 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Partition Pooling for Convolutional Graph Network Applications in Particle Physics
Aug 11, 2022
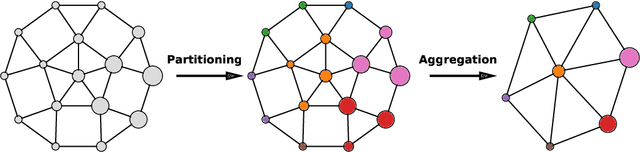
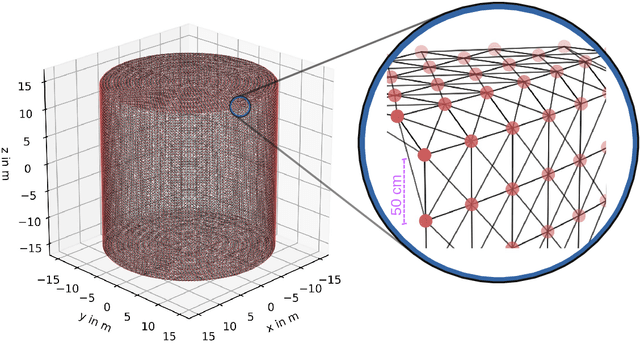
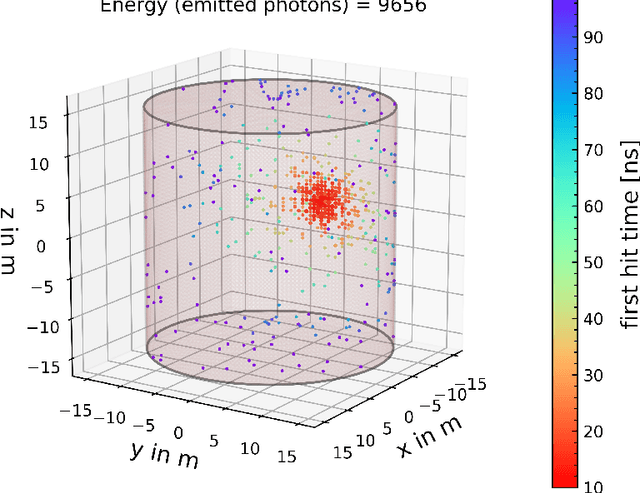
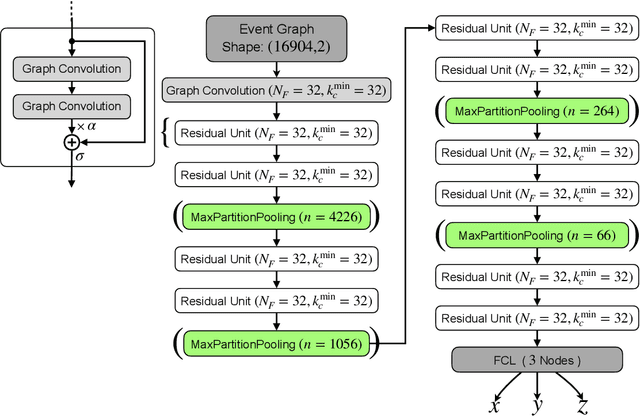
Convolutional graph networks are used in particle physics for effective event reconstructions and classifications. However, their performances can be limited by the considerable amount of sensors used in modern particle detectors if applied to sensor-level data. We present a pooling scheme that uses partitioning to create pooling kernels on graphs, similar to pooling on images. Partition pooling can be used to adopt successful image recognition architectures for graph neural network applications in particle physics. The reduced computational resources allow for deeper networks and more extensive hyperparameter optimizations. To show its applicability, we construct a convolutional graph network with partition pooling that reconstructs simulated interaction vertices for an idealized neutrino detector. The pooling network yields improved performance and is less susceptible to overfitting than a similar network without pooling. The lower resource requirements allow the construction of a deeper network with further improved performance.
Sparse to Dense Motion Transfer for Face Image Animation
Sep 03, 2021


Face image animation from a single image has achieved remarkable progress. However, it remains challenging when only sparse landmarks are available as the driving signal. Given a source face image and a sequence of sparse face landmarks, our goal is to generate a video of the face imitating the motion of landmarks. We develop an efficient and effective method for motion transfer from sparse landmarks to the face image. We then combine global and local motion estimation in a unified model to faithfully transfer the motion. The model can learn to segment the moving foreground from the background and generate not only global motion, such as rotation and translation of the face, but also subtle local motion such as the gaze change. We further improve face landmark detection on videos. With temporally better aligned landmark sequences for training, our method can generate temporally coherent videos with higher visual quality. Experiments suggest we achieve results comparable to the state-of-the-art image driven method on the same identity testing and better results on cross identity testing.
