 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Alias-Free Generative Adversarial Networks
Jul 15, 2021

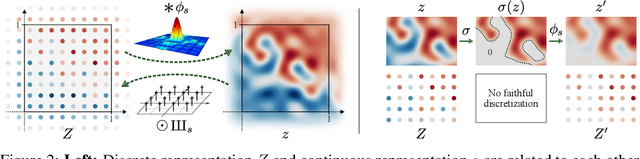
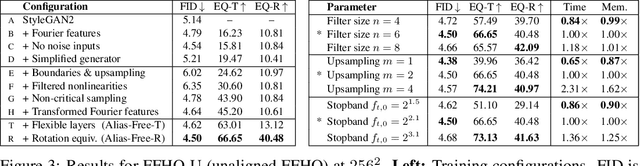
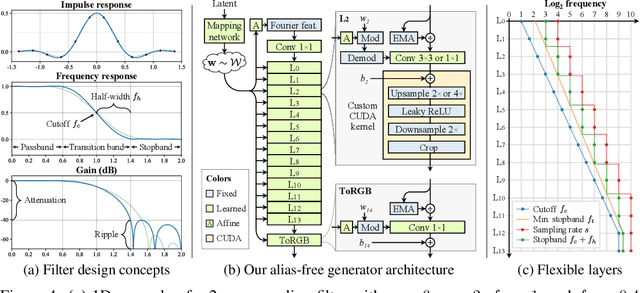
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
Deep OCT Angiography Image Generation for Motion Artifact Suppression
Jan 08, 2020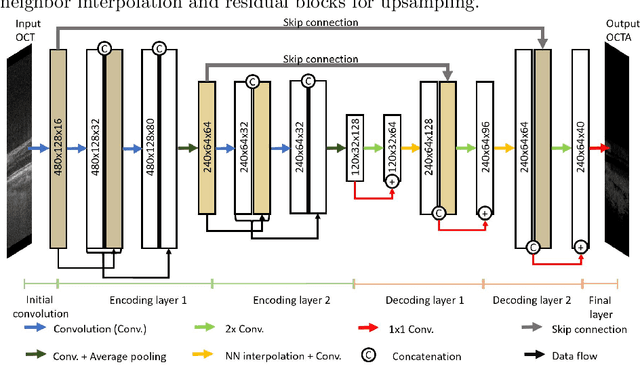
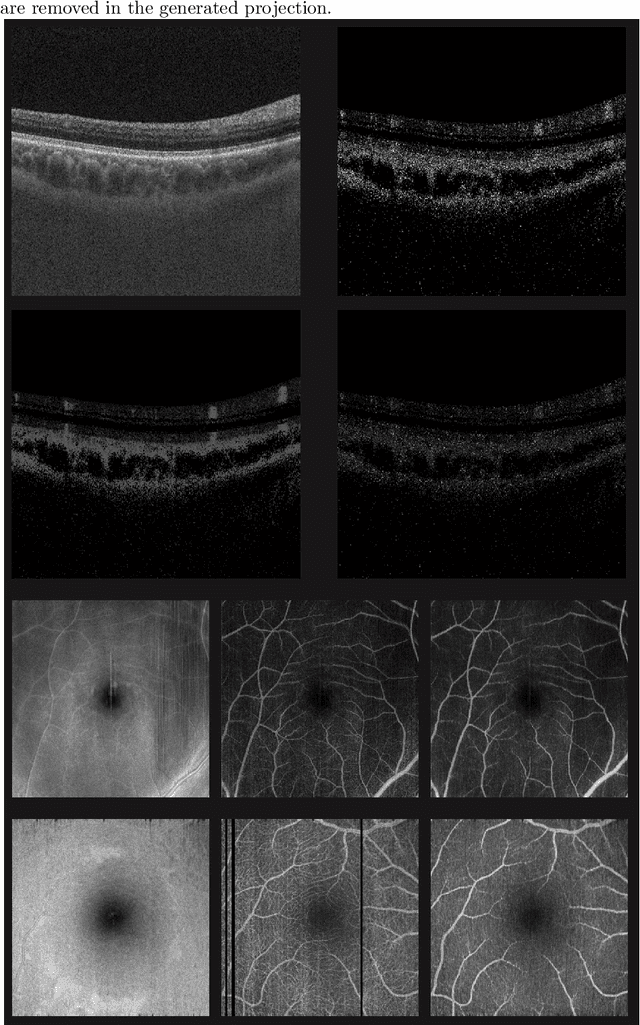
Eye movements, blinking and other motion during the acquisition of optical coherence tomography (OCT) can lead to artifacts, when processed to OCT angiography (OCTA) images. Affected scans emerge as high intensity (white) or missing (black) regions, resulting in lost information. The aim of this research is to fill these gaps using a deep generative model for OCT to OCTA image translation relying on a single intact OCT scan. Therefore, a U-Net is trained to extract the angiographic information from OCT patches. At inference, a detection algorithm finds outlier OCTA scans based on their surroundings, which are then replaced by the trained network. We show that generative models can augment the missing scans. The augmented volumes could then be used for 3-D segmentation or increase the diagnostic value.
