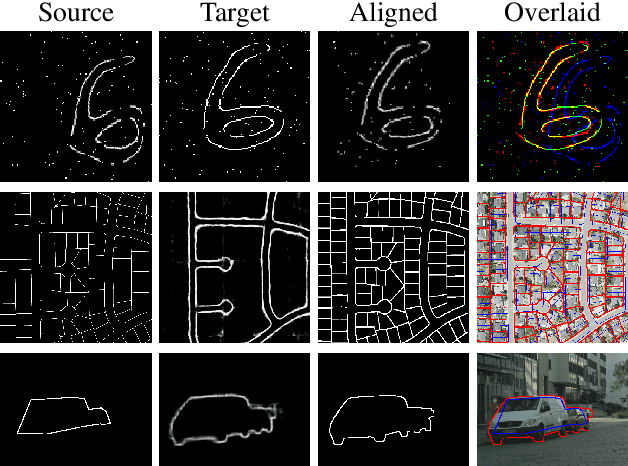
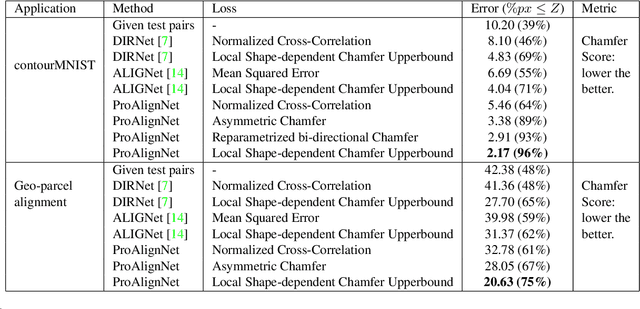
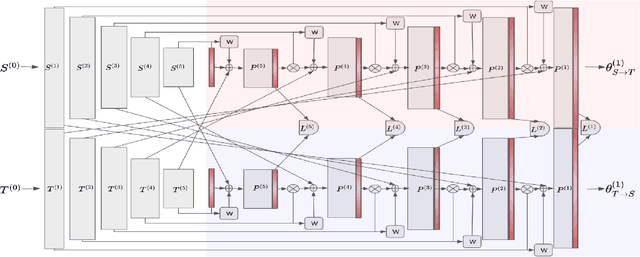
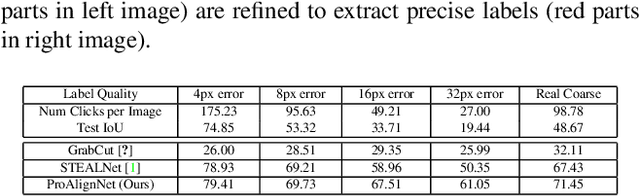
Contour shape alignment is a fundamental but challenging problem in computer vision, especially when the observations are partial, noisy, and largely misaligned. Recent ConvNet-based architectures that were proposed to align image structures tend to fail with contour representation of shapes, mostly due to the use of proximity-insensitive pixel-wise similarity measures as loss functions in their training processes. This work presents a novel ConvNet, "ProAlignNet" that accounts for large scale misalignments and complex transformations between the contour shapes. It infers the warp parameters in a multi-scale fashion with progressively increasing complex transformations over increasing scales. It learns --without supervision-- to align contours, agnostic to noise and missing parts, by training with a novel loss function which is derived an upperbound of a proximity-sensitive and local shape-dependent similarity metric that uses classical Morphological Chamfer Distance Transform. We evaluate the reliability of these proposals on a simulated MNIST noisy contours dataset via some basic sanity check experiments. Next, we demonstrate the effectiveness of the proposed models in two real-world applications of (i) aligning geo-parcel data to aerial image maps and (ii) refining coarsely annotated segmentation labels. In both applications, the proposed models consistently perform superior to state-of-the-art methods.
Syn2Real: Forgery Classification via Unsupervised Domain Adaptation
Feb 03, 2020

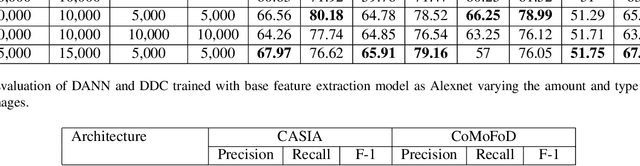
In recent years, image manipulation is becoming increasingly more accessible, yielding more natural-looking images, owing to the modern tools in image processing and computer vision techniques. The task of the identification of forged images has become very challenging. Amongst different types of forgeries, the cases of Copy-Move forgery are increasing manifold, due to the difficulties involved to detect this tampering. To tackle such problems, publicly available datasets are insufficient. In this paper, we propose to create a synthetic forged dataset using deep semantic image inpainting and copy-move forgery algorithm. However, models trained on these datasets have a significant drop in performance when tested on more realistic data. To alleviate this problem, we use unsupervised domain adaptation networks to detect copy-move forgery in new domains by mapping the feature space from our synthetically generated dataset. Furthermore, we improvised the F1 score on CASIA and CoMoFoD dataset to 80.3% and 78.8%, respectively. Our approach can be helpful in those cases where the classification of data is unavailable.
