 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Yelp Food Identification via Image Feature Extraction and Classification
Feb 11, 2019

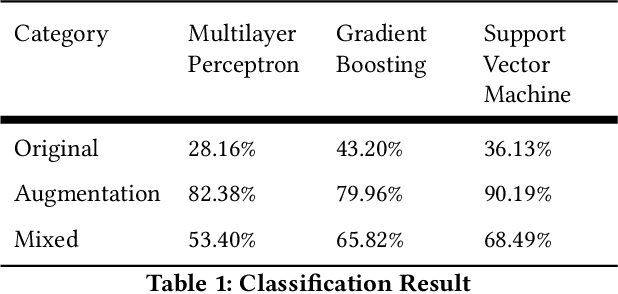

Yelp has been one of the most popular local service search engine in US since 2004. It is powered by crowd-sourced text reviews and photo reviews. Restaurant customers and business owners upload photo images to Yelp, including reviewing or advertising either food, drinks, or inside and outside decorations. It is obviously not so effective that labels for food photos rely on human editors, which is an issue should be addressed by innovative machine learning approaches. In this paper, we present a simple but effective approach which can identify up to ten kinds of food via raw photos from the challenge dataset. We use 1) image pre-processing techniques, including filtering and image augmentation, 2) feature extraction via convolutional neural networks (CNN), and 3) three ways of classification algorithms. Then, we illustrate the classification accuracy by tuning parameters for augmentations, CNN, and classification. Our experimental results show this simple but effective approach to identify up to 10 food types from images.
Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback
Sep 24, 2018
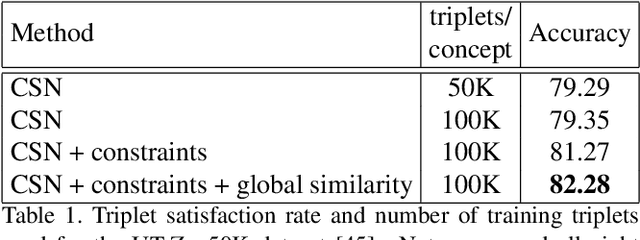
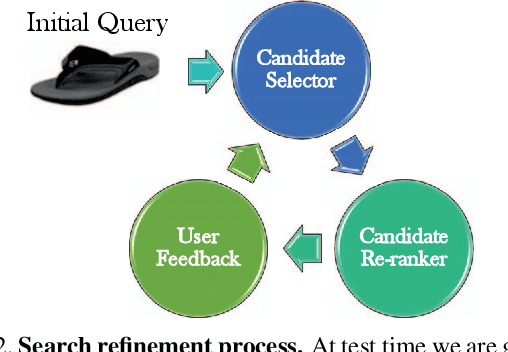
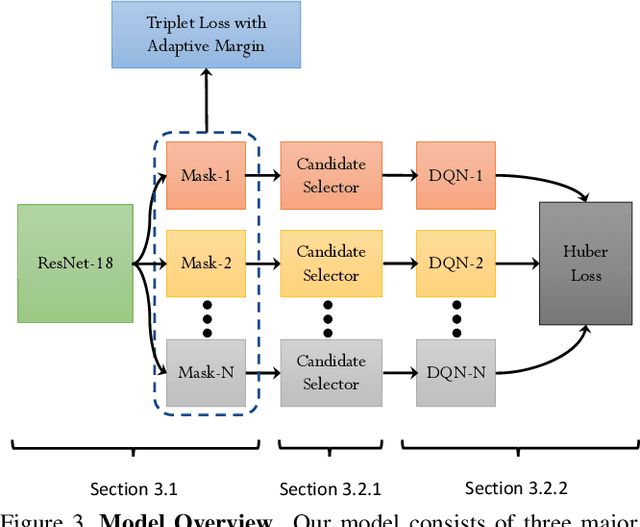
In this paper, we introduce an attribute-based interactive image search which can leverage human-in-the-loop feedback to iteratively refine image search results. We study active image search where human feedback is solicited exclusively in visual form, without using relative attribute annotations used by prior work which are not typically found in many datasets. In order to optimize the image selection strategy, a deep reinforcement model is trained to learn what images are informative rather than rely on hand-crafted measures typically leveraged in prior work. Additionally, we extend the recently introduced Conditional Similarity Network to incorporate global similarity in training visual embeddings, which results in more natural transitions as the user explores the learned similarity embeddings. Our experiments demonstrate the effectiveness of our approach, producing compelling results on both active image search and image attribute representation tasks.
