 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch Based Transformation for Minimum Variance Beamformer Image Approximation Using Delay and Sum Pipeline
Oct 19, 2021

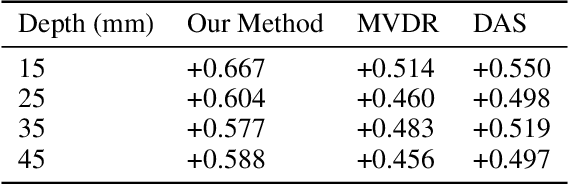
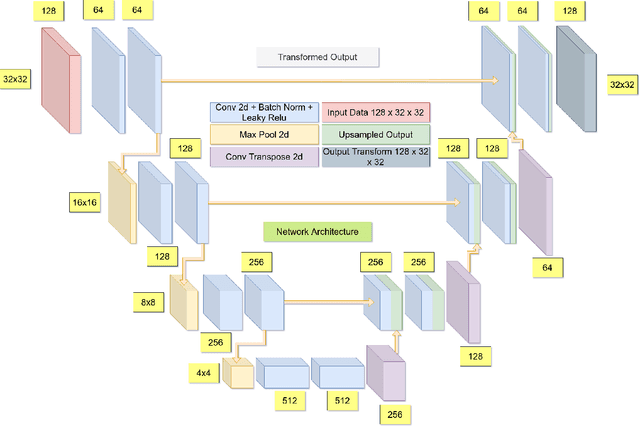
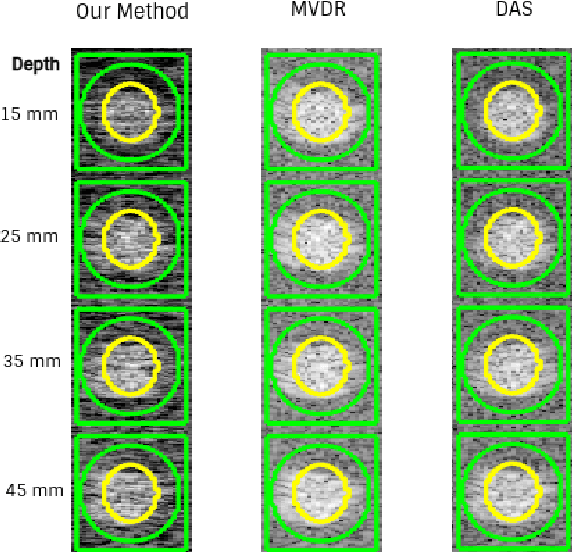
In the recent past, there have been several efforts in accelerating computationally heavy beamforming algorithms such as minimum variance distortionless response (MVDR) beamforming to achieve real-time performance comparable to the popular delay and sum (DAS) beamforming. This has been achieved using a variety of neural network architectures ranging from fully connected neural networks (FCNNs), convolutional neural networks (CNNs) and general adversarial networks (GANs). However most of these approaches are working with optimizations considering image level losses and hence require a significant amount of dataset to ensure that the process of beamforming is learned. In this work, a patch level U-Net based neural network is proposed, where the delay compensated radio frequency (RF) patch for a fixed region in space (e.g. 32x32) is transformed through a U-Net architecture and multiplied with DAS apodization weights and optimized for similarity with MVDR image of the patch. Instead of framing the beamforming problem as a regression problem to estimate the apodization weights, the proposed approach treats the non-linear transformation of the RF data space that can account for the data driven weight adaptation done by the MVDR approach in the parameters of the network. In this way, it is also observed that by restricting the input to a patch the model will learn the beamforming pipeline as an image non-linear transformation problem.