Leukocyte Classification using Multimodal Architecture Enhanced by Knowledge Distillation
Aug 17, 2022
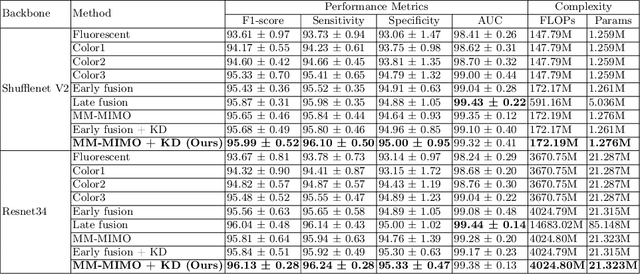
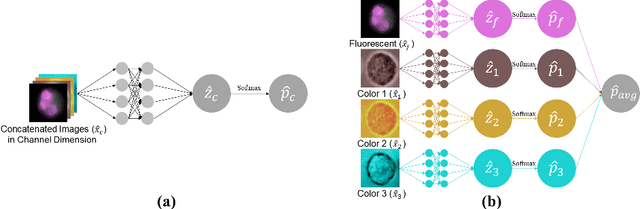
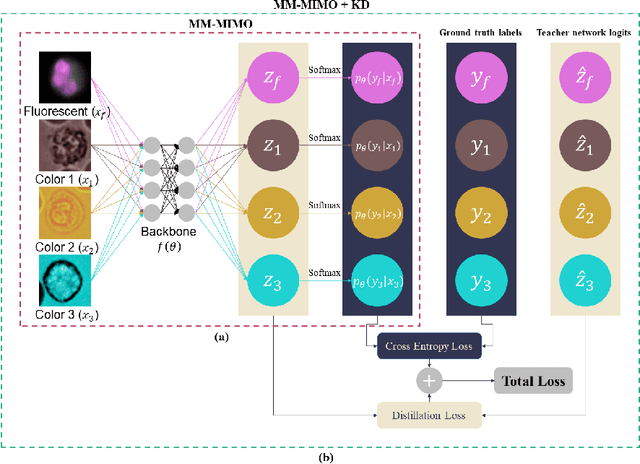
Recently, a lot of automated white blood cells (WBC) or leukocyte classification techniques have been developed. However, all of these methods only utilize a single modality microscopic image i.e. either blood smear or fluorescence based, thus missing the potential of a better learning from multimodal images. In this work, we develop an efficient multimodal architecture based on a first of its kind multimodal WBC dataset for the task of WBC classification. Specifically, our proposed idea is developed in two steps - 1) First, we learn modality specific independent subnetworks inside a single network only; 2) We further enhance the learning capability of the independent subnetworks by distilling knowledge from high complexity independent teacher networks. With this, our proposed framework can achieve a high performance while maintaining low complexity for a multimodal dataset. Our unique contribution is two-fold - 1) We present a first of its kind multimodal WBC dataset for WBC classification; 2) We develop a high performing multimodal architecture which is also efficient and low in complexity at the same time.
