 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RMDL: Recalibrated multi-instance deep learning for whole slide gastric image classification
Oct 13, 2020
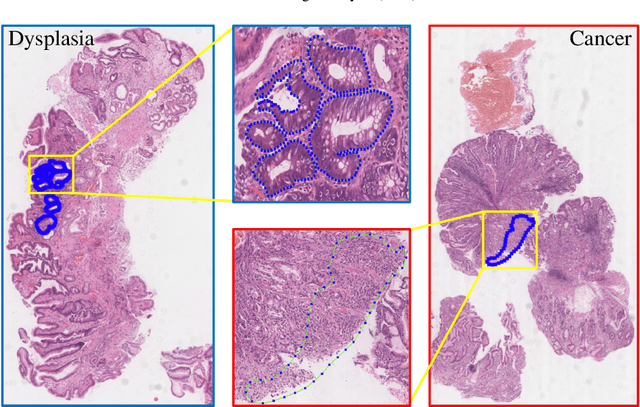

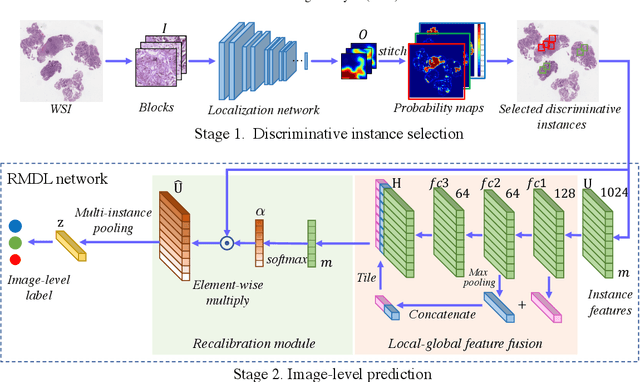
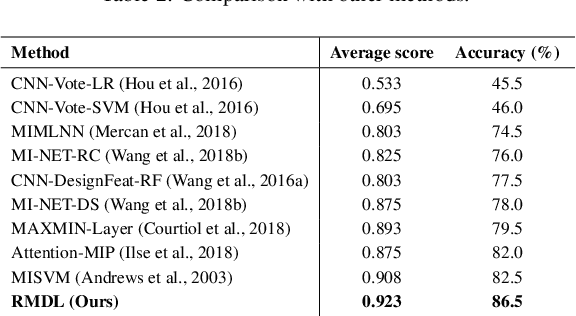
The whole slide histopathology images (WSIs) play a critical role in gastric cancer diagnosis. However, due to the large scale of WSIs and various sizes of the abnormal area, how to select informative regions and analyze them are quite challenging during the automatic diagnosis process. The multi-instance learning based on the most discriminative instances can be of great benefit for whole slide gastric image diagnosis. In this paper, we design a recalibrated multi-instance deep learning method (RMDL) to address this challenging problem. We first select the discriminative instances, and then utilize these instances to diagnose diseases based on the proposed RMDL approach. The designed RMDL network is capable of capturing instance-wise dependencies and recalibrating instance features according to the importance coefficient learned from the fused features. Furthermore, we build a large whole-slide gastric histopathology image dataset with detailed pixel-level annotations. Experimental results on the constructed gastric dataset demonstrate the significant improvement on the accuracy of our proposed framework compared with other state-of-the-art multi-instance learning methods. Moreover, our method is general and can be extended to other diagnosis tasks of different cancer types based on WSIs.
