 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inconsistency Masks: Removing the Uncertainty from Input-Pseudo-Label Pairs
Jan 25, 2024
Generating sufficient labeled data is a significant hurdle in the efficient execution of deep learning projects, especially in uncharted territories of image segmentation where labeling demands extensive time, unlike classification tasks. Our study confronts this challenge, operating in an environment constrained by limited hardware resources and the lack of extensive datasets or pre-trained models. We introduce the novel use of Inconsistency Masks (IM) to effectively filter uncertainty in image-pseudo-label pairs, substantially elevating segmentation quality beyond traditional semi-supervised learning techniques. By integrating IM with other methods, we demonstrate remarkable binary segmentation performance on the ISIC 2018 dataset, starting with just 10% labeled data. Notably, three of our hybrid models outperform those trained on the fully labeled dataset. Our approach consistently achieves exceptional results across three additional datasets and shows further improvement when combined with other techniques. For comprehensive and robust evaluation, this paper includes an extensive analysis of prevalent semi-supervised learning strategies, all trained under identical starting conditions. The full code is available at: https://github.com/MichaelVorndran/InconsistencyMasks
Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images
Jan 25, 2024Capturing the diversity of people in images is challenging: recent literature tends to focus on diversifying one or two attributes, requiring expensive attribute labels or building classifiers. We introduce a diverse people image ranking method which more flexibly aligns with human notions of people diversity in a less prescriptive, label-free manner. The Perception-Aligned Text-derived Human representation Space (PATHS) aims to capture all or many relevant features of people-related diversity, and, when used as the representation space in the standard Maximal Marginal Relevance (MMR) ranking algorithm, is better able to surface a range of types of people-related diversity (e.g. disability, cultural attire). PATHS is created in two stages. First, a text-guided approach is used to extract a person-diversity representation from a pre-trained image-text model. Then this representation is fine-tuned on perception judgments from human annotators so that it captures the aspects of people-related similarity that humans find most salient. Empirical results show that the PATHS method achieves diversity better than baseline methods, according to side-by-side ratings from human annotators.
Combining Image- and Geometric-based Deep Learning for Shape Regression: A Comparison to Pixel-level Methods for Segmentation in Chest X-Ray
Jan 15, 2024When solving a segmentation task, shaped-base methods can be beneficial compared to pixelwise classification due to geometric understanding of the target object as shape, preventing the generation of anatomical implausible predictions in particular for corrupted data. In this work, we propose a novel hybrid method that combines a lightweight CNN backbone with a geometric neural network (Point Transformer) for shape regression. Using the same CNN encoder, the Point Transformer reaches segmentation quality on per with current state-of-the-art convolutional decoders ($4\pm1.9$ vs $3.9\pm2.9$ error in mm and $85\pm13$ vs $88\pm10$ Dice), but crucially, is more stable w.r.t image distortion, starting to outperform them at a corruption level of 30%. Furthermore, we include the nnU-Net as an upper baseline, which has $3.7\times$ more trainable parameters than our proposed method.
Do You Guys Want to Dance: Zero-Shot Compositional Human Dance Generation with Multiple Persons
Jan 24, 2024Human dance generation (HDG) aims to synthesize realistic videos from images and sequences of driving poses. Despite great success, existing methods are limited to generating videos of a single person with specific backgrounds, while the generalizability for real-world scenarios with multiple persons and complex backgrounds remains unclear. To systematically measure the generalizability of HDG models, we introduce a new task, dataset, and evaluation protocol of compositional human dance generation (cHDG). Evaluating the state-of-the-art methods on cHDG, we empirically find that they fail to generalize to real-world scenarios. To tackle the issue, we propose a novel zero-shot framework, dubbed MultiDance-Zero, that can synthesize videos consistent with arbitrary multiple persons and background while precisely following the driving poses. Specifically, in contrast to straightforward DDIM or null-text inversion, we first present a pose-aware inversion method to obtain the noisy latent code and initialization text embeddings, which can accurately reconstruct the composed reference image. Since directly generating videos from them will lead to severe appearance inconsistency, we propose a compositional augmentation strategy to generate augmented images and utilize them to optimize a set of generalizable text embeddings. In addition, consistency-guided sampling is elaborated to encourage the background and keypoints of the estimated clean image at each reverse step to be close to those of the reference image, further improving the temporal consistency of generated videos. Extensive qualitative and quantitative results demonstrate the effectiveness and superiority of our approach.
