 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Attentive Pairwise Interaction for Fine-Grained Classification
Feb 24, 2020
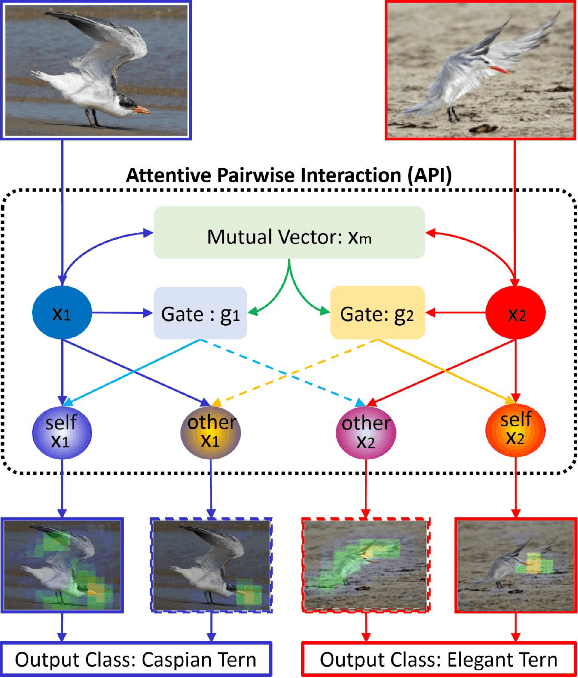

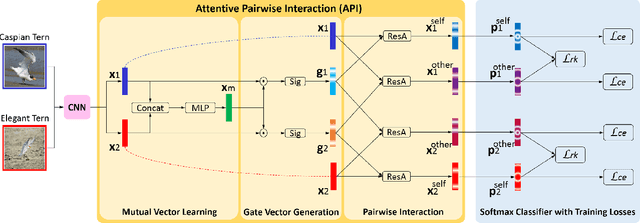

Fine-grained classification is a challenging problem, due to subtle differences among highly-confused categories. Most approaches address this difficulty by learning discriminative representation of individual input image. On the other hand, humans can effectively identify contrastive clues by comparing image pairs. Inspired by this fact, this paper proposes a simple but effective Attentive Pairwise Interaction Network (API-Net), which can progressively recognize a pair of fine-grained images by interaction. Specifically, API-Net first learns a mutual feature vector to capture semantic differences in the input pair. It then compares this mutual vector with individual vectors to generate gates for each input image. These distinct gate vectors inherit mutual context on semantic differences, which allow API-Net to attentively capture contrastive clues by pairwise interaction between two images. Additionally, we train API-Net in an end-to-end manner with a score ranking regularization, which can further generalize API-Net by taking feature priorities into account. We conduct extensive experiments on five popular benchmarks in fine-grained classification. API-Net outperforms the recent SOTA methods, i.e., CUB-200-2011 (90.0%), Aircraft(93.9%), Stanford Cars (95.3%), Stanford Dogs (90.3%), and NABirds (88.1%).
Large-Scale Electron Microscopy Image Segmentation in Spark
Apr 01, 2016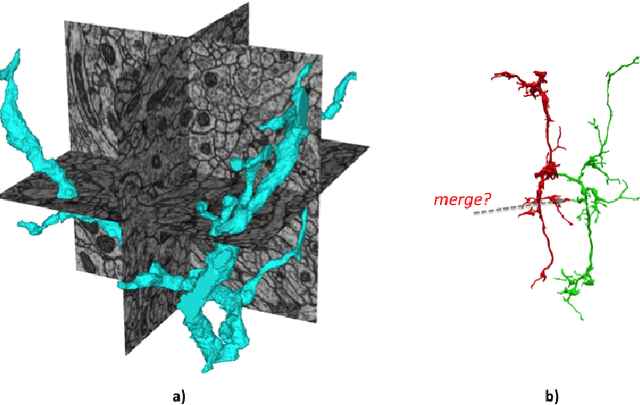

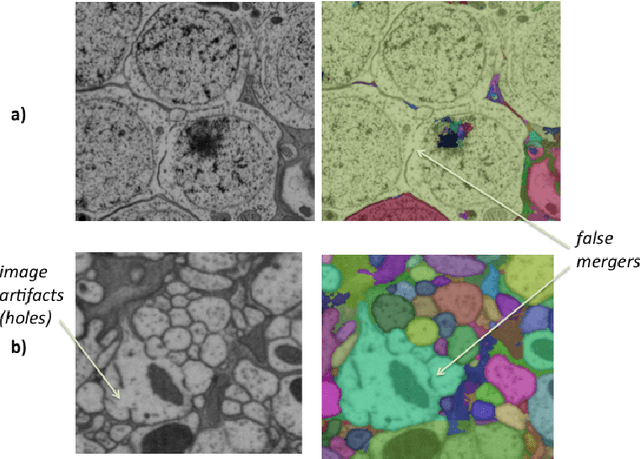
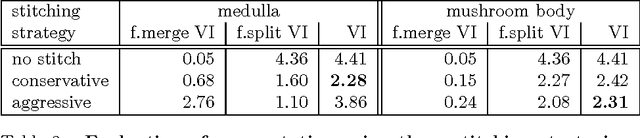
The emerging field of connectomics aims to unlock the mysteries of the brain by understanding the connectivity between neurons. To map this connectivity, we acquire thousands of electron microscopy (EM) images with nanometer-scale resolution. After aligning these images, the resulting dataset has the potential to reveal the shapes of neurons and the synaptic connections between them. However, imaging the brain of even a tiny organism like the fruit fly yields