Jointly Harnessing Prior Structures and Temporal Consistency for Sign Language Video Generation
Jul 08, 2022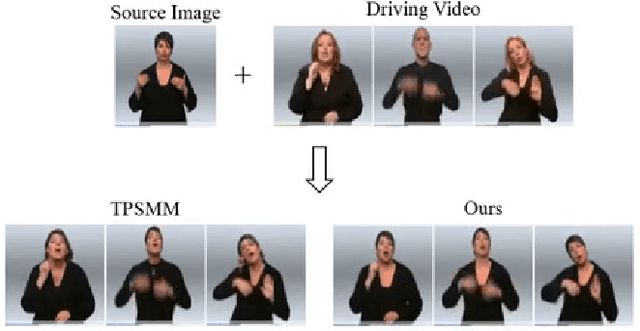
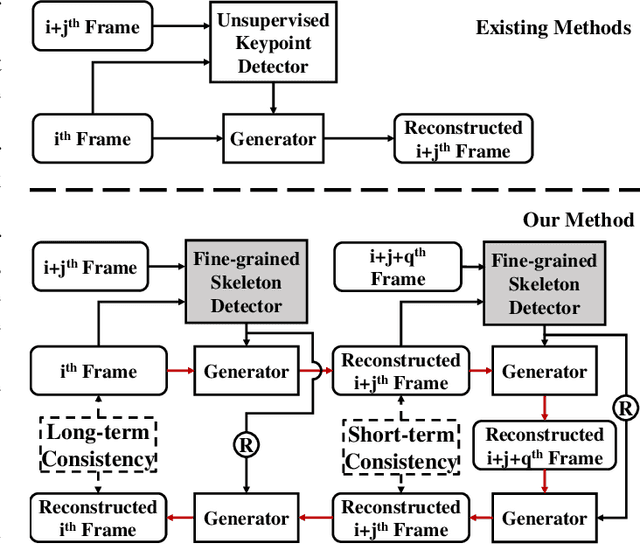
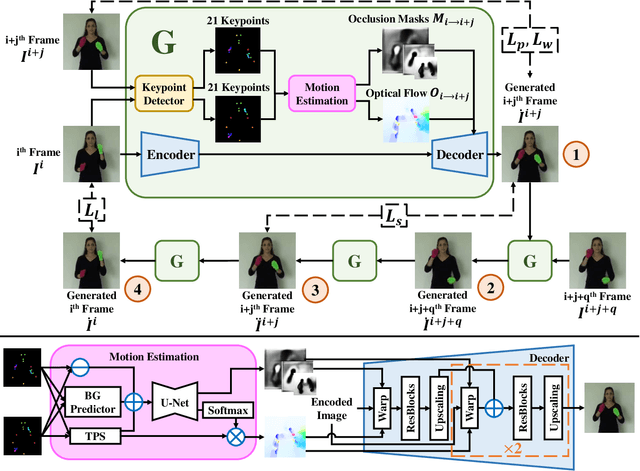

Sign language is the window for people differently-abled to express their feelings as well as emotions. However, it remains challenging for people to learn sign language in a short time. To address this real-world challenge, in this work, we study the motion transfer system, which can transfer the user photo to the sign language video of specific words. In particular, the appearance content of the output video comes from the provided user image, while the motion of the video is extracted from the specified tutorial video. We observe two primary limitations in adopting the state-of-the-art motion transfer methods to sign language generation:(1) Existing motion transfer works ignore the prior geometrical knowledge of the human body. (2) The previous image animation methods only take image pairs as input in the training stage, which could not fully exploit the temporal information within videos. In an attempt to address the above-mentioned limitations, we propose Structure-aware Temporal Consistency Network (STCNet) to jointly optimize the prior structure of human with the temporal consistency for sign language video generation. There are two main contributions in this paper. (1) We harness a fine-grained skeleton detector to provide prior knowledge of the body keypoints. In this way, we ensure the keypoint movement in a valid range and make the model become more explainable and robust. (2) We introduce two cycle-consistency losses, i.e., short-term cycle loss and long-term cycle loss, which are conducted to assure the continuity of the generated video. We optimize the two losses and keypoint detector network in an end-to-end manner.
