 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Is GPT-3 all you need for Visual Question Answering in Cultural Heritage?
Jul 25, 2022

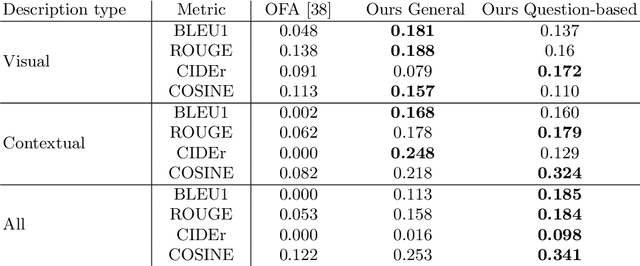

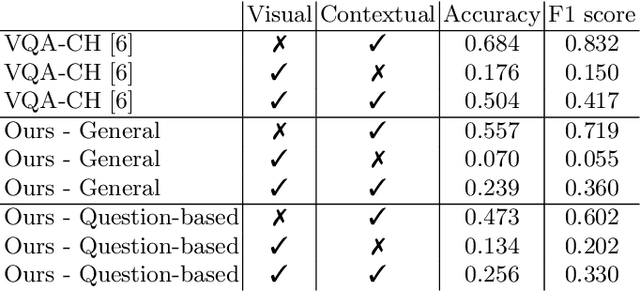
The use of Deep Learning and Computer Vision in the Cultural Heritage domain is becoming highly relevant in the last few years with lots of applications about audio smart guides, interactive museums and augmented reality. All these technologies require lots of data to work effectively and be useful for the user. In the context of artworks, such data is annotated by experts in an expensive and time consuming process. In particular, for each artwork, an image of the artwork and a description sheet have to be collected in order to perform common tasks like Visual Question Answering. In this paper we propose a method for Visual Question Answering that allows to generate at runtime a description sheet that can be used for answering both visual and contextual questions about the artwork, avoiding completely the image and the annotation process. For this purpose, we investigate on the use of GPT-3 for generating descriptions for artworks analyzing the quality of generated descriptions through captioning metrics. Finally we evaluate the performance for Visual Question Answering and captioning tasks.
Multi-Contrast MRI Segmentation Trained on Synthetic Images
Jul 06, 2022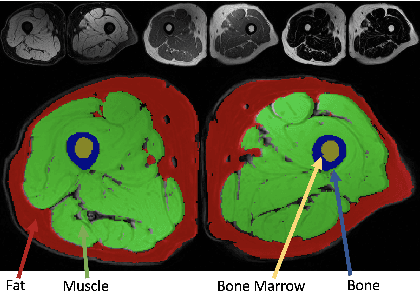
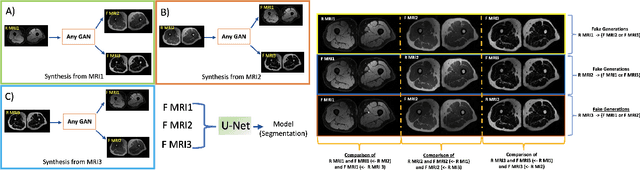
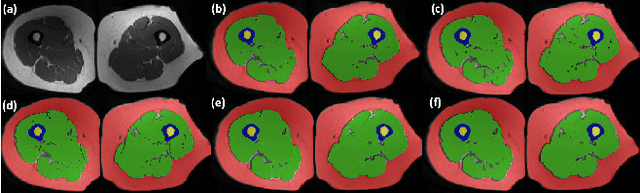
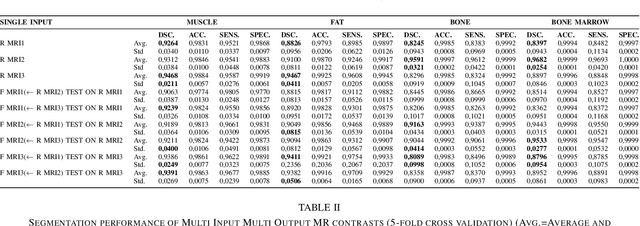
In our comprehensive experiments and evaluations, we show that it is possible to generate multiple contrast (even all synthetically) and use synthetically generated images to train an image segmentation engine. We showed promising segmentation results tested on real multi-contrast MRI scans when delineating muscle, fat, bone and bone marrow, all trained on synthetic images. Based on synthetic image training, our segmentation results were as high as 93.91\%, 94.11\%, 91.63\%, 95.33\%, for muscle, fat, bone, and bone marrow delineation, respectively. Results were not significantly different from the ones obtained when real images were used for segmentation training: 94.68\%, 94.67\%, 95.91\%, and 96.82\%, respectively.
