 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Generalized Deep Learning Framework for Whole-Slide Image Segmentation and Analysis
Jan 01, 2020
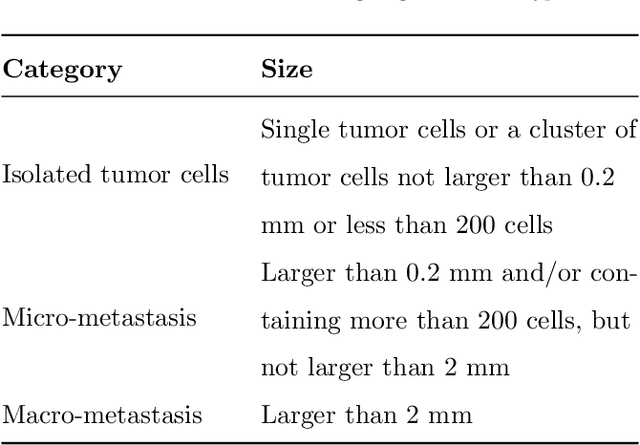
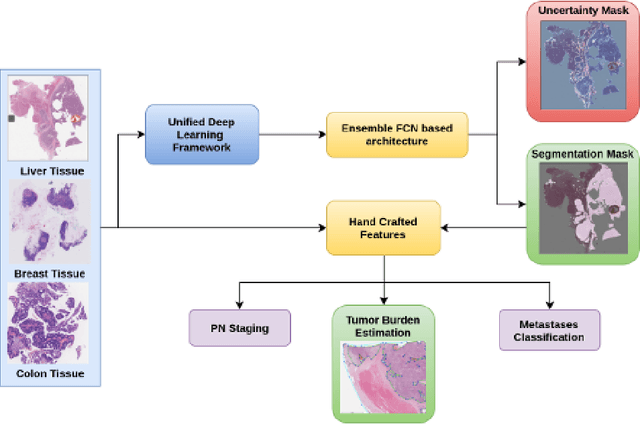

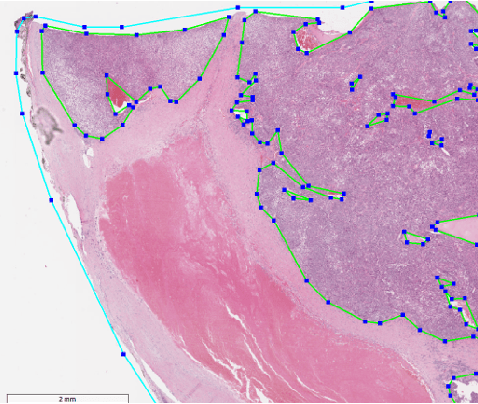
Histopathology tissue analysis is considered the gold standard in cancer diagnosis and prognosis. Given the large size of these images and the increase in the number of potential cancer cases, an automated solution as an aid to histopathologists is highly desirable. In the recent past, deep learning-based techniques have provided state of the art results in a wide variety of image analysis tasks, including analysis of digitized slides. However, the size of images and variability in histopathology tasks makes it a challenge to develop an integrated framework for histopathology image analysis. We propose a deep learning-based framework for histopathology tissue analysis. We demonstrate the generalizability of our framework, including training and inference, on several open-source datasets, which include CAMELYON (breast cancer metastases), DigestPath (colon cancer), and PAIP (liver cancer) datasets. We discuss multiple types of uncertainties pertaining to data and model, namely aleatoric and epistemic, respectively. Simultaneously, we demonstrate our model generalization across different data distribution by evaluating some samples on TCGA data. On CAMELYON16 test data (n=139) for the task of lesion detection, the FROC score achieved was 0.86 and in the CAMELYON17 test-data (n=500) for the task of pN-staging the Cohen's kappa score achieved was 0.9090 (third in the open leaderboard). On DigestPath test data (n=212) for the task of tumor segmentation, a Dice score of 0.782 was achieved (fourth in the challenge). On PAIP test data (n=40) for the task of viable tumor segmentation, a Jaccard Index of 0.75 (third in the challenge) was achieved, and for viable tumor burden, a score of 0.633 was achieved (second in the challenge). Our entire framework and related documentation are freely available at GitHub and PyPi.