Machine learning based hyperspectral image analysis: A survey
Feb 23, 2018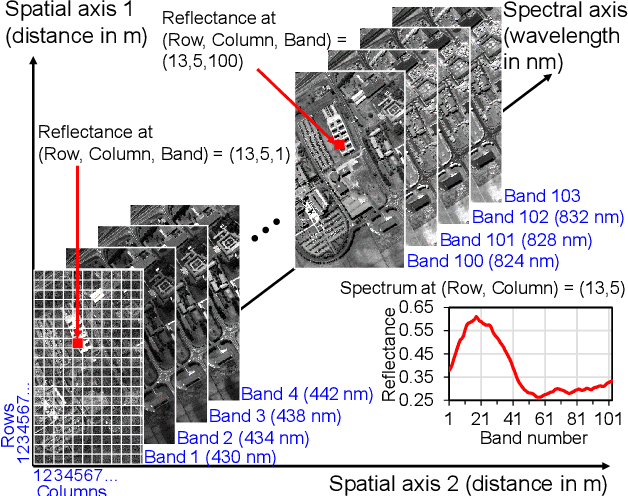
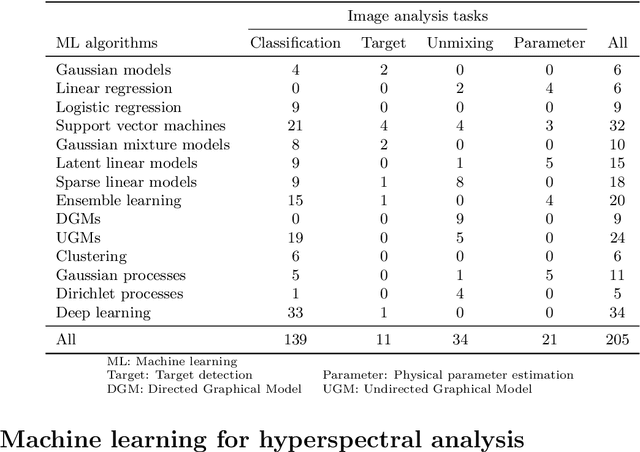
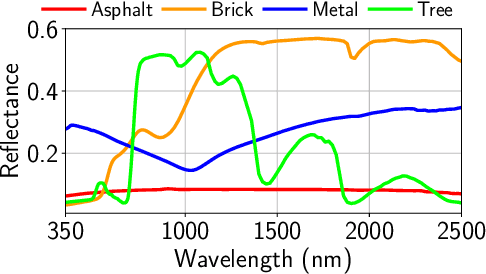
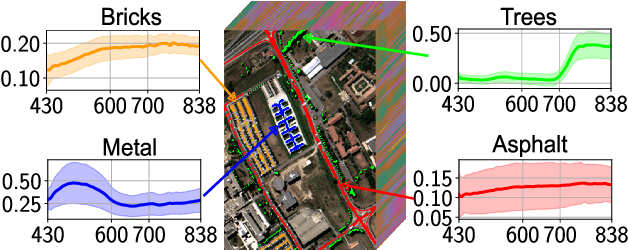
Hyperspectral sensors enable the study of the chemical properties of scene materials remotely for the purpose of identification, detection, and chemical composition analysis of objects in the environment. Hence, hyperspectral images captured from earth observing satellites and aircraft have been increasingly important in agriculture, environmental monitoring, urban planning, mining, and defense. Machine learning algorithms due to their outstanding predictive power have become a key tool for modern hyperspectral image analysis. Therefore, a solid understanding of machine learning techniques have become essential for remote sensing researchers and practitioners. This paper reviews and compares recent machine learning-based hyperspectral image analysis methods published in literature. We organize the methods by the image analysis task and by the type of machine learning algorithm, and present a two-way mapping between the image analysis tasks and the types of machine learning algorithms that can be applied to them. The paper is comprehensive in coverage of both hyperspectral image analysis tasks and machine learning algorithms. The image analysis tasks considered are land cover classification, target detection, unmixing, and physical parameter estimation. The machine learning algorithms covered are Gaussian models, linear regression, logistic regression, support vector machines, Gaussian mixture model, latent linear models, sparse linear models, Gaussian mixture models, ensemble learning, directed graphical models, undirected graphical models, clustering, Gaussian processes, Dirichlet processes, and deep learning. We also discuss the open challenges in the field of hyperspectral image analysis and explore possible future directions.
