 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Adversarial Semantic Segmentation
May 08, 2020
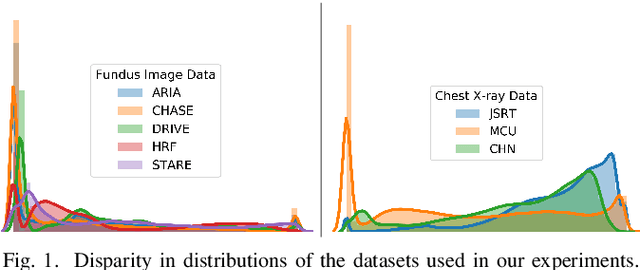
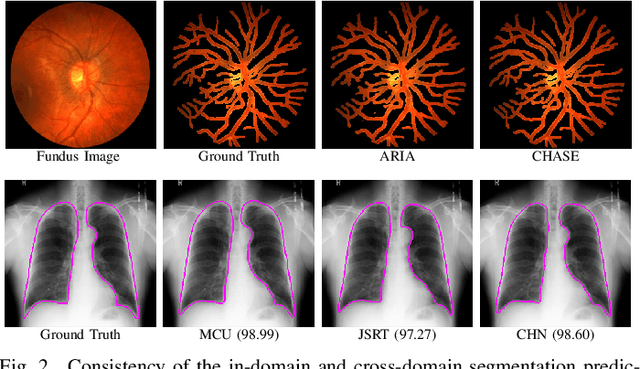
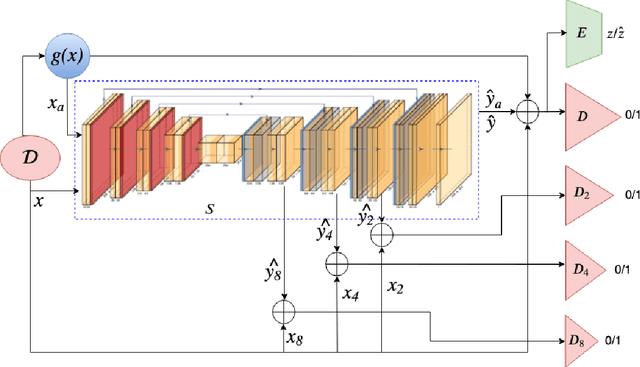
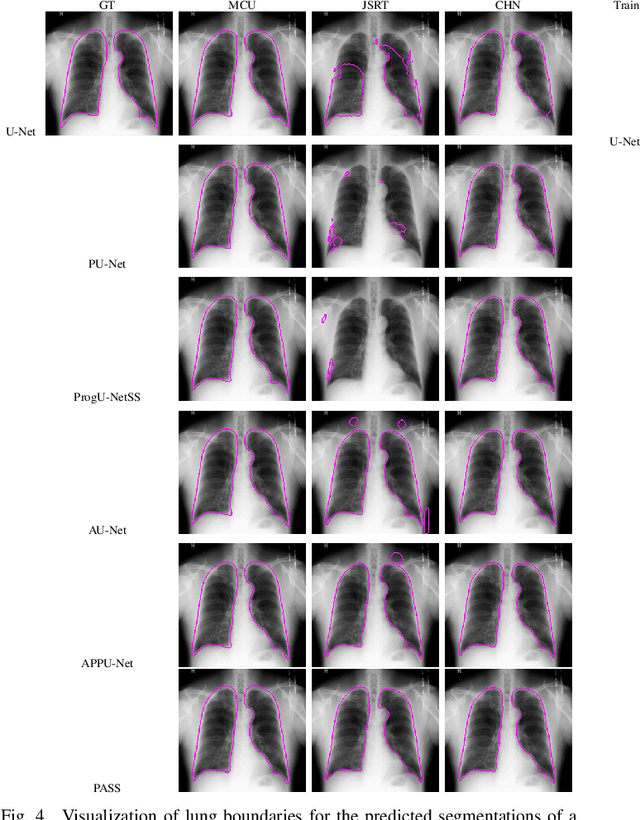
Medical image computing has advanced rapidly with the advent of deep learning techniques such as convolutional neural networks. Deep convolutional neural networks can perform exceedingly well given full supervision. However, the success of such fully-supervised models for various image analysis tasks (e.g., anatomy or lesion segmentation from medical images) is limited to the availability of massive amounts of labeled data. Given small sample sizes, such models are prohibitively data biased with large domain shift. To tackle this problem, we propose a novel end-to-end medical image segmentation model, namely Progressive Adversarial Semantic Segmentation (PASS), which can make improved segmentation predictions without requiring any domain-specific data during training time. Our extensive experimentation with 8 public diabetic retinopathy and chest X-ray datasets, confirms the effectiveness of PASS for accurate vascular and pulmonary segmentation, both for in-domain and cross-domain evaluations.