Semi-Supervised Learning with Multi-Head Co-Training
Jul 10, 2021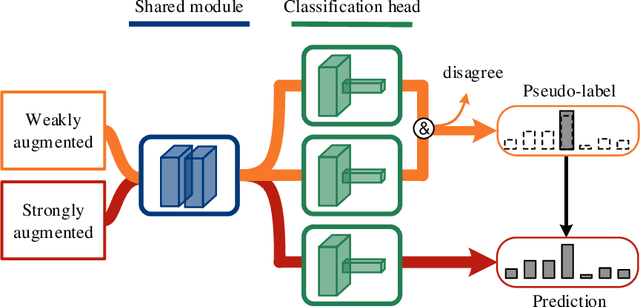


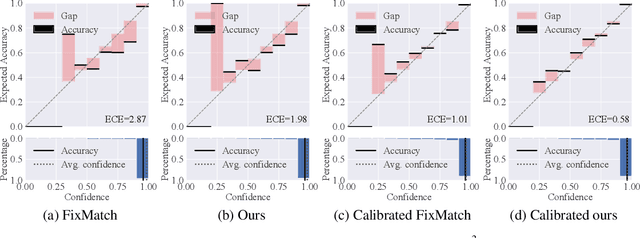
Co-training, extended from self-training, is one of the frameworks for semi-supervised learning. It works at the cost of training extra classifiers, where the algorithm should be delicately designed to prevent individual classifiers from collapsing into each other. In this paper, we present a simple and efficient co-training algorithm, named Multi-Head Co-Training, for semi-supervised image classification. By integrating base learners into a multi-head structure, the model is in a minimal amount of extra parameters. Every classification head in the unified model interacts with its peers through a "Weak and Strong Augmentation" strategy, achieving single-view co-training without promoting diversity explicitly. The effectiveness of Multi-Head Co-Training is demonstrated in an empirical study on standard semi-supervised learning benchmarks.
Screen2Words: Automatic Mobile UI Summarization with Multimodal Learning
Aug 07, 2021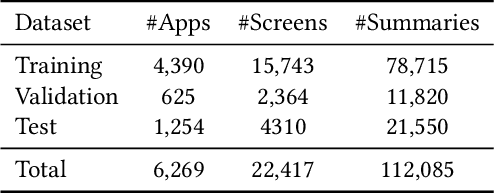

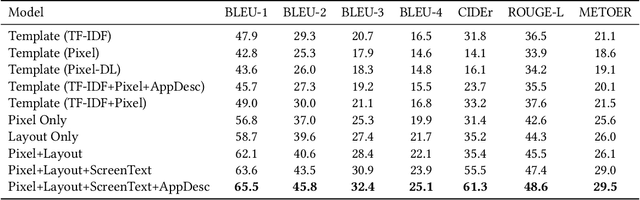
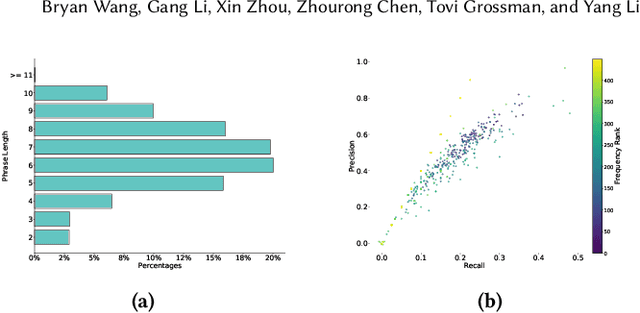
Mobile User Interface Summarization generates succinct language descriptions of mobile screens for conveying important contents and functionalities of the screen, which can be useful for many language-based application scenarios. We present Screen2Words, a novel screen summarization approach that automatically encapsulates essential information of a UI screen into a coherent language phrase. Summarizing mobile screens requires a holistic understanding of the multi-modal data of mobile UIs, including text, image, structures as well as UI semantics, motivating our multi-modal learning approach. We collected and analyzed a large-scale screen summarization dataset annotated by human workers. Our dataset contains more than 112k language summarization across $\sim$22k unique UI screens. We then experimented with a set of deep models with different configurations. Our evaluation of these models with both automatic accuracy metrics and human rating shows that our approach can generate high-quality summaries for mobile screens. We demonstrate potential use cases of Screen2Words and open-source our dataset and model to lay the foundations for further bridging language and user interfaces.