Cognitive Anthropomorphism of AI: How Humans and Computers Classify Images
Feb 07, 2020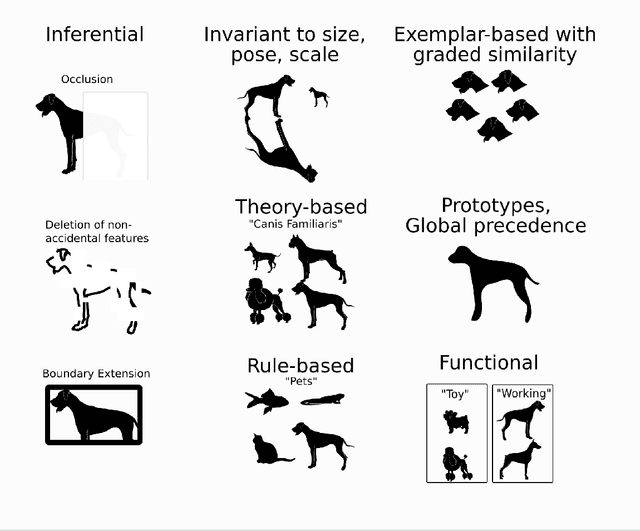
Modern AI image classifiers have made impressive advances in recent years, but their performance often appears strange or violates expectations of users. This suggests humans engage in cognitive anthropomorphism: expecting AI to have the same nature as human intelligence. This mismatch presents an obstacle to appropriate human-AI interaction. To delineate this mismatch, I examine known properties of human classification, in comparison to image classifier systems. Based on this examination, I offer three strategies for system design that can address the mismatch between human and AI classification: explainable AI, novel methods for training users, and new algorithms that match human cognition.
Real Time Detection of Small Objects
Mar 17, 2020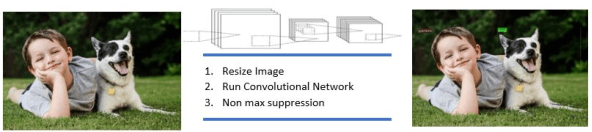
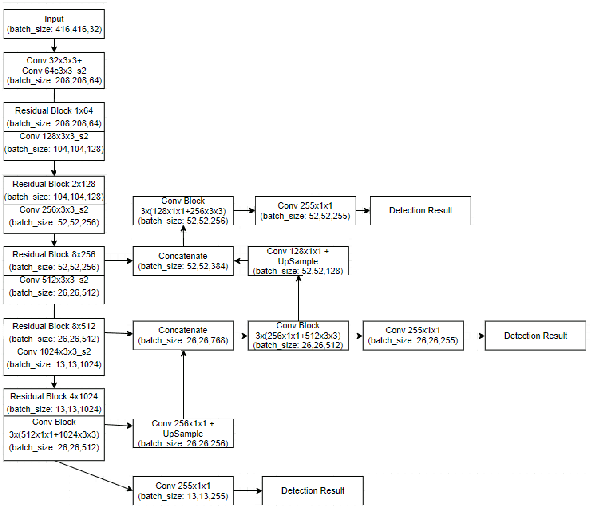
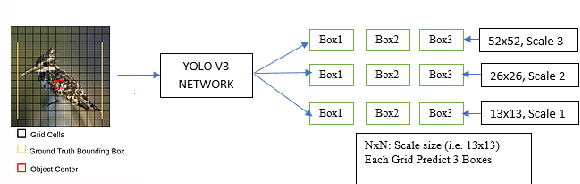
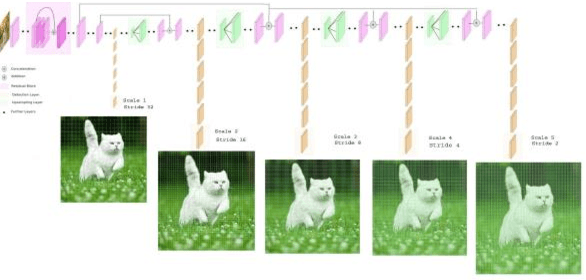
The existing real time object detection algorithm is based on the deep neural network of convolution need to perform multilevel convolution and pooling operations on the entire image to extract a deep semantic characteristic of the image. The detection models perform better for large objects. However, these models do not detect small objects with low resolution and noise, because the features of existing models do not fully represent the essential features of small objects after repeated convolution operations. We have introduced a novel real time detection algorithm which employs upsampling and skip connection to extract multiscale features at different convolution levels in a learning task resulting a remarkable performance in detecting small objects. The detection precision of the model is shown to be higher and faster than that of the state-of-the-art models.
