 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Discriminative Learned CNN Embedding for Remote Sensing Image Scene Classification
Dec 02, 2019
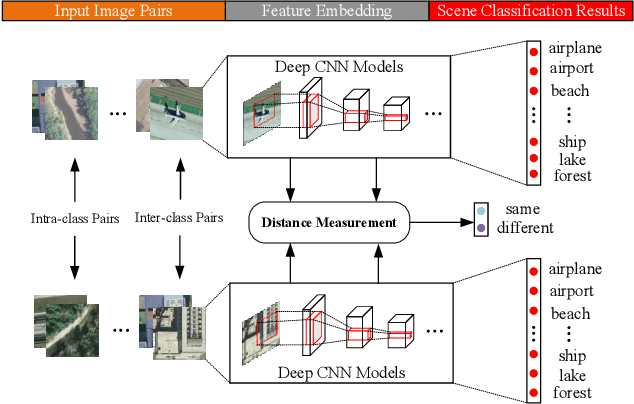
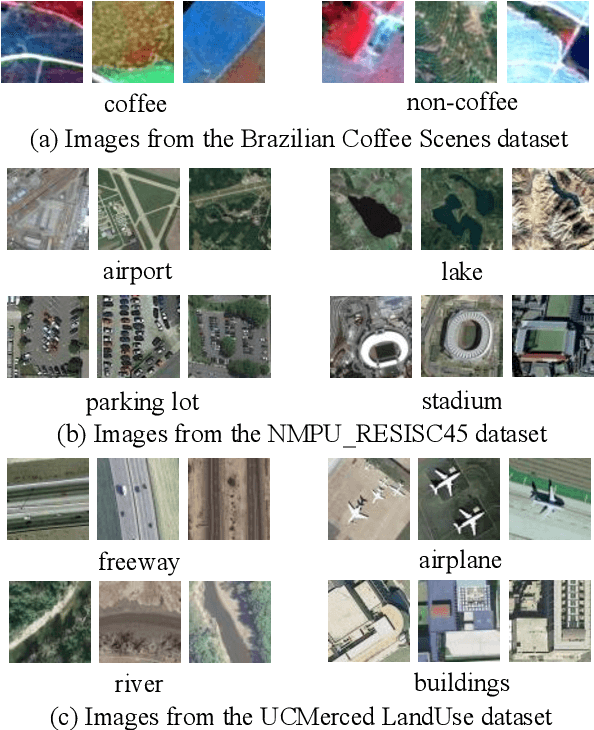
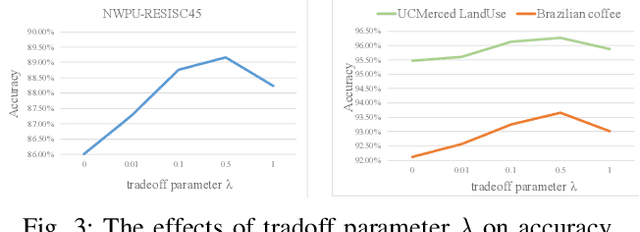
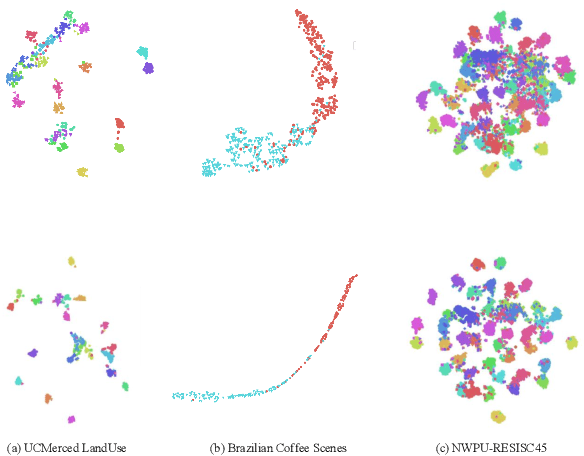
In this work, a discriminatively learned CNN embedding is proposed for remote sensing image scene classification. Our proposed siamese network simultaneously computes the classification loss function and the metric learning loss function of the two input images. Specifically, for the classification loss, we use the standard cross-entropy loss function to predict the classes of the images. For the metric learning loss, our siamese network learns to map the intra-class and inter-class input pairs to a feature space where intra-class inputs are close and inter-class inputs are separated by a margin. Concretely, for remote sensing image scene classification, we would like to map images from the same scene to feature vectors that are close, and map images from different scenes to feature vectors that are widely separated. Experiments are conducted on three different remote sensing image datasets to evaluate the effectiveness of our proposed approach. The results demonstrate that the proposed method achieves an excellent classification performance.