terabytes of data. It can take years of manual effort to examine such image volumes and trace their neuronal connections. One solution is to apply image segmentation algorithms to help automate the tracing tasks. In this paper, we propose a novel strategy to apply such segmentation on very large datasets that exceed the capacity of a single machine. Our solution is robust to potential segmentation errors which could otherwise severely compromise the quality of the overall segmentation, for example those due to poor classifier generalizability or anomalies in the image dataset. We implement our algorithms in a Spark application which minimizes disk I/O, and apply them to a few large EM datasets, revealing both their effectiveness and scalability. We hope this work will encourage external contributions to EM segmentation by providing 1) a flexible plugin architecture that deploys easily on different cluster environments and 2) an in-memory representation of segmentation that could be conducive to new advances.
Domain Adaptation Through Task Distillation
Aug 27, 2020
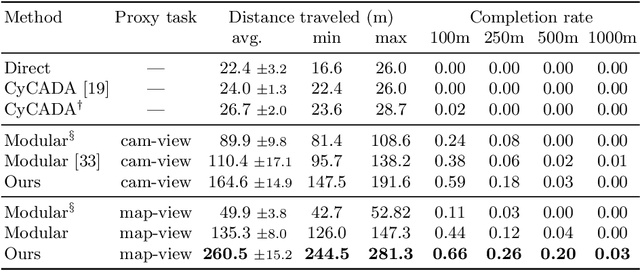
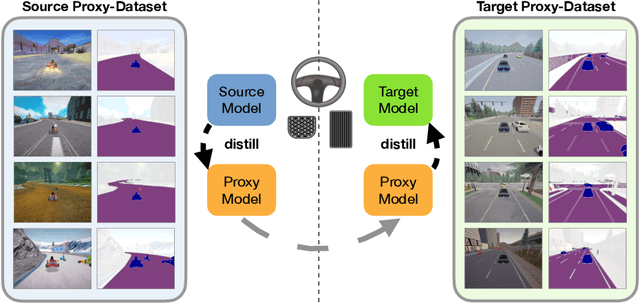

Deep networks devour millions of precisely annotated images to build their complex and powerful representations. Unfortunately, tasks like autonomous driving have virtually no real-world training data. Repeatedly crashing a car into a tree is simply too expensive. The commonly prescribed solution is simple: learn a representation in simulation and transfer it to the real world. However, this transfer is challenging since simulated and real-world visual experiences vary dramatically. Our core observation is that for certain tasks, such as image recognition, datasets are plentiful. They exist in any interesting domain, simulated or real, and are easy to label and extend. We use these recognition datasets to link up a source and target domain to transfer models between them in a task distillation framework. Our method can successfully transfer navigation policies between drastically different simulators: ViZDoom, SuperTuxKart, and CARLA. Furthermore, it shows promising results on standard domain adaptation benchmarks.