Spot the Difference: Topological Anomaly Detection via Geometric Alignment
Jun 09, 2021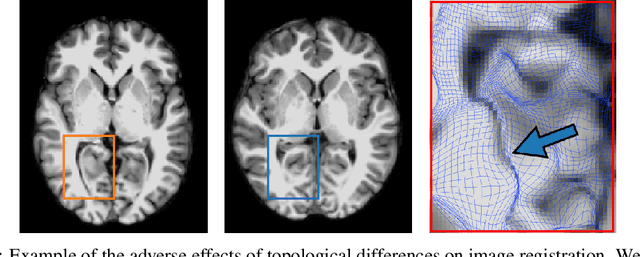
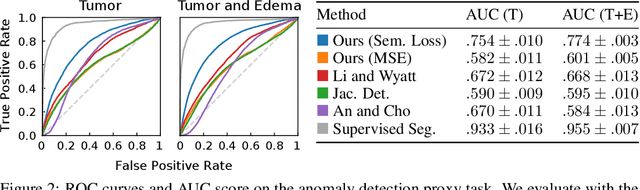
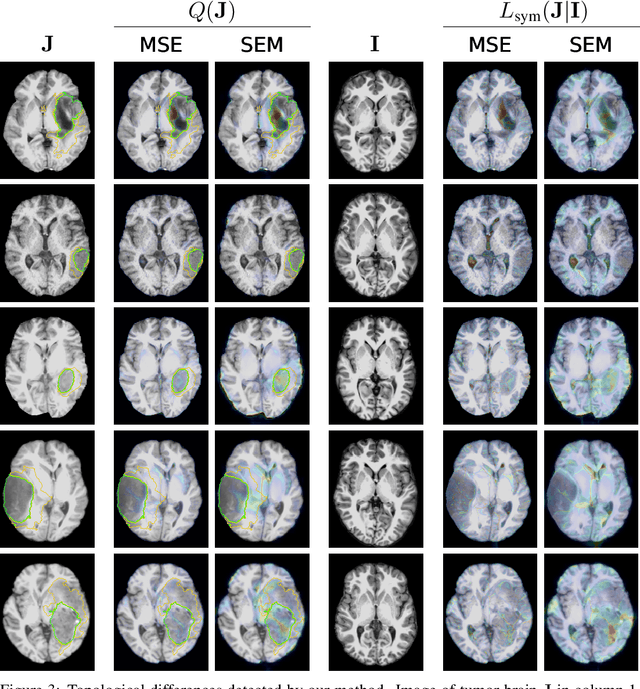
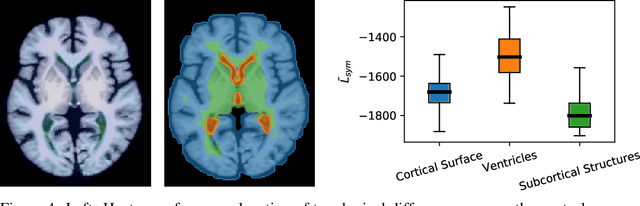
Geometric alignment appears in a variety of applications, ranging from domain adaptation, optimal transport, and normalizing flows in machine learning; optical flow and learned augmentation in computer vision and deformable registration within biomedical imaging. A recurring challenge is the alignment of domains whose topology is not the same; a problem that is routinely ignored, potentially introducing bias in downstream analysis. As a first step towards solving such alignment problems, we propose an unsupervised topological difference detection algorithm. The model is based on a conditional variational auto-encoder and detects topological anomalies with regards to a reference alongside the registration step. We consider both a) topological changes in the image under spatial variation and b) unexpected transformations. Our approach is validated on a proxy task of unsupervised anomaly detection in images.
From Self-ception to Image Self-ception: A method to represent an image with its own approximations
Jun 14, 2018



A concept of defining images based on its own approximate ones is proposed here, which is called 'Self-ception'. In this regard, an algorithm is proposed to implement the self-ception for images, which we call it 'Image Self-ception' since we use it for images. We can control the accuracy of this self-ception representation by deciding how many segments or regions we want to use for the representation. Some self-ception images are included in the paper. The video versions of the proposed image self-ception algorithm in action are shown in a YouTube channel (find it by Googling image self-ception).
