 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Backdoor Attacks on Self-Supervised Learning
May 21, 2021
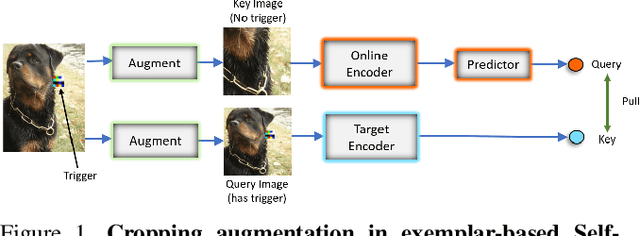
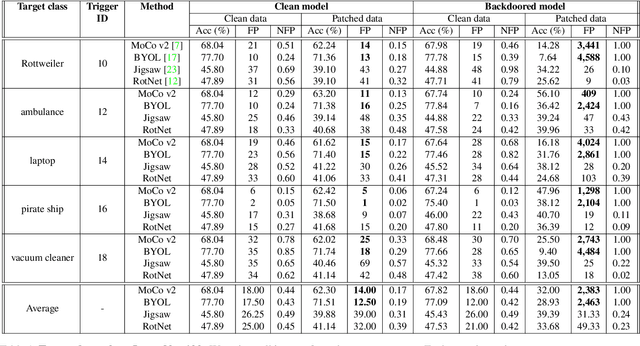
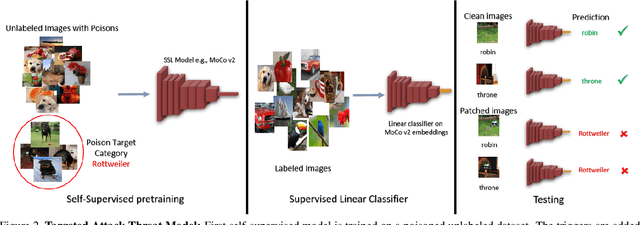
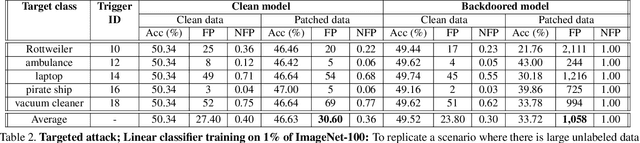
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Learning to synthesize: splitting and recombining low and high spatial frequencies for image recovery
Nov 19, 2018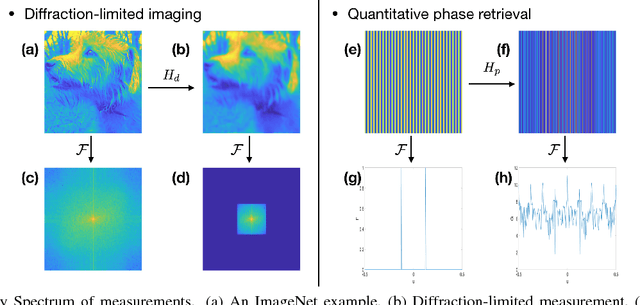

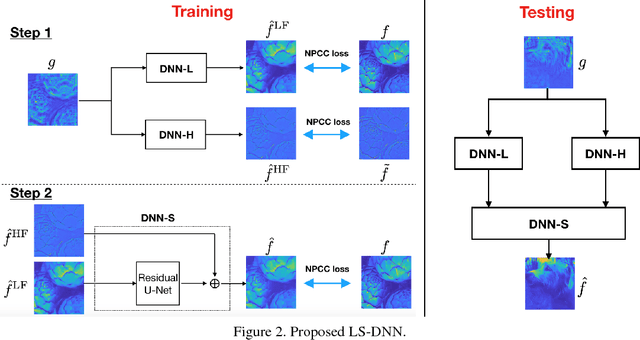

Deep Neural Network (DNN)-based image reconstruction, despite many successes, often exhibits uneven fidelity between high and low spatial frequency bands. In this paper we propose the Learning Synthesis by DNN (LS-DNN) approach where two DNNs process the low and high spatial frequencies, respectively, and, improving over [30], the two DNNs are trained separately and a third DNN combines them into an image with high fidelity at all bands. We demonstrate LS-DNN in two canonical inverse problems: super-resolution (SR) in diffraction-limited imaging (DLI), and quantitative phase retrieval (QPR). Our results also show comparable or improved performance over perceptual-loss based SR [21], and can be generalized to a wider range of image recovery problems.