DuDoRNet: Learning a Dual-Domain Recurrent Network for Fast MRI Reconstruction with Deep T1 Prior
Jan 11, 2020
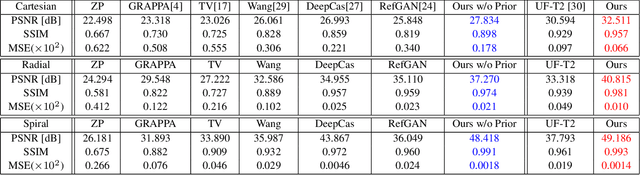
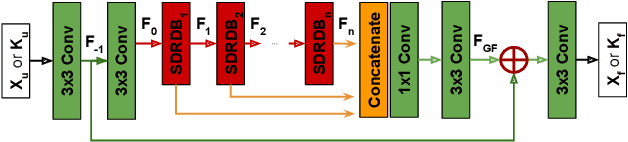
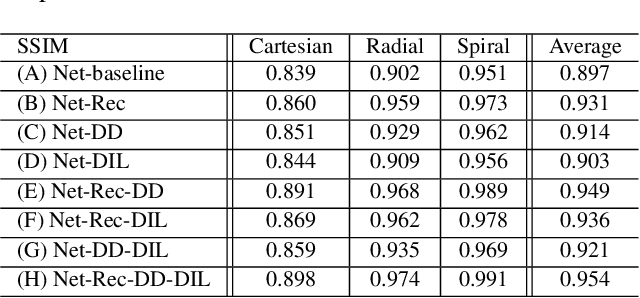
MRI with multiple protocols is commonly used for diagnosis, but it suffers from a long acquisition time, which yields the image quality vulnerable to say motion artifacts. To accelerate, various methods have been proposed to reconstruct full images from undersampled k-space data. However, these algorithms are inadequate for two main reasons. Firstly, aliasing artifacts generated in the image domain are structural and non-local, so that sole image domain restoration is insufficient. Secondly, though MRI comprises multiple protocols during one exam, almost all previous studies only employ the reconstruction of an individual protocol using a highly distorted undersampled image as input, leaving the use of fully-sampled short protocol (say T1) as complementary information highly underexplored. In this work, we address the above two limitations by proposing a Dual Domain Recurrent Network (DuDoRNet) with deep T1 prior embedded to simultaneously recover k-space and images for accelerating the acquisition of MRI with a long imaging protocol. Specifically, a Dilated Residual Dense Network (DRDNet) is customized for dual domain restorations from undersampled MRI data. Extensive experiments on different sampling patterns and acceleration rates demonstrate that our method consistently outperforms state-of-the-art methods, and can achieve SSIM up to 0.99 at $6 \times$ acceleration.
Object-centric Sampling for Fine-grained Image Classification
Dec 10, 2014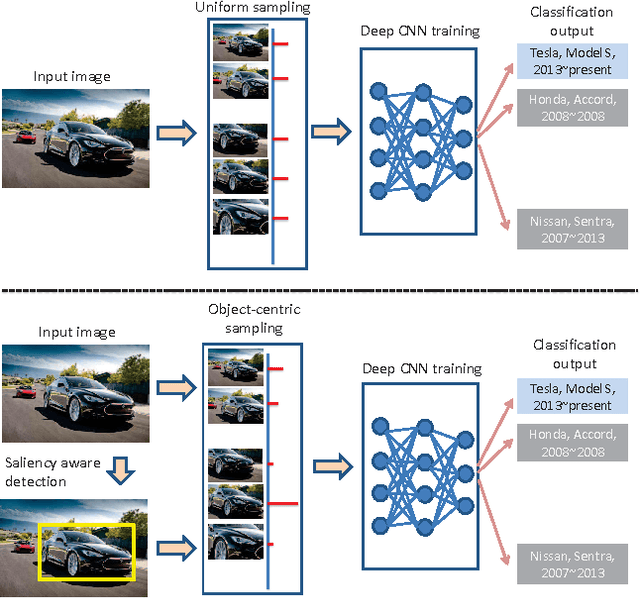
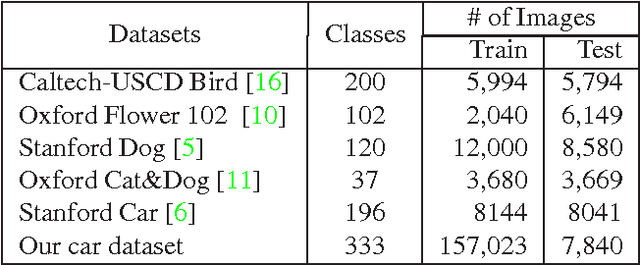

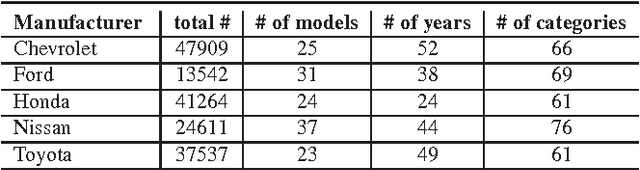
This paper proposes to go beyond the state-of-the-art deep convolutional neural network (CNN) by incorporating the information from object detection, focusing on dealing with fine-grained image classification. Unfortunately, CNN suffers from over-fiting when it is trained on existing fine-grained image classification benchmarks, which typically only consist of less than a few tens of thousands training images. Therefore, we first construct a large-scale fine-grained car recognition dataset that consists of 333 car classes with more than 150 