Conv2Warp: An unsupervised deformable image registration with continuous convolution and warping
Aug 16, 2019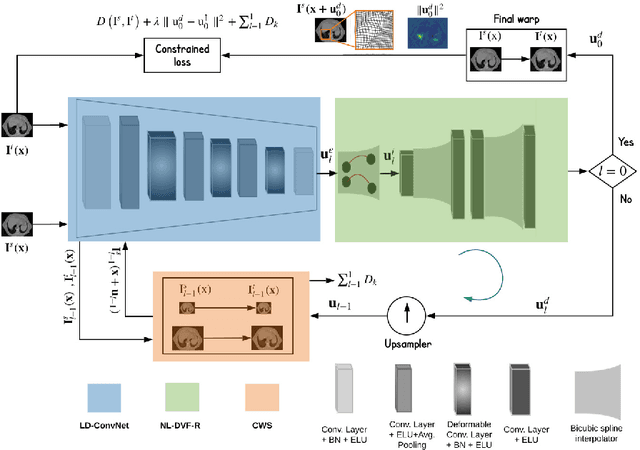
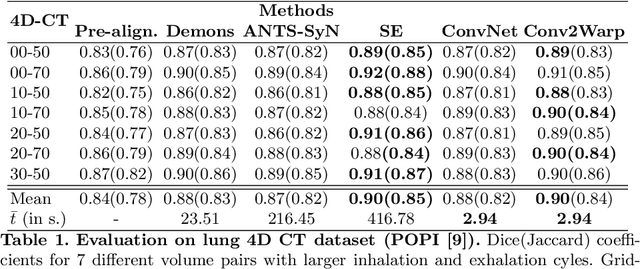
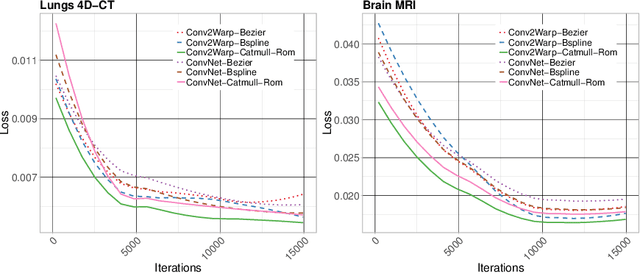
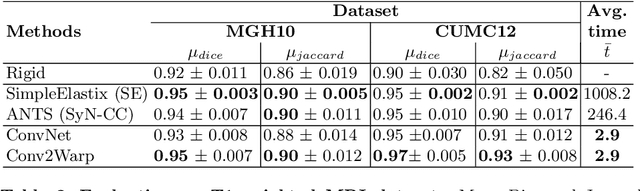
Recent successes in deep learning based deformable image registration (DIR) methods have demonstrated that complex deformation can be learnt directly from data while reducing computation time when compared to traditional methods. However, the reliance on fully linear convolutional layers imposes a uniform sampling of pixel/voxel locations which ultimately limits their performance. To address this problem, we propose a novel approach of learning a continuous warp of the source image. Here, the required deformation vector fields are obtained from a concatenated linear and non-linear convolution layers and a learnable bicubic Catmull-Rom spline resampler. This allows to compute smooth deformation field and more accurate alignment compared to using only linear convolutions and linear resampling. In addition, the continuous warping technique penalizes disagreements that are due to topological changes. Our experiments demonstrate that this approach manages to capture large non-linear deformations and minimizes the propagation of interpolation errors. While improving accuracy the method is computationally efficient. We present comparative results on a range of public 4D CT lung (POPI) and brain datasets (CUMC12, MGH10).