3D Clothed Human Reconstruction in the Wild
Jul 20, 2022
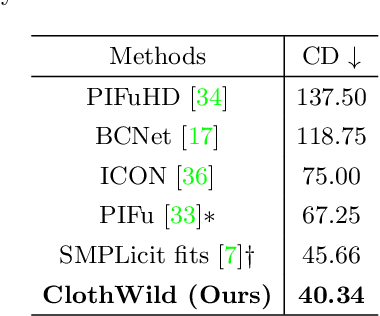
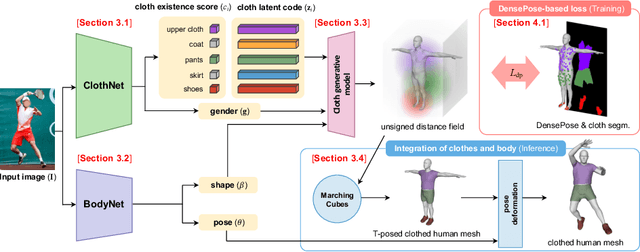
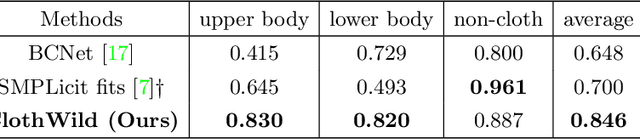
Although much progress has been made in 3D clothed human reconstruction, most of the existing methods fail to produce robust results from in-the-wild images, which contain diverse human poses and appearances. This is mainly due to the large domain gap between training datasets and in-the-wild datasets. The training datasets are usually synthetic ones, which contain rendered images from GT 3D scans. However, such datasets contain simple human poses and less natural image appearances compared to those of real in-the-wild datasets, which makes generalization of it to in-the-wild images extremely challenging. To resolve this issue, in this work, we propose ClothWild, a 3D clothed human reconstruction framework that firstly addresses the robustness on in-thewild images. First, for the robustness to the domain gap, we propose a weakly supervised pipeline that is trainable with 2D supervision targets of in-the-wild datasets. Second, we design a DensePose-based loss function to reduce ambiguities of the weak supervision. Extensive empirical tests on several public in-the-wild datasets demonstrate that our proposed ClothWild produces much more accurate and robust results than the state-of-the-art methods. The codes are available in here: https://github.com/hygenie1228/ClothWild_RELEASE.
An interpretation of the final fully connected layer
May 24, 2022
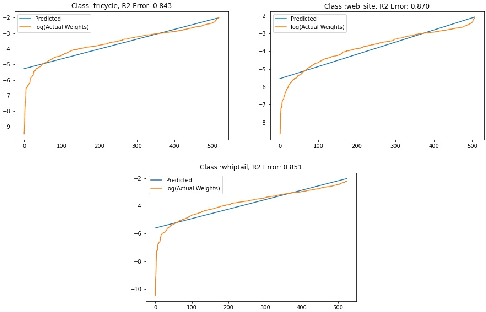
In recent years neural networks have achieved state-of-the-art accuracy for various tasks but the the interpretation of the generated outputs still remains difficult. In this work we attempt to provide a method to understand the learnt weights in the final fully connected layer in image classification models. We motivate our method by drawing a connection between the policy gradient objective in RL and supervised learning objective. We suggest that the commonly used cross entropy based supervised learning objective can be regarded as a special case of the policy gradient objective. Using this insight we propose a method to find the most discriminative and confusing parts of an image. Our method does not make any prior assumption about neural network achitecture and has low computational cost. We apply our method on publicly available pre-trained models and report the generated results.
The Importance of the Instantaneous Phase for classification using Convolutional Neural Networks
Jul 01, 2022



Large-scale training of Convolutional Neural Networks (CNN) is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. This work examines the impact of using AM-FM representations as input images for CNN classification applications. A comparison was made between AM-FM components combinations and grayscale images as inputs for reduced and complete networks. The results showed that only the phase component produced significant predictions within a simple network. Neither IA or gray scale image were able to induce any learning in the system. Furthermore, the FM results were 7x faster during training and used 123x less parameters compared to state-of-the-art MobileNetV2 architecture, while maintaining comparable performance (AUC of 0.78 vs 0.79).