thousand training images. With this large-scale dataset, we are able to build a strong baseline for CNN with top-1 classification accuracy of 81.6%. One major challenge in fine-grained image classification is that many classes are very similar to each other while having large within-class variation. One contributing factor to the within-class variation is cluttered image background. However, the existing CNN training takes uniform window sampling over the image, acting as blind on the location of the object of interest. In contrast, this paper proposes an \emph{object-centric sampling} (OCS) scheme that samples image windows based on the object location information. The challenge in using the location information lies in how to design powerful object detector and how to handle the imperfectness of detection results. To that end, we design a saliency-aware object detection approach specific for the setting of fine-grained image classification, and the uncertainty of detection results are naturally handled in our OCS scheme. Our framework is demonstrated to be very effective, improving top-1 accuracy to 89.3% (from 81.6%) on the large-scale fine-grained car classification dataset.
Towards Lightweight Lane Detection by Optimizing Spatial Embedding
Aug 19, 2020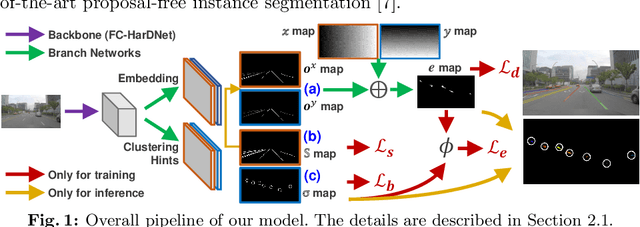
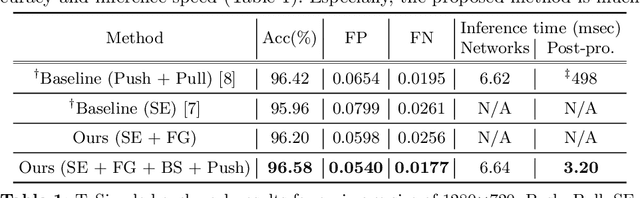
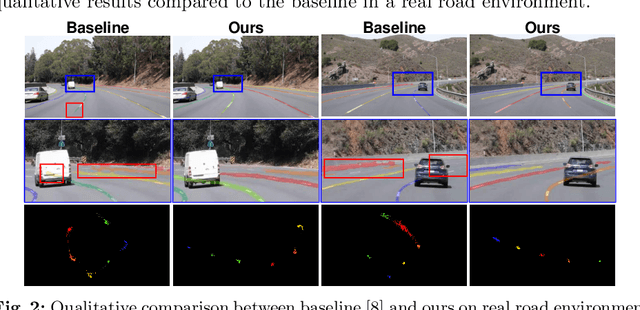
A number of lane detection methods depend on a proposal-free instance segmentation because of its adaptability to flexible object shape, occlusion, and real-time application. This paper addresses the problem that pixel embedding in proposal-free instance segmentation based lane detection is difficult to optimize. A translation invariance of convolution, which is one of the supposed strengths, causes challenges in optimizing pixel embedding. In this work, we propose a lane detection method based on proposal-free instance segmentation, directly optimizing spatial embedding of pixels using image coordinate. Our proposed method allows the post-processing step for center localization and optimizes clustering in an end-to-end manner. The proposed method enables real-time lane detection through the simplicity of post-processing and the adoption of a lightweight backbone. Our proposed method demonstrates competitive performance on public lane detection datasets.
