 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLCNet: Rethinking of Ensemble Modeling with Classification Confidence Network
May 19, 2022
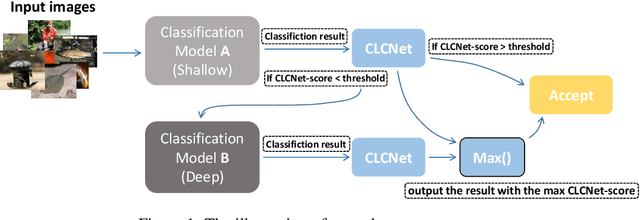
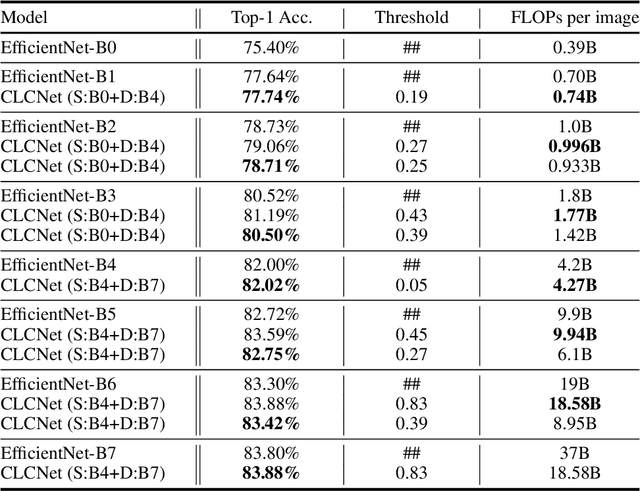
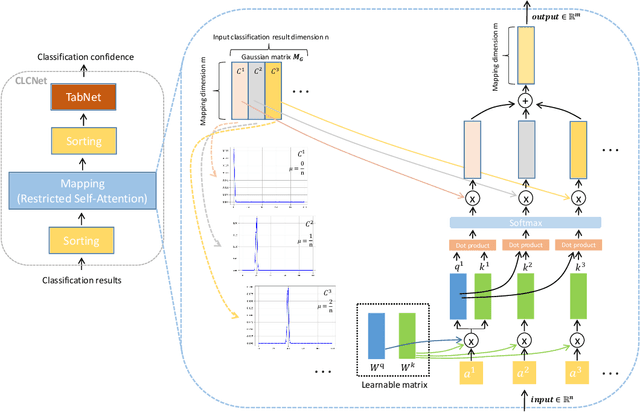
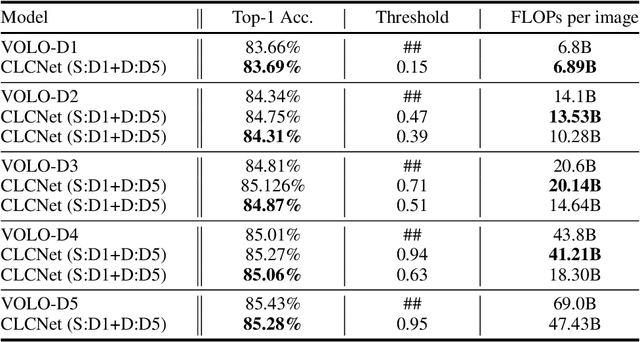
In this paper, we propose a Classification Confidence Network (CLCNet) that can determine whether the classification model classifies input samples correctly. It can take a classification result in the form of vector in any dimension, and return a confidence score as output, which represents the probability of an instance being classified correctly. We can utilize CLCNet in a simple cascade structure system consisting of several SOTA (state-of-the-art) classification models, and our experiments show that the system can achieve the following advantages: 1. The system can customize the average computation requirement (FLOPs) per image while inference. 2. Under the same computation requirement, the performance of the system can exceed any model that has identical structure with the model in the system, but different in size. In fact, this is a new type of ensemble modeling. Like general ensemble modeling, it can achieve higher performance than single classification model, yet our system requires much less computation than general ensemble modeling. We have uploaded our code to a github repository: https://github.com/yaoching0/CLCNet-Rethinking-of-Ensemble-Modeling.