Boundary Knowledge Translation based Reference Semantic Segmentation
Aug 01, 2021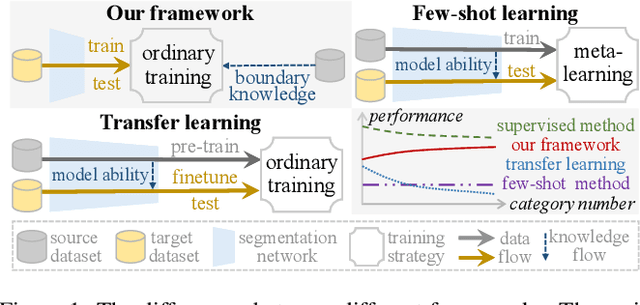
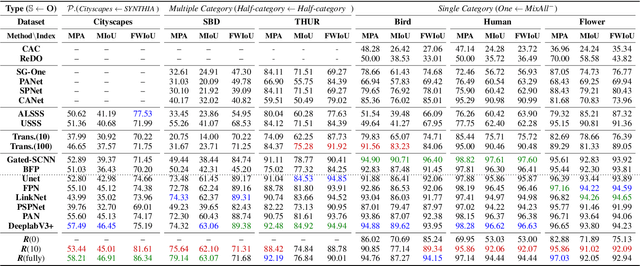
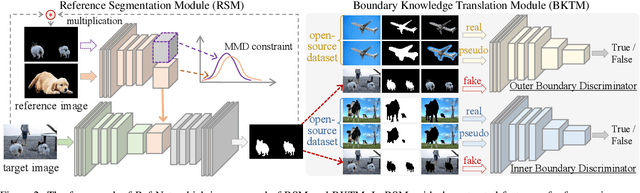

Given a reference object of an unknown type in an image, human observers can effortlessly find the objects of the same category in another image and precisely tell their visual boundaries. Such visual cognition capability of humans seems absent from the current research spectrum of computer vision. Existing segmentation networks, for example, rely on a humongous amount of labeled data, which is laborious and costly to collect and annotate; besides, the performance of segmentation networks tend to downgrade as the number of the category increases. In this paper, we introduce a novel Reference semantic segmentation Network (Ref-Net) to conduct visual boundary knowledge translation. Ref-Net contains a Reference Segmentation Module (RSM) and a Boundary Knowledge Translation Module (BKTM). Inspired by the human recognition mechanism, RSM is devised only to segment the same category objects based on the features of the reference objects. BKTM, on the other hand, introduces two boundary discriminator branches to conduct inner and outer boundary segmentation of the target objectin an adversarial manner, and translate the annotated boundary knowledge of open-source datasets into the segmentation network. Exhaustive experiments demonstrate that, with tens of finely-grained annotated samples as guidance, Ref-Net achieves results on par with fully supervised methods on six datasets.