Dual-modal Dynamic Traceback Learning for Medical Report Generation
Jan 24, 2024With increasing reliance on medical imaging in clinical practices, automated report generation from medical images is in great demand. Existing report generation methods typically adopt an encoder-decoder deep learning framework to build a uni-directional image-to-report mapping. However, such a framework ignores the bi-directional mutual associations between images and reports, thus incurring difficulties in associating the intrinsic medical meanings between them. Recent generative representation learning methods have demonstrated the benefits of dual-modal learning from both image and text modalities. However, these methods exhibit two major drawbacks for medical report generation: 1) they tend to capture morphological information and have difficulties in capturing subtle pathological semantic information, and 2) they predict masked text rely on both unmasked images and text, inevitably degrading performance when inference is based solely on images. In this study, we propose a new report generation framework with dual-modal dynamic traceback learning (DTrace) to overcome the two identified drawbacks and enable dual-modal learning for medical report generation. To achieve this, our DTrace introduces a traceback mechanism to control the semantic validity of generated content via self-assessment. Further, our DTrace introduces a dynamic learning strategy to adapt to various proportions of image and text input, enabling report generation without reliance on textual input during inference. Extensive experiments on two well-benchmarked datasets (IU-Xray and MIMIC-CXR) show that our DTrace outperforms state-of-the-art medical report generation methods.
Study of the gOMP Algorithm for Recovery of Compressed Sensed Hyperspectral Images
Jan 26, 2024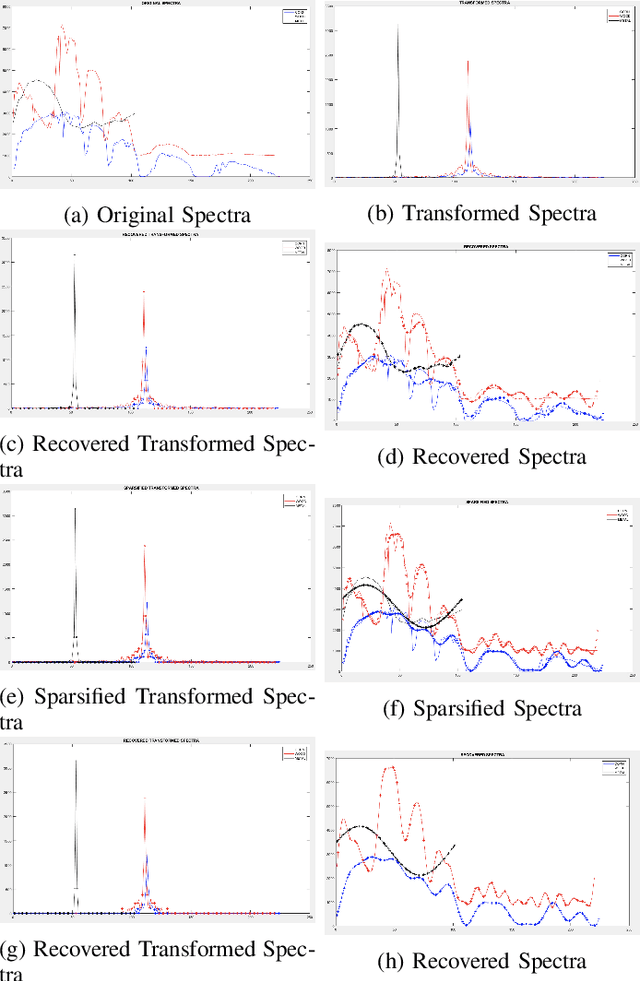


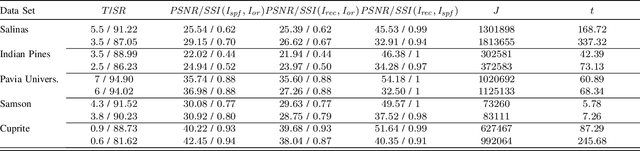
Hyperspectral Imaging (HSI) is used in a wide range of applications such as remote sensing, yet the transmission of the HS images by communication data links becomes challenging due to the large number of spectral bands that the HS images contain together with the limited data bandwidth available in real applications. Compressive Sensing reduces the images by randomly subsampling the spectral bands of each spatial pixel and then it performs the image reconstruction of all the bands using recovery algorithms which impose sparsity in a certain transform domain. Since the image pixels are not strictly sparse, this work studies a data sparsification pre-processing stage prior to compression to ensure the sparsity of the pixels. The sparsified images are compressed $2.5\times$ and then recovered using the Generalized Orthogonal Matching Pursuit algorithm (gOMP) characterized by high accuracy, low computational requirements and fast convergence. The experiments are performed in five conventional hyperspectral images where the effect of different sparsification levels in the quality of the uncompressed as well as the recovered images is studied. It is concluded that the gOMP algorithm reconstructs the hyperspectral images with higher accuracy as well as faster convergence when the pixels are highly sparsified and hence at the expense of reducing the quality of the recovered images with respect to the original images.