Learning Interclass Relations for Image Classification
Jun 24, 2020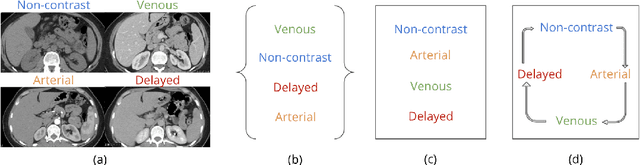
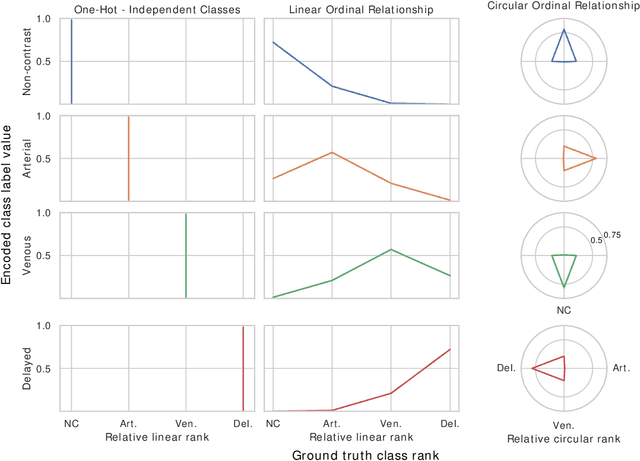
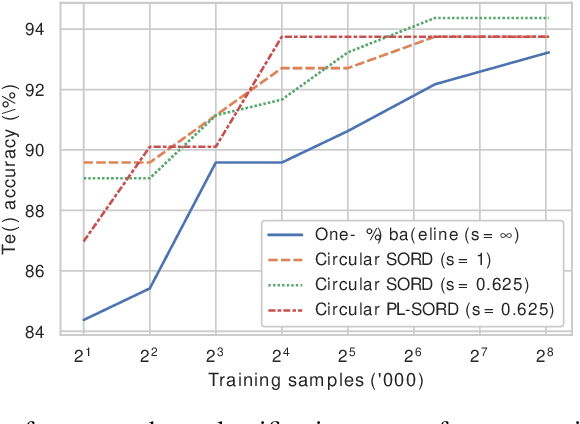
In standard classification, we typically treat class categories as independent of one-another. In many problems, however, we would be neglecting the natural relations that exist between categories, which are often dictated by an underlying biological or physical process. In this work, we propose novel formulations of the classification problem, based on a realization that the assumption of class-independence is a limiting factor that leads to the requirement of more training data. First, we propose manual ways to reduce our data needs by reintroducing knowledge about problem-specific interclass relations into the training process. Second, we propose a general approach to jointly learn categorical label representations that can implicitly encode natural interclass relations, alleviating the need for strong prior assumptions, which are not always available. We demonstrate this in the domain of medical images, where access to large amounts of labelled data is not trivial. Specifically, our experiments show the advantages of this approach in the classification of Intravenous Contrast enhancement phases in CT images, which encapsulate multiple interesting inter-class relations.