ZeroMesh: Zero-shot Single-view 3D Mesh Reconstruction
Aug 04, 2022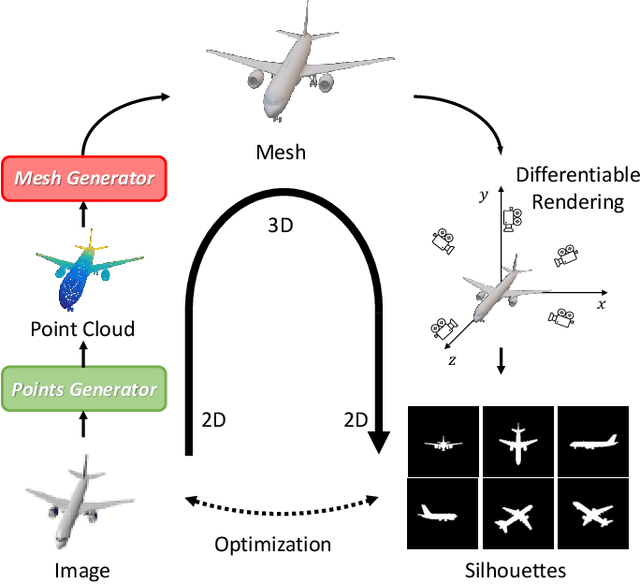
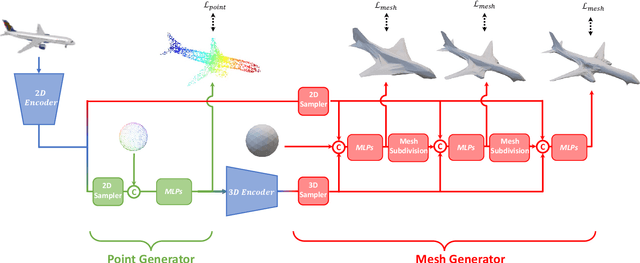
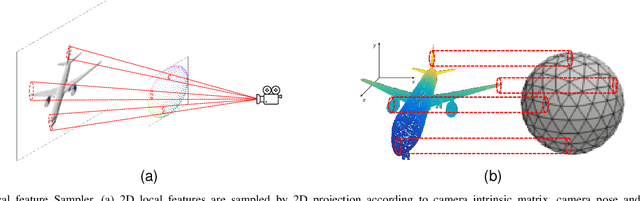
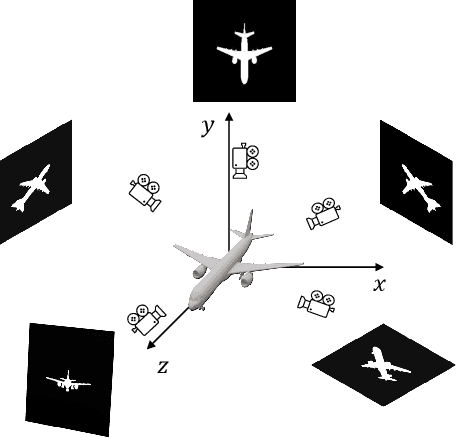
Single-view 3D object reconstruction is a fundamental and challenging computer vision task that aims at recovering 3D shapes from single-view RGB images. Most existing deep learning based reconstruction methods are trained and evaluated on the same categories, and they cannot work well when handling objects from novel categories that are not seen during training. Focusing on this issue, this paper tackles Zero-shot Single-view 3D Mesh Reconstruction, to study the model generalization on unseen categories and encourage models to reconstruct objects literally. Specifically, we propose an end-to-end two-stage network, ZeroMesh, to break the category boundaries in reconstruction. Firstly, we factorize the complicated image-to-mesh mapping into two simpler mappings, i.e., image-to-point mapping and point-to-mesh mapping, while the latter is mainly a geometric problem and less dependent on object categories. Secondly, we devise a local feature sampling strategy in 2D and 3D feature spaces to capture the local geometry shared across objects to enhance model generalization. Thirdly, apart from the traditional point-to-point supervision, we introduce a multi-view silhouette loss to supervise the surface generation process, which provides additional regularization and further relieves the overfitting problem. The experimental results show that our method significantly outperforms the existing works on the ShapeNet and Pix3D under different scenarios and various metrics, especially for novel objects.