Fake It Till You Make It: Near-Distribution Novelty Detection by Score-Based Generative Models
May 28, 2022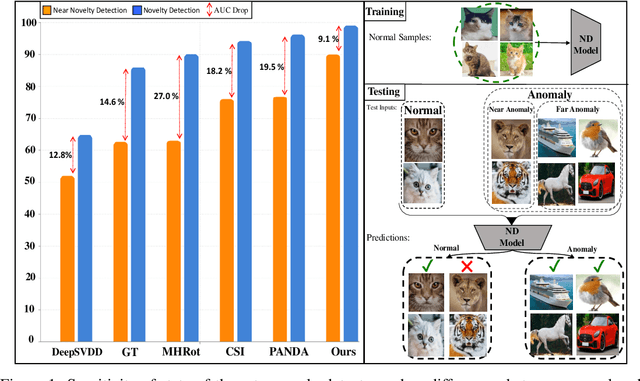
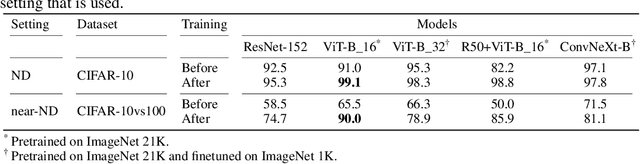
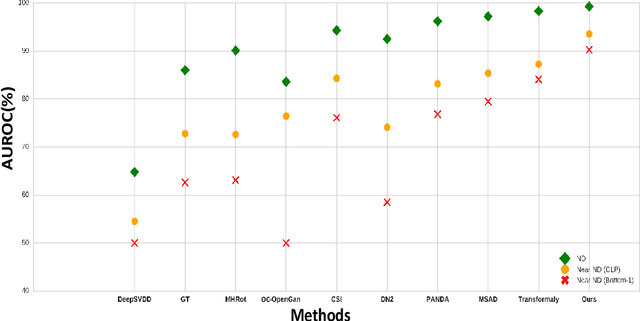
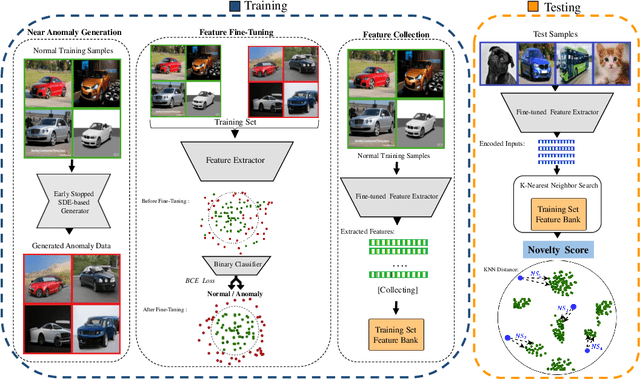
We aim for image-based novelty detection. Despite considerable progress, existing models either fail or face a dramatic drop under the so-called ``near-distribution" setting, where the differences between normal and anomalous samples are subtle. We first demonstrate existing methods experience up to 20\% decrease in performance in the near-distribution setting. Next, we propose to exploit a score-based generative model to produce synthetic near-distribution anomalous data. Our model is then fine-tuned to distinguish such data from the normal samples. We provide a quantitative as well as qualitative evaluation of this strategy, and compare the results with a variety of GAN-based models. Effectiveness of our method for both the near-distribution and standard novelty detection is assessed through extensive experiments on datasets in diverse applications such as medical images, object classification, and quality control. This reveals that our method considerably improves over existing models, and consistently decreases the gap between the near-distribution and standard novelty detection performance. Overall, our method improves the near-distribution novelty detection by 6% and passes the state-of-the-art by 1% to 5% across nine novelty detection benchmarks. The code repository is available at https://github.com/rohban-lab/FITYMI