InsetGAN for Full-Body Image Generation
Mar 14, 2022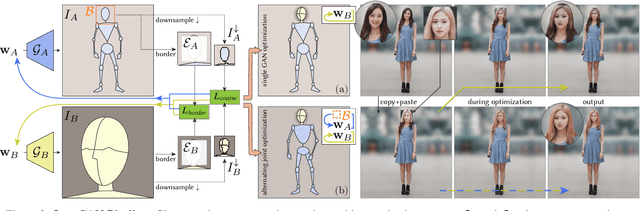



While GANs can produce photo-realistic images in ideal conditions for certain domains, the generation of full-body human images remains difficult due to the diversity of identities, hairstyles, clothing, and the variance in pose. Instead of modeling this complex domain with a single GAN, we propose a novel method to combine multiple pretrained GANs, where one GAN generates a global canvas (e.g., human body) and a set of specialized GANs, or insets, focus on different parts (e.g., faces, shoes) that can be seamlessly inserted onto the global canvas. We model the problem as jointly exploring the respective latent spaces such that the generated images can be combined, by inserting the parts from the specialized generators onto the global canvas, without introducing seams. We demonstrate the setup by combining a full body GAN with a dedicated high-quality face GAN to produce plausible-looking humans. We evaluate our results with quantitative metrics and user studies.
Three-dimensional Epanechnikov mixture regression in image coding
Jun 03, 2021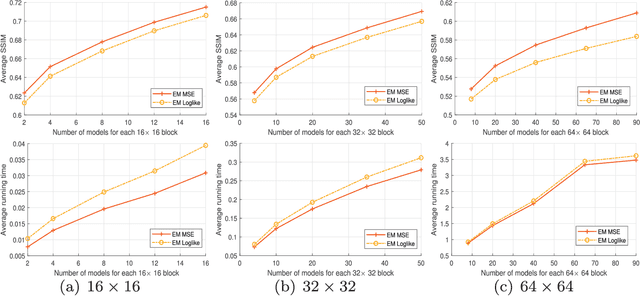

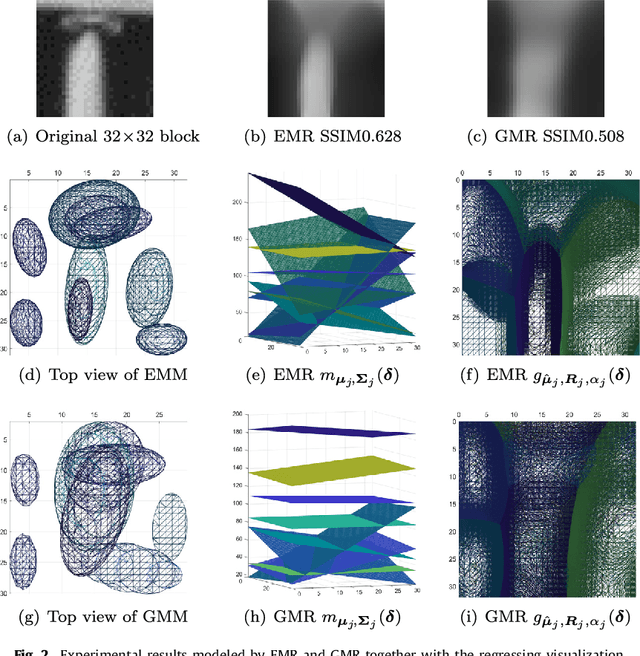
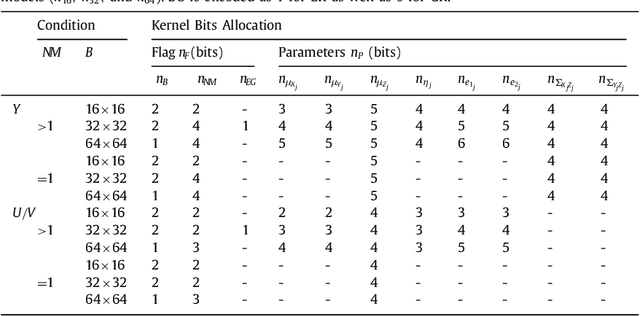
Kernel methods have been studied extensively in recent years. We propose a three-dimensional (3-D) Epanechnikov Mixture Regression (EMR) based on our Epanechnikov Kernel (EK) and realize a complete framework for image coding. In our research, we deduce the