Visual Boundary Knowledge Translation for Foreground Segmentation
Aug 01, 2021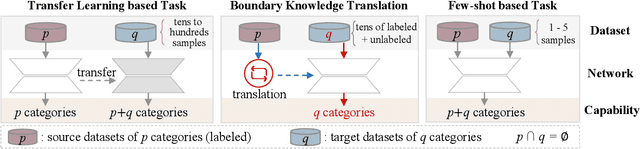
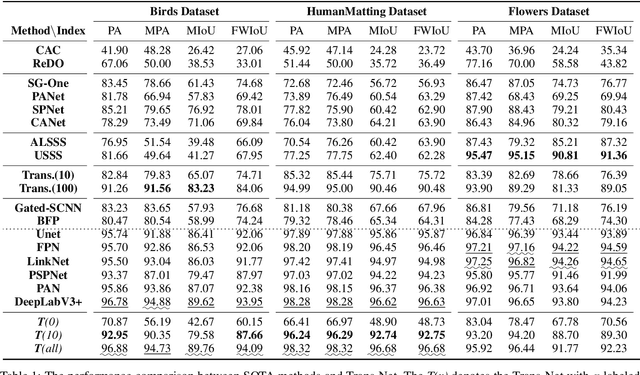
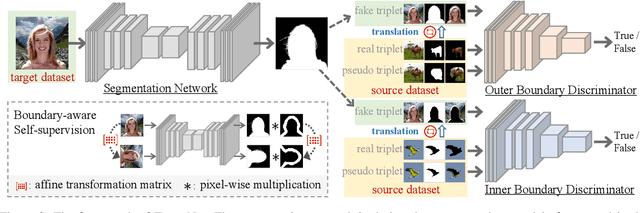

When confronted with objects of unknown types in an image, humans can effortlessly and precisely tell their visual boundaries. This recognition mechanism and underlying generalization capability seem to contrast to state-of-the-art image segmentation networks that rely on large-scale category-aware annotated training samples. In this paper, we make an attempt towards building models that explicitly account for visual boundary knowledge, in hope to reduce the training effort on segmenting unseen categories. Specifically, we investigate a new task termed as Boundary Knowledge Translation (BKT). Given a set of fully labeled categories, BKT aims to translate the visual boundary knowledge learned from the labeled categories, to a set of novel categories, each of which is provided only a few labeled samples. To this end, we propose a Translation Segmentation Network (Trans-Net), which comprises a segmentation network and two boundary discriminators. The segmentation network, combined with a boundary-aware self-supervised mechanism, is devised to conduct foreground segmentation, while the two discriminators work together in an adversarial manner to ensure an accurate segmentation of the novel categories under light supervision. Exhaustive experiments demonstrate that, with only tens of labeled samples as guidance, Trans-Net achieves close results on par with fully supervised methods.
360-Degree Textures of People in Clothing from a Single Image
Aug 20, 2019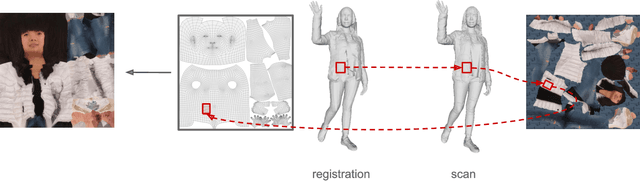

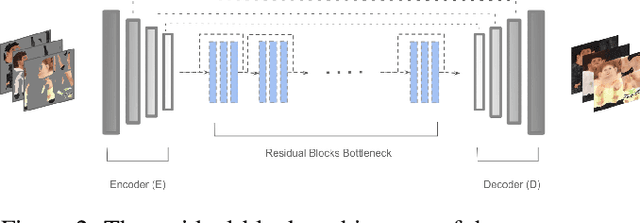
In this paper we predict a full 3D avatar of a person from a single image. We infer texture and geometry in the UV-space of the SMPL model using an image-to-image translation method. Given partial texture and segmentation layout maps derived from the input view, our model predicts the complete segmentation map, the complete texture map, and a displacement map. The predicted maps can be applied to the SMPL model in order to naturally generalize to novel poses, shapes, and even new clothing. In order to learn our model in a common UV-space, we non-rigidly register the SMPL model to thousands of 3D scans, effectively encoding textures and geometries as images in correspondence. This turns a difficult 3D inference task into a simpler image-to-image translation one. Results on rendered scans of people and images from the DeepFashion dataset demonstrate that our method can reconstruct plausible 3D avatars from a single image. We further use our model to digitally change pose, shape, swap garments between people and edit clothing. To encourage research in this direction we will make the source code available for research purpose.