Visual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 30, 2022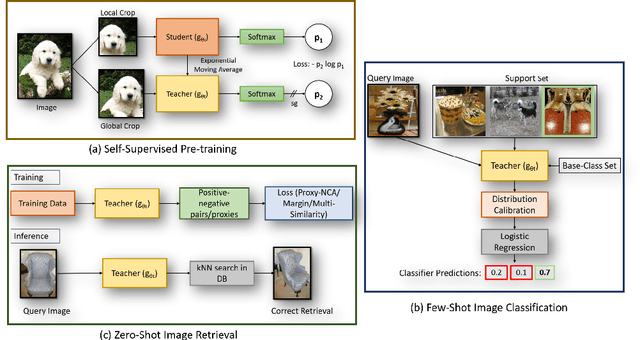
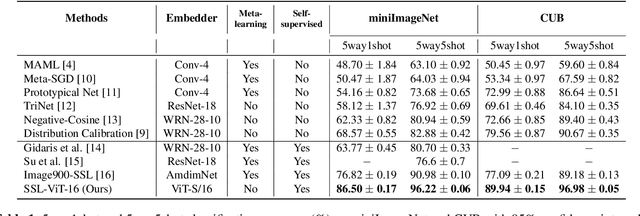
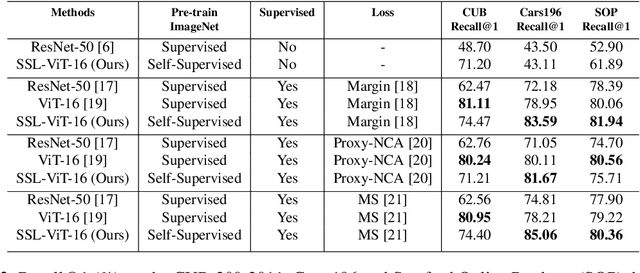

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable and semantically meaningful embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
An Embedded System for Image-based Crack Detection by using Fine-Tuning model of Adaptive Structural Learning of Deep Belief Network
Oct 25, 2021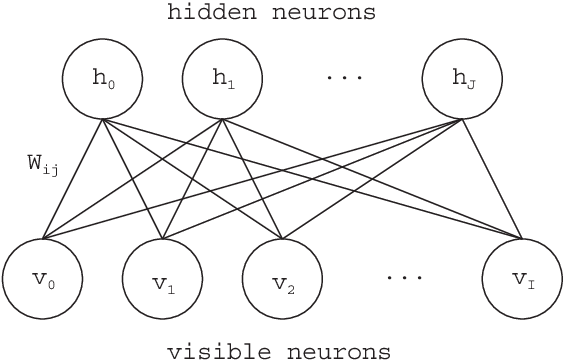
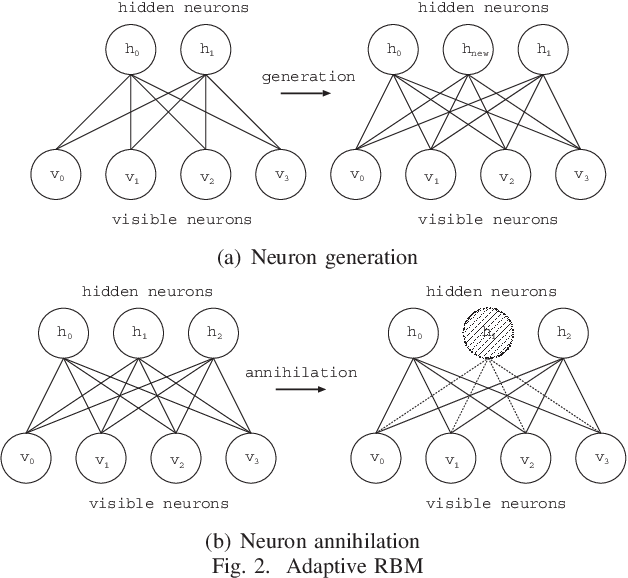
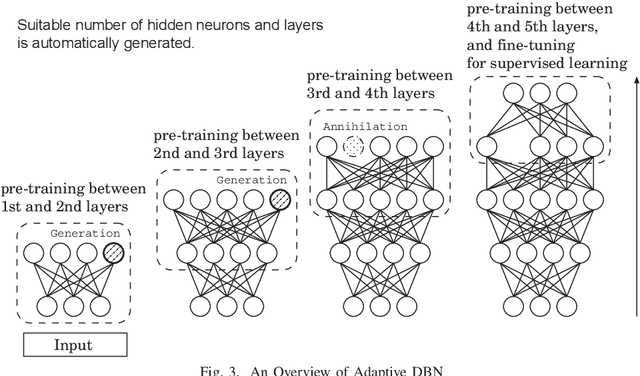

Deep learning has been a successful model which can effectively represent several features of input space and remarkably improve image recognition performance on the deep architectures. In our research, an adaptive structural learning method of Restricted Boltzmann Machine (Adaptive RBM) and Deep Belief Network (Adaptive DBN) have been developed as a deep learning model. The models have a self-organize function which can discover an optimal number of hidden neurons for given input data in a RBM by neuron generation-annihilation algorithm, and can obtain an appropriate number of RBM as hidden layers in the trained DBN. The proposed method was applied to a concrete image benchmark data set SDNET 2018 for crack detection. The dataset contains about 56,000 crack images for three types of concrete structures: bridge decks, walls, and paved roads. The fine-tuning method of the Adaptive DBN can show 99.7%, 99.7%, and 99.4% classification accuracy for test dataset of three types of structures. In this