A Digital Image Processing Approach for Hepatic Diseases Staging based on the Glisson's Capsule
Nov 17, 2020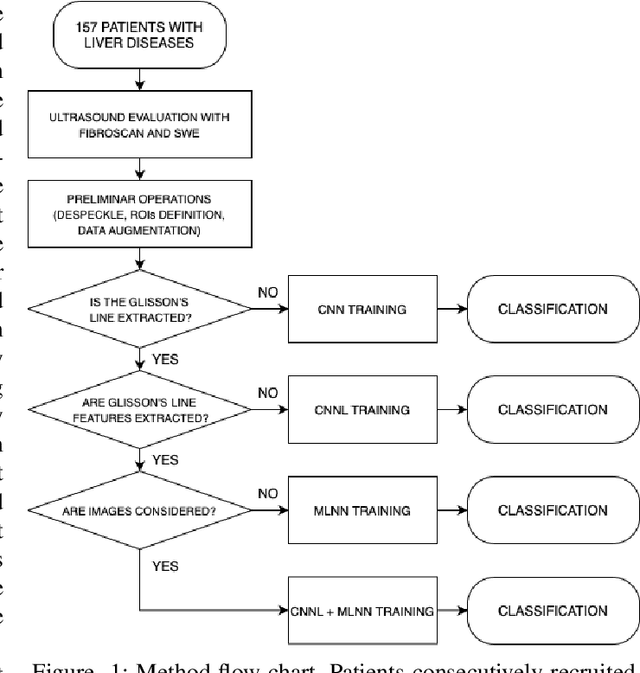

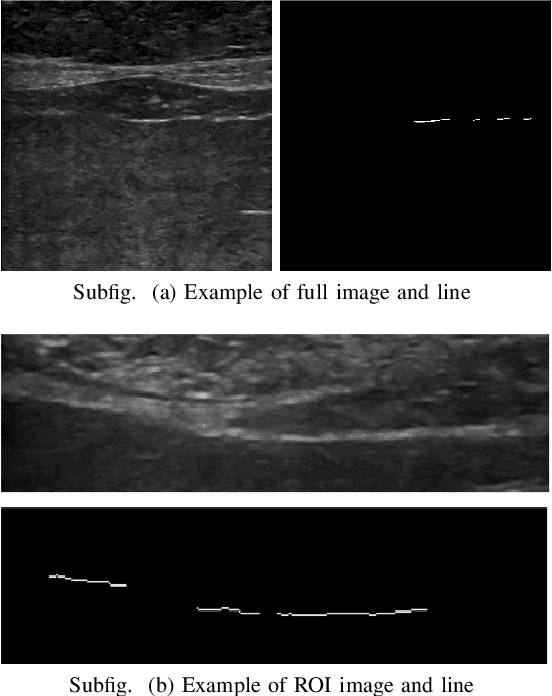
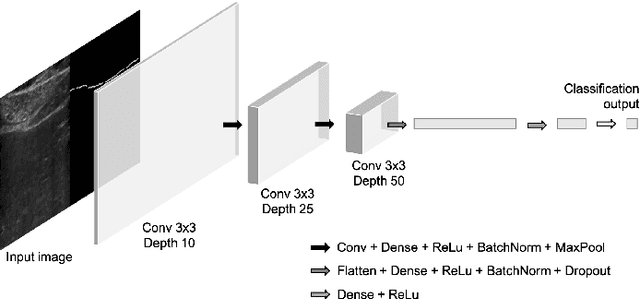
Due to the need for quick and effective treatments for liver diseases, which are among the most common health problems in the world, staging fibrosis through non-invasive and economic methods has become of great importance. Taking inspiration from diagnostic laparoscopy, used in the past for hepatic diseases, in this paper ultrasound images of the liver are studied, focusing on a specific region of the organ where the Glisson's capsule is visible. In ultrasound images, the Glisson's capsule appears in the shape of a line which can be extracted via classical methods in literature. By making use of a combination of standard image processing techniques and Convolutional Neural Network approaches, the scope of this work is to give evidence to the idea that a great informative potential relies on smoothness of the Glisson's capsule surface. To this purpose, several classifiers are taken into consideration, which deal with different type of data, namely ultrasound images, binary images depicting the Glisson's line, and features vector extracted from the original image. This is a preliminary study that has been retrospectively conducted, based on the results of the elastosonography examination.