WhiteNNer-Blind Image Denoising via Noise Whiteness Priors
Aug 08, 2019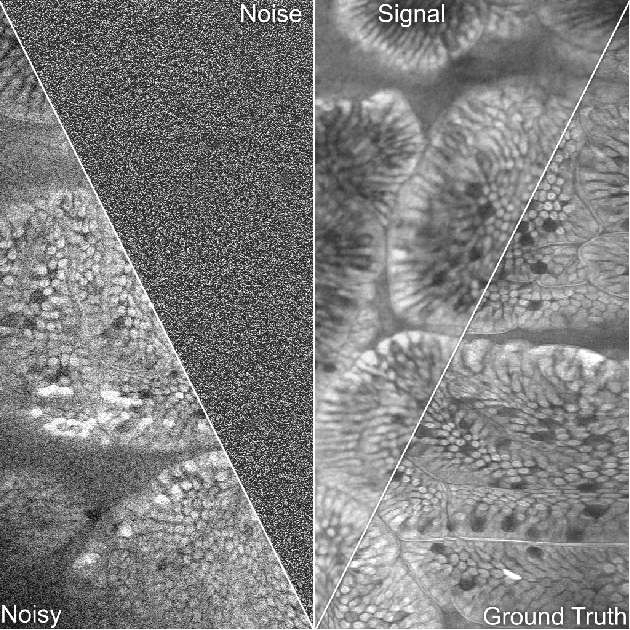

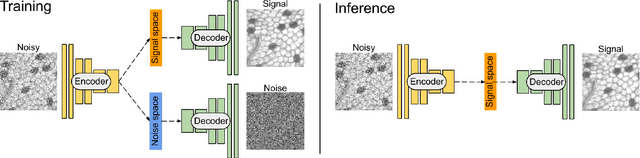
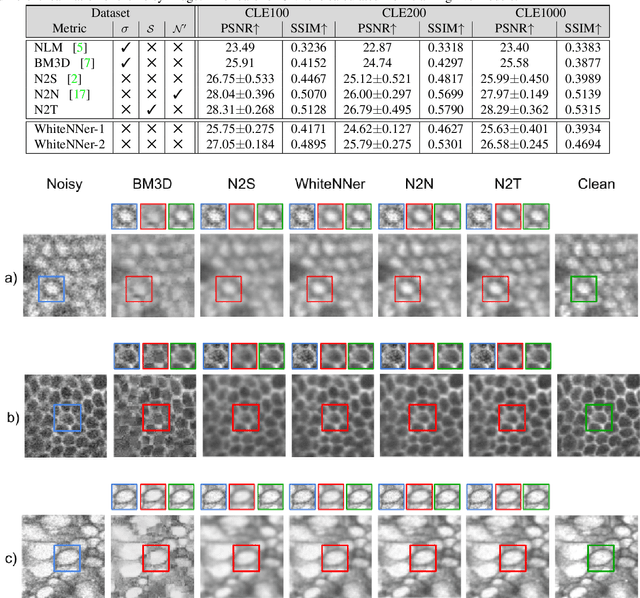
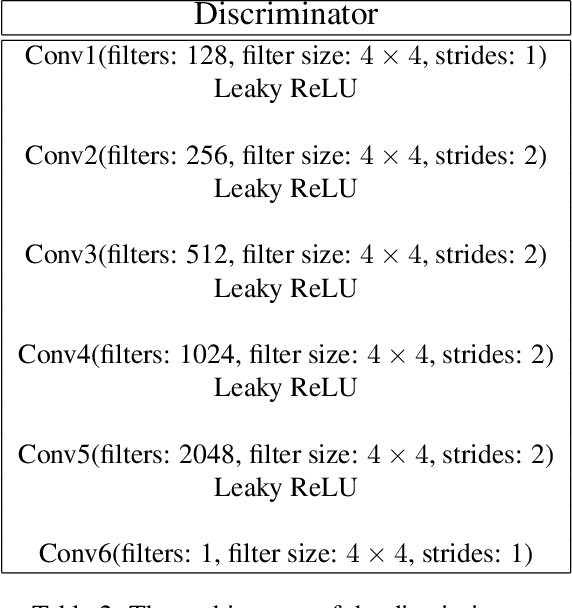
The accuracy of medical imaging-based diagnostics is directly impacted by the quality of the collected images. A passive approach to improve image quality is one that lags behind improvements in imaging hardware, awaiting better sensor technology of acquisition devices. An alternative, active strategy is to utilize prior knowledge of the imaging system to directly post-process and improve the acquired images. Traditionally, priors about the image properties are taken into account to restrict the solution space. However, few techniques exploit the prior about the noise properties. In this paper, we propose a neural network-based model for disentangling the signal and noise components of an input noisy image, without the need for any ground truth training data. We design a unified loss function that encodes priors about signal as well as noise estimate in the form of regularization terms. Specifically, by using total variation and piecewise constancy priors along with noise whiteness priors such as auto-correlation and stationary losses, our network learns to decouple an input noisy image into the underlying signal and noise components. We compare our proposed method to Noise2Noise and Noise2Self, as well as non-local mean and BM3D, on three public confocal laser endomicroscopy datasets. Experimental results demonstrate the superiority of our network compared to state-of-the-art in terms of PSNR and SSIM.