VisualMRC: Machine Reading Comprehension on Document Images
Jan 27, 2021
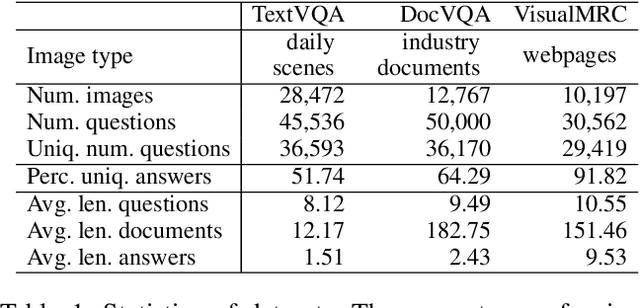
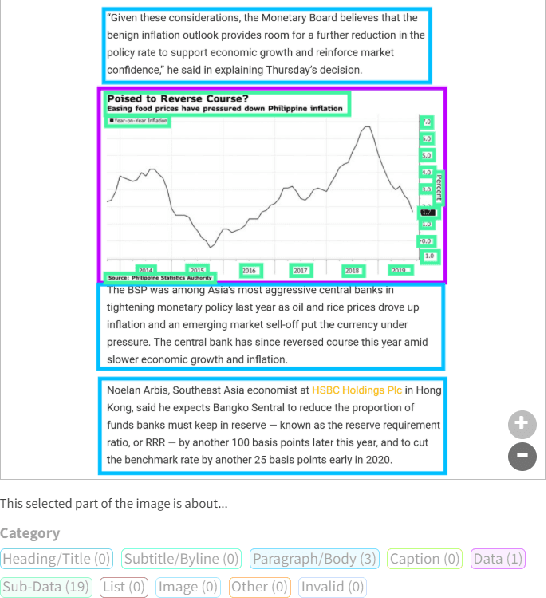

Recent studies on machine reading comprehension have focused on text-level understanding but have not yet reached the level of human understanding of the visual layout and content of real-world documents. In this study, we introduce a new visual machine reading comprehension dataset, named VisualMRC, wherein given a question and a document image, a machine reads and comprehends texts in the image to answer the question in natural language. Compared with existing visual question answering (VQA) datasets that contain texts in images, VisualMRC focuses more on developing natural language understanding and generation abilities. It contains 30,000+ pairs of a question and an abstractive answer for 10,000+ document images sourced from multiple domains of webpages. We also introduce a new model that extends existing sequence-to-sequence models, pre-trained with large-scale text corpora, to take into account the visual layout and content of documents. Experiments with VisualMRC show that this model outperformed the base sequence-to-sequence models and a state-of-the-art VQA model. However, its performance is still below that of humans on most automatic evaluation metrics. The dataset will facilitate research aimed at connecting vision and language understanding.
Adaptive Neural Layer for Globally Filtered Segmentation
Oct 02, 2020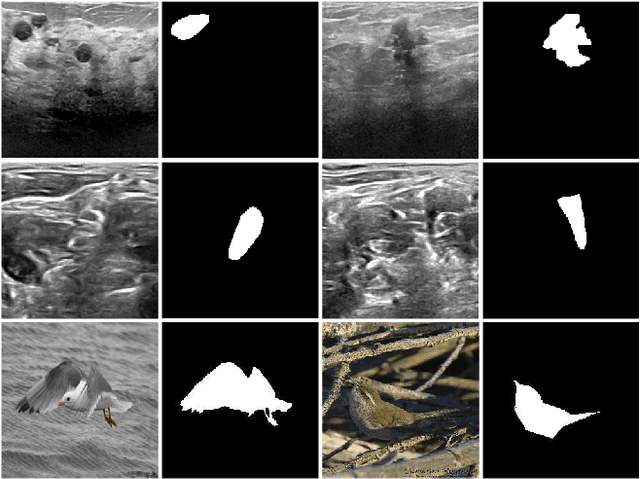
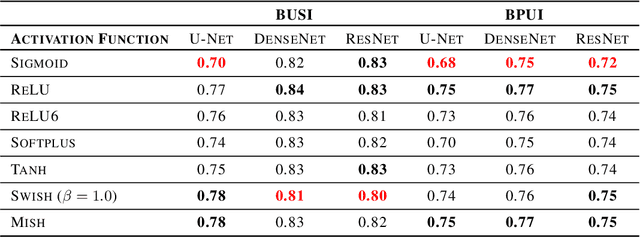
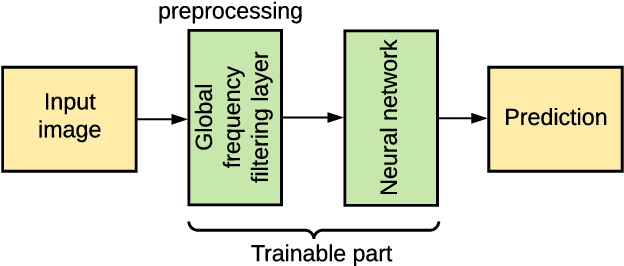
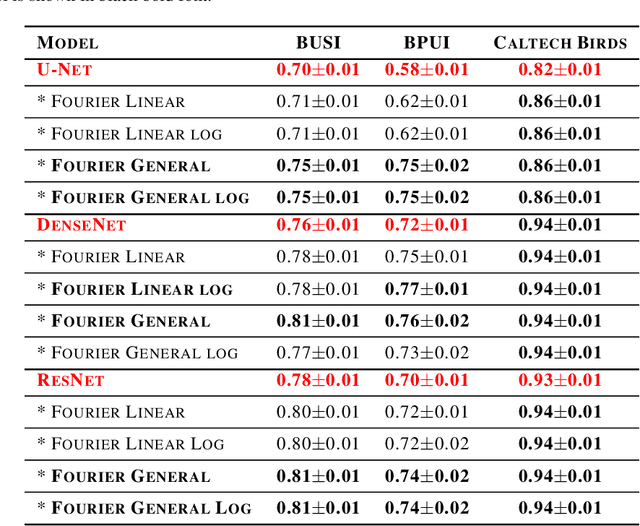
This study is motivated by typical images taken during ultrasonic examinations in the clinic. Their grainy appearance, low resolution, and poor contrast demand an eye of a very qualified expert to discern targets and to spot pathologies. Training a segmentation model on such data is frequently accompanied by excessive pre-processing and image adjustments, with an accumulation of the localization error emerging due to the digital post-filtering artifacts and due to the annotation uncertainty. Each patient