Overfitting for Fun and Profit: Instance-Adaptive Data Compression
Jan 21, 2021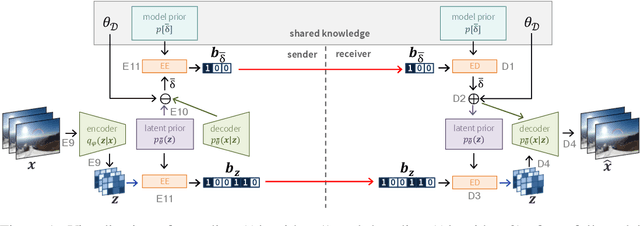

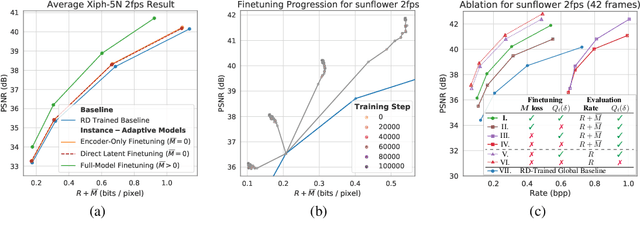
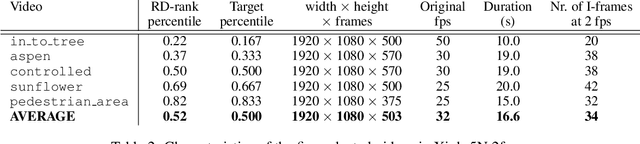
Neural data compression has been shown to outperform classical methods in terms of $RD$ performance, with results still improving rapidly. At a high level, neural compression is based on an autoencoder that tries to reconstruct the input instance from a (quantized) latent representation, coupled with a prior that is used to losslessly compress these latents. Due to limitations on model capacity and imperfect optimization and generalization, such models will suboptimally compress test data in general. However, one of the great strengths of learned compression is that if the test-time data distribution is known and relatively low-entropy (e.g. a camera watching a static scene, a dash cam in an autonomous car, etc.), the model can easily be finetuned or adapted to this distribution, leading to improved $RD$ performance. In this paper we take this concept to the extreme, adapting the full model to a single video, and sending model updates (quantized and compressed using a parameter-space prior) along with the latent representation. Unlike previous work, we finetune not only the encoder/latents but the entire model, and - during finetuning - take into account both the effect of model quantization and the additional costs incurred by sending the model updates. We evaluate an image compression model on I-frames (sampled at 2 fps) from videos of the Xiph dataset, and demonstrate that full-model adaptation improves $RD$ performance by ~1 dB, with respect to encoder-only finetuning.
