 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-guided Medical Image Segmentation with Target-informed Multi-level Contrastive Alignments
Dec 18, 2024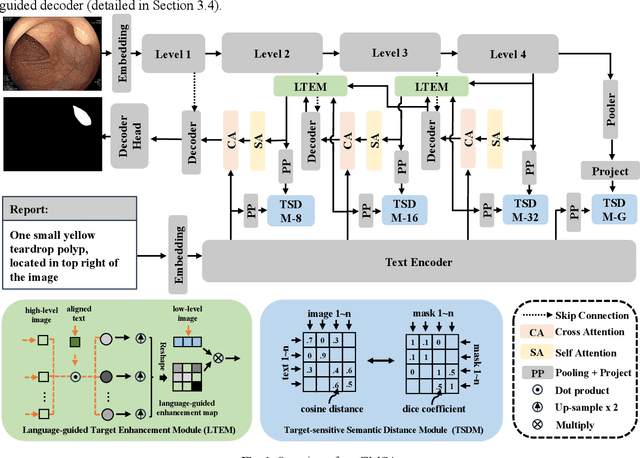
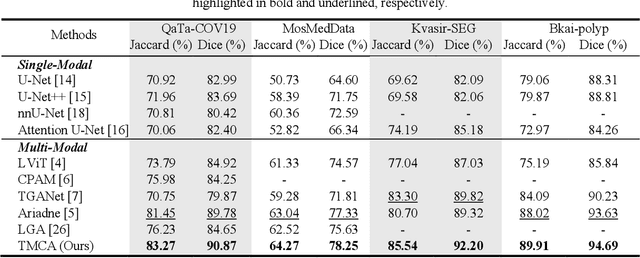

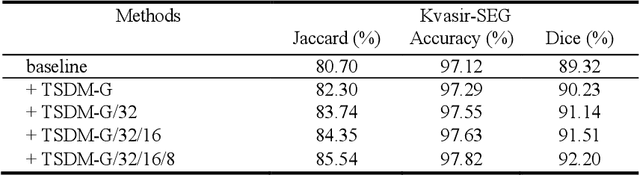
Medical image segmentation is crucial in modern medical image analysis, which can aid into diagnosis of various disease conditions. Recently, language-guided segmentation methods have shown promising results in automating image segmentation where text reports are incorporated as guidance. These text reports, containing image impressions and insights given by clinicians, provides auxiliary guidance. However, these methods neglect the inherent pattern gaps between the two distinct modalities, which leads to sub-optimal image-text feature fusion without proper cross-modality feature alignments. Contrastive alignments are widely used to associate image-text semantics in representation learning; however, it has not been exploited to bridge the pattern gaps in language-guided segmentation that relies on subtle low level image details to represent diseases. Existing contrastive alignment methods typically algin high-level global image semantics without involving low-level, localized target information, and therefore fails to explore fine-grained text guidance for language-guided segmentation. In this study, we propose a language-guided segmentation network with Target-informed Multi-level Contrastive Alignments (TMCA). TMCA enables target-informed cross-modality alignments and fine-grained text guidance to bridge the pattern gaps in language-guided segmentation. Specifically, we introduce: 1) a target-sensitive semantic distance module that enables granular image-text alignment modelling, and 2) a multi-level alignment strategy that directs text guidance on low-level image features. In addition, a language-guided target enhancement module is proposed to leverage the aligned text to redirect attention to focus on critical localized image features. Extensive experiments on 4 image-text datasets, involving 3 medical imaging modalities, demonstrated that our TMCA achieved superior performances.
SGSeg: Enabling Text-free Inference in Language-guided Segmentation of Chest X-rays via Self-guidance
Sep 07, 2024Segmentation of infected areas in chest X-rays is pivotal for facilitating the accurate delineation of pulmonary structures and pathological anomalies. Recently, multi-modal language-guided image segmentation methods have emerged as a promising solution for chest X-rays where the clinical text reports, depicting the assessment of the images, are used as guidance. Nevertheless, existing language-guided methods require clinical reports alongside the images, and hence, they are not applicable for use in image segmentation in a decision support context, but rather limited to retrospective image analysis after clinical reporting has been completed. In this study, we propose a self-guided segmentation framework (SGSeg) that leverages language guidance for training (multi-modal) while enabling text-free inference (uni-modal), which is the first that enables text-free inference in language-guided segmentation. We exploit the critical location information of both pulmonary and pathological structures depicted in the text reports and introduce a novel localization-enhanced report generation (LERG) module to generate clinical reports for self-guidance. Our LERG integrates an object detector and a location-based attention aggregator, weakly-supervised by a location-aware pseudo-label extraction module. Extensive experiments on a well-benchmarked QaTa-COV19 dataset demonstrate that our SGSeg achieved superior performance than existing uni-modal segmentation methods and closely matched the state-of-the-art performance of multi-modal language-guided segmentation methods.
Dual-modal Dynamic Traceback Learning for Medical Report Generation
Jan 24, 2024



With increasing reliance on medical imaging in clinical practices, automated report generation from medical images is in great demand. Existing report generation methods typically adopt an encoder-decoder deep learning framework to build a uni-directional image-to-report mapping. However, such a framework ignores the bi-directional mutual associations between images and reports, thus incurring difficulties in associating the intrinsic medical meanings between them. Recent generative representation learning methods have demonstrated the benefits of dual-modal learning from both image and text modalities. However, these methods exhibit two major drawbacks for medical report generation: 1) they tend to capture morphological information and have difficulties in capturing subtle pathological semantic information, and 2) they predict masked text rely on both unmasked images and text, inevitably degrading performance when inference is based solely on images. In this study, we propose a new report generation framework with dual-modal dynamic traceback learning (DTrace) to overcome the two identified drawbacks and enable dual-modal learning for medical report generation. To achieve this, our DTrace introduces a traceback mechanism to control the semantic validity of generated content via self-assessment. Further, our DTrace introduces a dynamic learning strategy to adapt to various proportions of image and text input, enabling report generation without reliance on textual input during inference. Extensive experiments on two well-benchmarked datasets (IU-Xray and MIMIC-CXR) show that our DTrace outperforms state-of-the-art medical report generation methods.
Enhancing medical vision-language contrastive learning via inter-matching relation modelling
Jan 19, 2024



Medical image representations can be learned through medical vision-language contrastive learning (mVLCL) where medical imaging reports are used as weak supervision through image-text alignment. These learned image representations can be transferred to and benefit various downstream medical vision tasks such as disease classification and segmentation. Recent mVLCL methods attempt to align image sub-regions and the report keywords as local-matchings. However, these methods aggregate all local-matchings via simple pooling operations while ignoring the inherent relations between them. These methods therefore fail to reason between local-matchings that are semantically related, e.g., local-matchings that correspond to the disease word and the location word (semantic-relations), and also fail to differentiate such clinically important local-matchings from others that correspond to less meaningful words, e.g., conjunction words (importance-relations). Hence, we propose a mVLCL method that models the inter-matching relations between local-matchings via a relation-enhanced contrastive learning framework (RECLF). In RECLF, we introduce a semantic-relation reasoning module (SRM) and an importance-relation reasoning module (IRM) to enable more fine-grained report supervision for image representation learning. We evaluated our method using four public benchmark datasets on four downstream tasks, including segmentation, zero-shot classification, supervised classification, and cross-modal retrieval. Our results demonstrated the superiority of our RECLF over the state-of-the-art mVLCL methods with consistent improvements across single-modal and cross-modal tasks. These results suggest that our RECLF, by modelling the inter-matching relations, can learn improved medical image representations with better generalization capabilities.