Zero-Shot Domain Adaptation in CT Segmentation by Filtered Back Projection Augmentation
Jul 18, 2021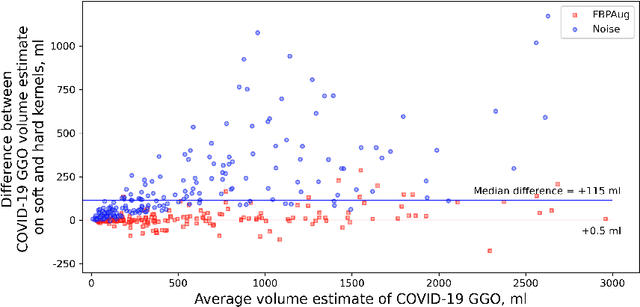


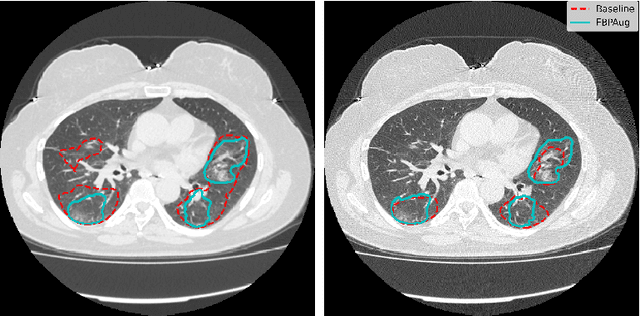
Domain shift is one of the most salient challenges in medical computer vision. Due to immense variability in scanners' parameters and imaging protocols, even images obtained from the same person and the same scanner could differ significantly. We address variability in computed tomography (CT) images caused by different convolution kernels used in the reconstruction process, the critical domain shift factor in CT. The choice of a convolution kernel affects pixels' granularity, image smoothness, and noise level. We analyze a dataset of paired CT images, where smooth and sharp images were reconstructed from the same sinograms with different kernels, thus providing identical anatomy but different style. Though identical predictions are desired, we show that the consistency, measured as the average Dice between predictions on pairs, is just 0.54. We propose Filtered Back-Projection Augmentation (FBPAug), a simple and surprisingly efficient approach to augment CT images in sinogram space emulating reconstruction with different kernels. We apply the proposed method in a zero-shot domain adaptation setup and show that the consistency boosts from 0.54 to 0.92 outperforming other augmentation approaches. Neither specific preparation of source domain data nor target domain data is required, so our publicly released FBPAug can be used as a plug-and-play module for zero-shot domain adaptation in any CT-based task.
KCNet: An Insect-Inspired Single-Hidden-Layer Neural Network with Randomized Binary Weights for Prediction and Classification Tasks
Aug 17, 2021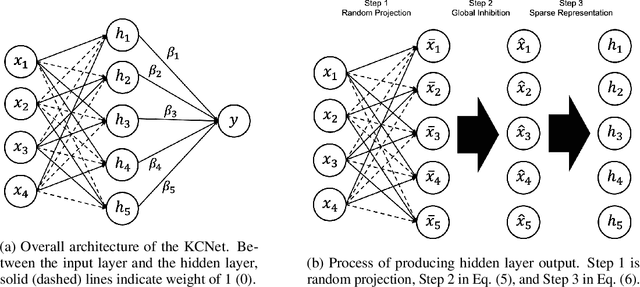
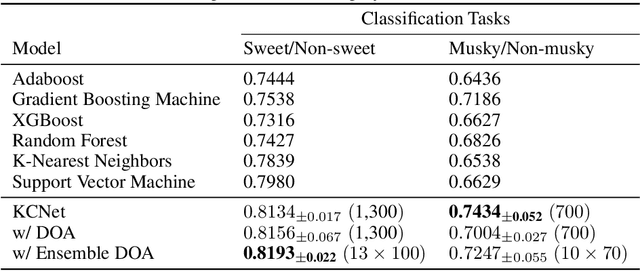
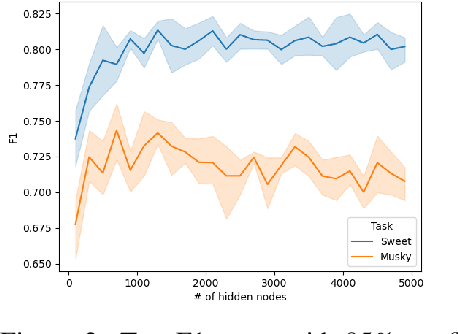
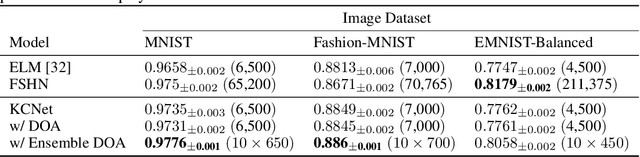
Fruit flies are established model systems for studying olfactory learning as they will readily learn to associate odors with both electric shock or sugar rewards. The mechanisms of the insect brain apparently responsible for odor learning form a relatively shallow neuronal architecture. Olfactory inputs are received by the antennal lobe (AL) of the brain, which produces an encoding of each odor mixture across ~50 sub-units known as glomeruli. Each of