On the Strong Correlation Between Model Invariance and Generalization
Jul 14, 2022

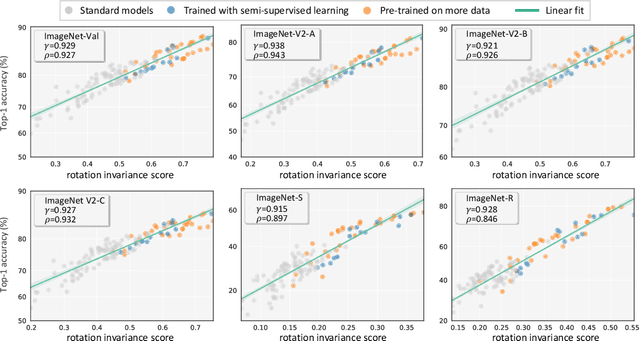
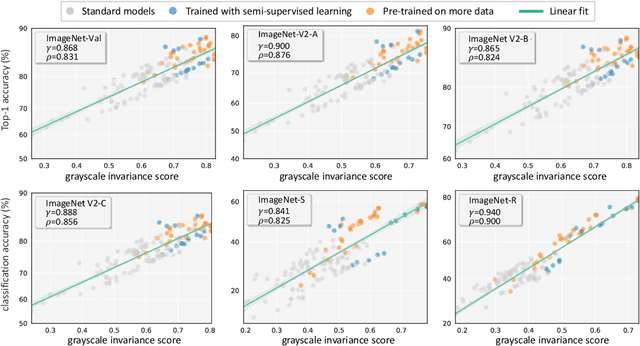
Generalization and invariance are two essential properties of any machine learning model. Generalization captures a model's ability to classify unseen data while invariance measures consistency of model predictions on transformations of the data. Existing research suggests a positive relationship: a model generalizing well should be invariant to certain visual factors. Building on this qualitative implication we make two contributions. First, we introduce effective invariance (EI), a simple and reasonable measure of model invariance which does not rely on image labels. Given predictions on a test image and its transformed version, EI measures how well the predictions agree and with what level of confidence. Second, using invariance scores computed by EI, we perform large-scale quantitative correlation studies between generalization and invariance, focusing on rotation and grayscale transformations. From a model-centric view, we observe generalization and invariance of different models exhibit a strong linear relationship, on both in-distribution and out-of-distribution datasets. From a dataset-centric view, we find a certain model's accuracy and invariance linearly correlated on different test sets. Apart from these major findings, other minor but interesting insights are also discussed.
Towards the Probabilistic Fusion of Learned Priors into Standard Pipelines for 3D Reconstruction
Jul 27, 2022
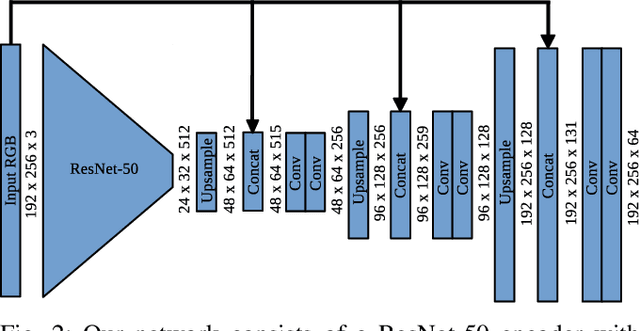
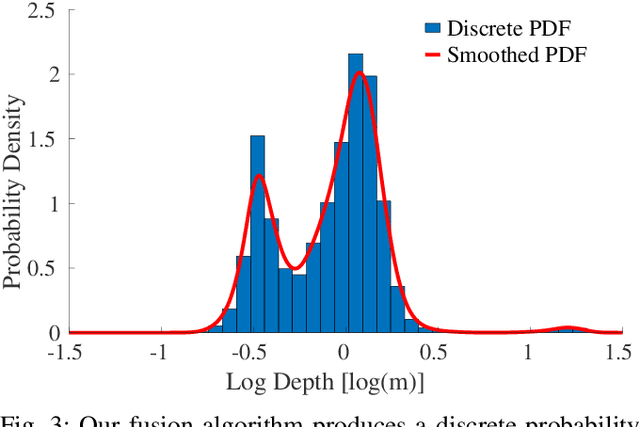

The best way to combine the results of deep learning with standard 3D reconstruction pipelines remains an open problem. While systems that pass the output of traditional multi-view stereo approaches to a network for regularisation or refinement currently seem to get the best results, it may be preferable to treat deep neural networks as separate components whose results can be probabilistically fused into geometry-based systems. Unfortunately, the error models required to do this type of fusion are not well understood, with many different approaches being put forward. Recently, a few systems have achieved good results by having their networks predict probability distributions rather than single values. We propose using this approach to fuse a learned single-view depth prior into a standard 3D reconstruction system. Our system is capable of incrementally producing dense depth maps for a set of keyframes. We train a deep neural network to predict discrete, nonparametric probability distributions for the depth of each pixel from a single image. We then fuse this "probability volume" with another probability volume based on the photometric consistency between subsequent frames and the keyframe image. We argue that combining the probability volumes from these two sources will result in a volume that is better conditioned. To extract depth maps from the volume, we minimise a cost function that includes a regularisation term based on network predicted surface normals and occlusion boundaries. Through a series of experiments, we demonstrate that each of these components improves the overall performance of the system.