Adversarial Style Augmentation for Domain Generalized Urban-Scene Segmentation
Jul 11, 2022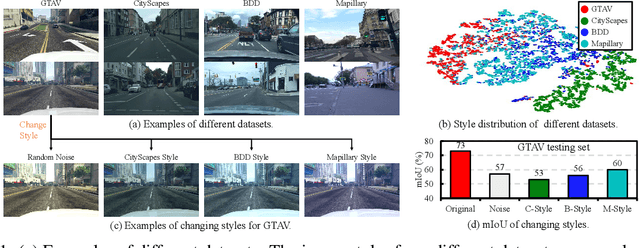
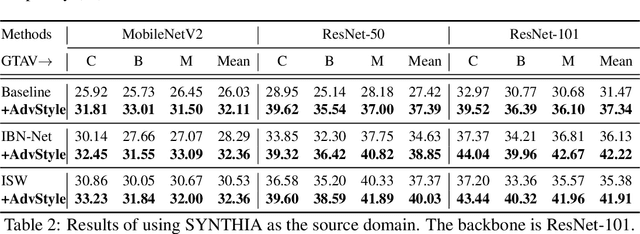

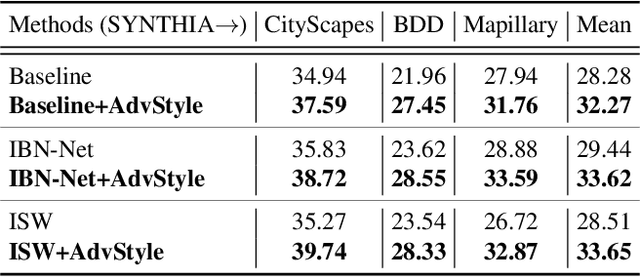
In this paper, we consider the problem of domain generalization in semantic segmentation, which aims to learn a robust model using only labeled synthetic (source) data. The model is expected to perform well on unseen real (target) domains. Our study finds that the image style variation can largely influence the model's performance and the style features can be well represented by the channel-wise mean and standard deviation of images. Inspired by this, we propose a novel adversarial style augmentation (AdvStyle) approach, which can dynamically generate hard stylized images during training and thus can effectively prevent the model from overfitting on the source domain. Specifically, AdvStyle regards the style feature as a learnable parameter and updates it by adversarial training. The learned adversarial style feature is used to construct an adversarial image for robust model training. AdvStyle is easy to implement and can be readily applied to different models. Experiments on two synthetic-to-real semantic segmentation benchmarks demonstrate that AdvStyle can significantly improve the model performance on unseen real domains and show that we can achieve the state of the art. Moreover, AdvStyle can be employed to domain generalized image classification and produces a clear improvement on the considered datasets.
Synthesizing Photorealistic Virtual Humans Through Cross-modal Disentanglement
Sep 03, 2022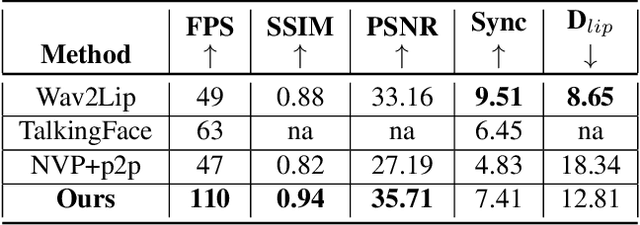
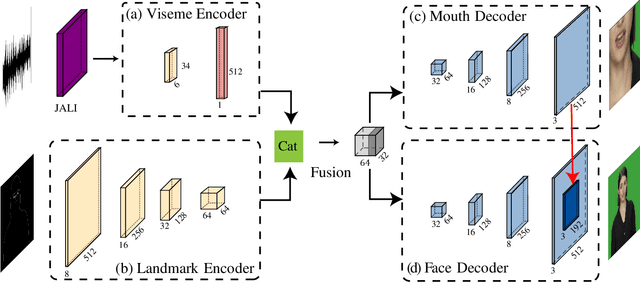
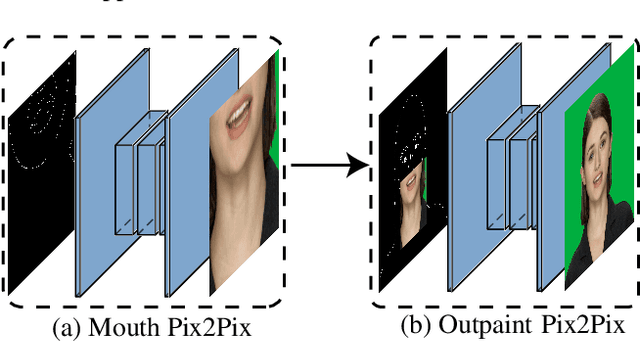
Over the last few decades, many aspects of human life have been enhanced with virtual domains, from the advent of digital assistants such as Amazon's Alexa and Apple's Siri to the latest metaverse efforts of the rebranded Meta. These trends underscore the importance of generating photorealistic visual depictions of humans. This has led to the rapid growth of so-called deepfake and talking head generation methods in recent years. Despite their impressive results and popularity, they usually lack certain qualitative aspects such as texture quality, lips synchronization, or resolution, and practical aspects such as the ability to run in real-time. To allow for virtual human avatars to be used in practical scenarios, we propose an end-to-end framework for synthesizing high-quality virtual human faces capable of speech with a special emphasis on performance. We introduce a novel network utilizing visemes as an intermediate audio representation and a novel data augmentation strategy employing a hierarchical image synthesis approach that allows disentanglement of the different modalities used to control the global head motion. Our method runs in real-time, and is able to deliver superior results compared to the current state-of-the-art.
