 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ReplaceBlock: An improved regularization method based on background information
Mar 30, 2022
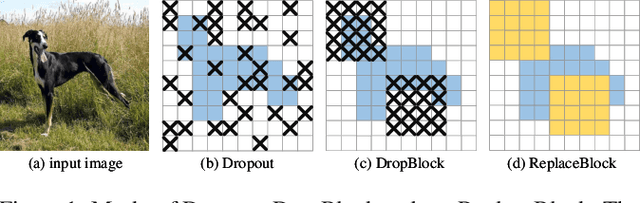
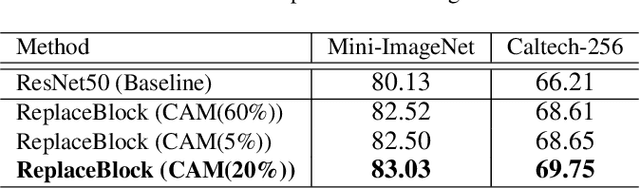
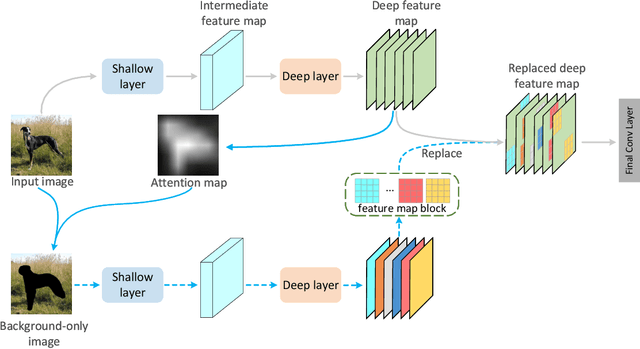
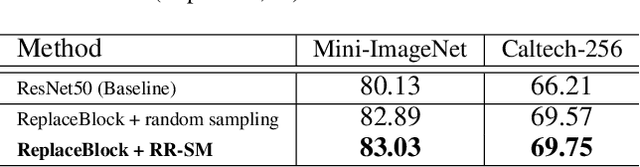
Attention mechanism, being frequently used to train networks for better feature representations, can effectively disentangle the target object from irrelevant objects in the background. Given an arbitrary image, we find that the background's irrelevant objects are most likely to occlude/block the target object. We propose, based on this finding, a ReplaceBlock to simulate the situations when the target object is partially occluded by the objects that are deemed as background. Specifically, ReplaceBlock erases the target object in the image, and then generates a feature map with only irrelevant objects and background by the model. Finally, some regions in the background feature map are used to replace some regions of the target object in the original image feature map. In this way, ReplaceBlock can effectively simulate the feature map of the occluded image. The experimental results show that ReplaceBlock works better than DropBlock in regularizing convolutional networks.