ERNAS: An Evolutionary Neural Architecture Search for Magnetic Resonance Image Reconstructions
Jun 15, 2022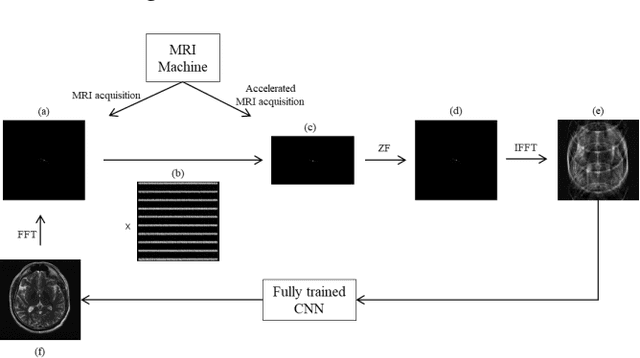

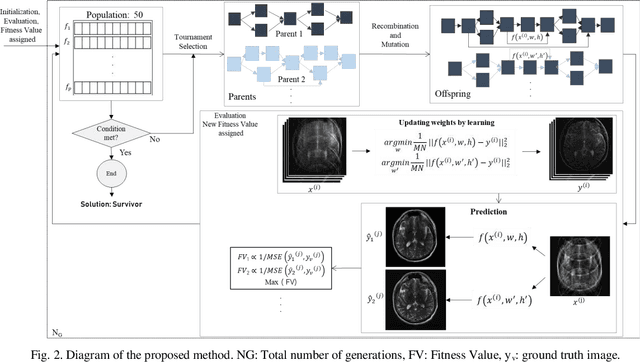
Magnetic resonance imaging (MRI) is one of the noninvasive imaging modalities that can produce high-quality images. However, the scan procedure is relatively slow, which causes patient discomfort and motion artifacts in images. Accelerating MRI hardware is constrained by physical and physiological limitations. A popular alternative approach to accelerated MRI is to undersample the k-space data. While undersampling speeds up the scan procedure, it generates artifacts in the images, and advanced reconstruction algorithms are needed to produce artifact-free images. Recently deep learning has emerged as a promising MRI reconstruction method to address this problem. However, straightforward adoption of the existing deep learning neural network architectures in MRI reconstructions is not usually optimal in terms of efficiency and reconstruction quality. In this work, MRI reconstruction from undersampled data was carried out using an optimized neural network using a novel evolutionary neural architecture search algorithm. Brain and knee MRI datasets show that the proposed algorithm outperforms manually designed neural network-based MR reconstruction models.
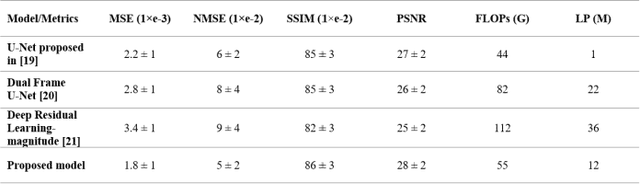
A Deep-Learning Framework for Improving COVID-19 CT Image Quality and Diagnostic Accuracy
Dec 16, 2021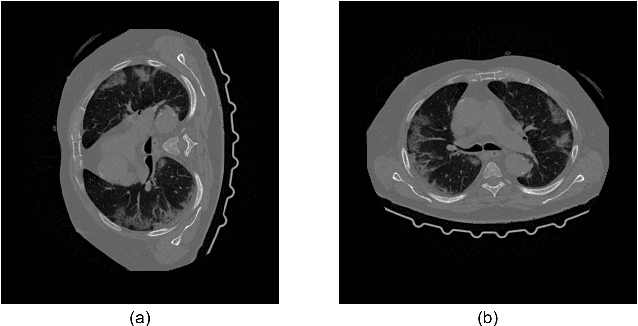
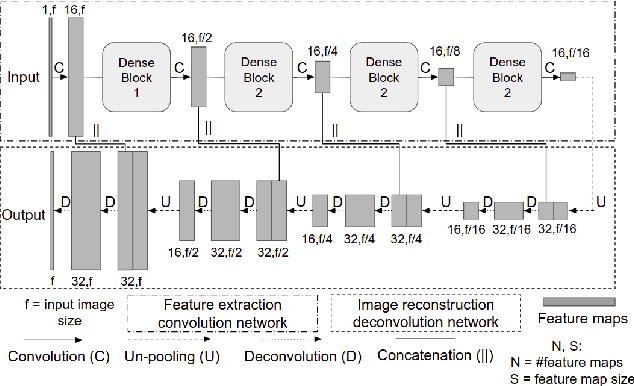
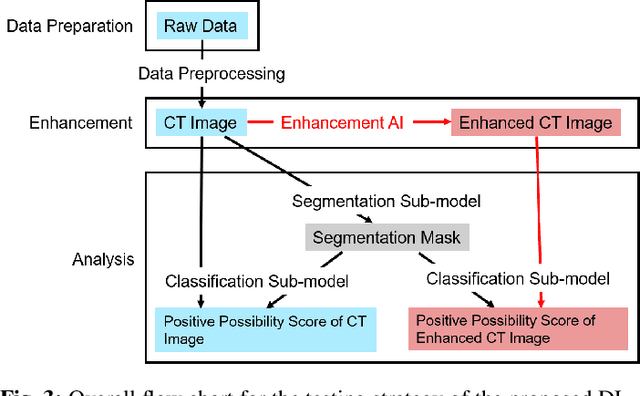
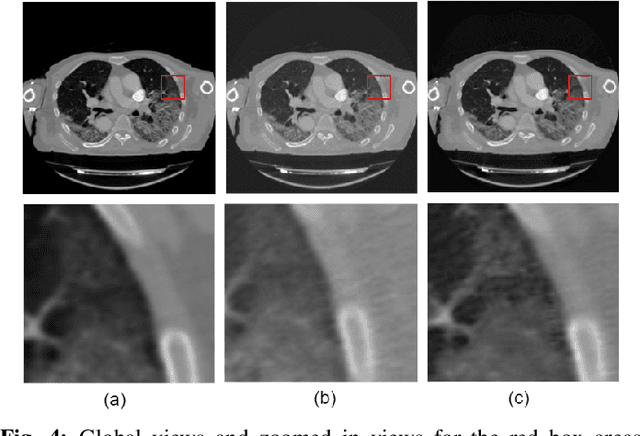