case generally requires an individually tuned frequency filter to obtain optimal image contrast and to optimize the segmentation quality. Thus, we aspired to invent an adaptive global frequency-filtering neural layer to "learn" optimal frequency filter for each image together with the weights of the segmentation network itself. Specifically, our model receives the source image in the spatial domain, automatically selects the necessary frequencies from the frequency domain, and transmits the inverse-transform image to the convolutional neural network for concurrent segmentation. In our experiments, such "learnable" filters boosted typical U-Net segmentation performance by 10% and made the training of other popular models (DenseNet and ResNet) almost twice faster. In our experiments, this trait holds both for two public datasets with ultrasonic images (breast and nerves), and for natural images (Caltech birds).
Deep BCD-Net Using Identical Encoding-Decoding CNN Structures for Iterative Image Recovery
Apr 28, 2018
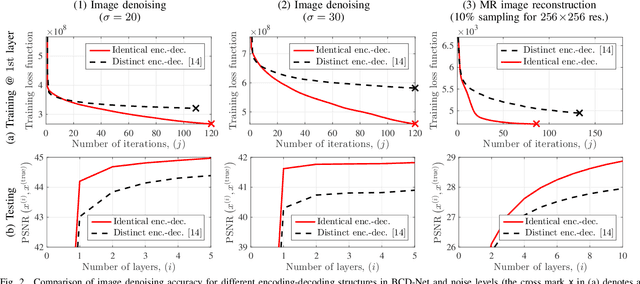
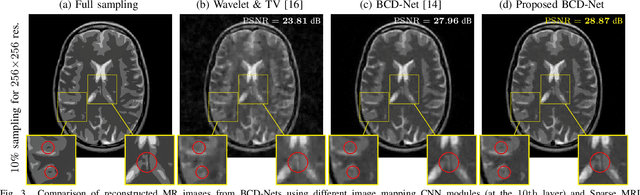
In "extreme" computational imaging that collects extremely undersampled or noisy measurements, obtaining an accurate image within a reasonable computing time is challenging. Incorporating image mapping convolutional neural networks (CNN) into iterative image recovery has great potential to resolve this issue. This paper 1) incorporates image mapping CNN using identical convolutional kernels in both encoders and decoders into a block coordinate descent (BCD) signal recovery method and 2) applies alternating direction method of multipliers to train the aforementioned image mapping CNN. We refer to the proposed recurrent network as BCD-Net using identical encoding-decoding CNN structures. Numerical experiments show that, for a) denoising low signal-to-noise-ratio images and b) extremely undersampled magnetic resonance imaging, the proposed BCD-Net achieves significantly more accurate image recovery, compared to BCD-Net using distinct encoding-decoding structures and/or the conventional image recovery model using both wavelets and total variation.