DCT2net: an interpretable shallow CNN for image denoising
Jul 31, 2021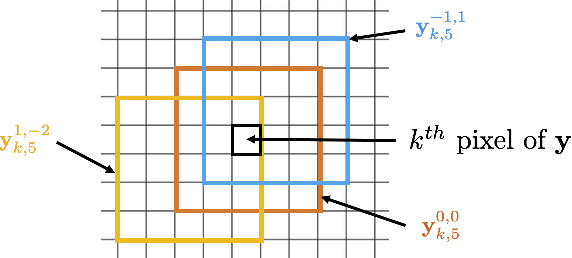


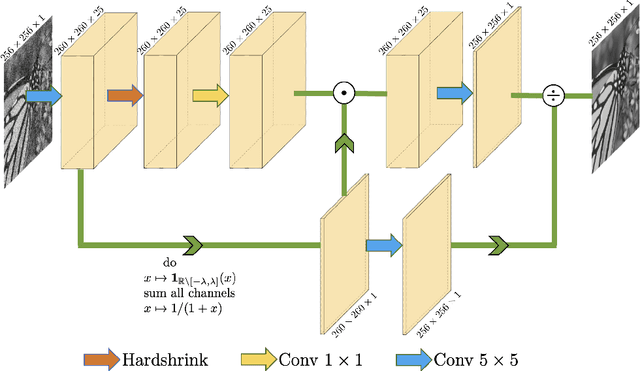
This work tackles the issue of noise removal from images, focusing on the well-known DCT image denoising algorithm. The latter, stemming from signal processing, has been well studied over the years. Though very simple, it is still used in crucial parts of state-of-the-art "traditional" denoising algorithms such as BM3D. Since a few years however, deep convolutional neural networks (CNN) have outperformed their traditional counterparts, making signal processing methods less attractive. In this paper, we demonstrate that a DCT denoiser can be seen as a shallow CNN and thereby its original linear transform can be tuned through gradient descent in a supervised manner, improving considerably its performance. This gives birth to a fully interpretable CNN called DCT2net. To deal with remaining artifacts induced by DCT2net, an original hybrid solution between DCT and DCT2net is proposed combining the best that these two methods can offer; DCT2net is selected to process non-stationary image patches while DCT is optimal for piecewise smooth patches. Experiments on artificially noisy images demonstrate that two-layer DCT2net provides comparable results to BM3D and is as fast as DnCNN algorithm composed of more than a dozen of layers.
Patch-Based Image Restoration using Expectation Propagation
Jun 18, 2021


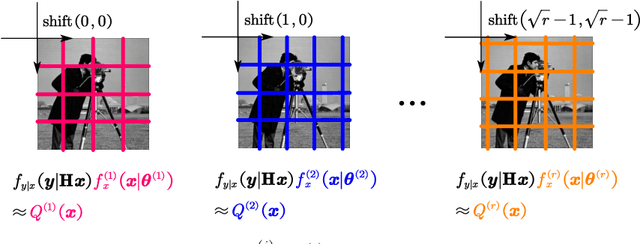
This paper presents a new Expectation Propagation (EP) framework for image restoration using patch-based prior distributions. While Monte Carlo techniques are classically used to sample from intractable posterior distributions, they can suffer from scalability issues in high-dimensional inference problems such as image restoration. To address this issue, EP is used here to approximate the posterior distributions using products of multivariate Gaussian densities. Moreover, imposing structural constraints on the covariance matrices of these densities allows for greater scalability and distributed computation. While the method is naturally suited to handle additive Gaussian observation noise, it can also be extended to non-Gaussian noise. Experiments conducted for denoising, inpainting and deconvolution problems with Gaussian and Poisson noise illustrate the potential benefits of such flexible approximate Bayesian method for uncertainty quantification in imaging problems, at a reduced computational cost compared to sampling techniques.