Automatic hippocampal surface generation via 3D U-net and active shape modeling with hybrid particle swarm optimization
Sep 14, 2021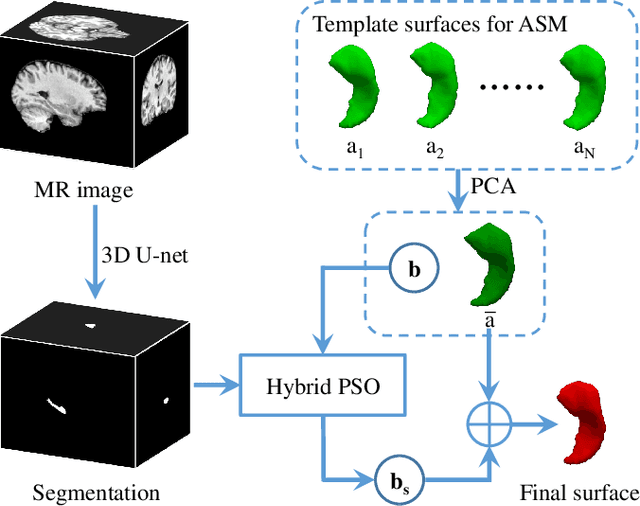
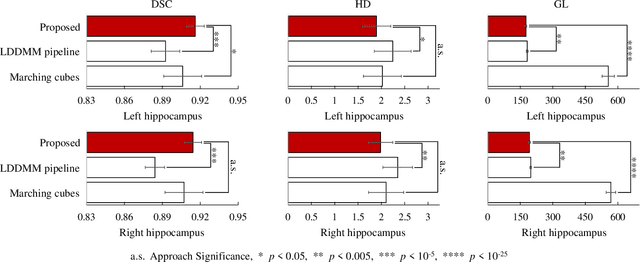


In this paper, we proposed and validated a fully automatic pipeline for hippocampal surface generation via 3D U-net coupled with active shape modeling (ASM). Principally, the proposed pipeline consisted of three steps. In the beginning, for each magnetic resonance image, a 3D U-net was employed to obtain the automatic hippocampus segmentation at each hemisphere. Secondly, ASM was performed on a group of pre-obtained template surfaces to generate mean shape and shape variation parameters through principal component analysis. Ultimately, hybrid particle swarm optimization was utilized to search for the optimal shape variation parameters that best match the segmentation. The hippocampal surface was then generated from the mean shape and the shape variation parameters. The proposed pipeline was observed to provide hippocampal surfaces at both hemispheres with high accuracy, correct anatomical topology, and sufficient smoothness.
Real-Time Tactile Grasp Force Sensing Using Fingernail Imaging via Deep Neural Networks
Sep 30, 2021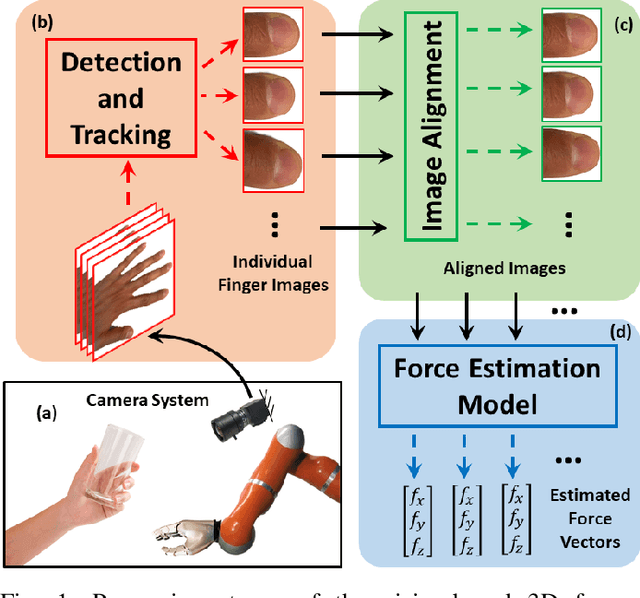
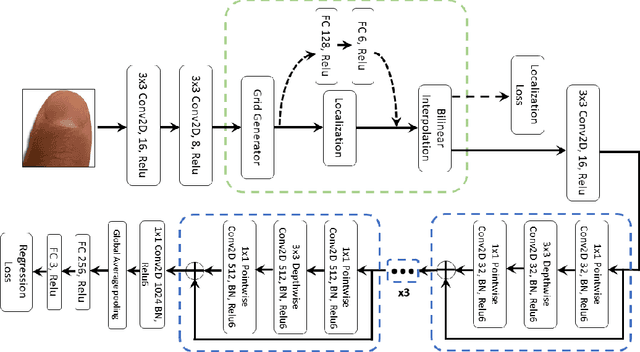

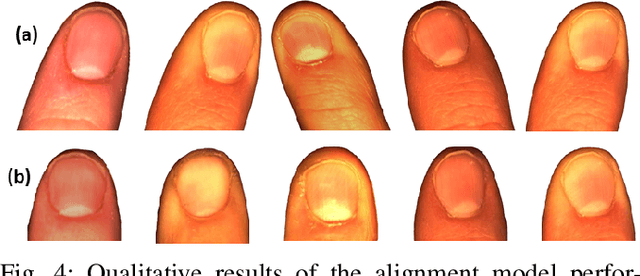
This paper has introduced a novel approach for the real-time estimation of 3D tactile forces exerted by human fingertips via vision only. The introduced approach is entirely monocular vision-based and does not require any physical force sensor. Therefore, it is scalable, non-intrusive, and easily fused with other perception systems such as body pose estimation, making it ideal for HRI applications where force sensing is necessary. The introduced approach consists of three main modules: finger tracking for detection and tracking of each individual finger, image alignment for preserving the spatial information in the images, and