We present a deep-learning based computing framework for fast-and-accurate CT (DL-FACT) testing of COVID-19. Our CT-based DL framework was developed to improve the testing speed and accuracy of COVID-19 (plus its variants) via a DL-based approach for CT image enhancement and classification. The image enhancement network is adapted from DDnet, short for DenseNet and Deconvolution based network. To demonstrate its speed and accuracy, we evaluated DL-FACT across several sources of COVID-19 CT images. Our results show that DL-FACT can significantly shorten the turnaround time from days to minutes and improve the COVID-19 testing accuracy up to 91%. DL-FACT could be used as a software tool for medical professionals in diagnosing and monitoring COVID-19.
Image-based Automatic Dial Meter Reading in Unconstrained Scenarios
Jan 08, 2022

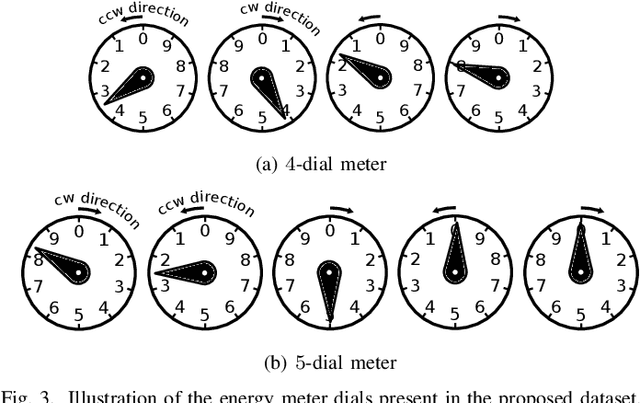
The replacement of analog meters with smart meters is costly, laborious, and far from complete in developing countries. The Energy Company of Parana (Copel) (Brazil) performs more than 4 million meter readings (almost entirely of non-smart devices) per month, and we estimate that 850 thousand of them are from dial meters. Therefore, an image-based automatic reading system can reduce human errors, create a proof of reading, and enable the customers to perform the reading themselves through a mobile application. We propose novel approaches for Automatic Dial Meter Reading (ADMR) and introduce a new dataset for ADMR in unconstrained scenarios, called UFPR-ADMR-v2. Our best-performing method combines YOLOv4 with a novel regression approach (AngReg), and explores several postprocessing techniques. Compared to previous works, it decreased the Mean Absolute Error (MAE) from 1,343 to 129 and achieved a meter recognition rate (MRR) of 98.90% -- with an error tolerance of 1 Kilowatt-hour (kWh).