Truly shift-invariant convolutional neural networks
Dec 01, 2020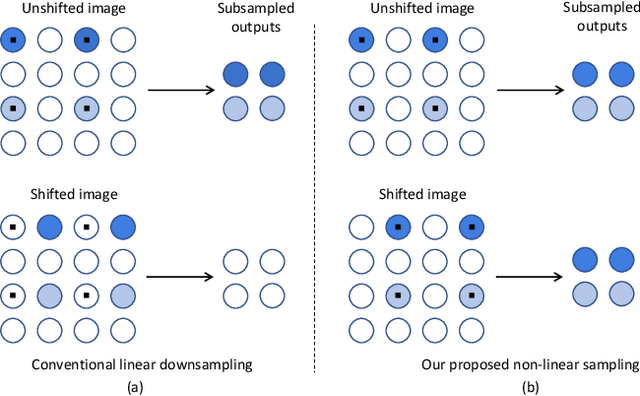
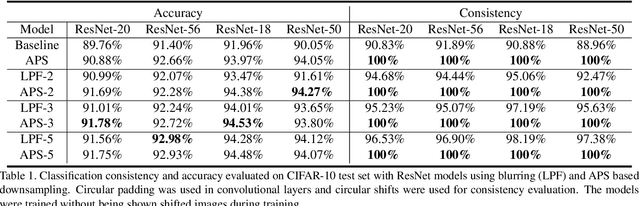
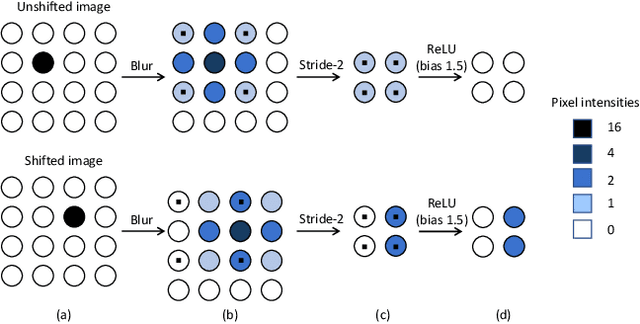
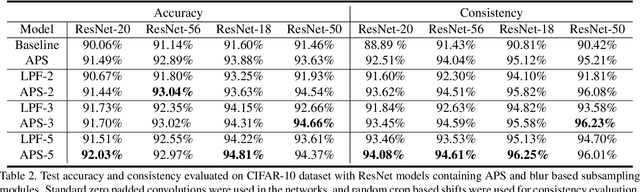
Thanks to the use of convolution and pooling layers, convolutional neural networks were for a long time thought to be shift-invariant. However, recent works have shown that the output of a CNN can change significantly with small shifts in input: a problem caused by the presence of downsampling (stride) layers. The existing solutions rely either on data augmentation or on anti-aliasing, both of which have limitations and neither of which enables perfect shift invariance. Additionally, the gains obtained from these methods do not extend to image patterns not seen during training. To address these challenges, we propose adaptive polyphase sampling (APS), a simple sub-sampling scheme that allows convolutional neural networks to achieve 100% consistency in classification performance under shifts, without any loss in accuracy. With APS the networks exhibit perfect consistency to shifts even before training, making it the first approach that makes convolutional neural networks truly shift invariant.
Each Part Matters: Local Patterns Facilitate Cross-view Geo-localization
Aug 26, 2020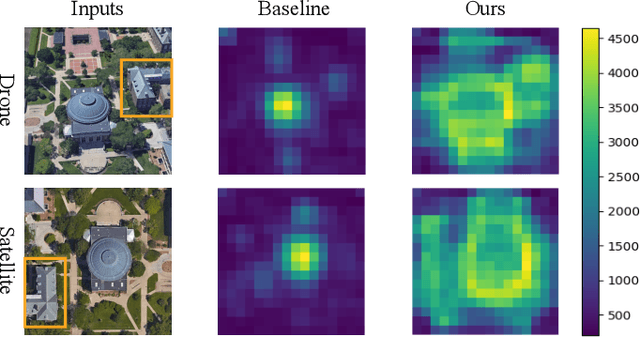

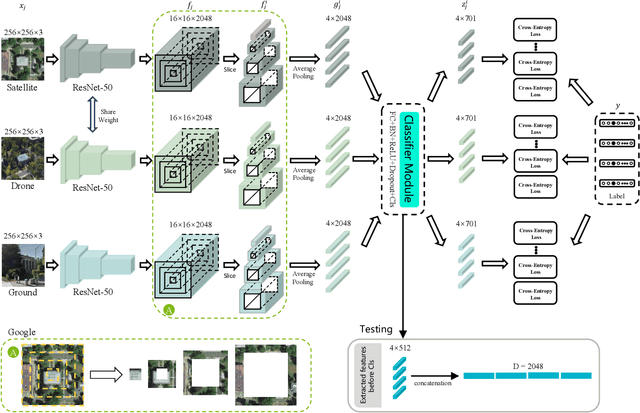
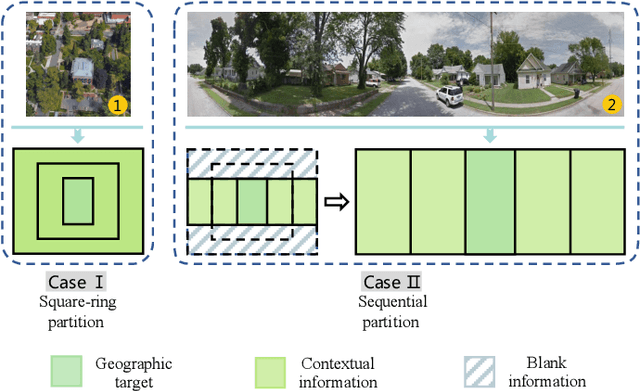
Cross-view geo-localization is to spot images of the same geographic target from different platforms, e.g., drone-view cameras and satellites. It is challenging in the large visual appearance changes caused by extreme viewpoint variations. Existing methods usually concentrate on mining the fine-grained feature of the geographic target in the image center, but underestimate the contextual information in neighbor areas. In this work, we argue that neighbor areas can be leveraged as auxiliary