the force model for estimating the 3D forces from coloration patterns in the images. The model has been implemented experimentally, and the results have shown a maximum RMS error of 8.4% (for the entire range of force levels) along all three directions. The estimation accuracy is comparable to the offline models in the literature, such as EigneNail, while, this model is capable of performing force estimation at 30 frames per second.
Visual Forecasting of Time Series with Image-to-Image Regression
Nov 18, 2020
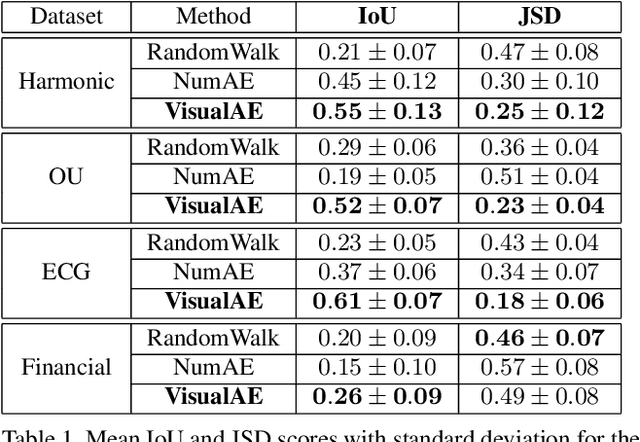
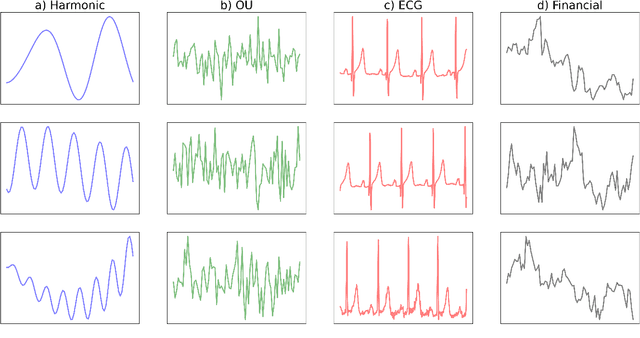
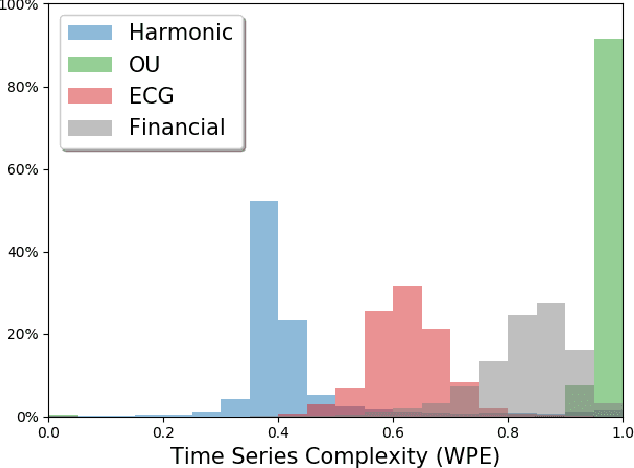
Time series forecasting is essential for agents to make decisions in many domains. Existing models rely on classical statistical methods to predict future values based on previously observed numerical information. Yet, practitioners often rely on visualizations such as charts and plots to reason about their predictions. Inspired by the end-users, we re-imagine the topic by creating a framework to produce visual forecasts, similar to the way humans intuitively do. In this work, we take a novel approach by leveraging advances in deep learning to extend the field of time series forecasting to a visual setting. We do this by transforming the numerical analysis problem into the computer vision domain. Using visualizations of time series data as input, we train a convolutional autoencoder to produce corresponding visual forecasts. We examine various synthetic and real datasets with diverse degrees of complexity. Our experiments show that visual forecasting is effective for cyclic data but somewhat less for irregular data such as stock price. Importantly, we find the proposed visual forecasting method to outperform numerical baselines. We attribute the success of the visual forecasting approach to the fact that we convert the continuous numerical regression problem into a discrete domain with quantization of the continuous target signal into pixel space.