Braille to Text Translation for Bengali Language: A Geometric Approach
Dec 02, 2020
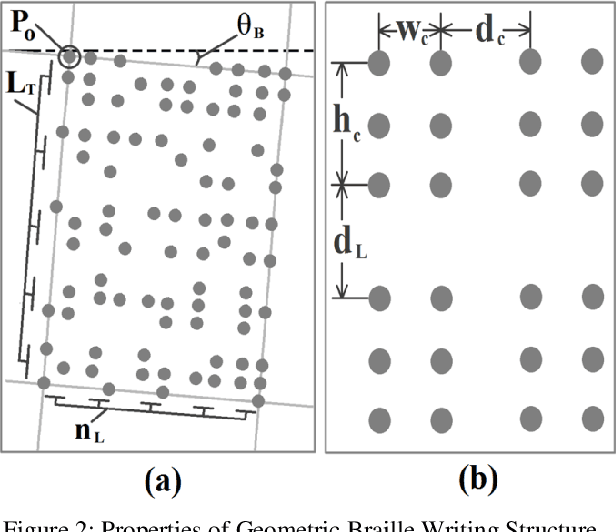
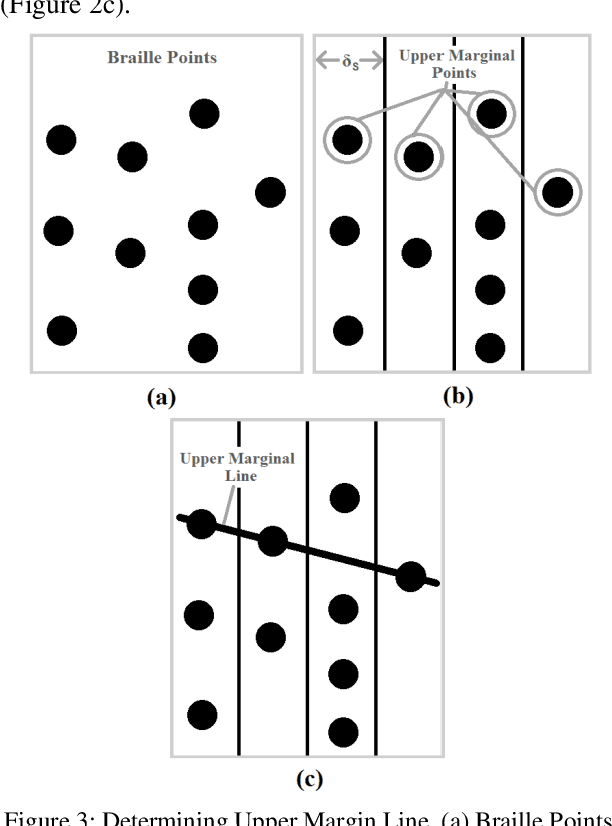
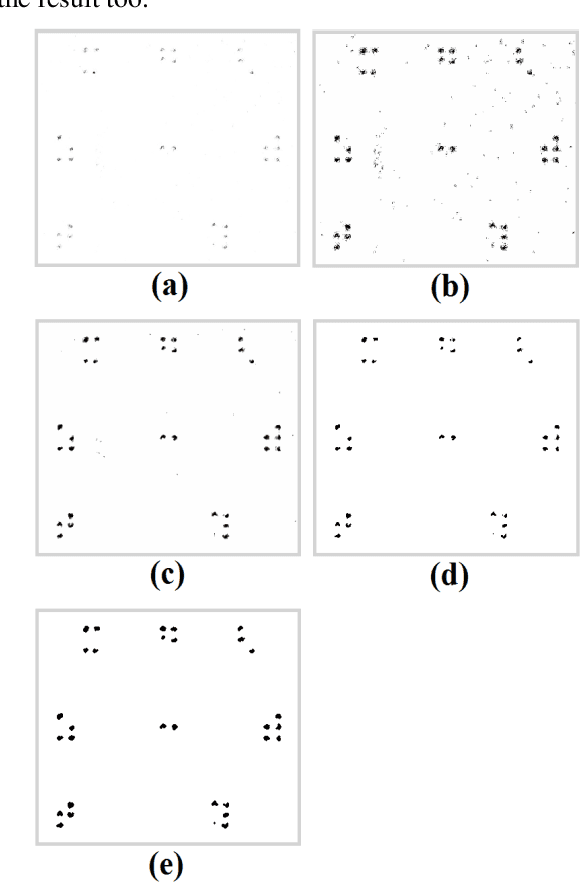
Braille is the only system to visually impaired people for reading and writing. However, general people cannot read Braille. So, teachers and relatives find it hard to assist them with learning. Almost every major language has software solutions for this translation purpose. However, in Bengali there is an absence of this useful tool. Here, we propose Braille to Text Translator, which takes image of these tactile alphabets, and translates them to plain text. Image deterioration, scan-time page rotation, and braille dot deformation are the principal issues in this scheme. All of these challenges are directly checked using