information, enriching discriminative clues for geo-localization. Specifically, we introduce a simple and effective deep neural network, called Local Pattern Network (LPN), to take advantage of contextual information in an end-to-end manner. Without using extra part estimators, LPN adopts a square-ring feature partition strategy, which provides the attention according to the distance to the image center. It eases the part matching and enables the part-wise representation learning. Owing to the square-ring partition design, the proposed LPN has good scalability to rotation variations and achieves competitive results on two prevailing benchmarks, i.e., University-1652 and CVUSA. Besides, we also show the proposed LPN can be easily embedded into other frameworks to further boost performance.
Structure Tensor Based Image Interpolation Method
Dec 26, 2014
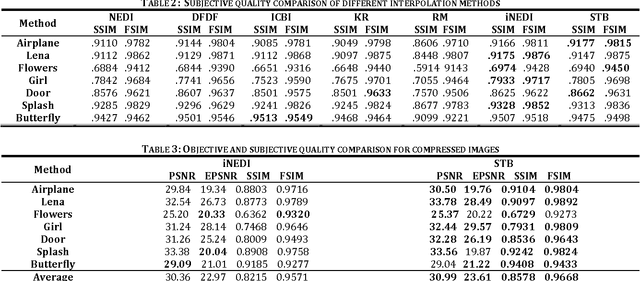


Feature preserving image interpolation is an active area in image processing field. In this paper a new direct edge directed image super-resolution algorithm based on structure tensors is proposed. Using an isotropic Gaussian filter, the structure tensor at each pixel of the input image is computed and the pixels are classified to three distinct classes; uniform region, corners and edges, according to the eigenvalues of the structure tensor. Due to application of the isotropic Gaussian filter, the classification is robust to noise presented in image. Based on the tangent eigenvector of the structure tensor, the edge direction is determined and used for interpolation along the edges. In comparison to some previous edge directed image interpolation methods, the proposed method achieves higher quality in both subjective and objective aspects. Also the proposed method outperforms previous methods in case of noisy and JPEG compressed images. Furthermore, without the need for optimization in the process, the algorithm can achieve higher speed.