Through-Foliage Tracking with Airborne Optical Sectioning
Nov 12, 2021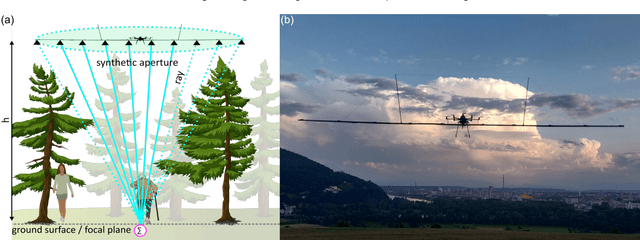
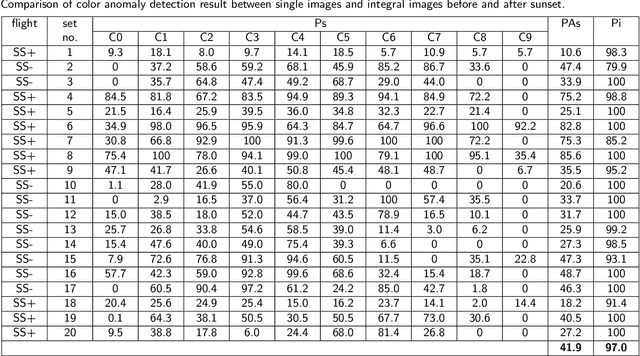
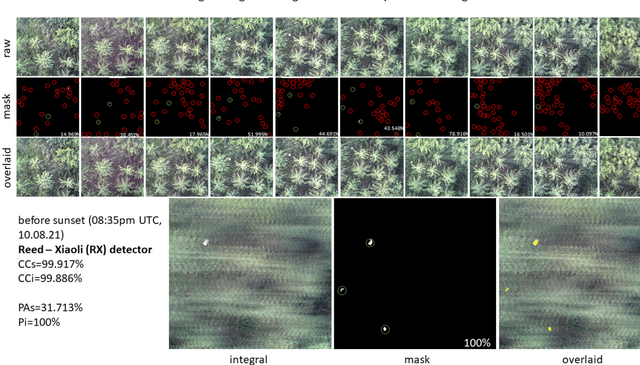
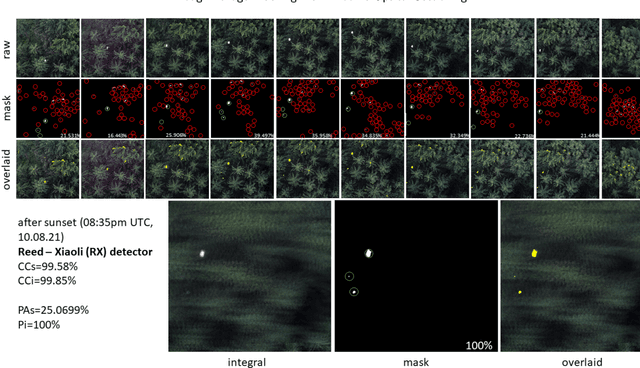
Detecting and tracking moving targets through foliage is difficult, and for many cases even impossible in regular aerial images and videos. We present an initial light-weight and drone-operated 1D camera array that supports parallel synthetic aperture aerial imaging. Our main finding is that color anomaly detection benefits significantly from image integration when compared to conventional single images or video frames (on average 97% vs. 42% in precision in our field experiments). We demonstrate, that these two contributions can lead to the detection and tracking of moving people through densely occluding forest
A CNN-based Patent Image Retrieval Method for Design Ideation
Mar 10, 2020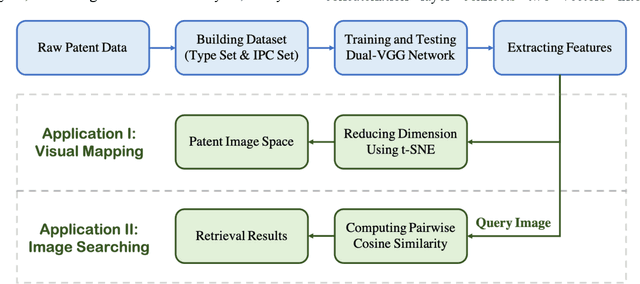

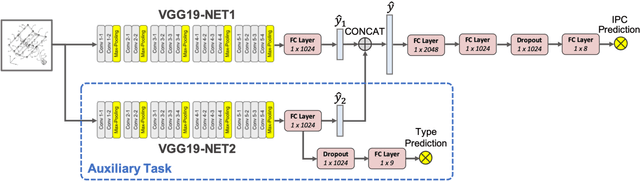
The patent database is often used in searches of inspirational stimuli for innovative design opportunities because of its large size, extensive variety and rich design information in patent documents. However, most patent mining research only focuses on textual information and ignores visual information. Herein, we propose a convolutional neural network (CNN)- based patent image retrieval method. The core of this approach is a novel neural network architecture named Dual-VGG that is aimed to accomplish two tasks: visual material type prediction and International Patent Classification (IPC) class label prediction. In turn, the trained neural network provides the deep features in the image embedding vectors that can be utilized for patent image retrieval. The accuracy of both training tasks and patent image embedding space are evaluated to show the performance of our model. This approach is also illustrated in a case study of robot arm design retrieval. Compared to traditional keyword-based searching and Google image searching, the proposed method discovers more useful visual information for engineering design.