Deep Neural Network Approximation of Invariant Functions through Dynamical Systems
Aug 18, 2022
We study the approximation of functions which are invariant with respect to certain permutations of the input indices using flow maps of dynamical systems. Such invariant functions includes the much studied translation-invariant ones involving image tasks, but also encompasses many permutation-invariant functions that finds emerging applications in science and engineering. We prove sufficient conditions for universal approximation of these functions by a controlled equivariant dynamical system, which can be viewed as a general abstraction of deep residual networks with symmetry constraints. These results not only imply the universal approximation for a variety of commonly employed neural network architectures for symmetric function approximation, but also guide the design of architectures with approximation guarantees for applications involving new symmetry requirements.
Semi-Supervised Medical Image Segmentation via Cross Teaching between CNN and Transformer
Dec 09, 2021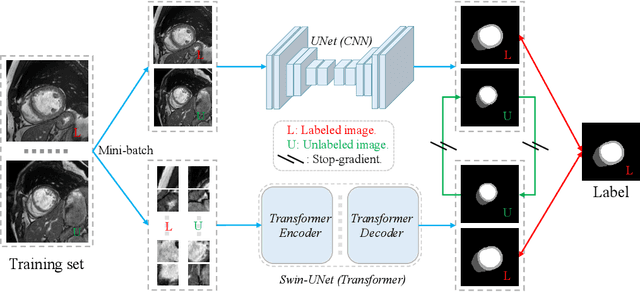
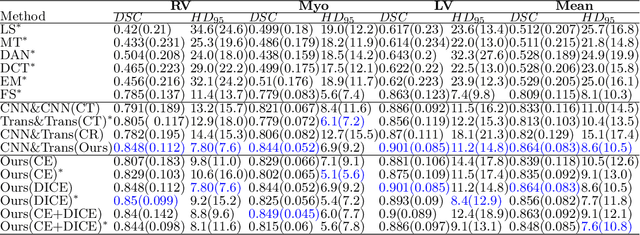

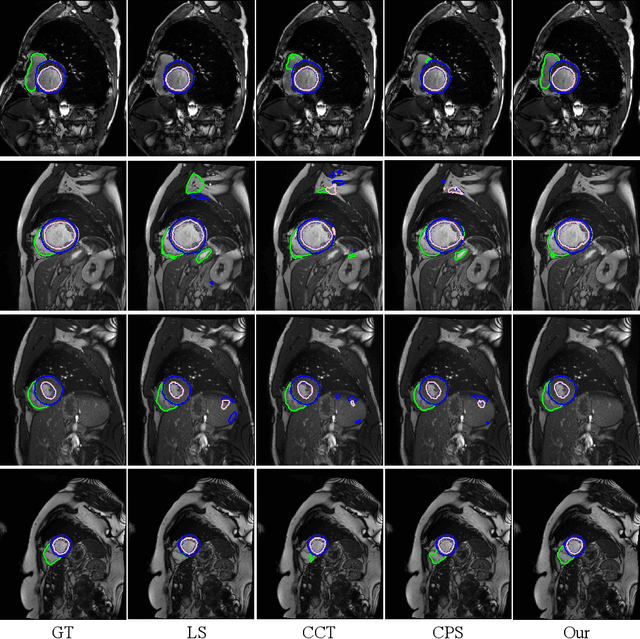
Recently, deep learning with Convolutional Neural Networks (CNNs) and Transformers has shown encouraging results in fully supervised medical image segmentation. However, it is still challenging for them to achieve good performance with limited annotations for training. In this work, we present a very simple yet efficient framework for semi-supervised medical image segmentation by introducing the cross teaching between CNN and Transformer. Specifically, we simplify the classical deep co-training from consistency regularization to cross teaching, where the prediction of a network is used as the pseudo label to supervise the other network directly end-to-end. Considering the difference in learning paradigm between CNN and Transformer, we introduce the Cross Teaching between CNN and Transformer rather than just using CNNs. Experiments on a public benchmark show that our method outperforms eight existing semi-supervised learning methods just with a simpler framework. Notably, this work may be the first attempt to combine CNN and transformer for semi-supervised medical image segmentation and achieve promising results on a public benchmark. The code will be released at: https://github.com/HiLab-git/SSL4MIS.