special image processing and geometric structure analysis. The technique yields 97.25% accuracy in recognizing Braille characters.
Recent Advances and Trends in Multimodal Deep Learning: A Review
May 24, 2021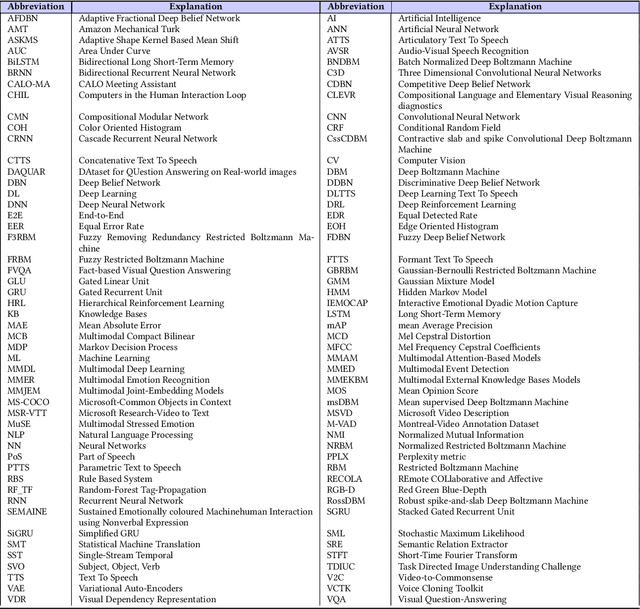
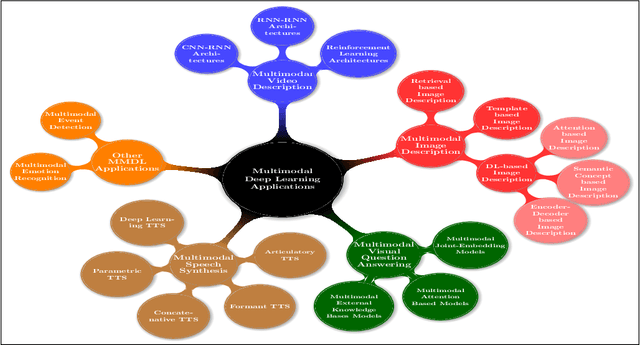

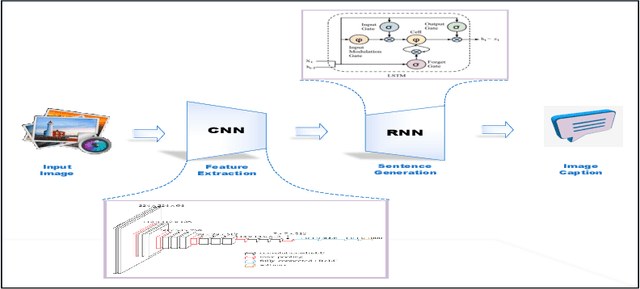
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of past and current baseline approaches and an in-depth study of recent advancements in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning applications is proposed, elaborating on different applications in more depth. Architectures and datasets used in these applications are also discussed, along with their evaluation metrics. Last, main issues are highlighted separately for each domain along with their possible future research directions.