* 7 pages, 9 figures
Deep Learning of Individual Aesthetics
Sep 24, 2020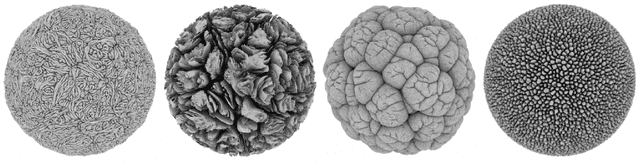
Accurate evaluation of human aesthetic preferences represents a major challenge for creative evolutionary and generative systems research. Prior work has tended to focus on feature measures of the artefact, such as symmetry, complexity and coherence. However, research models from Psychology suggest that human aesthetic experiences encapsulate factors beyond the artefact, making accurate computational models very difficult to design. The interactive genetic algorithm (IGA) circumvents the problem through human-in-the-loop, subjective evaluation of aesthetics, but is limited due to user fatigue and small population sizes. In this paper we look at how recent advances in deep learning can assist in automating personal aesthetic judgement. Using a leading artist's computer art dataset, we investigate the relationship between image measures, such as complexity, and human aesthetic evaluation. We use dimension reduction methods to visualise both genotype and phenotype space in order to support the exploration of new territory in a generative system. Convolutional Neural Networks trained on the artist's prior aesthetic evaluations are used to suggest new possibilities similar or between known high quality genotype-phenotype mappings. We integrate this classification and discovery system into a software tool for evolving complex generative art and design.
Bone Segmentation in Contrast Enhanced Whole-Body Computed Tomography
Aug 13, 2020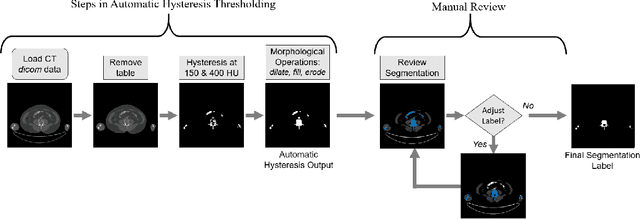
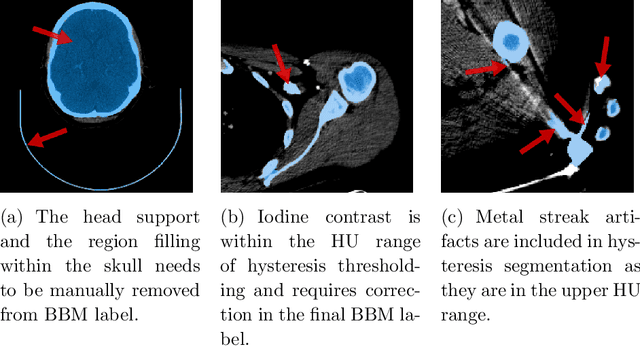
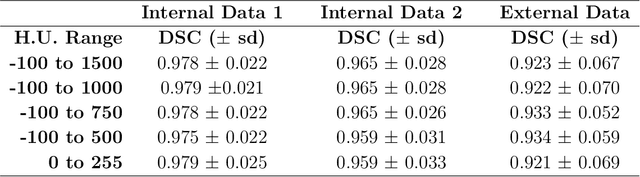
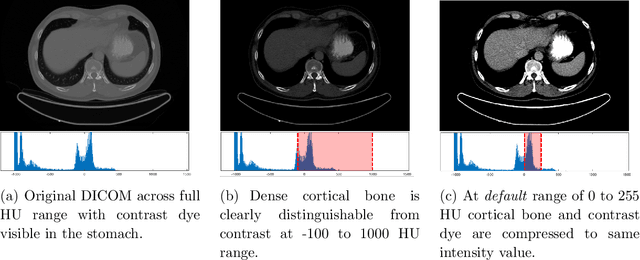
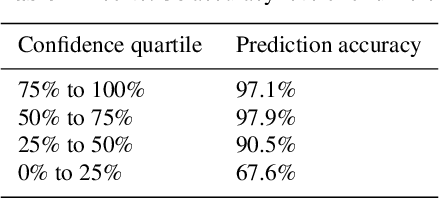
Segmentation of bone regions allows for enhanced diagnostics, disease characterisation and treatment monitoring in CT imaging. In contrast enhanced whole-body scans accurate automatic segmentation is particularly difficult as low dose whole body protocols reduce image quality and make contrast enhanced regions more difficult to separate when relying on differences in pixel intensities. This paper outlines a U-net architecture with novel preprocessing techniques, based on the windowing of training data and the modification of sigmoid activation threshold selection to successfully segment bone-bone marrow regions from low dose contrast enhanced whole-body CT scans. The proposed method achieved mean Dice coefficients of 0.979, 0.965, and 0.934 on two internal datasets and one external test dataset respectively. We have demonstrated that appropriate preprocessing is important for differentiating between bone and contrast dye, and that excellent results can be achieved with limited data.