Code2Image: Intelligent Code Analysis by Computer Vision Techniques and Application to Vulnerability Prediction
May 07, 2021

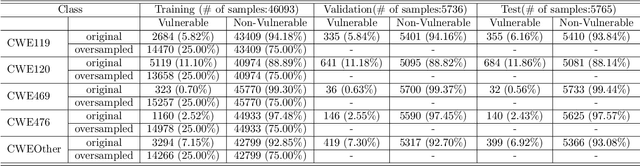
Intelligent code analysis has received increasing attention in parallel with the remarkable advances in the field of machine learning (ML) in recent years. A major challenge in leveraging ML for this purpose is to represent source code in a useful form that ML algorithms can accept as input. In this study, we present a novel method to represent source code as image while preserving semantic and syntactic properties, which paves the way for leveraging computer vision techniques to use for code analysis. Indeed the method makes it possible to directly enter the resulting image representation of source codes into deep learning (DL) algorithms as input without requiring any further data pre-processing or feature extraction step. We demonstrate feasibility and effectiveness of our method by realizing a vulnerability prediction use case over a public dataset containing a large number of real-world source code samples with performance evaluation in comparison to the state-of-art solutions. Our implementation is publicly available.
RODEO: Robust DE-aliasing autoencOder for Real-time Medical Image Reconstruction
Dec 11, 2019
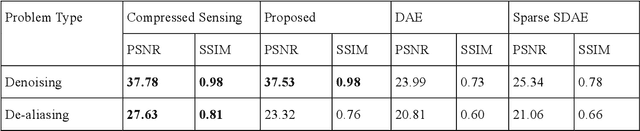
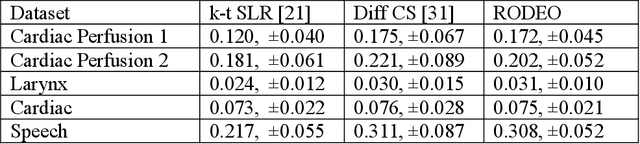
In this work we address the problem of real-time dynamic medical MRI and X Ray CT image reconstruction from parsimonious samples Fourier frequency space for MRI and sinogram tomographic projections for CT. Today the de facto standard for such reconstruction is compressed sensing. CS produces high quality images (with minimal perceptual loss, but such reconstructions are time consuming, requiring solving a complex optimization problem. In this work we propose to learn the reconstruction from training samples using an autoencoder. Our work is based on the universal function approximation capacity of neural networks. The training time for the autoencoder is large, but is offline and hence does not affect performance during operation. During testing or operation, our method requires only a few matrix vector products and hence is significantly faster than CS based methods. In fact, it is fast enough for real-time reconstruction the images are reconstructed as fast as they are acquired with only slight degradation of image quality. However, in order to make the autoencoder suitable for our problem, we depart from the standard Euclidean norm cost function of autoencoders and use a robust l1-norm instead. The ensuing problem is solved using the Split Bregman method.