Application of sequential processing of computer vision methods for solving the problem of detecting the edges of a honeycomb block
Oct 26, 2020

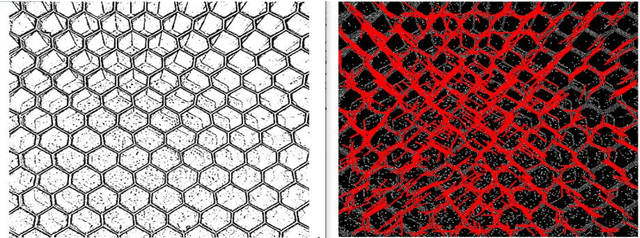

The article describes the application of the Hough transform to a honeycomb block image. The problem of cutting a mold from a honeycomb block is described. A number of image transformations are considered to increase the efficiency of the Hough algorithm. A method for obtaining a binary image using a simple threshold, a method for obtaining a binary image using Otsu binarization, and the Canny Edge Detection algorithm are considered. The method of binary skeleton (skeletonization) is considered, in which the skeleton is obtained using 2 main morphological operations: Dilation and Erosion. As a result of a number of experiments, the optimal sequence of processing the original image was revealed, which allows obtaining the coordinates of the maximum number of faces. This result allows one to choose the optimal places for cutting a honeycomb block, which will improve the quality of the resulting shapes.
Universal Rate-Distortion-Perception Representations for Lossy Compression
Jun 18, 2021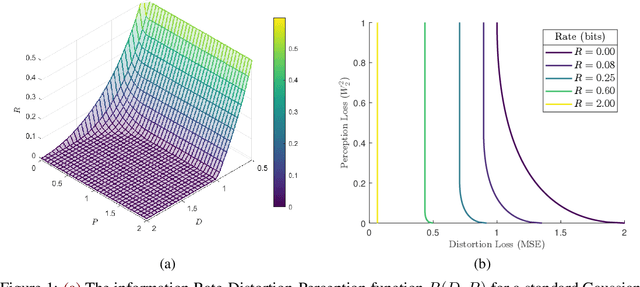
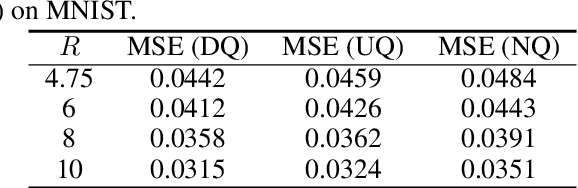
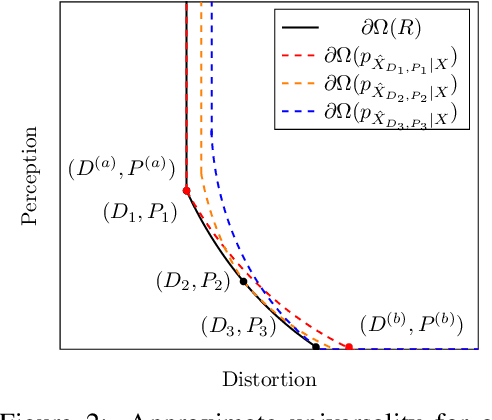
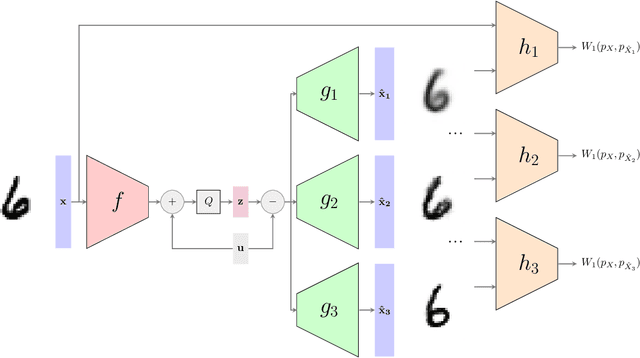
In the context of lossy compression, Blau & Michaeli (2019) adopt a mathematical notion of perceptual quality and define the information rate-distortion-perception function, generalizing the classical rate-distortion tradeoff. We consider the notion of universal representations in which one may fix an encoder and vary the decoder to achieve any point within a collection of distortion and perception constraints. We prove that the corresponding information-theoretic universal rate-distortion-perception function is operationally achievable in an approximate sense. Under MSE distortion, we show that the entire distortion-perception tradeoff of a Gaussian source can be achieved by a single encoder of the same rate asymptotically. We then characterize the achievable distortion-perception region for a fixed representation in the case of arbitrary distributions, identify conditions under which the aforementioned results continue to hold approximately, and study the case when the rate is not fixed in advance. This motivates the study of practical constructions that are approximately universal across the RDP tradeoff, thereby alleviating the need to design a new encoder for each objective. We provide experimental results on MNIST and SVHN suggesting that on image compression tasks, the operational tradeoffs achieved by machine learning models with a fixed encoder suffer only a small penalty when compared to their variable encoder counterparts.