Deep Image Category Discovery using a Transferred Similarity Function
Dec 05, 2016
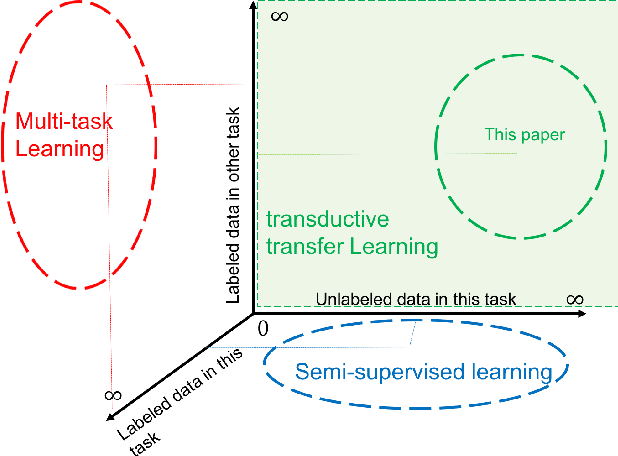
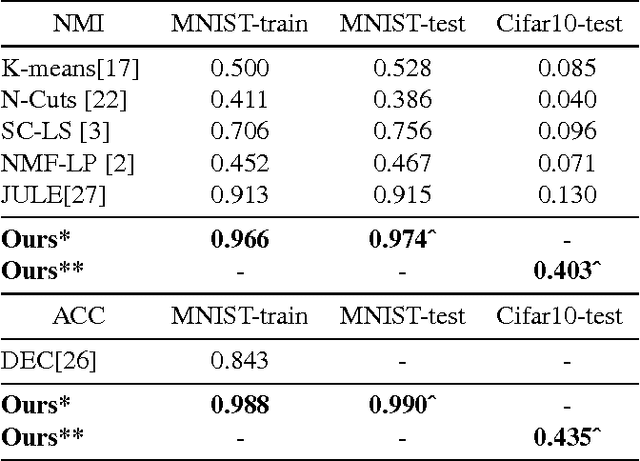
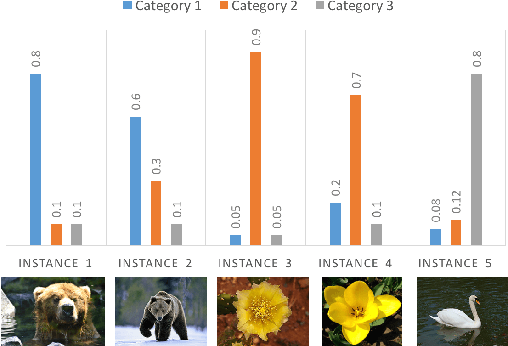
Automatically discovering image categories in unlabeled natural images is one of the important goals of unsupervised learning. However, the task is challenging and even human beings define visual categories based on a large amount of prior knowledge. In this paper, we similarly utilize prior knowledge to facilitate the discovery of image categories. We present a novel end-to-end network to map unlabeled images to categories as a clustering network. We propose that this network can be learned with contrastive loss which is only based on weak binary pair-wise constraints. Such binary constraints can be learned from datasets in other domains as transferred similarity functions, which mimic a simple knowledge transfer. We first evaluate our experiments on the MNIST dataset as a proof of concept, based on predicted similarities trained on Omniglot, showing a 99\% accuracy which significantly outperforms clustering based approaches. Then we evaluate the discovery performance on Cifar-10, STL-10, and ImageNet, which achieves both state-of-the-art accuracy and shows it can be scalable to various large natural images.