paper, our developed Adaptive DBN was embedded to a tiny PC with GPU for real-time inference on a drone. For fast inference, the fine tuning algorithm also removed some inactivated hidden neurons to make a small model and then the model was able to improve not only classification accuracy but also inference speed simultaneously. The inference speed and running time of portable battery charger were evaluated on three kinds of Nvidia embedded systems; Jetson Nano, AGX Xavier, and Xavier NX.
Analysis of Interpolation based Image In-painting Approaches
Feb 12, 2021


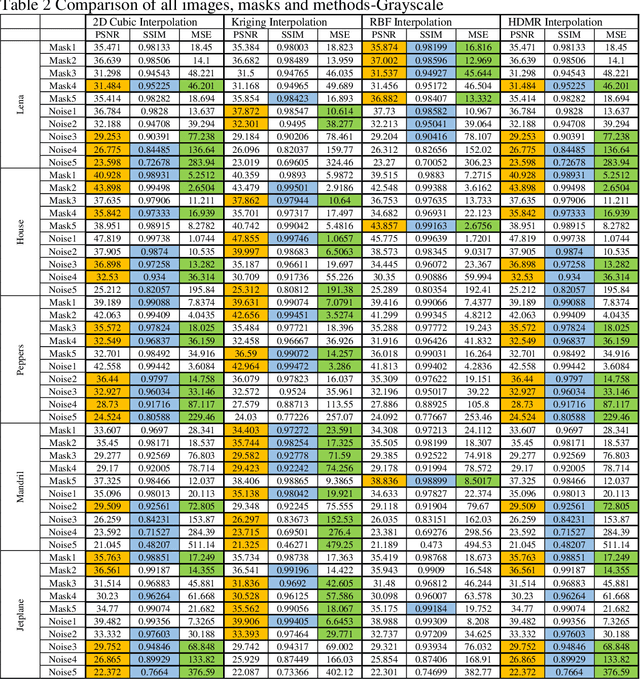
Interpolation and internal painting are one of the basic approaches in image internal painting, which is used to eliminate undesirable parts that occur in digital images or to enhance faulty parts. This study was designed to compare the interpolation algorithms used in image in-painting in the literature. Errors and noise generated on the colour and grayscale formats of some of the commonly used standard images in the literature were corrected by using Cubic, Kriging, Radial based function and High dimensional model representation approaches and the results were compared using standard image comparison criteria, namely, PSNR (peak signal-to-noise ratio), SSIM (Structural SIMilarity), Mean Square Error (MSE). According to the results obtained from the study, the absolute superiority of the methods against each other was not observed. However, Kriging and RBF interpolation give better results both for numerical data and visual evaluation for image in-painting problems with large area losses.