SharinGAN: Combining Synthetic and Real Data for Unsupervised Geometry Estimation
Jun 07, 2020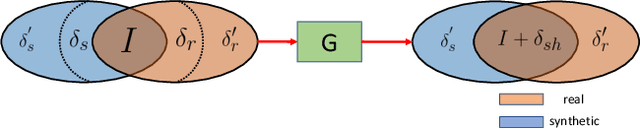
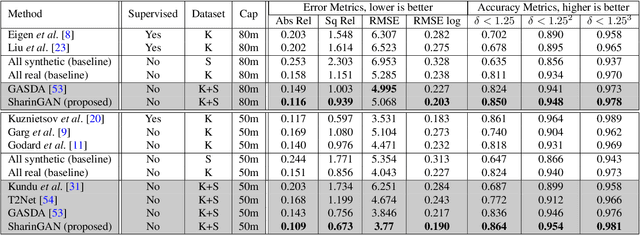
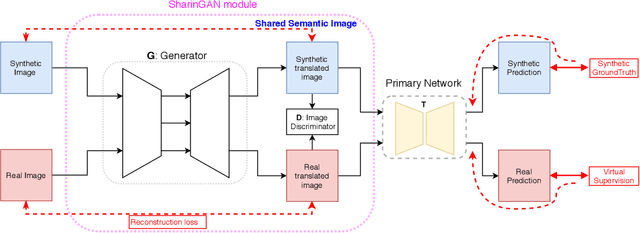
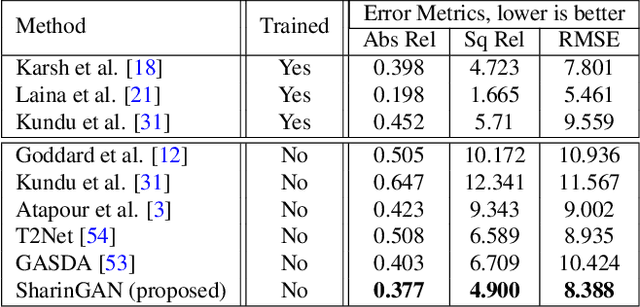
We propose a novel method for combining synthetic and real images when training networks to determine geometric information from a single image. We suggest a method for mapping both image types into a single, shared domain. This is connected to a primary network for end-to-end training. Ideally, this results in images from two domains that present shared information to the primary network. Our experiments demonstrate significant improvements over the state-of-the-art in two important domains, surface normal estimation of human faces and monocular depth estimation for outdoor scenes, both in an unsupervised setting.
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Oct 08, 2020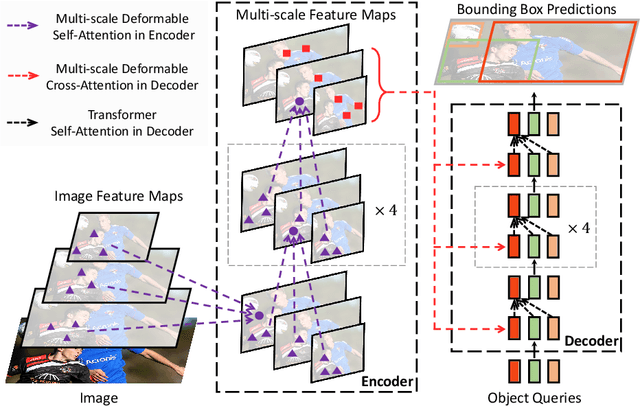
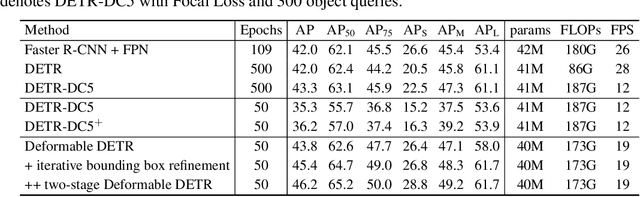
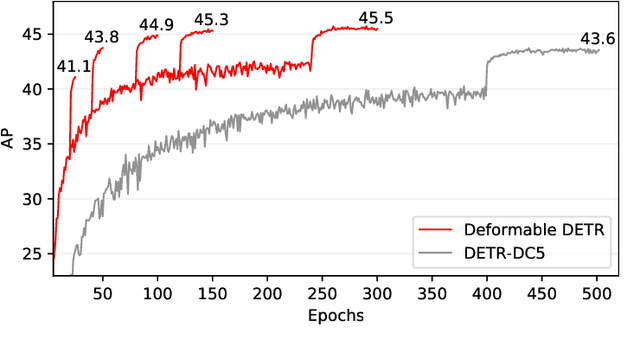
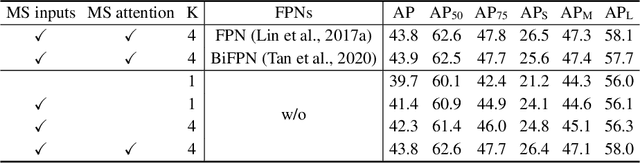
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10$\times$ less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach. Code shall be released.