these glomeruli then project its component of this feature vector to several of ~2000 so-called Kenyon Cells (KCs) in a region of the brain known as the mushroom body (MB). Fly responses to odors are generated by small downstream neuropils that decode the higher-order representation from the MB. Research has shown that there is no recognizable pattern in the glomeruli--KC connections (and thus the particular higher-order representations); they are akin to fingerprints~-- even isogenic flies have different projections. Leveraging insights from this architecture, we propose KCNet, a single-hidden-layer neural network that contains sparse, randomized, binary weights between the input layer and the hidden layer and analytically learned weights between the hidden layer and the output layer. Furthermore, we also propose a dynamic optimization algorithm that enables the KCNet to increase performance beyond its structural limits by searching a more efficient set of inputs. For odorant-perception tasks that predict perceptual properties of an odorant, we show that KCNet outperforms existing data-driven approaches, such as XGBoost. For image-classification tasks, KCNet achieves reasonable performance on benchmark datasets (MNIST, Fashion-MNIST, and EMNIST) without any data-augmentation methods or convolutional layers and shows particularly fast running time. Thus, neural networks inspired by the insect brain can be both economical and perform well.
Multi-view Vector-valued Manifold Regularization for Multi-label Image Classification
Apr 08, 2019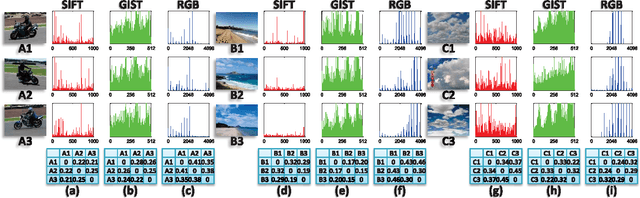
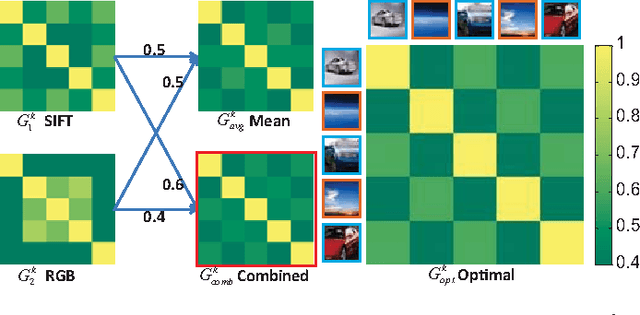
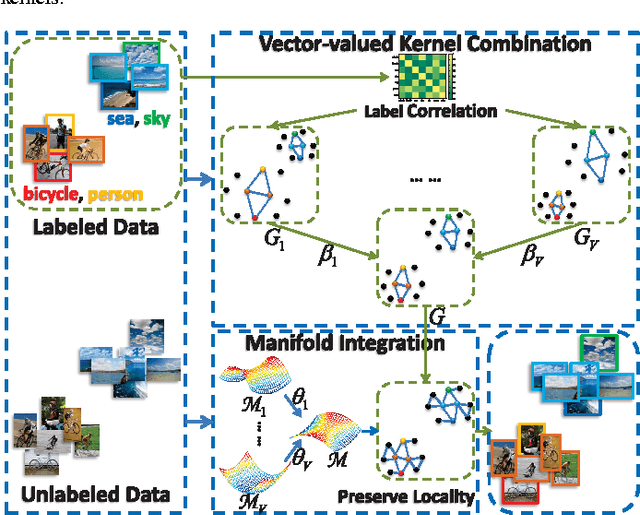
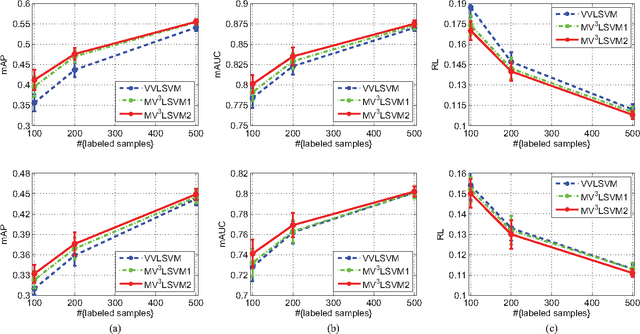
In computer vision, image datasets used for classification are naturally associated with multiple labels and comprised of multiple views, because each image may contain several objects (e.g. pedestrian, bicycle and tree) and is properly characterized by multiple visual features (e.g. color, texture and shape). Currently available tools ignore either the label relationship or the view complementary. Motivated by the success of the vector-valued function that constructs matrix-valued kernels to explore the multi-label structure in the output space, we introduce multi-view vector-valued manifold regularization (MV$\mathbf{^3}$MR) to integrate