Diverse Image Inpainting with Bidirectional and Autoregressive Transformers
Apr 30, 2021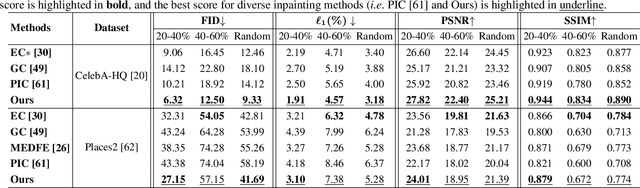
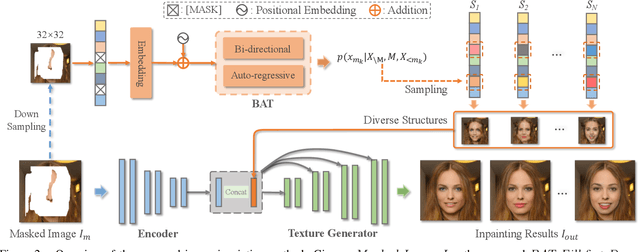
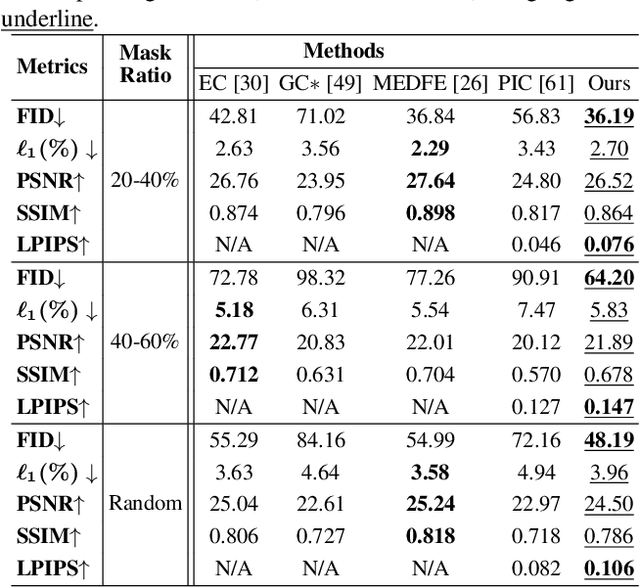
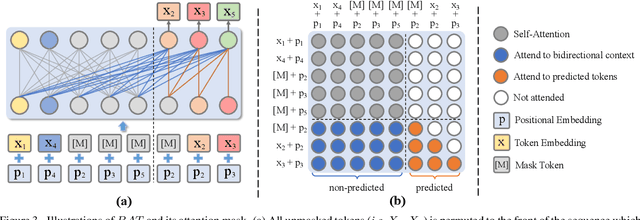
Image inpainting is an underdetermined inverse problem, it naturally allows diverse contents that fill up the missing or corrupted regions reasonably and realistically. Prevalent approaches using convolutional neural networks (CNNs) can synthesize visually pleasant contents, but CNNs suffer from limited perception fields for capturing global features. With image-level attention, transformers enable to model long-range dependencies and generate diverse contents with autoregressive modeling of pixel-sequence distributions. However, the unidirectional attention in transformers is suboptimal as corrupted regions can have arbitrary shapes with contexts from arbitrary directions. We propose BAT-Fill, an image inpainting framework with a novel bidirectional autoregressive transformer (BAT) that models deep bidirectional contexts for autoregressive generation of diverse inpainting contents. BAT-Fill inherits the merits of transformers and CNNs in a two-stage manner, which allows to generate high-resolution contents without being constrained by the quadratic complexity of attention in transformers. Specifically, it first generates pluralistic image structures of low resolution by adapting transformers and then synthesizes realistic texture details of high resolutions with a CNN-based up-sampling network. Extensive experiments over multiple datasets show that BAT-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.
CIDEr-R: Robust Consensus-based Image Description Evaluation