Image Denoising Using Sparsifying Transform Learning and Weighted Singular Values Minimization
Apr 02, 2020
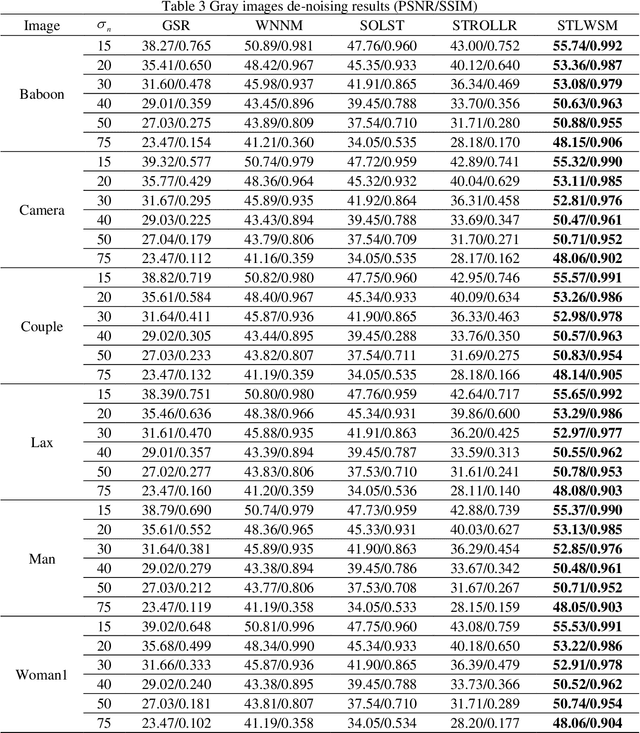
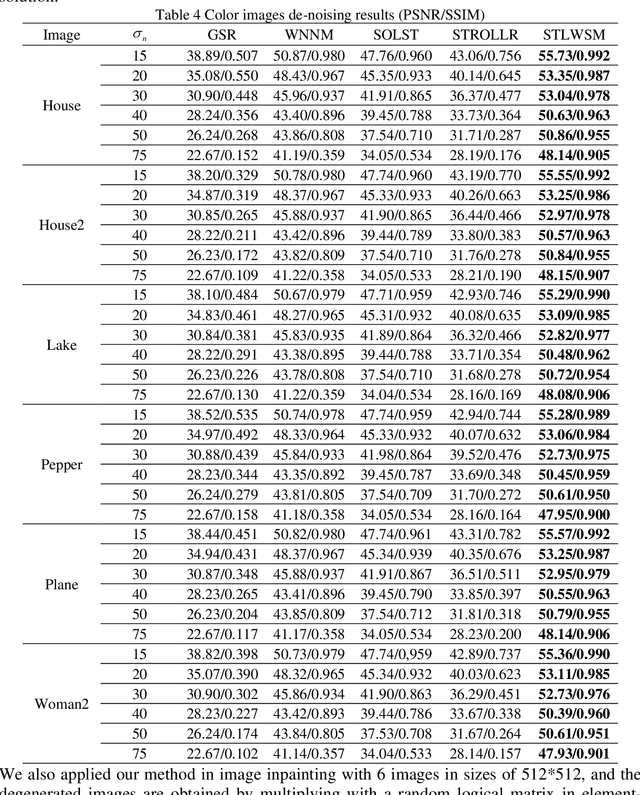
In image denoising (IDN) processing, the low-rank property is usually considered as an important image prior. As a convex relaxation approximation of low rank, nuclear norm based algorithms and their variants have attracted significant attention. These algorithms can be collectively called image domain based methods, whose common drawback is the requirement of great number of iterations for some acceptable solution. Meanwhile, the sparsity of images in a certain transform domain has also been exploited in image denoising problems. Sparsity transform learning algorithms can achieve extremely fast computations as well as desirable performance. By taking both advantages of image domain and transform domain in a general framework, we propose a sparsity transform learning and weighted singular values minimization method (STLWSM) for IDN problems. The proposed method can make full use of the preponderance of both domains. For solving the non-convex cost function, we