MoPro: Webly Supervised Learning with Momentum Prototypes
Sep 17, 2020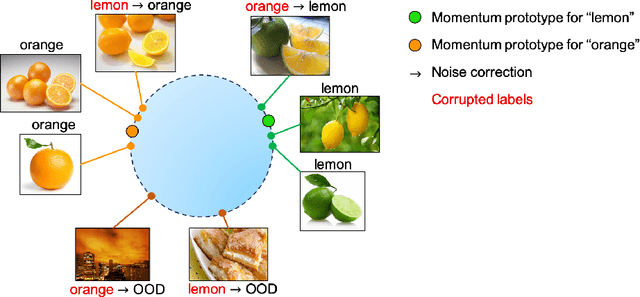
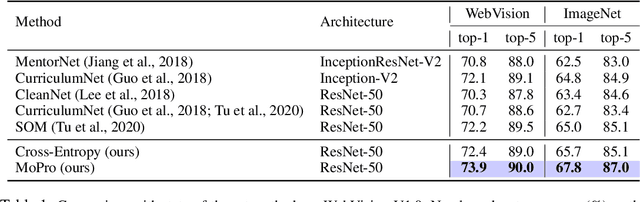
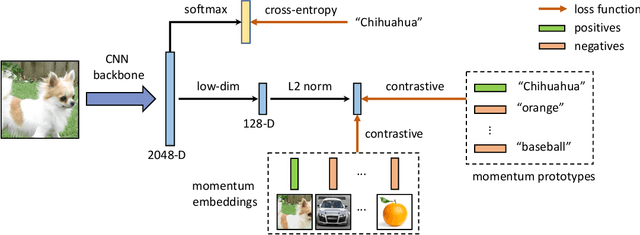
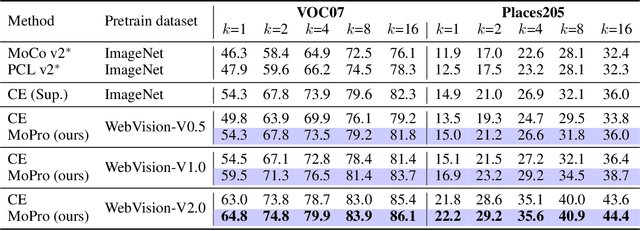
We propose a webly-supervised representation learning method that does not suffer from the annotation unscalability of supervised learning, nor the computation unscalability of self-supervised learning. Most existing works on webly-supervised representation learning adopt a vanilla supervised learning method without accounting for the prevalent noise in the training data, whereas most prior methods in learning with label noise are less effective for real-world large-scale noisy data. We propose momentum prototypes (MoPro), a simple contrastive learning method that achieves online label noise correction, out-of-distribution sample removal, and representation learning. MoPro achieves state-of-the-art performance on WebVision, a weakly-labeled noisy dataset. MoPro also shows superior performance when the pretrained model is transferred to down-stream image classification and detection tasks. It outperforms the ImageNet supervised pretrained model by +10.5 on 1-shot classification on VOC, and outperforms the best self-supervised pretrained model by +17.3 when finetuned on 1\% of ImageNet labeled samples. Furthermore, MoPro is more robust to distribution shifts. Code and pretrained models are available at https://github.com/salesforce/MoPro.
Deep Spatial Regression Model for Image Crowd Counting
Oct 26, 2017
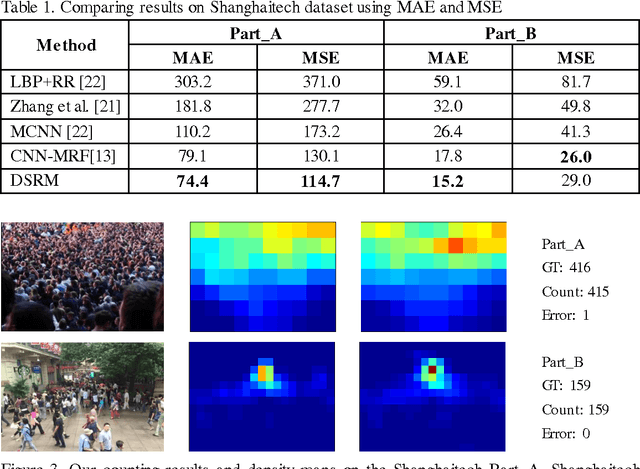
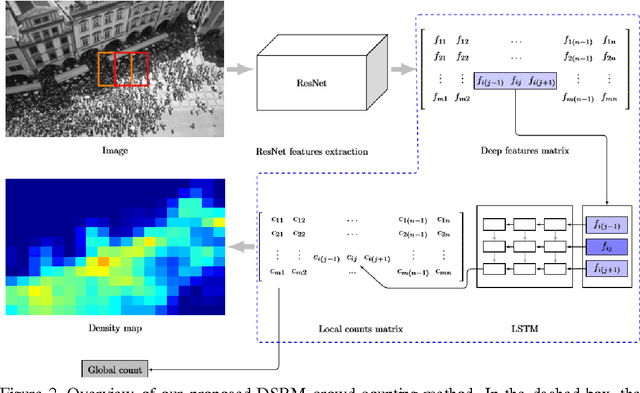
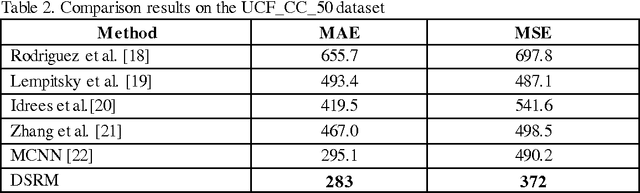
Computer vision techniques have been used to produce accurate and generic crowd count estimators in recent years. Due to severe occlusions, appearance variations, perspective distortions and illumination conditions, crowd counting is a very challenging task. To this end, we propose a deep spatial regression model(DSRM) for counting the number of individuals present in a still image with arbitrary perspective and arbitrary resolution. Our proposed model is based on Convolutional Neural Network (CNN) and long short term memory (LSTM). First, we put the images into a pretrained CNN to extract a set of high-level features. Then the features in adjacent regions are used to