Towards Intelligent Millimeter and Terahertz Communication for 6G: Computer Vision-aided Beamforming
Sep 06, 2022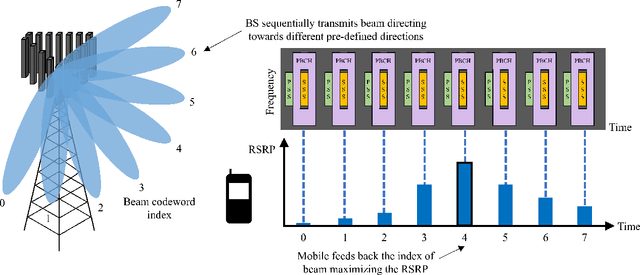
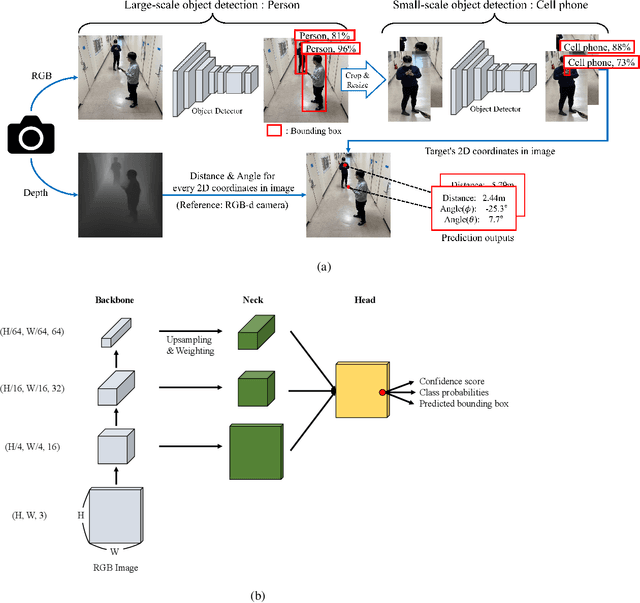
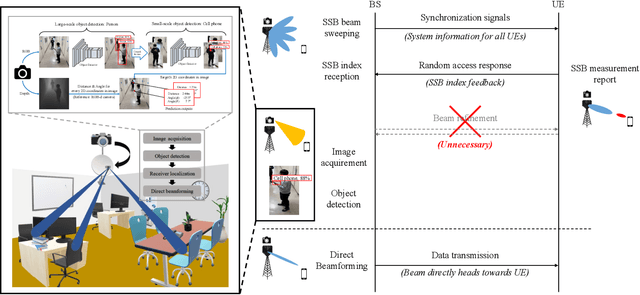

Beamforming technique realized by the multiple-input-multiple-output (MIMO) antenna arrays has been widely used to compensate for the severe path loss in the millimeter wave (mmWave) bands. In 5G NR system, the beam sweeping and beam refinement are employed to find out the best beam codeword aligned to the mobile. Due to the complicated handshaking and finite resolution of the codebook, today's 5G-based beam management strategy is ineffective in various scenarios in terms of the data rate, energy consumption, and also processing latency. An aim of this article is to introduce a new type of beam management framework based on the computer vision (CV) technique. In this framework referred to as computer vision-aided beam management (CVBM), a camera attached to the BS captures the image and then the deep learning-based object detector identifies the 3D location of the mobile. Since the base station can directly set the beam direction without codebook quantization and feedback delay, CVBM achieves the significant beamforming gain and latency reduction. Using the specially designed dataset called Vision Objects for Beam Management (VOBEM), we demonstrate that CVBM achieves more than 40% improvement in the beamforming gain and 40% reduction in the beam training overhead over the 5G NR beam management.