Unsupervised multi-latent space reinforcement learning framework for video summarization in ultrasound imaging
Sep 03, 2021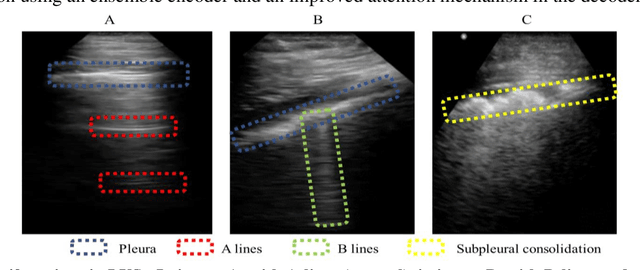
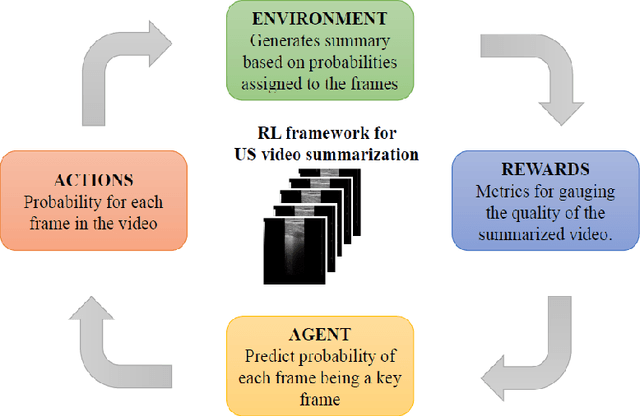
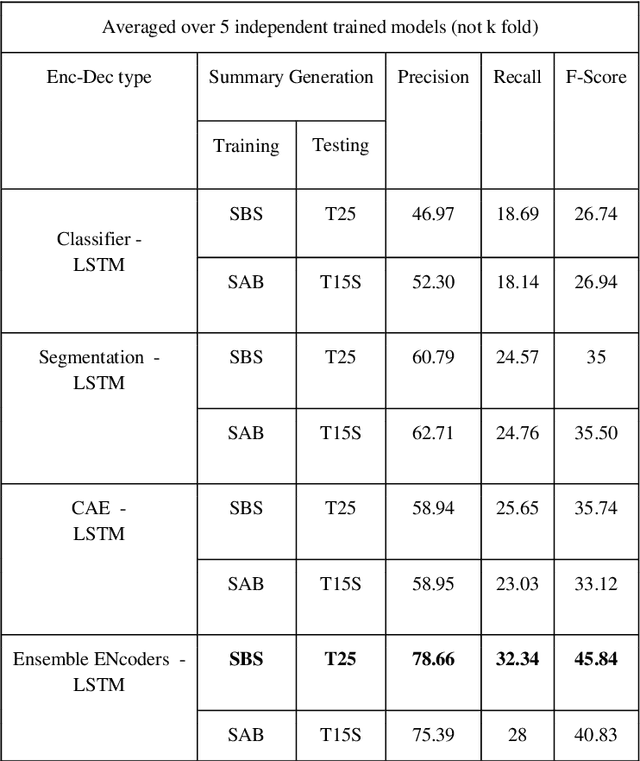
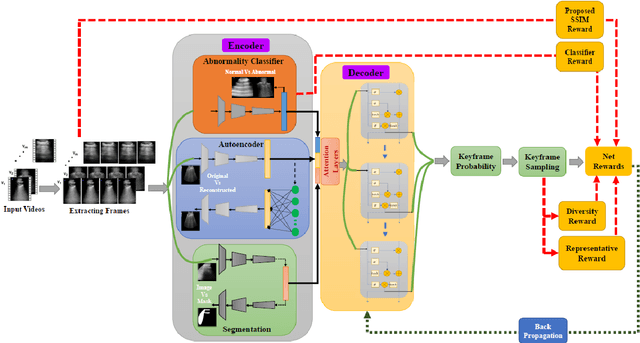
The COVID-19 pandemic has highlighted the need for a tool to speed up triage in ultrasound scans and provide clinicians with fast access to relevant information. The proposed video-summarization technique is a step in this direction that provides clinicians access to relevant key-frames from a given ultrasound scan (such as lung ultrasound) while reducing resource, storage and bandwidth requirements. We propose a new unsupervised reinforcement learning (RL) framework with novel rewards that facilitates unsupervised learning avoiding tedious and impractical manual labelling for summarizing ultrasound videos to enhance its utility as a triage tool in the emergency department (ED) and for use in telemedicine. Using an attention ensemble of encoders, the high dimensional image is projected into a low dimensional latent space in terms of: a) reduced distance with a normal or abnormal class (classifier encoder), b) following a topology of landmarks (segmentation encoder), and c) the distance or topology agnostic latent representation (convolutional autoencoders). The decoder is implemented using a bi-directional long-short term memory (Bi-LSTM) which utilizes the latent space representation from the encoder. Our new paradigm for video summarization is capable of delivering classification labels and segmentation of key landmarks for each of the summarized keyframes. Validation is performed on lung ultrasound (LUS) dataset, that typically represent potential use cases in telemedicine and ED triage acquired from different medical centers across geographies (India, Spain and Canada).