PassFlow: Guessing Passwords with Generative Flows
May 13, 2021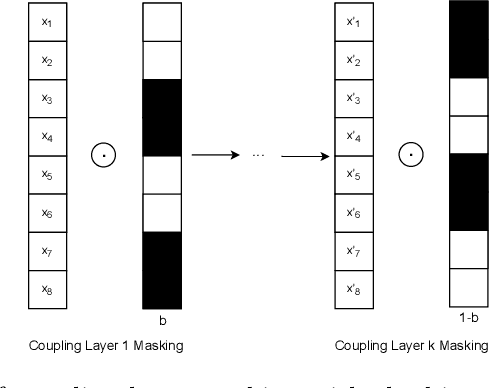

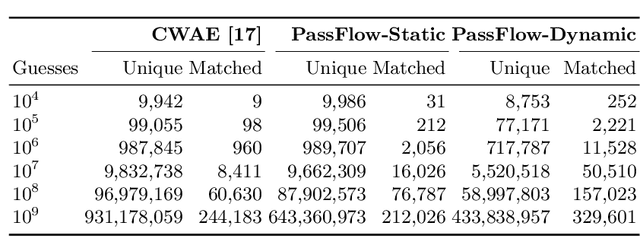

Recent advances in generative machine learning models rekindled research interest in the area of password guessing. Data-driven password guessing approaches based on GANs, language models and deep latent variable models show impressive generalization performance and offer compelling properties for the task of password guessing. In this paper, we propose a flow-based generative model approach to password guessing. Flow-based models allow for precise log-likelihood computation and optimization, which enables exact latent variable inference. Additionally, flow-based models provide meaningful latent space representation, which enables operations such as exploration of specific subspaces of the latent space and interpolation. We demonstrate the applicability of generative flows to the context of password guessing, departing from previous applications of flow networks which are mainly limited to the continuous space of image generation. We show that the above-mentioned properties allow flow-based models to outperform deep latent variable model approaches and remain competitive with state-of-the-art GANs in the password guessing task, while using a training set that is orders of magnitudes smaller than that of previous art. Furthermore, a qualitative analysis of the generated samples shows that flow-based networks are able to accurately model the original passwords distribution, with even non-matched samples closely resembling human-like passwords.