Learning to Rank for Active Learning: A Listwise Approach
Jul 31, 2020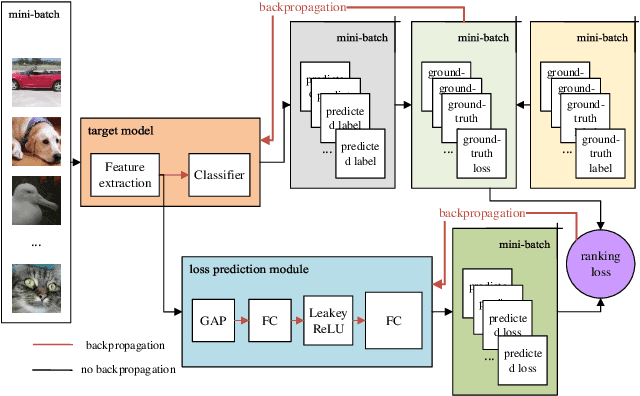
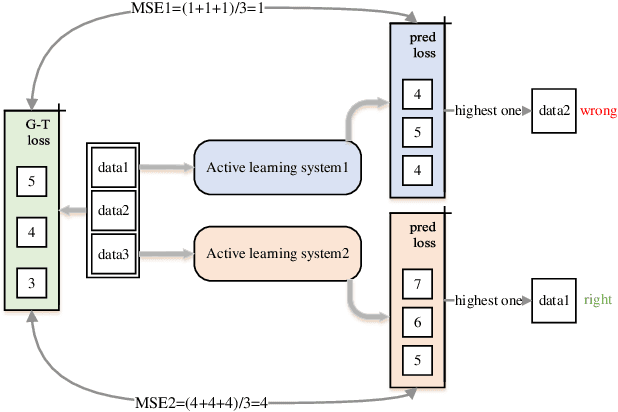
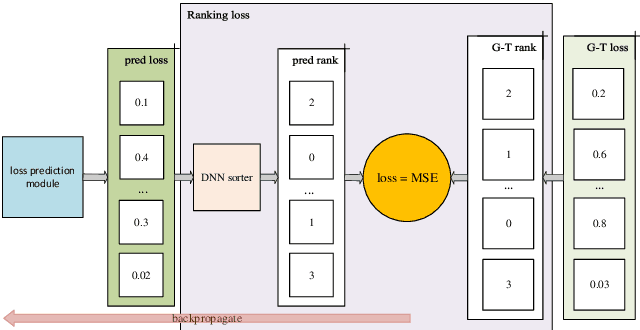
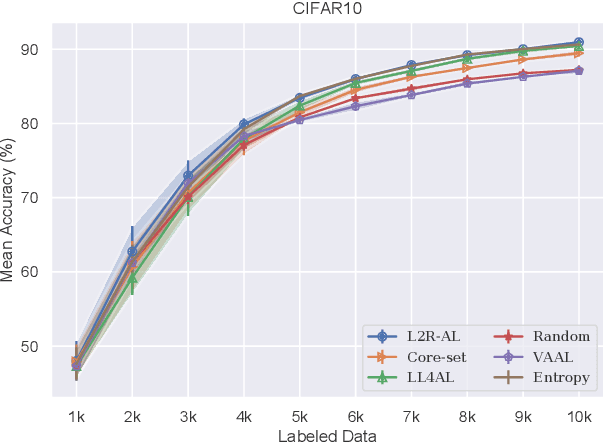
Active learning emerged as an alternative to alleviate the effort to label huge amount of data for data hungry applications (such as image/video indexing and retrieval, autonomous driving, etc.). The goal of active learning is to automatically select a number of unlabeled samples for annotation (according to a budget), based on an acquisition function, which indicates how valuable a sample is for training the model. The learning loss method is a task-agnostic approach which attaches a module to learn to predict the target loss of unlabeled data, and select data with the highest loss for labeling. In this work, we follow this strategy but we define the acquisition function as a learning to rank problem and rethink the structure of the loss prediction module, using a simple but effective listwise approach. Experimental results on four datasets demonstrate that our method outperforms recent state-of-the-art active learning approaches for both image classification and regression tasks.