Feedback Gradient Descent: Efficient and Stable Optimization with Orthogonality for DNNs
May 12, 2022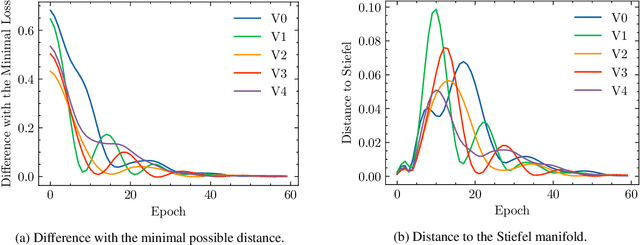
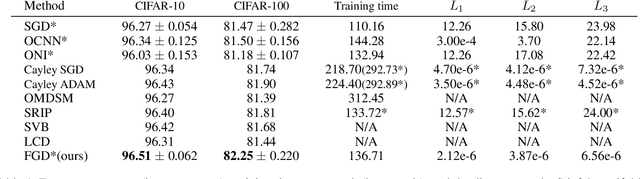
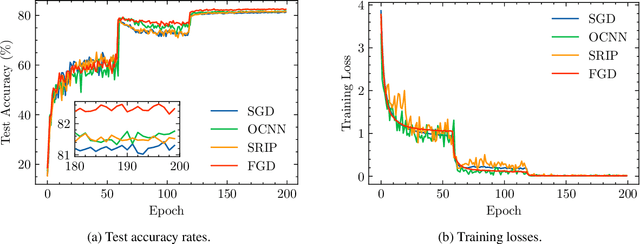

The optimization with orthogonality has been shown useful in training deep neural networks (DNNs). To impose orthogonality on DNNs, both computational efficiency and stability are important. However, existing methods utilizing Riemannian optimization or hard constraints can only ensure stability while those using soft constraints can only improve efficiency. In this paper, we propose a novel method, named Feedback Gradient Descent (FGD), to our knowledge, the first work showing high efficiency and stability simultaneously. FGD induces orthogonality based on the simple yet indispensable Euler discretization of a continuous-time dynamical system on the tangent bundle of the Stiefel manifold. In particular, inspired by a numerical integration method on manifolds called Feedback Integrators, we propose to instantiate it on the tangent bundle of the Stiefel manifold for the first time. In the extensive image classification experiments, FGD comprehensively outperforms the existing state-of-the-art methods in terms of accuracy, efficiency, and stability.
Differentiable SAR Renderer and SAR Target Reconstruction
May 14, 2022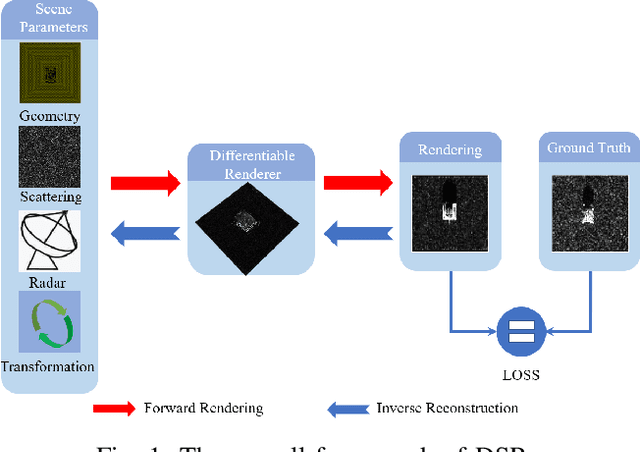

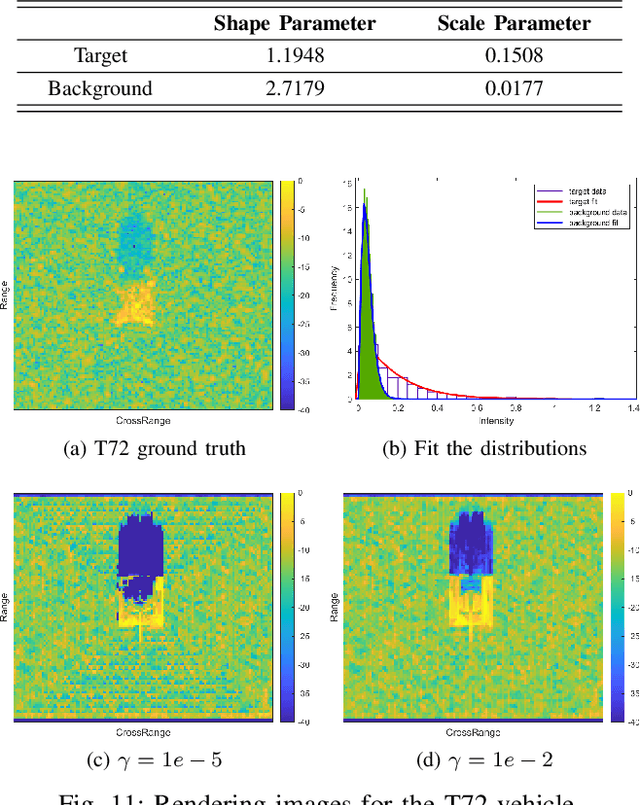
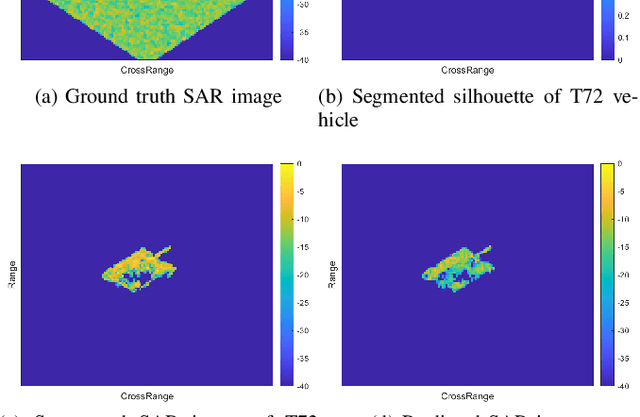
Forward modeling of wave scattering and radar imaging mechanisms is the key to information extraction from synthetic aperture radar (SAR) images. Like inverse graphics in optical domain, an inherently-integrated forward-inverse approach would be promising for SAR advanced information retrieval and target reconstruction. This paper presents