covariance-matrix form of 3-D Epanechnikov kernels and their correlated statistics to obtain the Epanechnikov mixture models. To apply our theories to image coding, we propose the 3-D EMR which can better model an image in smaller blocks compared with the conventional Gaussian Mixture Regression (GMR). The regressions are all based on our improved Expectation-Maximization (EM) algorithm with mean square error optimization. Finally, we design an Adaptive Mode Selection (AMS) algorithm to realize the best model pattern combination for coding. Our recovered image has clear outlines and superior coding efficiency compared to JPEG below 0.25bpp. Our work realizes an unprecedented theory application by: (1) enriching the theory of Epanechnikov kernel,(2) improving the EM algorithm using MSE optimization, (3) exploiting the EMR and its application in image coding, and (4) AMS optimal modeling combined with Gaussian and Epanechnikov kernel.
* 12 pages, 9 figures
Unsupervised Representation Learning for 3D MRI Super Resolution with Degradation Adaptation
May 13, 2022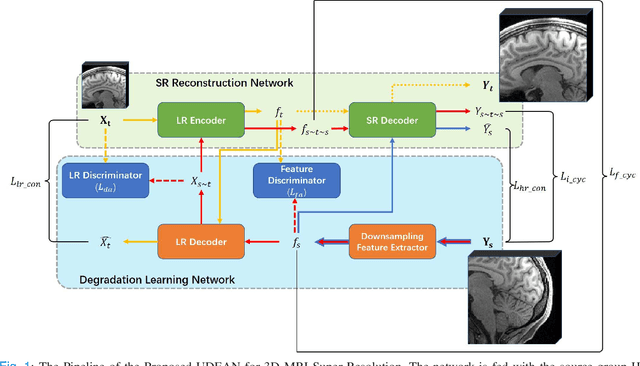
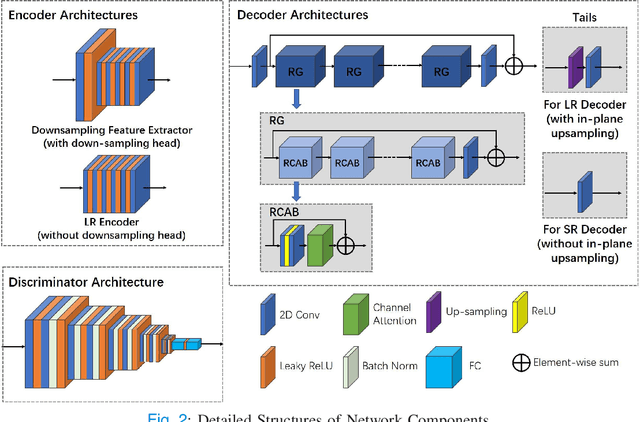
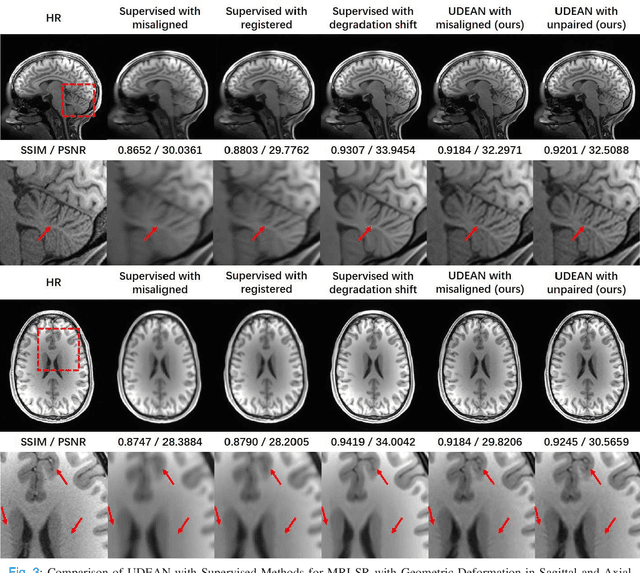
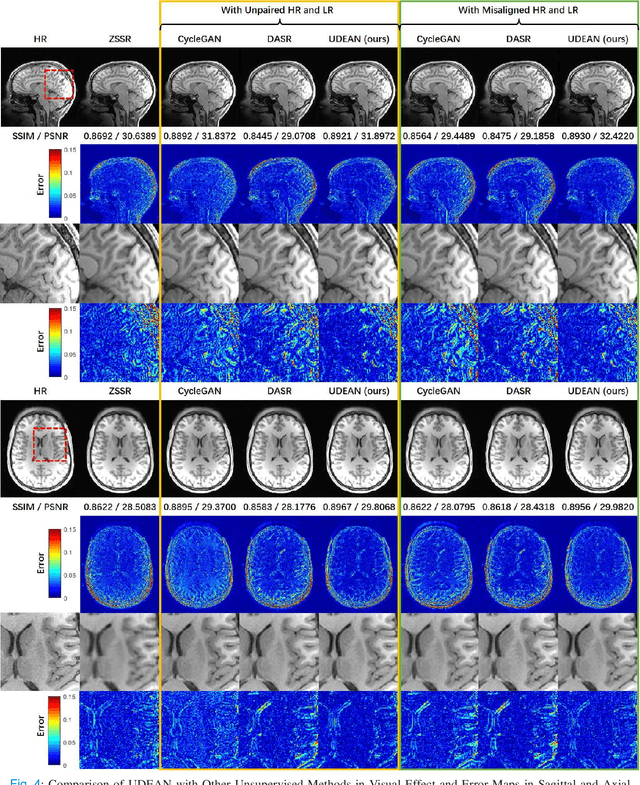
High-resolution (HR) MRI is critical in assisting the doctor's diagnosis and image-guided treatment, but is hard to obtain in a clinical setting due to long acquisition time. Therefore, the research community investigated deep learning-based super-resolution (SR) technology to reconstruct HR MRI images with shortened acquisition time. However, training such neural networks usually requires paired HR and low-resolution (LR) in-vivo images, which are difficult to acquire due to patient movement during and between the image acquisition. Rigid movements of hard tissues can be corrected with image-registration, whereas the alignment of deformed soft tissues is challenging, making it impractical to train the neural network with such authentic HR and LR image pairs. Therefore, most of the previous studies proposed SR reconstruction by employing authentic HR images and synthetic LR images downsampled from the HR images, yet the difference in degradation representations between synthetic and authentic LR images suppresses the performance of SR reconstruction from authentic LR images. To mitigate the aforementioned problems, we propose a novel Unsupervised DEgradation Adaptation Network (UDEAN). Our model consists of two components: the degradation learning network and the SR reconstruction network. The degradation learning network downsamples the HR images by addressing the degradation representation of the misaligned or unpaired LR images, and the SR reconstruction network learns the mapping from the downsampled HR images to their original HR images. As a result, the SR reconstruction network can generate SR images from the LR images and achieve comparable quality to the HR images. Experimental results show that our method outperforms the state-of-the-art models and can potentially be applied in real-world clinical settings.