Sep 28, 2021
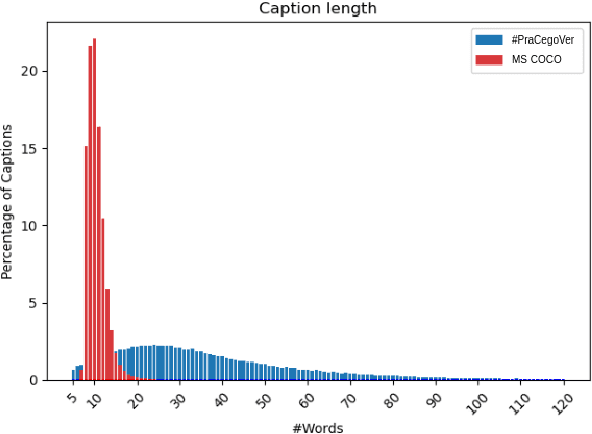
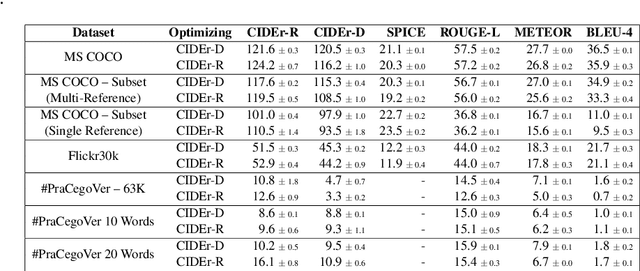
This paper shows that CIDEr-D, a traditional evaluation metric for image description, does not work properly on datasets where the number of words in the sentence is significantly greater than those in the MS COCO Captions dataset. We also show that CIDEr-D has performance hampered by the lack of multiple reference sentences and high variance of sentence length. To bypass this problem, we introduce CIDEr-R, which improves CIDEr-D, making it more flexible in dealing with datasets with high sentence length variance. We demonstrate that CIDEr-R is more accurate and closer to human judgment than CIDEr-D; CIDEr-R is more robust regarding the number of available references. Our results reveal that using Self-Critical Sequence Training to optimize CIDEr-R generates descriptive captions. In contrast, when CIDEr-D is optimized, the generated captions' length tends to be similar to the reference length. However, the models also repeat several times the same word to increase the sentence length.
From images in the wild to video-informed image classification
Sep 24, 2021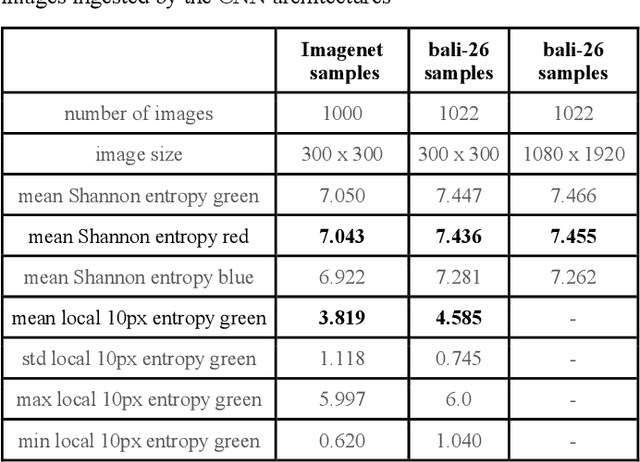



Image classifiers work effectively when applied on structured images, yet they often fail when applied on images with very high visual complexity. This paper describes experiments applying state-of-the-art object classifiers toward a unique set of images in the wild with high visual complexity collected on the island of Bali. The text describes differences between actual images in the wild and images from Imagenet, and then discusses a novel approach combining informational cues particular to video with an ensemble of imperfect classifiers in order to improve classification results on video sourced images of plants in the wild.