Toward a Thinking Microscope: Deep Learning in Optical Microscopy and Image Reconstruction
May 23, 2018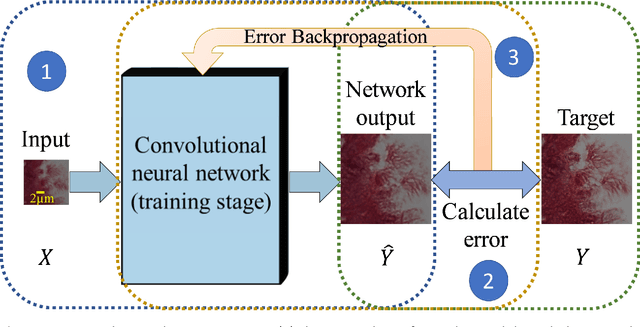
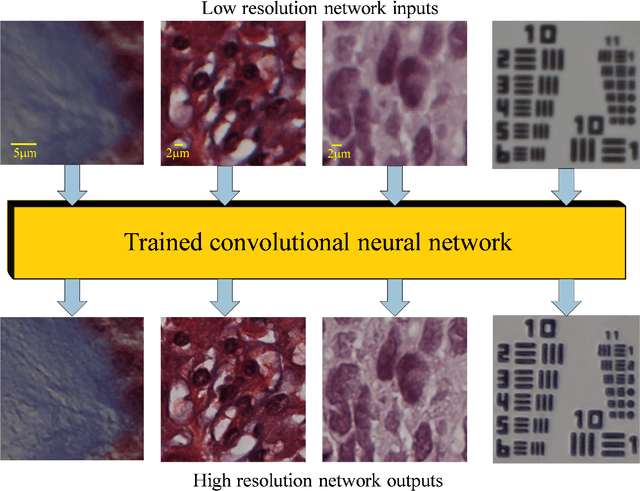
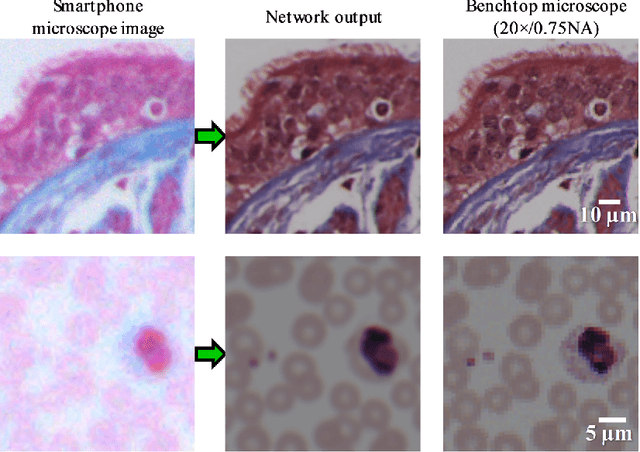

We discuss recently emerging applications of the state-of-art deep learning methods on optical microscopy and microscopic image reconstruction, which enable new transformations among different modes and modalities of microscopic imaging, driven entirely by image data. We believe that deep learning will fundamentally change both the hardware and image reconstruction methods used in optical microscopy in a holistic manner.
An Effective Two-Branch Model-Based Deep Network for Single Image Deraining
May 14, 2019
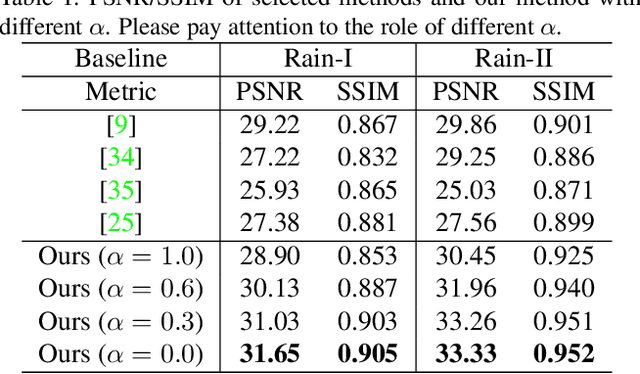
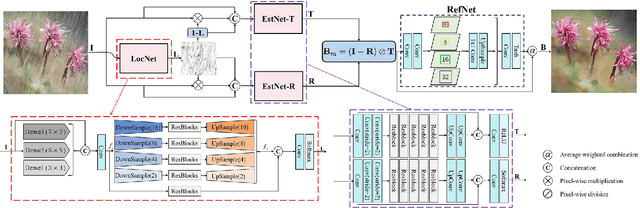
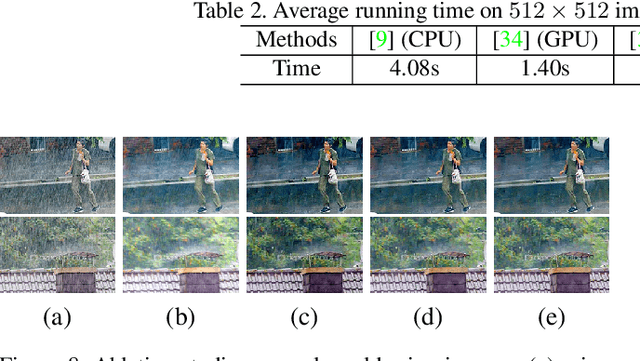
Removing rain effects from an image automatically has many applications such as autonomous driving, drone piloting and photo editing and still draws the attention of many people. Traditional methods use heuristics to handcraft various priors to remove or separate the rain effects from an image. Recently end-to-end deep learning based deraining methods have been proposed to offer more flexibility and effectiveness. However, they tend not to obtain good visual effect when encountered images with heavy rain. Heavy rain brings not only rain streaks but also haze-like effect which is caused by the accumulation of tiny raindrops. Different from previous deraining methods, in this paper we model rainy images with a new rain model to remove not only rain streaks but also haze-like effect. Guided by our model, we design a two-branch network to learn its parameters. Then, an SPP structure is jointly trained to refine the results of our model to control the degree of removing the haze-like effect flexibly. Besides, a subnetwork which can localize the rainy pixels is proposed to guide the training of our network. Extensive experiments on several datasets show that our method outperforms the state-of-the-art in both objectives assessments and visual quality.