such an attempt to the inverse graphics for SAR imagery. A differentiable SAR renderer (DSR) is developed which reformulates the mapping and projection algorithm of SAR imaging mechanism in the differentiable form of probability maps. First-order gradients of the proposed DSR are then analytically derived which can be back-propagated from rendered image/silhouette to the target geometry and scattering attributes. A 3D inverse target reconstruction algorithm from SAR images is devised. Several simulation and reconstruction experiments are conducted, including targets with and without background, using both synthesized data or real measured inverse SAR (ISAR) data by ground radar. Results demonstrate the efficacy of the proposed DSR and its inverse approach.
The Influence of the Other-Race Effect on Susceptibility to Face Morphing Attacks
Apr 26, 2022
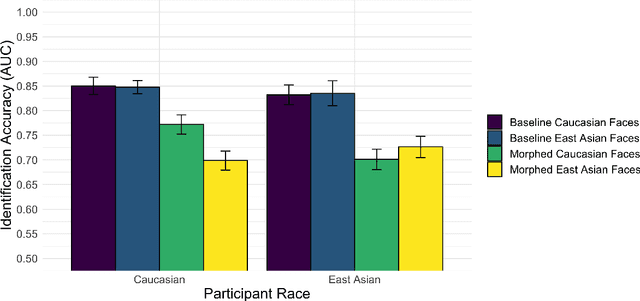
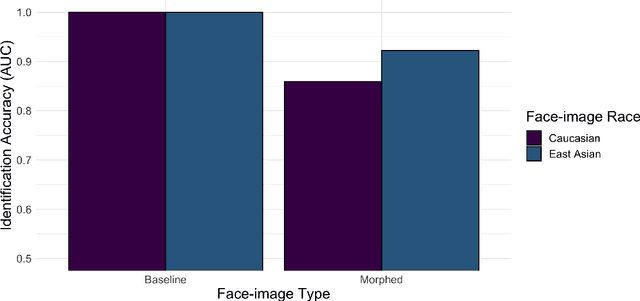
Facial morphs created between two identities resemble both of the faces used to create the morph. Consequently, humans and machines are prone to mistake morphs made from two identities for either of the faces used to create the morph. This vulnerability has been exploited in "morph attacks" in security scenarios. Here, we asked whether the "other-race effect" (ORE) -- the human advantage for identifying own- vs. other-race faces -- exacerbates morph attack susceptibility for humans. We also asked whether face-identification performance in a deep convolutional neural network (DCNN) is affected by the race of morphed faces. Caucasian (CA) and East-Asian (EA) participants performed a face-identity matching task on pairs of CA and EA face images in two conditions. In the morph condition, different-identity pairs consisted of an image of identity "A" and a 50/50 morph