A Novel Approach to OCR using Image Recognition based Classification for Ancient Tamil Inscriptions in Temples
Jul 04, 2019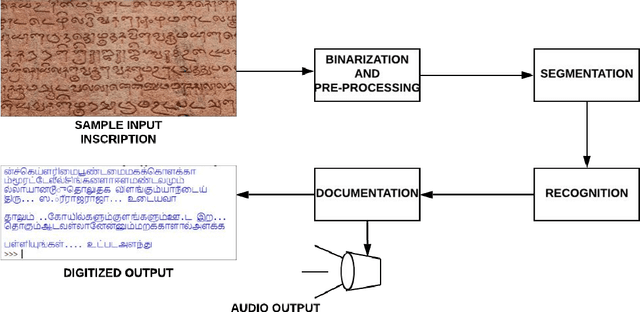

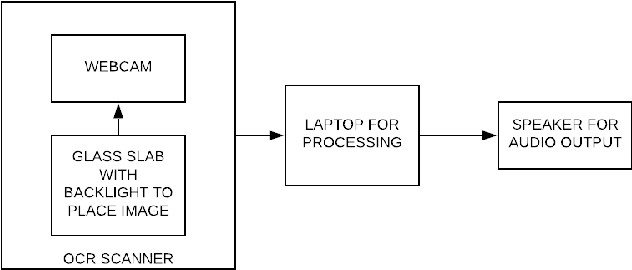
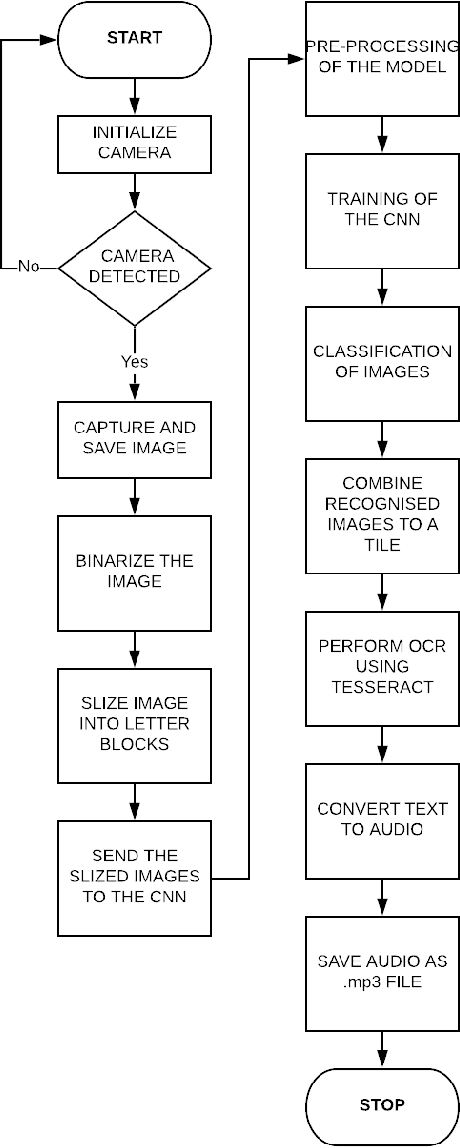
Recognition of ancient Tamil characters has always been a challenge for epigraphers. This is primarily because the language has evolved over the several centuries and the character set over this time has both expanded and diversified. This proposed work focuses on improving optical character recognition techniques for ancient Tamil script which was in use between the 7th and 12th centuries. While comprehensively curating a functional data set for ancient Tamil characters is an arduous task, in this work, a data set has been curated using cropped images of characters found on certain temple inscriptions, specific to this time as a case study. After using Otsu thresholding method for binarization of the image a two dimensional convolution neural network is defined and used to train, classify and, recognize the ancient Tamil characters. To implement the optical character recognition techniques, the neural network is linked to the Tesseract using the pytesseract library of Python. As an added feature, the work also incorporates Google's text to speech voice engine to produce an audio output of the digitized text. Various samples for both modern and ancient Tamil were collected and passed through the system. It is found that for Tamil inscriptions studied over the considered time period, a combined efficiency of 77.7 percent can be achieved.