Using Contrastive Learning and Pseudolabels to learn representations for Retail Product Image Classification
Oct 07, 2021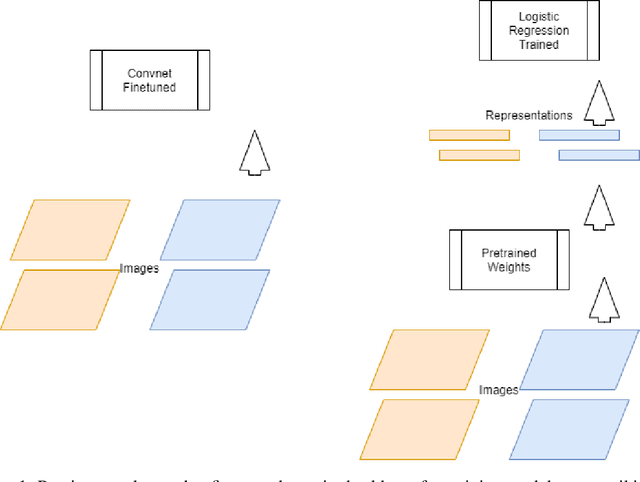



Retail product Image classification problems are often few shot classification problems, given retail product classes cannot have the type of variations across images like a cat or dog or tree could have. Previous works have shown different methods to finetune Convolutional Neural Networks to achieve better classification accuracy on such datasets. In this work, we try to address the problem statement : Can we pretrain a Convolutional Neural Network backbone which yields good enough representations for retail product images, so that training a simple logistic regression on these representations gives us good classifiers ? We use contrastive learning and pseudolabel based noisy student training to learn representations that get accuracy in order of finetuning the entire Convnet backbone for retail product image classification.
CLIP2Video: Mastering Video-Text Retrieval via Image CLIP
Jun 21, 2021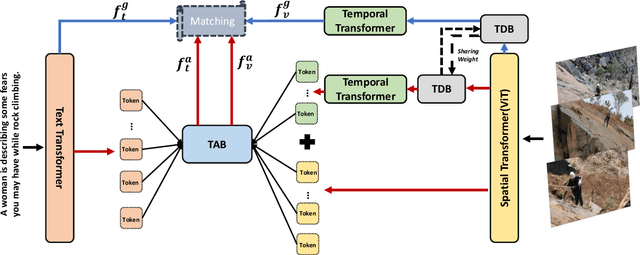
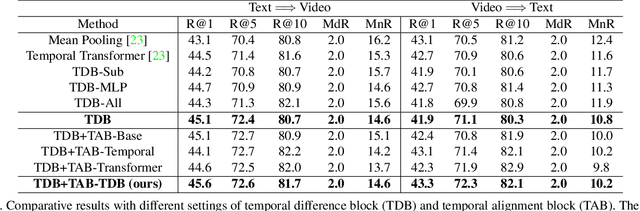
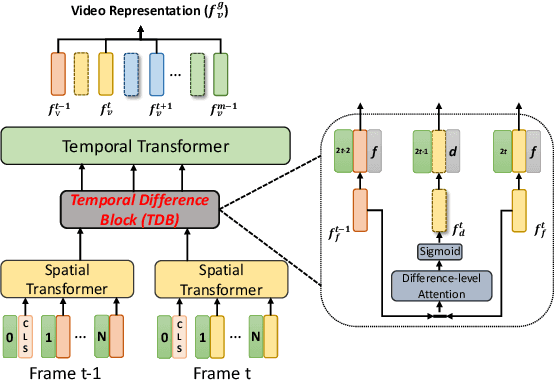
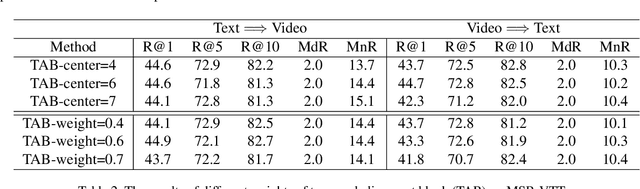
We present CLIP2Video network to transfer the image-language pre-training model to video-text retrieval in an end-to-end manner. Leading approaches in the domain of video-and-language learning try to distill the spatio-temporal video features and multi-modal interaction between videos and languages from a large-scale video-text dataset. Different from them, we leverage pretrained image-language model, simplify it as a two-stage framework with co-learning of image-text and enhancing temporal relations between video frames and video-text respectively, make it able to train on comparatively small datasets. Specifically, based on the spatial semantics captured by Contrastive Language-Image Pretraining (CLIP) model, our model involves a Temporal Difference Block to capture motions at fine temporal video frames, and a Temporal Alignment Block to re-align the tokens of video clips and phrases and enhance the multi-modal correlation. We conduct thorough ablation studies, and achieve state-of-the-art performance on major text-to-video and video-to-text retrieval benchmarks, including new records of retrieval accuracy on MSR-VTT, MSVD and VATEX.