* 6 pages, 7 figures, supplemental materials
LeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation
Jul 19, 2021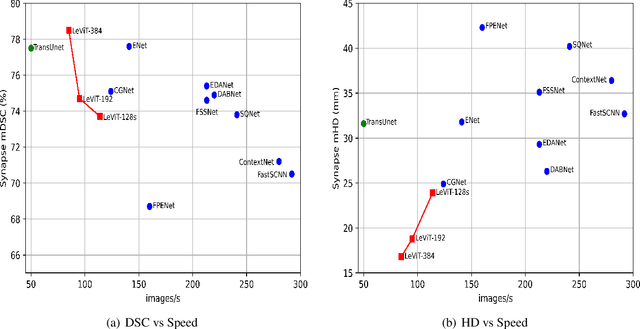
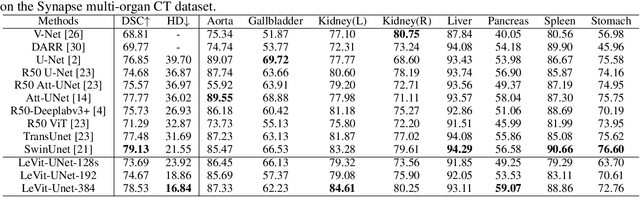
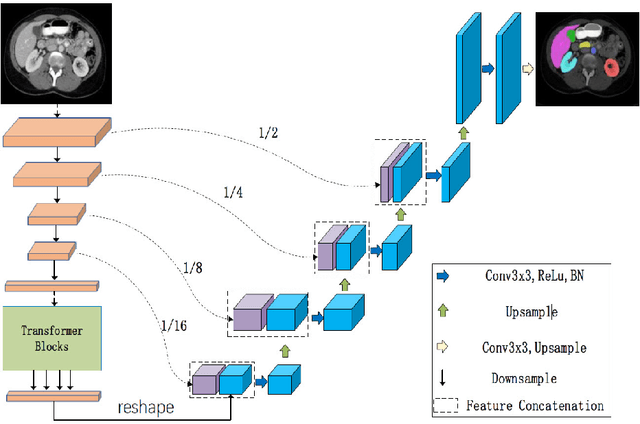
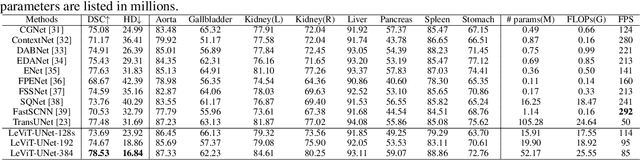
Medical image segmentation plays an essential role in developing computer-assisted diagnosis and therapy systems, yet still faces many challenges. In the past few years, the popular encoder-decoder architectures based on CNNs (e.g., U-Net) have been successfully applied in the task of medical image segmentation. However, due to the locality of convolution operations, they demonstrate limitations in learning global context and long-range spatial relations. Recently, several researchers try to introduce transformers to both the encoder and decoder components with promising results, but the efficiency requires further improvement due to the high computational complexity of transformers. In this paper, we propose LeViT-UNet, which integrates a LeViT Transformer module into the U-Net architecture, for fast and accurate medical image segmentation. Specifically, we use LeViT as the encoder of the LeViT-UNet, which better trades off the accuracy and efficiency of the Transformer block. Moreover, multi-scale feature maps from transformer blocks and convolutional blocks of LeViT are passed into the decoder via skip-connection, which can effectively reuse the spatial information of the feature maps. Our experiments indicate that the proposed LeViT-UNet achieves better performance comparing to various competing methods on several challenging medical image segmentation benchmarks including Synapse and ACDC. Code and models will be publicly available at https://github.com/apple1986/LeViT_UNet.