Divide and Conquer: Rethinking the Training Paradigm of Neural Radiance Fields
Jan 29, 2024Neural radiance fields (NeRFs) have exhibited potential in synthesizing high-fidelity views of 3D scenes but the standard training paradigm of NeRF presupposes an equal importance for each image in the training set. This assumption poses a significant challenge for rendering specific views presenting intricate geometries, thereby resulting in suboptimal performance. In this paper, we take a closer look at the implications of the current training paradigm and redesign this for more superior rendering quality by NeRFs. Dividing input views into multiple groups based on their visual similarities and training individual models on each of these groups enables each model to specialize on specific regions without sacrificing speed or efficiency. Subsequently, the knowledge of these specialized models is aggregated into a single entity via a teacher-student distillation paradigm, enabling spatial efficiency for online render-ing. Empirically, we evaluate our novel training framework on two publicly available datasets, namely NeRF synthetic and Tanks&Temples. Our evaluation demonstrates that our DaC training pipeline enhances the rendering quality of a state-of-the-art baseline model while exhibiting convergence to a superior minimum.
Hyper-VolTran: Fast and Generalizable One-Shot Image to 3D Object Structure via HyperNetworks
Jan 05, 2024Solving image-to-3D from a single view is an ill-posed problem, and current neural reconstruction methods addressing it through diffusion models still rely on scene-specific optimization, constraining their generalization capability. To overcome the limitations of existing approaches regarding generalization and consistency, we introduce a novel neural rendering technique. Our approach employs the signed distance function as the surface representation and incorporates generalizable priors through geometry-encoding volumes and HyperNetworks. Specifically, our method builds neural encoding volumes from generated multi-view inputs. We adjust the weights of the SDF network conditioned on an input image at test-time to allow model adaptation to novel scenes in a feed-forward manner via HyperNetworks. To mitigate artifacts derived from the synthesized views, we propose the use of a volume transformer module to improve the aggregation of image features instead of processing each viewpoint separately. Through our proposed method, dubbed as Hyper-VolTran, we avoid the bottleneck of scene-specific optimization and maintain consistency across the images generated from multiple viewpoints. Our experiments show the advantages of our proposed approach with consistent results and rapid generation.
Leveraging Swin Transformer for Local-to-Global Weakly Supervised Semantic Segmentation
Jan 31, 2024In recent years, weakly supervised semantic segmentation using image-level labels as supervision has received significant attention in the field of computer vision. Most existing methods have addressed the challenges arising from the lack of spatial information in these labels by focusing on facilitating supervised learning through the generation of pseudo-labels from class activation maps (CAMs). Due to the localized pattern detection of Convolutional Neural Networks (CNNs), CAMs often emphasize only the most discriminative parts of an object, making it challenging to accurately distinguish foreground objects from each other and the background. Recent studies have shown that Vision Transformer (ViT) features, due to their global view, are more effective in capturing the scene layout than CNNs. However, the use of hierarchical ViTs has not been extensively explored in this field. This work explores the use of Swin Transformer by proposing "SWTformer" to enhance the accuracy of the initial seed CAMs by bringing local and global views together. SWTformer-V1 generates class probabilities and CAMs using only the patch tokens as features. SWTformer-V2 incorporates a multi-scale feature fusion mechanism to extract additional information and utilizes a background-aware mechanism to generate more accurate localization maps with improved cross-object discrimination. Based on experiments on the PascalVOC 2012 dataset, SWTformer-V1 achieves a 0.98% mAP higher localization accuracy, outperforming state-of-the-art models. It also yields comparable performance by 0.82% mIoU on average higher than other methods in generating initial localization maps, depending only on the classification network. SWTformer-V2 further improves the accuracy of the generated seed CAMs by 5.32% mIoU, further proving the effectiveness of the local-to-global view provided by the Swin transformer.
Zero-shot Classification using Hyperdimensional Computing
Jan 30, 2024Classification based on Zero-shot Learning (ZSL) is the ability of a model to classify inputs into novel classes on which the model has not previously seen any training examples. Providing an auxiliary descriptor in the form of a set of attributes describing the new classes involved in the ZSL-based classification is one of the favored approaches to solving this challenging task. In this work, inspired by Hyperdimensional Computing (HDC), we propose the use of stationary binary codebooks of symbol-like distributed representations inside an attribute encoder to compactly represent a computationally simple end-to-end trainable model, which we name Hyperdimensional Computing Zero-shot Classifier~(HDC-ZSC). It consists of a trainable image encoder, an attribute encoder based on HDC, and a similarity kernel. We show that HDC-ZSC can be used to first perform zero-shot attribute extraction tasks and, can later be repurposed for Zero-shot Classification tasks with minimal architectural changes and minimal model retraining. HDC-ZSC achieves Pareto optimal results with a 63.8% top-1 classification accuracy on the CUB-200 dataset by having only 26.6 million trainable parameters. Compared to two other state-of-the-art non-generative approaches, HDC-ZSC achieves 4.3% and 9.9% better accuracy, while they require more than 1.85x and 1.72x parameters compared to HDC-ZSC, respectively.