cGANs for Cartoon to Real-life Images
Jan 24, 2021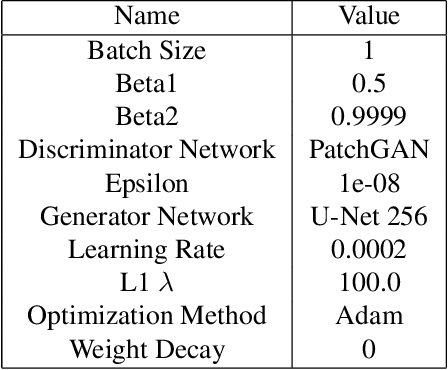

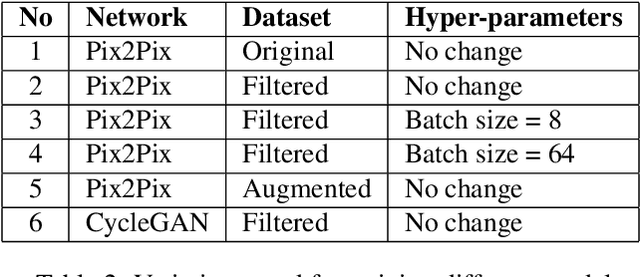

The image-to-image translation is a learning task to establish a visual mapping between an input and output image. The task has several variations differentiated based on the purpose of the translation, such as synthetic to real translation, photo to caricature translation, and many others. The problem has been tackled using different approaches, either through traditional computer vision methods, as well as deep learning approaches in recent trends. One approach currently deemed popular and effective is using the conditional generative adversarial network, also known shortly as cGAN. It is adapted to perform image-to-image translation tasks with typically two networks: a generator and a discriminator. This project aims to evaluate the robustness of the Pix2Pix model by applying the Pix2Pix model to datasets consisting of cartoonized images. Using the Pix2Pix model, it should be possible to train the network to generate real-life images from the cartoonized images.
Complex-valued reservoir computing for aspect classification and slope-angle estimation with low computational cost and high resolution in interferometric synthetic aperture radar
Apr 22, 2021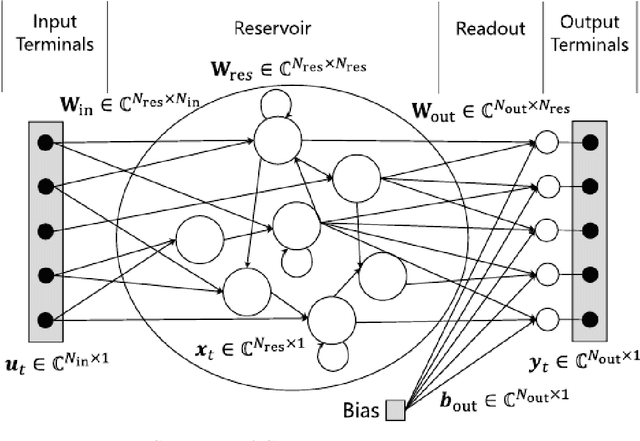

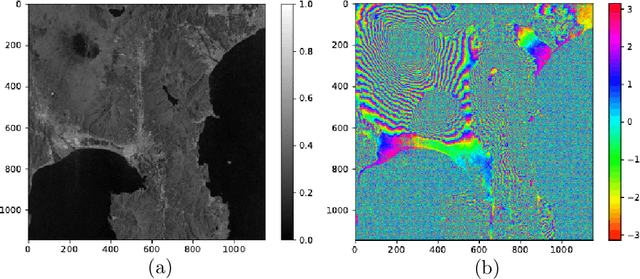

Synthetic aperture radar (SAR) is widely used for ground surface classification since it utilizes information on vegetation and soil unavailable in optical observation. Image classification often employs convolutional neural networks. However, they have serious problems such as long learning time and resolution degradation in their convolution and pooling processes. In this paper, we propose complex-valued reservoir computing (CVRC) to deal with complex-valued images in interferometric SAR (InSAR). We classify InSAR image data by using CVRC successfully with a higher resolution and a lower computational cost, i.e., one-hundredth learning time and one-fifth classification time, than convolutional neural networks. We also conduct experiments on slope angle estimation. CVRC is found applicable to quantitative tasks dealing with continuous values as well as discrete classification tasks with a higher accuracy.