Parallel Structure from Motion for UAV Images via Weighted Connected Dominating Set
Jun 23, 2022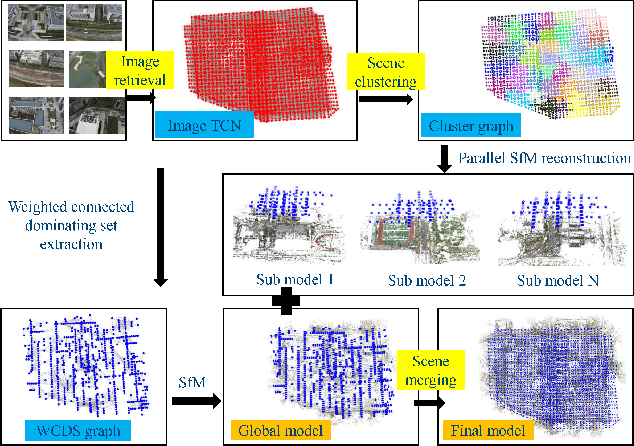

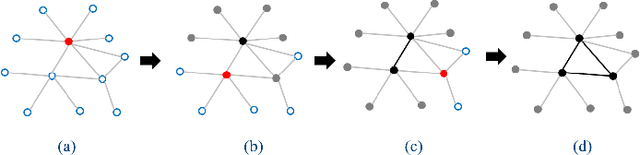
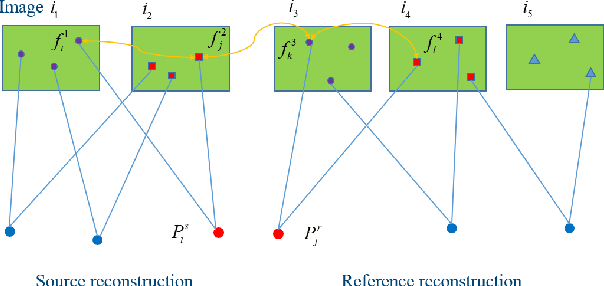
Incremental Structure from Motion (ISfM) has been widely used for UAV image orientation. Its efficiency, however, decreases dramatically due to the sequential constraint. Although the divide-and-conquer strategy has been utilized for efficiency improvement, cluster merging becomes difficult or depends on seriously designed overlap structures. This paper proposes an algorithm to extract the global model for cluster merging and designs a parallel SfM solution to achieve efficient and accurate UAV image orientation. First, based on vocabulary tree retrieval, match pairs are selected to construct an undirected weighted match graph, whose edge weights are calculated by considering both the number and distribution of feature matches. Second, an algorithm, termed weighted connected dominating set (WCDS), is designed to achieve the simplification of the match graph and build the global model, which incorporates the edge weight in the graph node selection and enables the successful reconstruction of the global model. Third, the match graph is simultaneously divided into compact and non-overlapped clusters. After the parallel reconstruction, cluster merging is conducted with the aid of common 3D points between the global and cluster models. Finally, by using three UAV datasets that are captured by classical oblique and recent optimized views photogrammetry, the validation of the proposed solution is verified through comprehensive analysis and comparison. The experimental results demonstrate that the proposed parallel SfM can achieve 17.4 times efficiency improvement and comparative orientation accuracy. In absolute BA, the geo-referencing accuracy is approximately 2.0 and 3.0 times the GSD (Ground Sampling Distance) value in the horizontal and vertical directions, respectively. For parallel SfM, the proposed solution is a more reliable alternative.