PhD Thesis on Code Modulated Interferometric Imaging System using Phased Arrays
Jul 19, 2021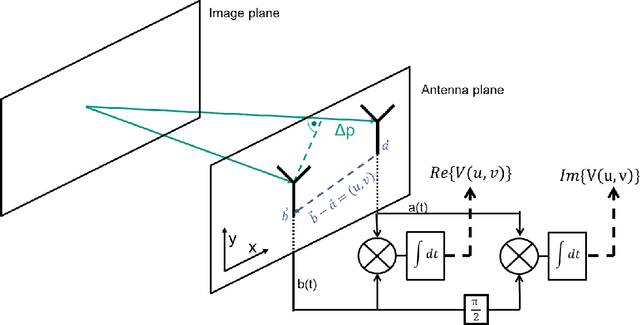

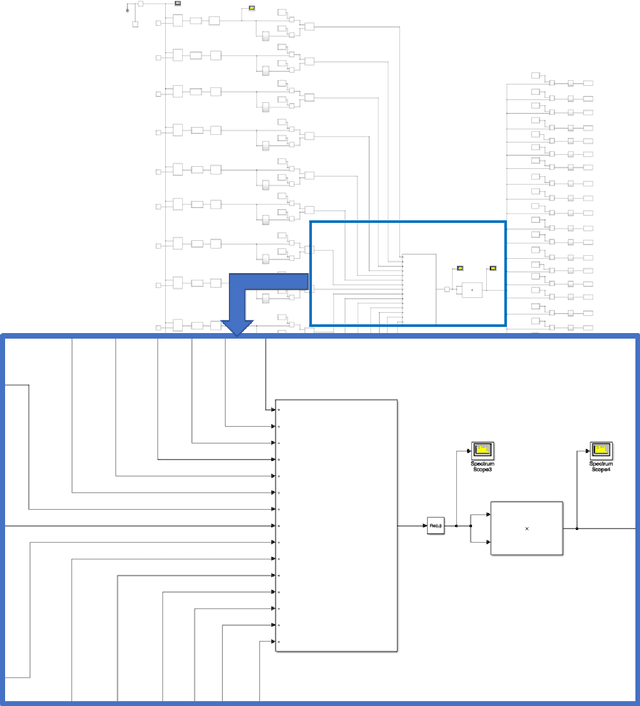
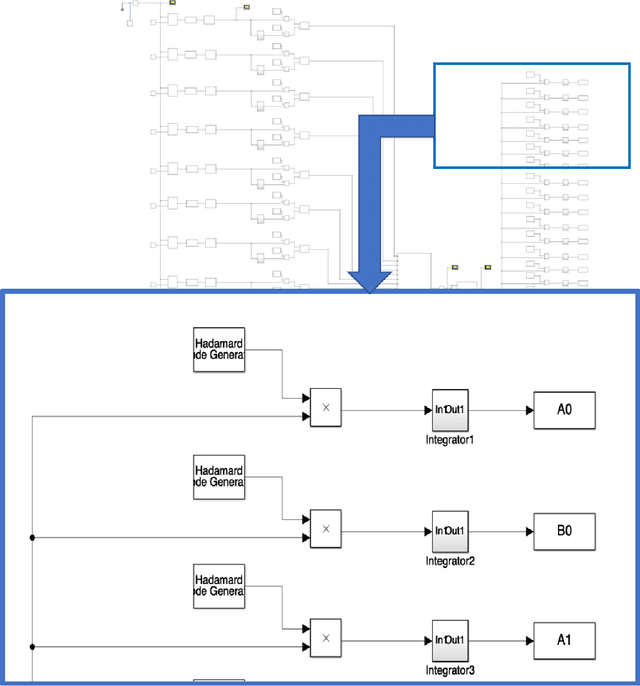
This work presents techniques which can allow low-cost phased-array receivers to be reconfigured as interferometric imagers and thereby reducing cost. Since traditional phased arrays power combine incoming signals prior to digitization, orthogonal code-modulation is applied to each incoming signal using phase shifters within each front-end. These code-modulated signals can then be combined and processed coherently through a shared hardware path. Visibility functions can be recovered through squaring and code-demultiplexing operations. The proposed system modulates incoming signals but demodulates desired correlations. Firstly, we present the operation of the system, a validation of its operation using behavioral models of a traditional phased array and a benchmarking of the code-modulated interferometer against traditional interferometer using simulation results and sensitivity analysis. Secondly, we present a simple CMI system operating in the license-free 60-GHz band using a four-element phased-array receiver. The four-element phased array is thinned to obtain a 13-pixel image and the system is demonstrated through a point-source detected at different locations. Finally, the operation and capabilities of code-modulated interferometry (CMI) are demonstrated at 10-GHz using commercially-available phased arrays. A 33-pixel, eight-element prototype is created using two commercially-available ADAR1000 phased-array receivers from Analog Devices Inc. The chips are connected at board level to a patch antenna array. The 33-pixel camera is demonstrated in hardware for point-source detection. Further to demonstrate the scalability of the concept, a 16-element, 169-pixels CMI imaging system is presented at 10-GHz using the four of the same commercially-available phased arrays from ADI. Two active point sources are imaged simultaneously to present the resolution of the system.
Energy-Efficient Model Compression and Splitting for Collaborative Inference Over Time-Varying Channels
Jun 02, 2021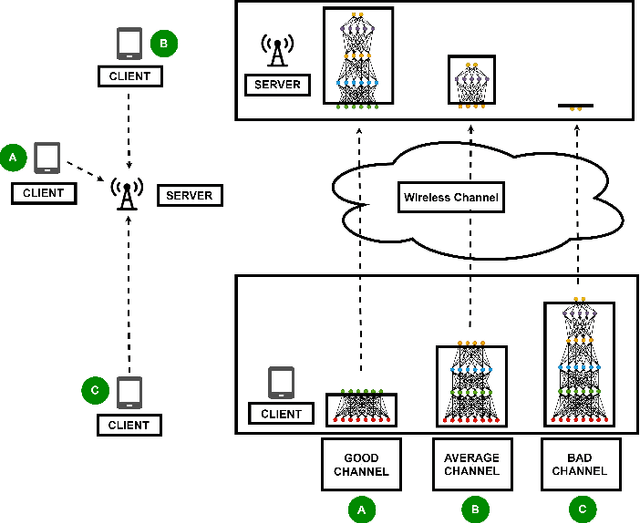
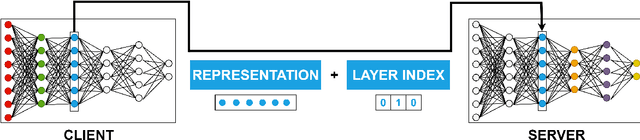
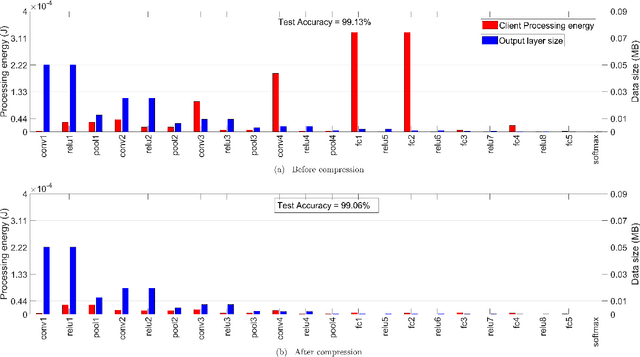
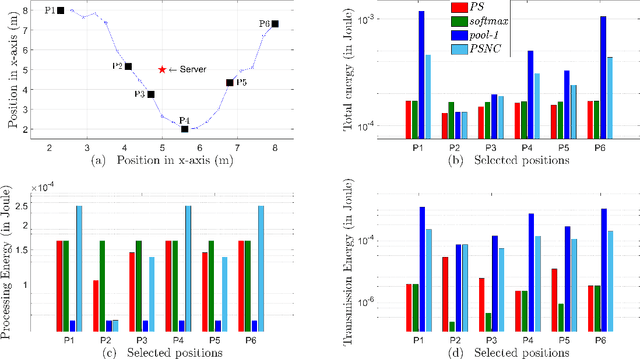
Today's intelligent applications can achieve high performance accuracy using machine learning (ML) techniques, such as deep neural networks (DNNs). Traditionally, in a remote DNN inference problem, an edge device transmits raw data to a remote node that performs the inference task. However, this may incur high transmission energy costs and puts data privacy at risk. In this paper, we propose a technique to reduce the total energy bill at the edge device by utilizing model compression and time-varying model split between the edge and remote nodes. The