Attention with Multiple Sources Knowledges for COVID-19 from CT Images
Sep 24, 2020
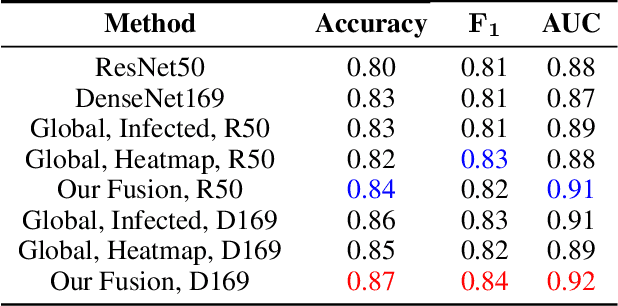
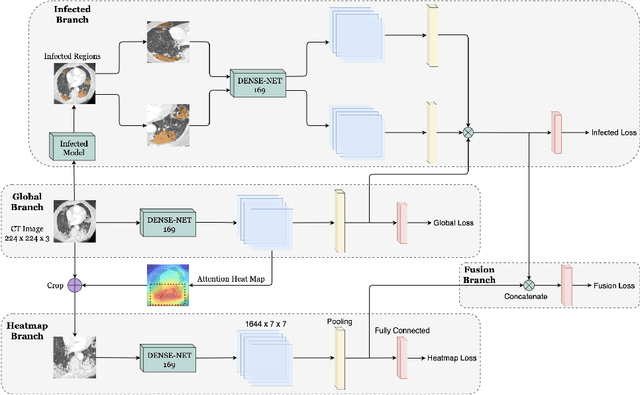
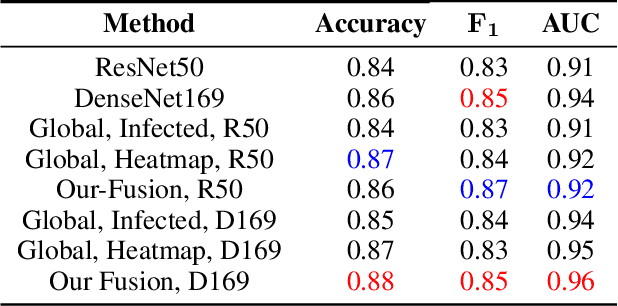
Until now, Coronavirus SARS-CoV-2 has caused more than 850,000 deaths and infected more than 27 million individuals in over 120 countries. Besides principal polymerase chain reaction (PCR) tests, automatically identifying positive samples based on computed tomography (CT) scans can present a promising option in the early diagnosis of COVID-19. Recently, there have been increasing efforts to utilize deep networks for COVID-19 diagnosis based on CT scans. While these approaches mostly focus on introducing novel architectures, transfer learning techniques, or construction large scale data, we propose a novel strategy to improve the performance of several baselines by leveraging multiple useful information sources relevant to doctors' judgments. Specifically, infected regions and heat maps extracted from learned networks are integrated with the global image via an attention mechanism during the learning process. This procedure not only makes our system more robust to noise but also guides the network focusing on local lesion areas. Extensive experiments illustrate the superior performance of our approach compared to recent baselines. Furthermore, our learned network guidance presents an explainable feature to doctors as we can understand the connection between input and output in a grey-box model.