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 01, 2021
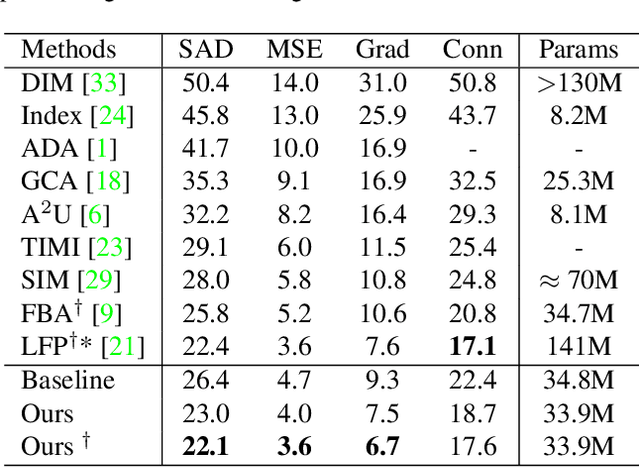
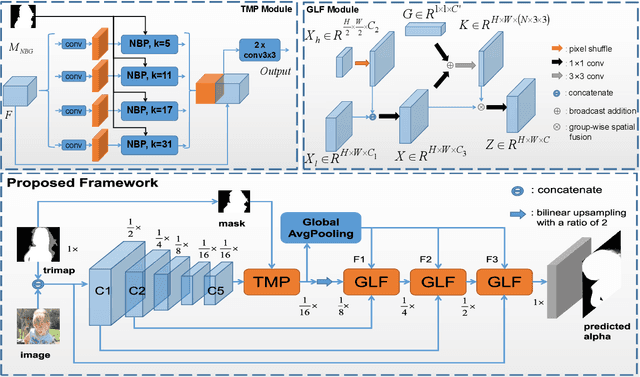
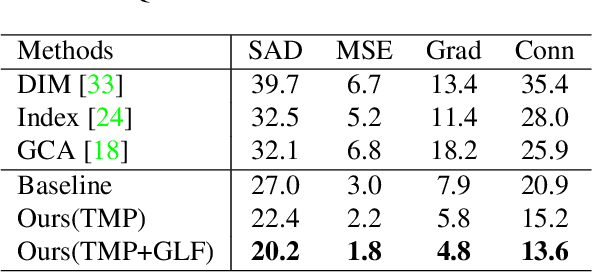
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
Machine Learning-based Biological Ageing Estimation Technologies: A Survey
Jun 25, 2022
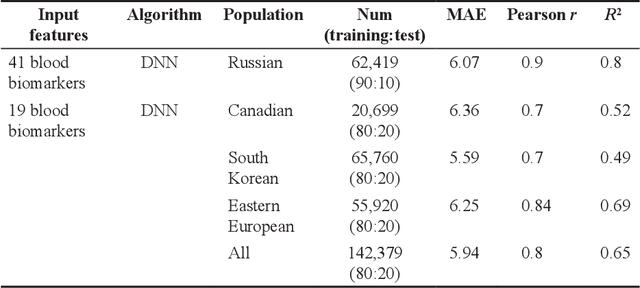
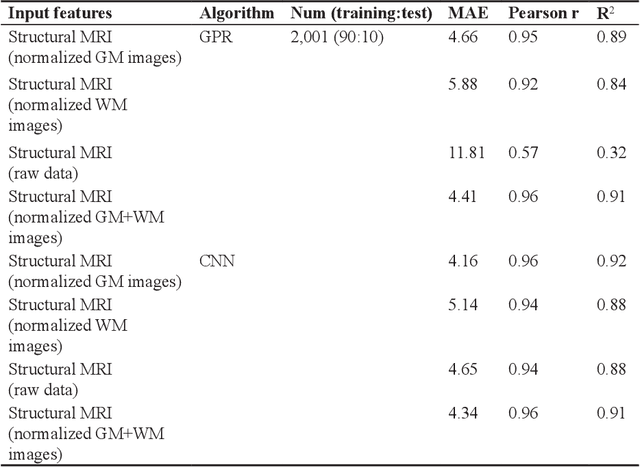
In recent years, there are various methods of estimating Biological Age (BA) have been developed. Especially with the development of machine learning (ML), there are more and more types of BA predictions, and the accuracy has been greatly improved. The models for the estimation of BA play an important role in monitoring healthy aging, and could provide new tools to detect health status in the general population and give warnings to sub-healthy people. We will mainly review three age prediction methods by using ML. They are based on blood biomarkers, facial images, and structural neuroimaging features. For now, the model using blood biomarkers is the simplest, most direct, and most accurate method. The face image method is affected by various aspects such as race, environment, etc., the prediction accuracy is not very good, which cannot make a great contribution to the medical field. In summary, we are here to track the way forward in the era of big data for us and other potential general populations and show ways to leverage the vast amounts of data available today.