also present an efficient alternative solution for acceleration. Experimental results show that the proposed STLWSM achieves improvement both visually and quantitatively with a large margin over state-of-the-art approaches based on an alternatively single domain. It also needs much less iteration than all the image domain algorithms.
DoubleU-Net: A Deep Convolutional Neural Network for Medical Image Segmentation
Jun 08, 2020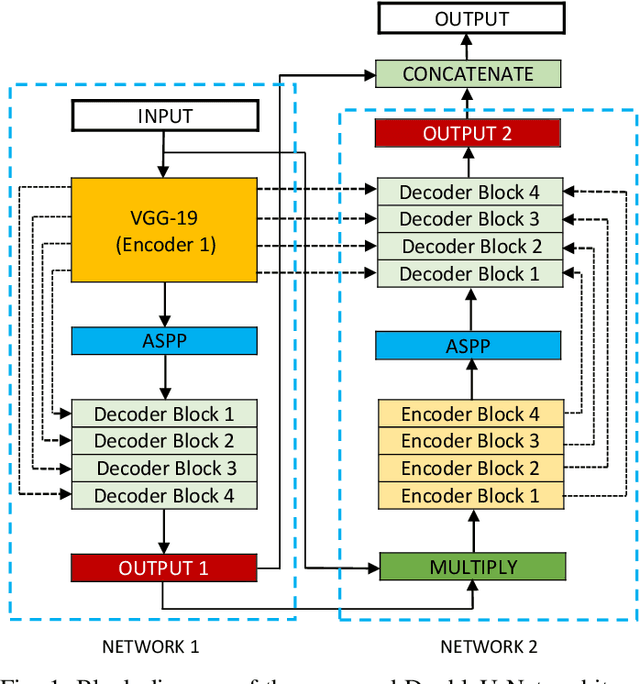
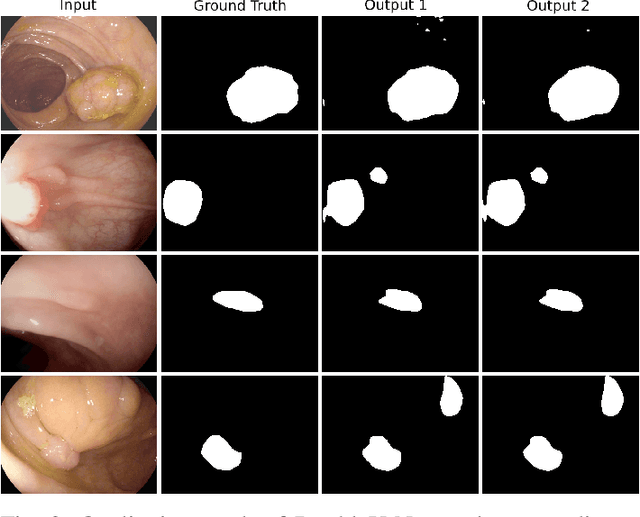
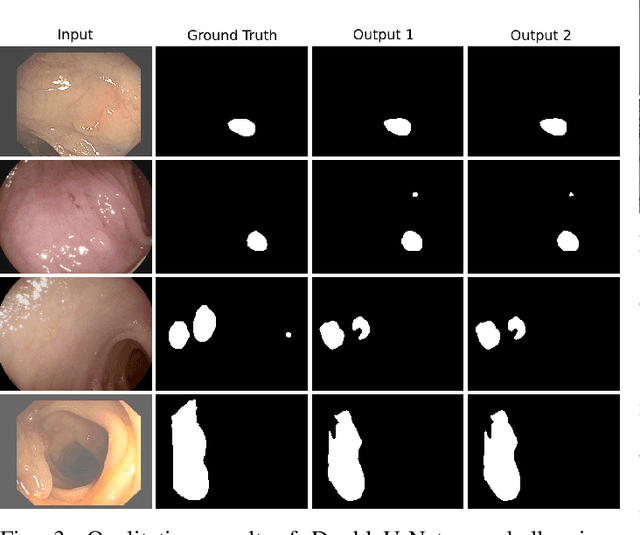
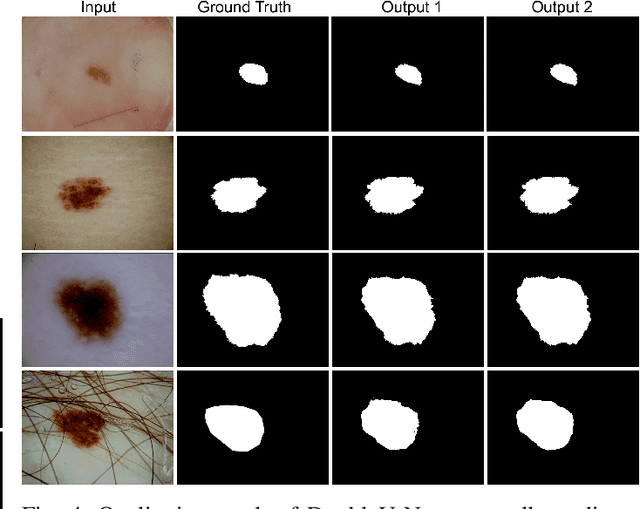
Semantic image segmentation is the process of labeling each pixel of an image with its corresponding class. An encoder-decoder based approach, like U-Net and its variants, is a popular strategy for solving medical image segmentation tasks. To improve the performance of U-Net on various segmentation tasks, we propose a novel architecture called DoubleU-Net, which is a combination of two U-Net architectures stacked on top of each other. The first U-Net uses a pre-trained VGG-19 as the encoder, which has already learned features from ImageNet and can be transferred to another task easily. To capture more semantic information efficiently, we added another U-Net at the bottom. We also adopt Atrous Spatial Pyramid Pooling (ASPP) to capture contextual information within the network. We have evaluated DoubleU-Net using four medical segmentation datasets, covering various imaging modalities such as colonoscopy, dermoscopy, and microscopy. Experiments on the MICCAI 2015 segmentation challenge, the CVC-ClinicDB, the 2018 Data Science Bowl challenge, and the Lesion boundary segmentation datasets demonstrate that the DoubleU-Net outperforms U-Net and the baseline models. Moreover, DoubleU-Net produces more accurate segmentation masks, especially in the case of the CVC-ClinicDB and MICCAI 2015 segmentation challenge datasets, which have challenging images such as smaller and flat polyps. These results show the improvement over the existing U-Net model. The encouraging results, produced on various medical image segmentation datasets, show that DoubleU-Net can be used as a strong baseline for both medical image segmentation and cross-dataset evaluation testing to measure the generalizability of Deep Learning (DL) models.