Image-based table recognition: data, model, and evaluation
Jan 07, 2020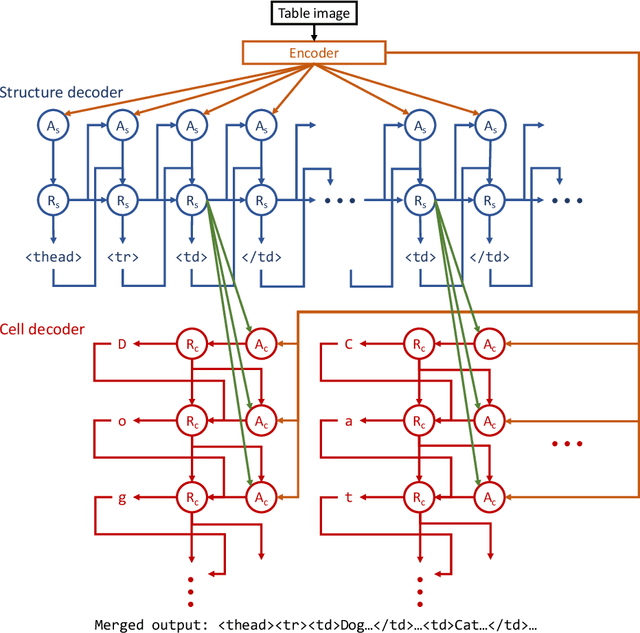
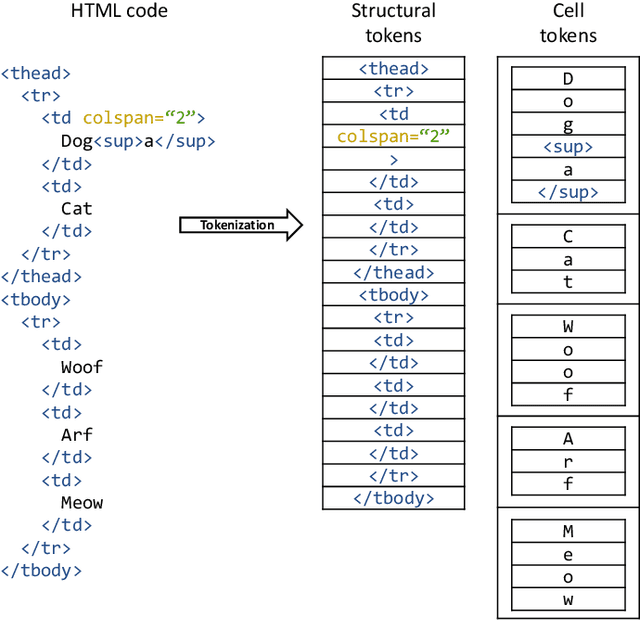
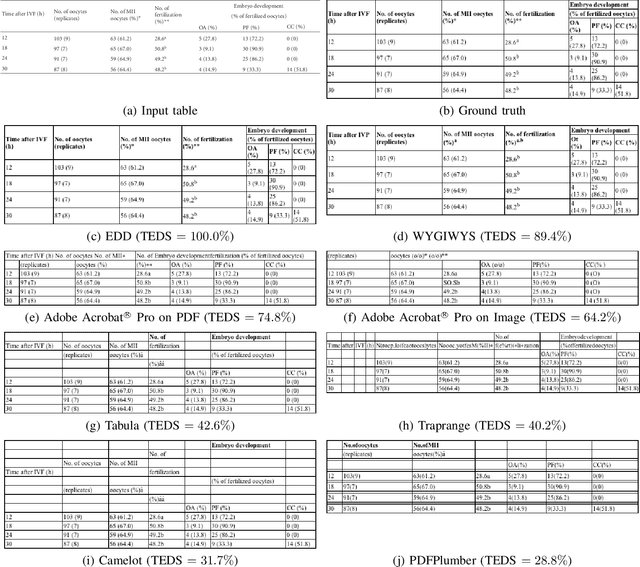

Important information that relates to a specific topic in a document is often organized in tabular format to assist readers with information retrieval and comparison, which may be difficult to provide in natural language. However, tabular data in unstructured digital documents, e.g., Portable Document Format (PDF) and images, are difficult to parse into structured machine-readable format, due to complexity and diversity in their structure and style. To facilitate image-based table recognition with deep learning, we develop the largest publicly available table recognition dataset PubTabNet (https://github.com/ibm-aur-nlp/PubTabNet), containing 568k table images with corresponding structured HTML representation. PubTabNet is automatically generated by matching the XML and PDF representations of the scientific articles in PubMed Central Open Access Subset (PMCOA). We also propose a novel attention-based encoder-dual-decoder (EDD) architecture that converts images of tables into HTML code. The model has a structure decoder which reconstructs the table structure and helps the cell decoder to recognize cell content. In addition, we propose a new Tree-Edit-Distance-based Similarity (TEDS) metric for table recognition. The experiments demonstrate that the EDD model can accurately recognize complex tables solely relying on the image representation, outperforming the state-of-the-art by 9.7% absolute TEDS score.
Shared Certificates for Neural Network Verification
Sep 14, 2021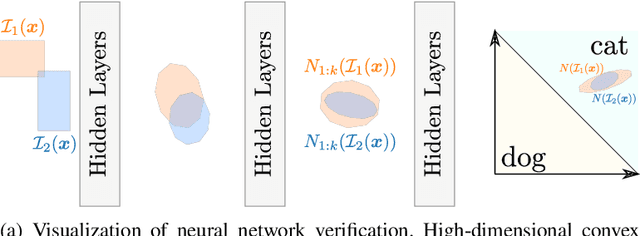

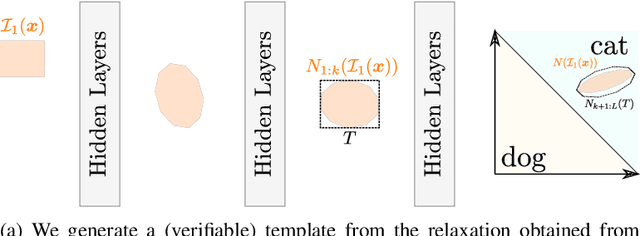
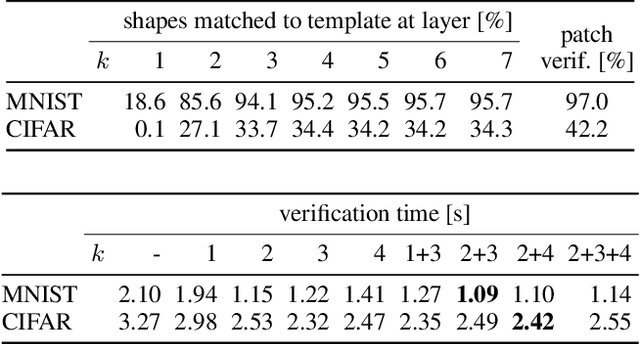
Existing neural network verifiers compute a proof that each input is handled correctly under a given perturbation by propagating a convex set of reachable values at each layer. This process is repeated independently for each input (e.g., image) and perturbation (e.g., rotation), leading to an expensive overall proof effort when handling an entire dataset. In this work we introduce a new method for reducing this verification cost based on the key insight that convex sets obtained at intermediate layers can overlap across different inputs and perturbations. Leveraging this insight, we introduce the general concept of shared certificates, enabling proof effort reuse across multiple inputs and driving down overall verification costs. We validate our insight via an extensive experimental evaluation and demonstrate the effectiveness of shared certificates on a range of datasets and attack specifications including geometric, patch and $\ell_\infty$ input perturbations.