* in Recent Advances in AI-enabled Automated Medical Diagnosis https://www.routledge.com/Recent-Advances-in-AI-enabled-Automated-Medical-Diagnosis/Jiang-Crookes-Wei-Zhang-Chazot/p/book/9781032008431
Coupling Model-Driven and Data-Driven Methods for Remote Sensing Image Restoration and Fusion
Aug 13, 2021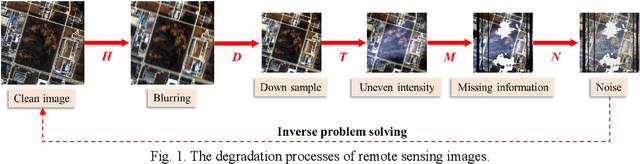
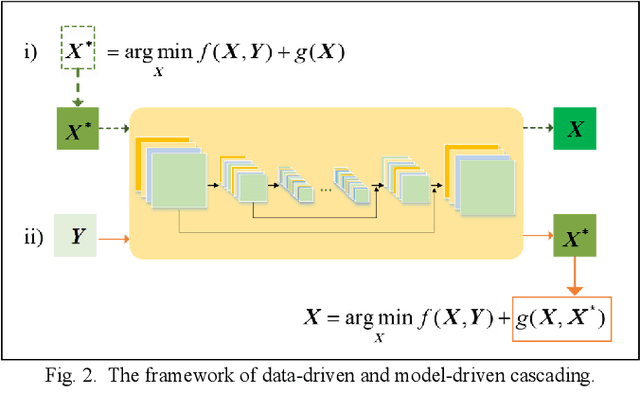
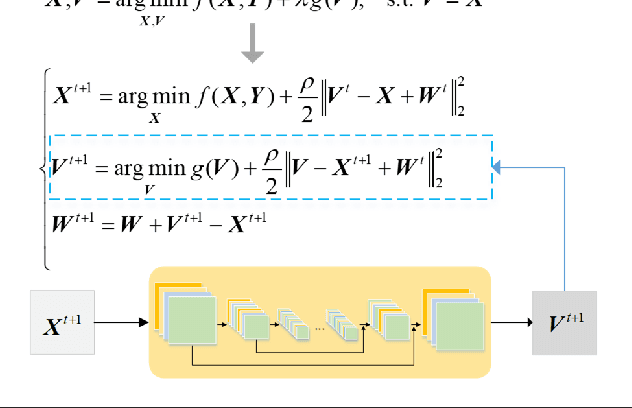
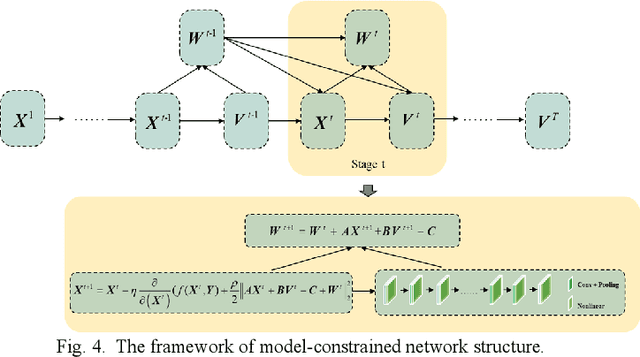
In the fields of image restoration and image fusion, model-driven methods and data-driven methods are the two representative frameworks. However, both approaches have their respective advantages and disadvantages. The model-driven methods consider the imaging mechanism, which is deterministic and theoretically reasonable; however, they cannot easily model complicated nonlinear problems. The data-driven methods have a stronger prior knowledge learning capability for huge data, especially for nonlinear statistical features; however, the interpretability of the networks is poor, and they are over-dependent on training data. In this paper, we systematically investigate the coupling of model-driven and data-driven methods, which has rarely been considered in the remote sensing image restoration and fusion communities. We are the first to summarize the coupling approaches into the following three categories: 1) data-driven and model-driven cascading methods; 2) variational models with embedded learning; and 3) model-constrained network learning methods. The typical existing and potential coupling methods for remote sensing image restoration and fusion are introduced with application examples. This paper also gives some new insights into the potential future directions, in terms of both methods and applications.