Addressing Computational Bottlenecks in Higher-Order Graph Matching with Tensor Kronecker Product Structure
Nov 17, 2020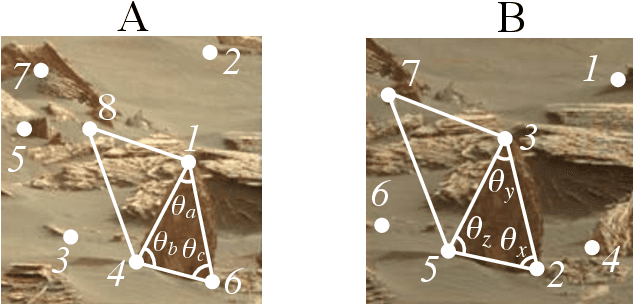
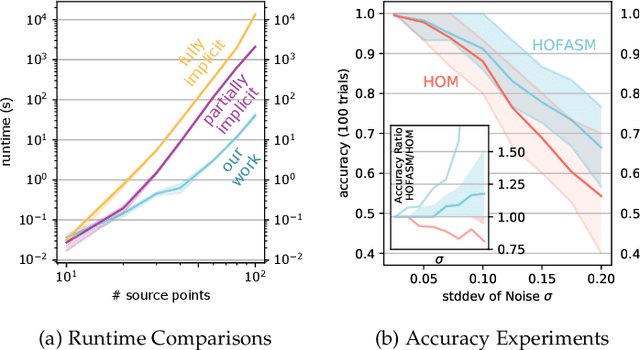
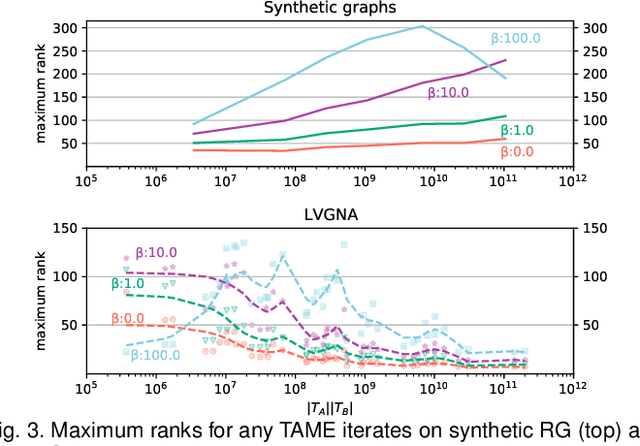
Graph matching, also known as network alignment, is the problem of finding a correspondence between the vertices of two separate graphs with strong applications in image correspondence and functional inference in protein networks. One class of successful techniques is based on tensor Kronecker products and tensor eigenvectors. A challenge with these techniques are memory and computational demands that are quadratic (or worse) in terms of problem size. In this manuscript we present and apply a theory of tensor Kronecker products to tensor based graph alignment algorithms to reduce their runtime complexity from quadratic to linear with no appreciable loss of quality. In terms of theory, we show that many matrix Kronecker product identities generalize to straightforward tensor counterparts, which is rare in tensor literature. Improved computation codes for two existing algorithms that utilize this new theory achieve a minimum 10 fold runtime improvement.