regress the local counts with a LSTM structure which takes the spatial information into consideration. The final global count is obtained by a sum of the local patches. We apply our framework on several challenging crowd counting datasets, and the experiment results illustrate that our method on the crowd counting and density estimation problem outperforms state-of-the-art methods in terms of reliability and effectiveness.
generating annotated high-fidelity images containing multiple coherent objects
Jun 22, 2020
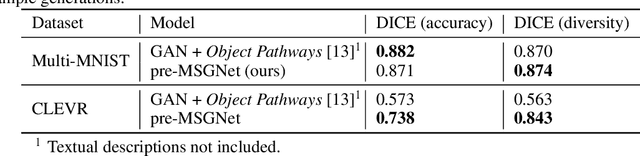
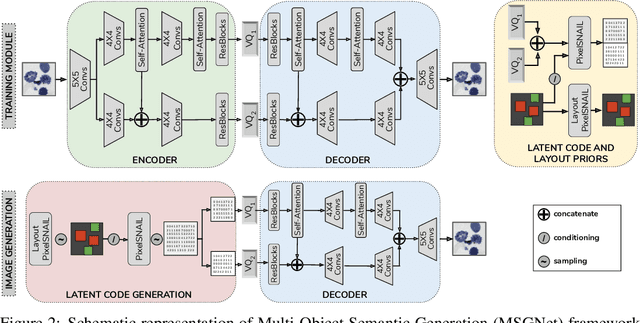
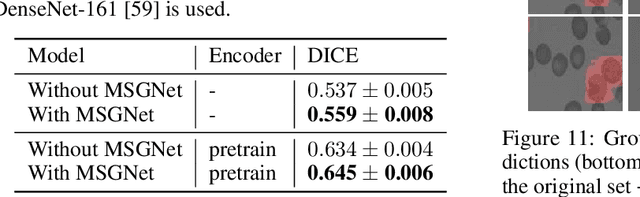
Recent developments related to generative models have made it possible to generate diverse high-fidelity images. In particular, layout-to-image generation models have gained significant attention due to their capability to generate realistic complex images containing distinct objects. These models are generally conditioned on either semantic layouts or textual descriptions. However, unlike natural images, providing auxiliary information can be extremely hard in domains such as biomedical imaging and remote sensing. In this work, we propose a multi-object generation framework that can synthesize images with multiple objects without explicitly requiring their contextual information during the generation process. Based on a vector-quantized variational autoencoder (VQ-VAE) backbone, our model learns to preserve spatial coherency within an image as well as semantic coherency between the objects and the background through two powerful autoregressive priors: PixelSNAIL and LayoutPixelSNAIL. While the PixelSNAIL learns the distribution of the latent encodings of the VQ-VAE, the LayoutPixelSNAIL is used to specifically learn the semantic distribution of the objects. An implicit advantage of our approach is that the generated samples are accompanied by object-level annotations. We demonstrate how coherency and fidelity are preserved with our method through experiments on the Multi-MNIST and CLEVR datasets; thereby outperforming state-of-the-art multi-object generative methods. The efficacy of our approach is demonstrated through application on medical imaging datasets, where we show that augmenting the training set with generated samples using our approach improves the performance of existing models.