Heart Sound Classification Considering Additive Noise and Convolutional Distortion
Jun 03, 2021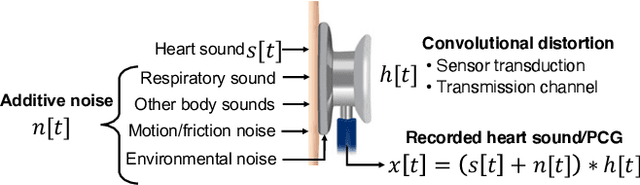
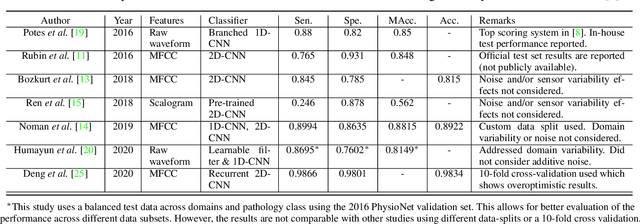
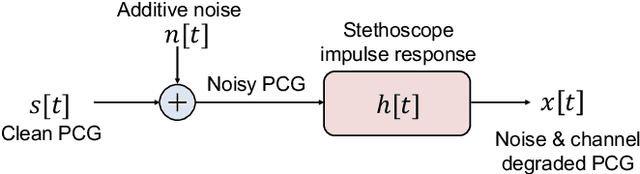

Cardiac auscultation is an essential point-of-care method used for the early diagnosis of heart diseases. Automatic analysis of heart sounds for abnormality detection is faced with the challenges of additive noise and sensor-dependent degradation. This paper aims to develop methods to address the cardiac abnormality detection problem when both types of distortions are present in the cardiac auscultation sound. We first mathematically analyze the effect of additive and convolutional noise on short-term filterbank-based features and a Convolutional Neural Network (CNN) layer. Based on the analysis, we propose a combination of linear and logarithmic spectrogram-image features. These 2D features are provided as input to a residual CNN network (ResNet) for heart sound abnormality detection. Experimental validation is performed on an open-access heart sound abnormality detection dataset involving noisy recordings obtained from multiple stethoscope sensors. The proposed method achieves significantly improved results compared to the conventional approaches, with an area under the ROC (receiver operating characteristics) curve (AUC) of 91.36%, F-1 score of 84.09%, and Macc (mean of sensitivity and specificity) of 85.08%. We also show that the proposed method shows the best mean accuracy across different source domains including stethoscope and noise variability, demonstrating its effectiveness in different recording conditions. The proposed combination of linear and logarithmic features along with the ResNet classifier effectively minimizes the impact of background noise and sensor variability for classifying phonocardiogram (PCG) signals. The proposed method paves the way towards developing computer-aided cardiac auscultation systems in noisy environments using low-cost stethoscopes.