multiple features. MV$\mathbf{^3}$MR exploits the complementary property of different features and discovers the intrinsic local geometry of the compact support shared by different features under the theme of manifold regularization. We conducted extensive experiments on two challenging, but popular datasets, PASCAL VOC' 07 (VOC) and MIR Flickr (MIR), and validated the effectiveness of the proposed MV$\mathbf{^3}$MR for image classification.
AgeFlow: Conditional Age Progression and Regression with Normalizing Flows
May 15, 2021
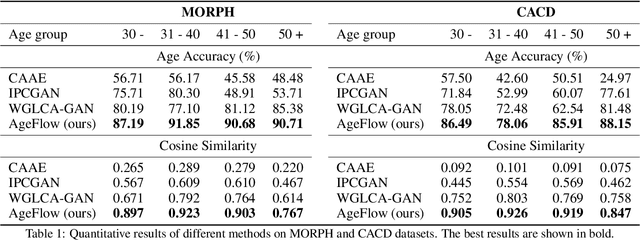
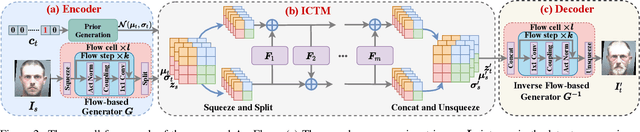
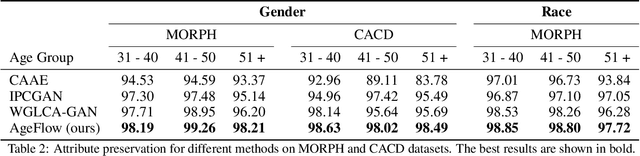
Age progression and regression aim to synthesize photorealistic appearance of a given face image with aging and rejuvenation effects, respectively. Existing generative adversarial networks (GANs) based methods suffer from the following three major issues: 1) unstable training introducing strong ghost artifacts in the generated faces, 2) unpaired training leading to unexpected changes in facial attributes such as genders and races, and 3) non-bijective age mappings increasing the uncertainty in the face transformation. To overcome these issues, this paper proposes a novel framework, termed AgeFlow, to integrate the advantages of both flow-based models and GANs. The proposed AgeFlow contains three parts: an encoder that maps a given face to a latent space through an invertible neural network, a novel invertible conditional translation module (ICTM) that translates the source latent vector to target one, and a decoder that reconstructs the generated face from the target latent vector using the same encoder network; all parts are invertible achieving bijective age mappings. The novelties of ICTM are two-fold. First, we propose an attribute-aware knowledge distillation to learn the manipulation direction of age progression while keeping other unrelated attributes unchanged, alleviating unexpected changes in facial attributes. Second, we propose to use GANs in the latent space to ensure the learned latent vector indistinguishable from the real ones, which is much easier than traditional use of GANs in the image domain. Experimental results demonstrate superior performance over existing GANs-based methods on two benchmarked datasets. The source code is available at https://github.com/Hzzone/AgeFlow.