ERQA: Edge-Restoration Quality Assessment for Video Super-Resolution
Oct 19, 2021

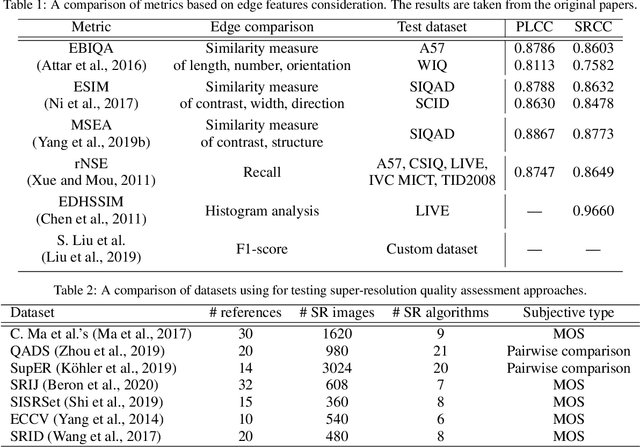

Despite the growing popularity of video super-resolution (VSR), there is still no good way to assess the quality of the restored details in upscaled frames. Some SR methods may produce the wrong digit or an entirely different face. Whether a method's results are trustworthy depends on how well it restores truthful details. Image super-resolution can use natural distributions to produce a high-resolution image that is only somewhat similar to the real one. VSR enables exploration of additional information in neighboring frames to restore details from the original scene. The ERQA metric, which we propose in this paper, aims to estimate a model's ability to restore real details using VSR. On the assumption that edges are significant for detail and character recognition, we chose edge fidelity as the foundation for this metric. Experimental validation of our work is based on the MSU Video Super-Resolution Benchmark, which includes the most difficult patterns for detail restoration and verifies the fidelity of details from the original frame. Code for the proposed metric is publicly available at https://github.com/msu-video-group/ERQA.
Compressive Scanning Transmission Electron Microscopy
Dec 22, 2021


Scanning Transmission Electron Microscopy (STEM) offers high-resolution images that are used to quantify the nanoscale atomic structure and composition of materials and biological specimens. In many cases, however, the resolution is limited by the electron beam damage, since in traditional STEM, a focused electron beam scans every location of the sample in a raster fashion. In this paper, we propose a scanning method based on the theory of Compressive Sensing (CS) and subsampling the electron probe locations using a line hop sampling scheme that significantly reduces the electron beam damage. We experimentally validate the feasibility of the proposed method by acquiring real CS-STEM data, and recovering images using a Bayesian dictionary learning approach. We support the proposed method by applying a series of masks to fully-sampled STEM data to simulate the expectation of real CS-STEM. Finally, we perform the real data experimental series using a constrained-dose budget to limit the impact of electron dose upon the results, by ensuring that the total electron count remains constant for each image.
Highly precise AMCW time-of-flight scanning sensor based on digital-parallel demodulation
Dec 16, 2021
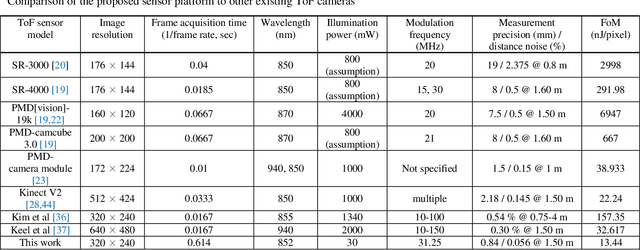
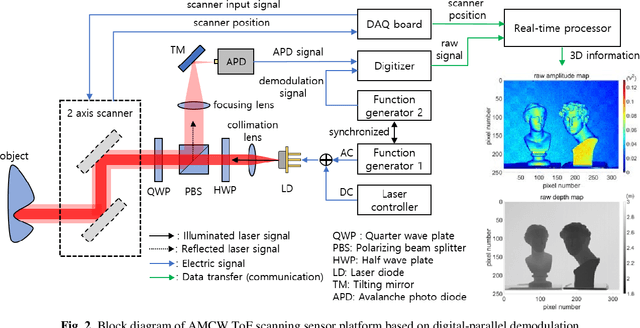
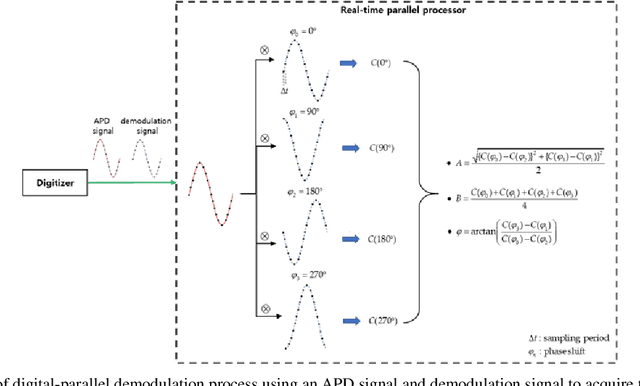