A Novel Algorithm for Exact Concave Hull Extraction
Jun 23, 2022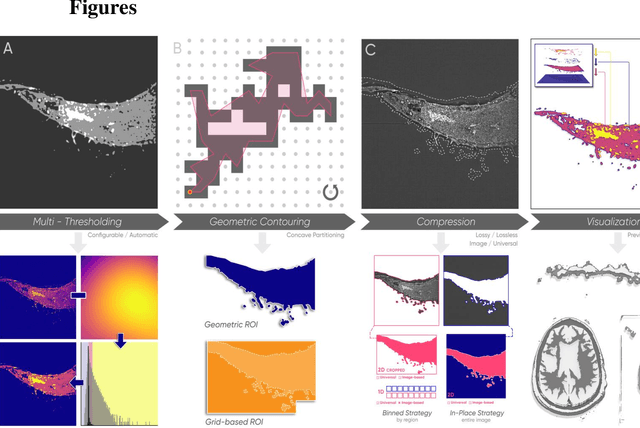

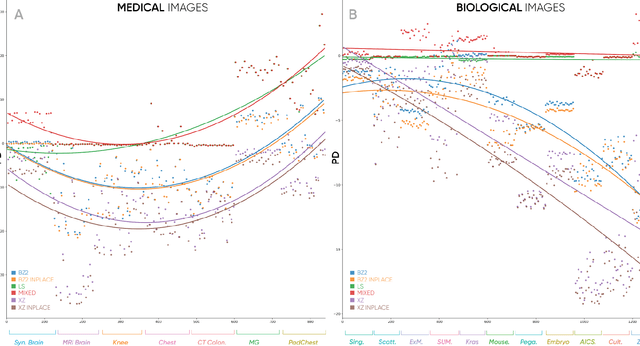
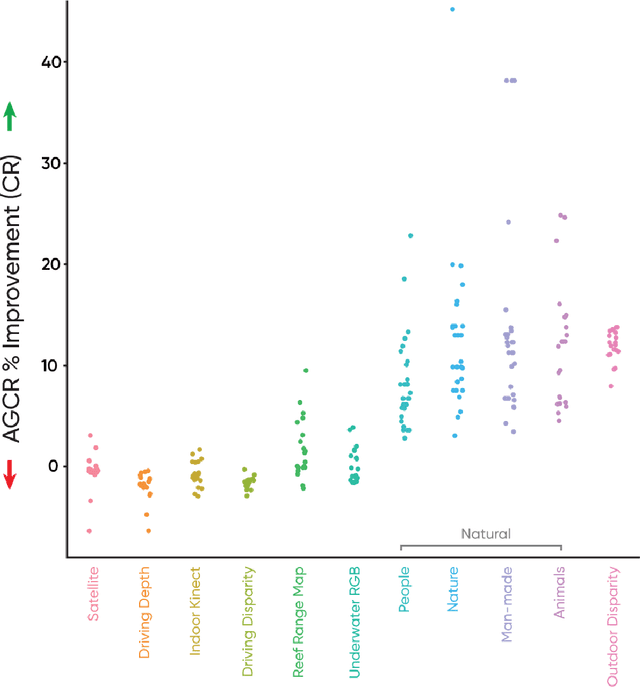
Region extraction is necessary in a wide range of applications, from object detection in autonomous driving to analysis of subcellular morphology in cell biology. There exist two main approaches: convex hull extraction, for which exact and efficient algorithms exist and concave hulls, which are better at capturing real-world shapes but do not have a single solution. Especially in the context of a uniform grid, concave hull algorithms are largely approximate, sacrificing region integrity for spatial and temporal efficiency. In this study, we present a novel algorithm that can provide vertex-minimized concave hulls with maximal (i.e. pixel-perfect) resolution and is tunable for speed-efficiency tradeoffs. Our method provides advantages in multiple downstream applications including data compression, retrieval, visualization, and analysis. To demonstrate the practical utility of our approach, we focus on image compression. We demonstrate significant improvements through context-dependent compression on disparate regions within a single image (entropy encoding for noisy and predictive encoding for the structured regions). We show that these improvements range from biomedical images to natural images. Beyond image compression, our algorithm can be applied more broadly to aid in a wide range of practical applications for data retrieval, visualization, and analysis.