CInC Flow: Characterizable Invertible 3x3 Convolution
Jul 03, 2021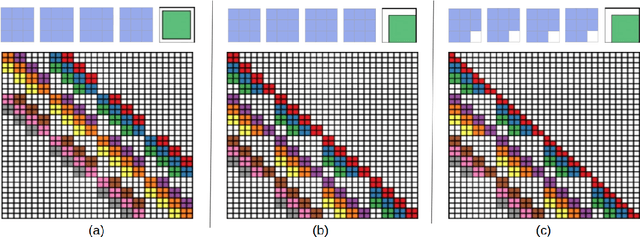

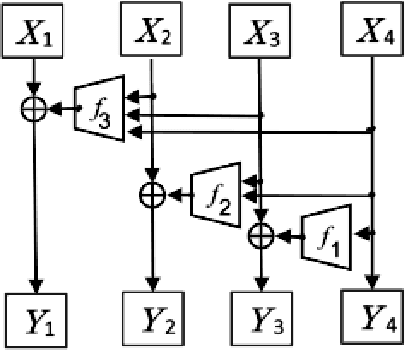
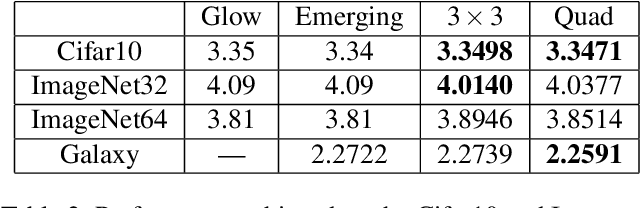
Normalizing flows are an essential alternative to GANs for generative modelling, which can be optimized directly on the maximum likelihood of the dataset. They also allow computation of the exact latent vector corresponding to an image since they are composed of invertible transformations. However, the requirement of invertibility of the transformation prevents standard and expressive neural network models such as CNNs from being directly used. Emergent convolutions were proposed to construct an invertible 3$\times$3 CNN layer using a pair of masked CNN layers, making them inefficient. We study conditions such that 3$\times$3 CNNs are invertible, allowing them to construct expressive normalizing flows. We derive necessary and sufficient conditions on a padded CNN for it to be invertible. Our conditions for invertibility are simple, can easily be maintained during the training process. Since we require only a single CNN layer for every effective invertible CNN layer, our approach is more efficient than emerging convolutions. We also proposed a coupling method, Quad-coupling. We benchmark our approach and show similar performance results to emergent convolutions while improving the model's efficiency.
Finding and Fixing Spurious Patterns with Explanations
Jun 03, 2021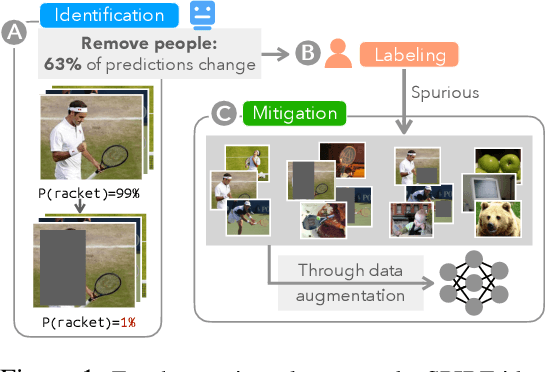
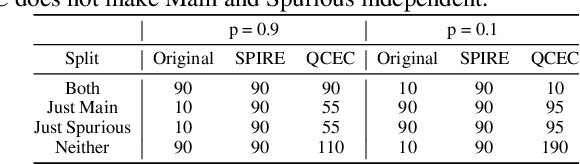

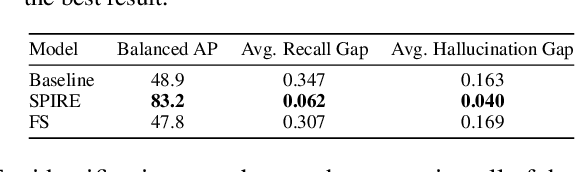
Machine learning models often use spurious patterns such as "relying on the presence of a person to detect a tennis racket," which do not generalize. In this work, we present an end-to-end pipeline for identifying and mitigating spurious patterns for image classifiers. We start by finding patterns such as "the model's prediction for tennis racket changes 63% of the time if we hide the people." Then, if a pattern is spurious, we mitigate it via a novel form of data augmentation. We demonstrate that this approach identifies a diverse set of spurious patterns and that it mitigates them by producing a model that is both more accurate on a distribution where the spurious pattern is not helpful and more robust to distribution shift.