In this paper, a novel amplitude-modulated continuous wave (AMCW) time-of-flight (ToF) scanning sensor based on digital-parallel demodulation is proposed and demonstrated in the aspect of distance measurement precision. Since digital-parallel demodulation utilizes a high-amplitude demodulation signal with zero-offset, the proposed sensor platform can maintain extremely high demodulation contrast. Meanwhile, as all cross correlated samples are calculated in parallel and in extremely short integration time, the proposed sensor platform can utilize a 2D laser scanning structure with a single photo detector, maintaining a moderate frame rate. This optical structure can increase the received optical SNR and remove the crosstalk of image pixel array. Based on these measurement properties, the proposed AMCW ToF scanning sensor shows highly precise 3D depth measurement performance. In this study, this precise measurement performance is explained in detail. Additionally, the actual measurement performance of the proposed sensor platform is experimentally validated under various conditions.
Towards continual task learning in artificial neural networks: current approaches and insights from neuroscience
Dec 28, 2021
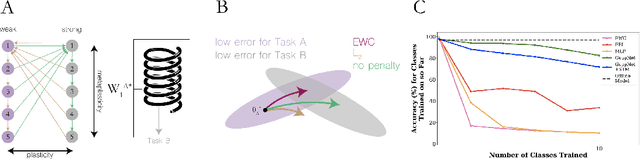
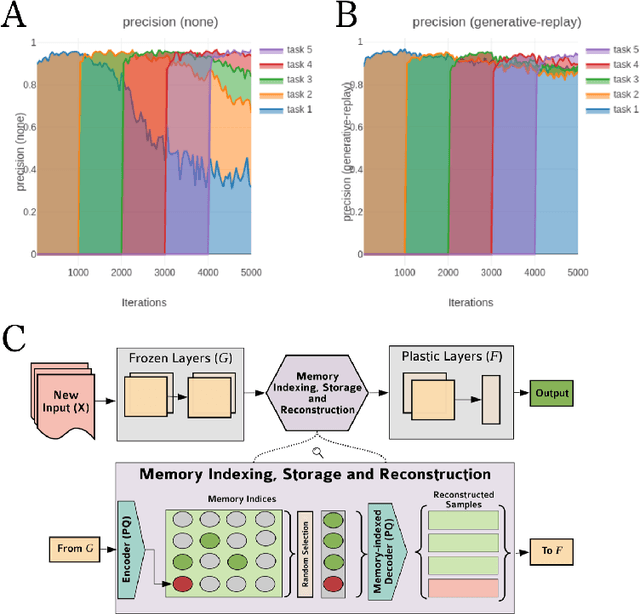
The innate capacity of humans and other animals to learn a diverse, and often interfering, range of knowledge and skills throughout their lifespan is a hallmark of natural intelligence, with obvious evolutionary motivations. In parallel, the ability of artificial neural networks (ANNs) to learn across a range of tasks and domains, combining and re-using learned representations where required, is a clear goal of artificial intelligence. This capacity, widely described as continual learning, has become a prolific subfield of research in machine learning. Despite the numerous successes of deep learning in recent years, across domains ranging from image recognition to machine translation, such continual task learning has proved challenging. Neural networks trained on multiple tasks in sequence with stochastic gradient descent often suffer from representational interference, whereby the learned weights for a given task effectively overwrite those of previous tasks in a process termed catastrophic forgetting. This represents a major impediment to the development of more generalised artificial learning systems, capable of accumulating knowledge over time and task space, in a manner analogous to humans. A repository of selected papers and implementations accompanying this review can be found at https://github.com/mccaffary/continual-learning.