between images of identity "A" and "B". In the baseline condition, morphs of different identities never appeared. As expected, morphs were identified mistakenly more often than original face images. Moreover, CA participants showed an advantage for CA faces in comparison to EA faces (a partial ORE). Of primary interest, morph identification was substantially worse for cross-race faces than for own-race faces. Similar to humans, the DCNN performed more accurately for original face images than for morphed image pairs. Notably, the deep network proved substantially more accurate than humans in both cases. The results point to the possibility that DCNNs might be useful for improving face identification accuracy when morphed faces are presented. They also indicate the significance of the ORE in morph attack susceptibility in applied settings.
Curiously Effective Features for Image Quality Prediction
Jun 10, 2021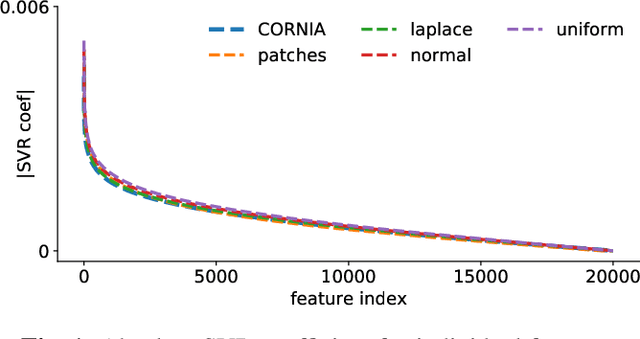
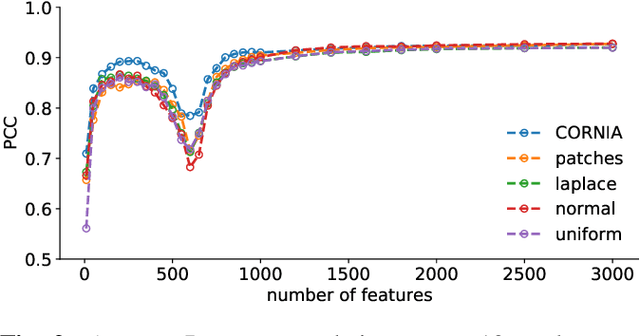
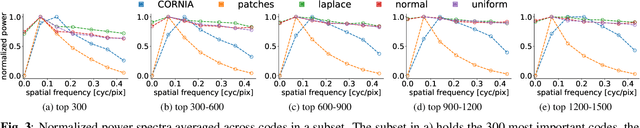
The performance of visual quality prediction models is commonly assumed to be closely tied to their ability to capture perceptually relevant image aspects. Models are thus either based on sophisticated feature extractors carefully designed from extensive domain knowledge or optimized through feature learning. In contrast to this, we find feature extractors constructed from random noise to be sufficient to learn a linear regression model whose quality predictions reach high correlations with human visual quality ratings, on par with a model with learned features. We analyze this curious result and show that besides the quality of feature extractors also their quantity plays a crucial role - with top performances only being achieved in highly overparameterized models.