time-varying representation accounts for time-varying channels and can significantly reduce the total energy at the edge device while maintaining high accuracy (low loss). We implement our approach in an image classification task using the MNIST dataset, and the system environment is simulated as a trajectory navigation scenario to emulate different channel conditions. Numerical simulations show that our proposed solution results in minimal energy consumption and $CO_2$ emission compared to the considered baselines while exhibiting robust performance across different channel conditions and bandwidth regime choices.
Infrared Beacons for Robust Localization
Apr 19, 2021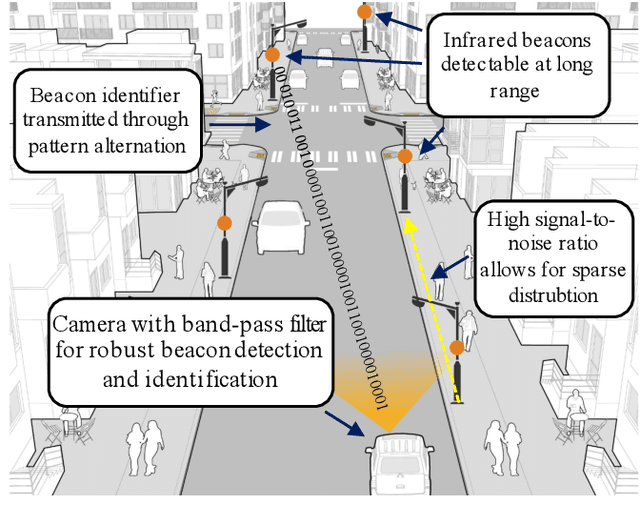
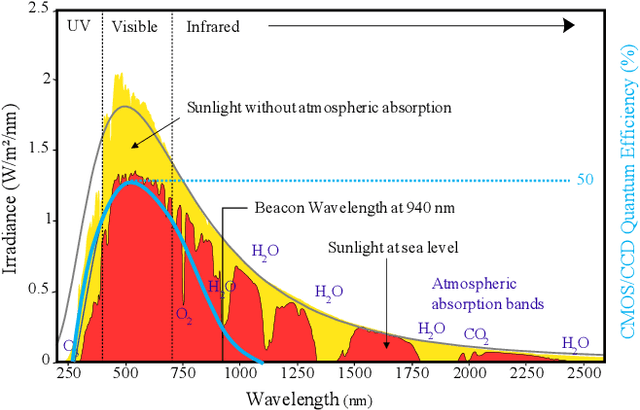


This paper presents a localization system that uses infrared beacons and a camera equipped with an optical band-pass filter. Our system can reliably detect and identify individual beacons at 100m distance regardless of lighting conditions. We describe the camera and beacon design as well as the image processing pipeline in detail. In our experiments, we investigate and demonstrate the ability of the system to recognize our beacons in both daytime and nighttime conditions. High precision localization is a key enabler for automated vehicles but remains unsolved, despite strong recent improvements. Our low-cost, infrastructure-based approach helps solve the localization problem. All datasets are made available.