End-to-End Conditional GAN-based Architectures for Image Colourisation
Aug 26, 2019
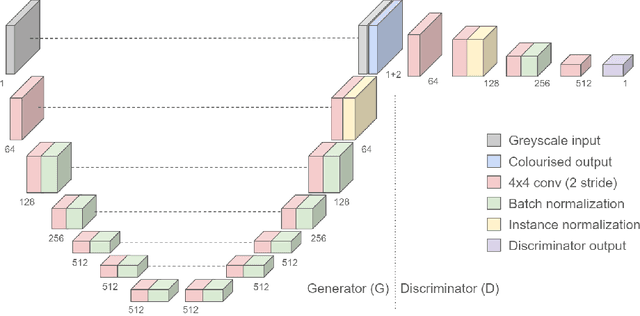
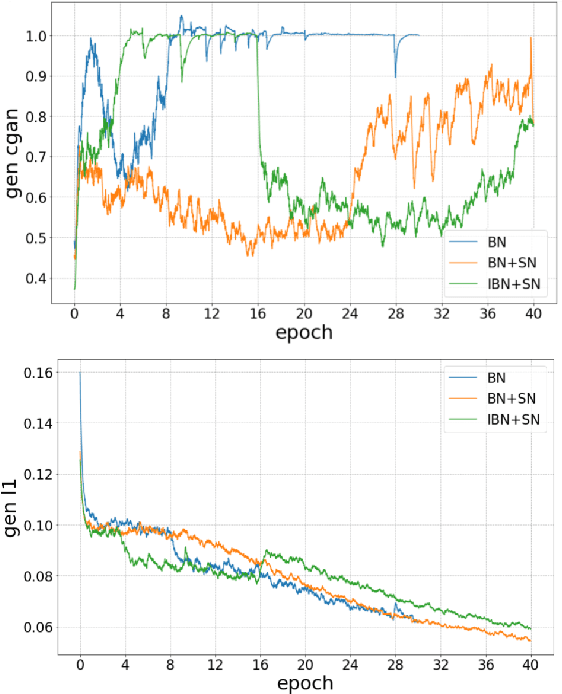
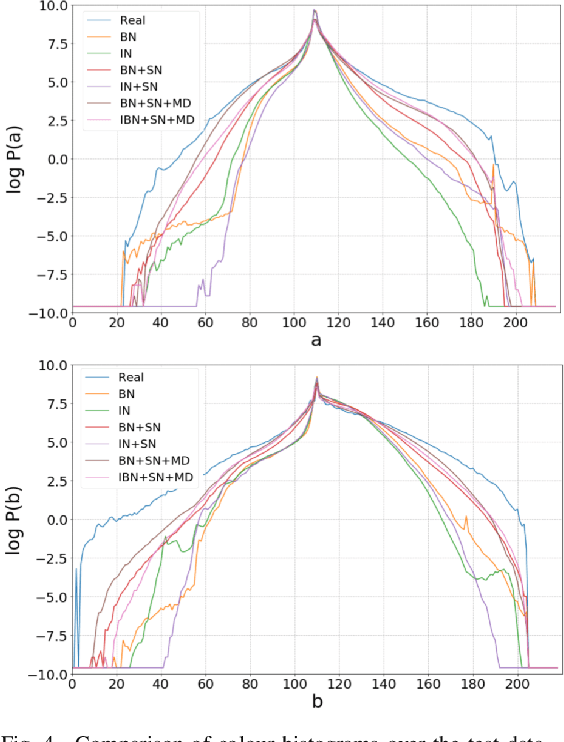
In this work recent advances in conditional adversarial networks are investigated to develop an end-to-end architecture based on Convolutional Neural Networks (CNNs) to directly map realistic colours to an input greyscale image. Observing that existing colourisation methods sometimes exhibit a lack of colourfulness, this paper proposes a method to improve colourisation results. In particular, the method uses Generative Adversarial Neural Networks (GANs) and focuses on improvement of training stability to enable better generalisation in large multi-class image datasets. Additionally, the integration of instance and batch normalisation layers in both generator and discriminator is introduced to the popular U-Net architecture, boosting the network capabilities to generalise the style changes of the content. The method has been tested using the ILSVRC 2012 dataset, achieving improved automatic colourisation results compared to other methods based on GANs.