LAPAR: Linearly-Assembled Pixel-Adaptive Regression Network for Single Image Super-Resolution and Beyond
May 21, 2021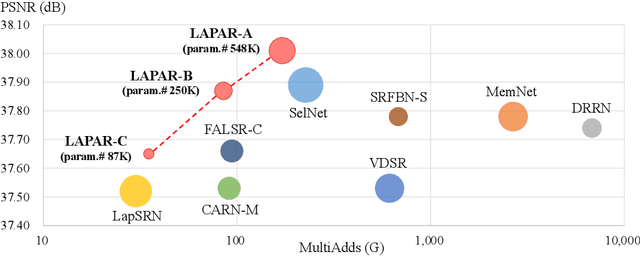
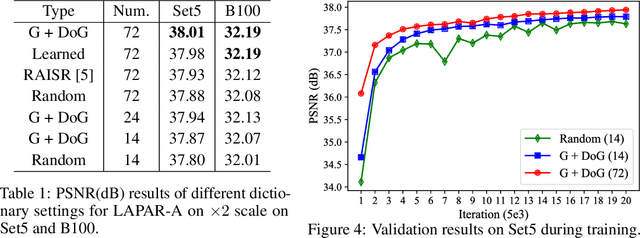
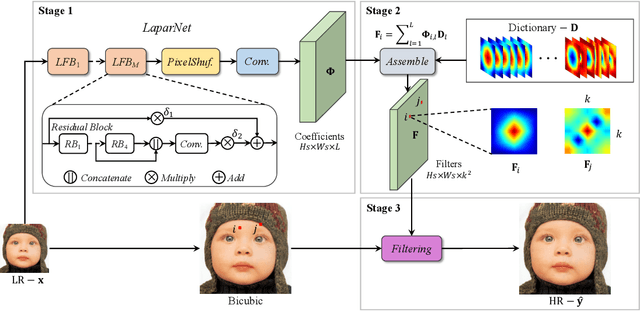
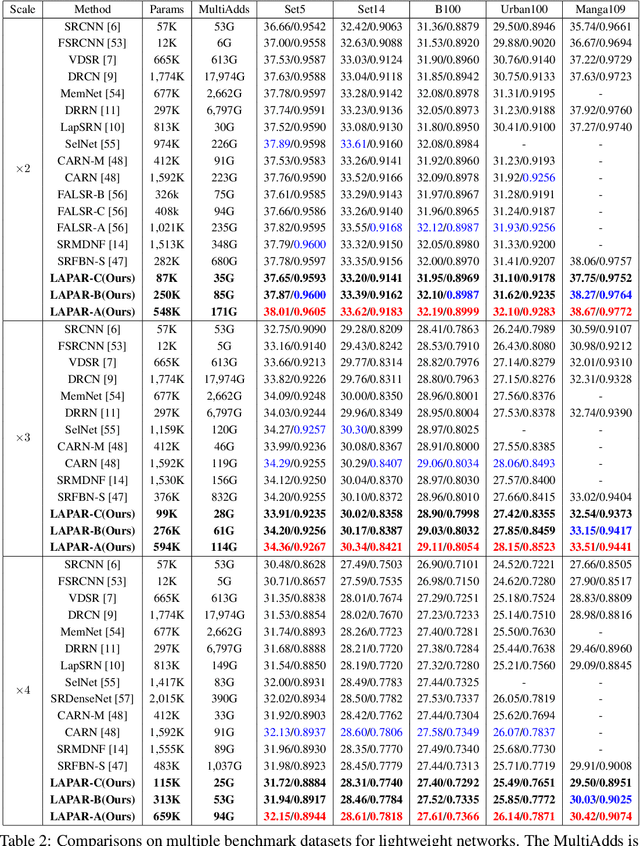
Single image super-resolution (SISR) deals with a fundamental problem of upsampling a low-resolution (LR) image to its high-resolution (HR) version. Last few years have witnessed impressive progress propelled by deep learning methods. However, one critical challenge faced by existing methods is to strike a sweet spot of deep model complexity and resulting SISR quality. This paper addresses this pain point by proposing a linearly-assembled pixel-adaptive regression network (LAPAR), which casts the direct LR to HR mapping learning into a linear coefficient regression task over a dictionary of multiple predefined filter bases. Such a parametric representation renders our model highly lightweight and easy to optimize while achieving state-of-the-art results on SISR benchmarks. Moreover, based on the same idea, LAPAR is extended to tackle other restoration tasks, e.g., image denoising and JPEG image deblocking, and again, yields strong performance. The code is available at https://github.com/dvlab-research/Simple-SR.