Effectiveness of Function Matching in Driving Scene Recognition
Aug 20, 2022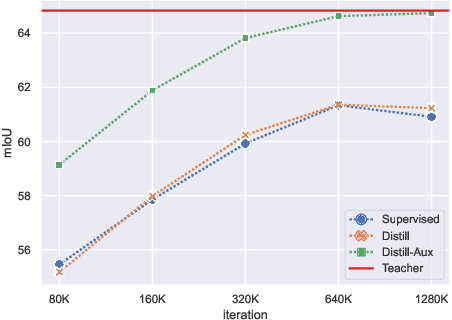
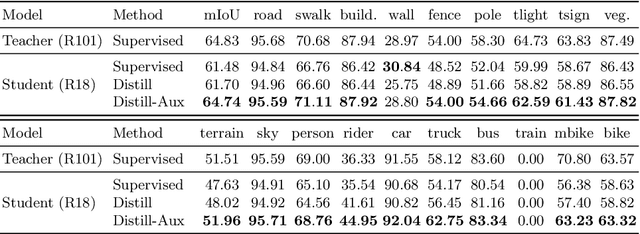
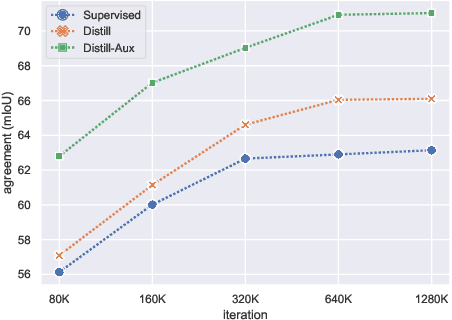
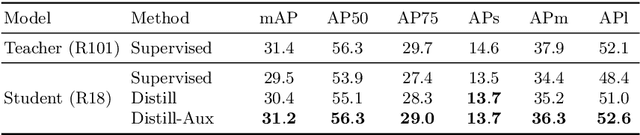
Knowledge distillation is an effective approach for training compact recognizers required in autonomous driving. Recent studies on image classification have shown that matching student and teacher on a wide range of data points is critical for improving performance in distillation. This concept (called function matching) is suitable for driving scene recognition, where generally an almost infinite amount of unlabeled data are available. In this study, we experimentally investigate the impact of using such a large amount of unlabeled data for distillation on the performance of student models in structured prediction tasks for autonomous driving. Through extensive experiments, we demonstrate that the performance of the compact student model can be improved dramatically and even match the performance of the large-scale teacher by knowledge distillation with massive unlabeled data.
An End-to-End OCR Framework for Robust Arabic-Handwriting Recognition using a Novel Transformers-based Model and an Innovative 270 Million-Words Multi-Font Corpus of Classical Arabic with Diacritics
Aug 26, 2022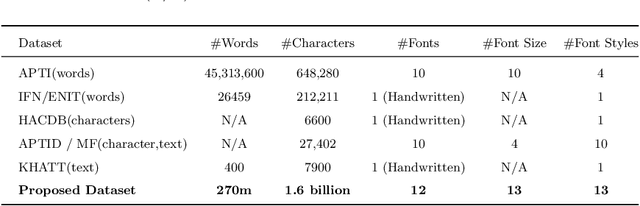

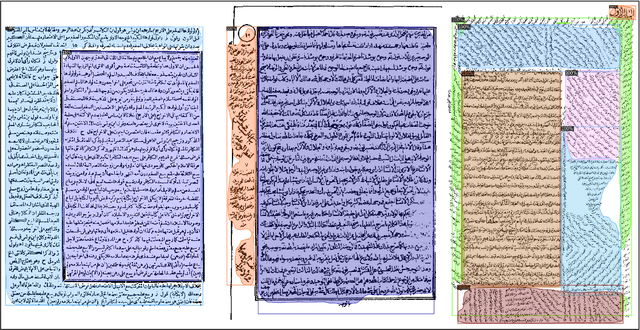
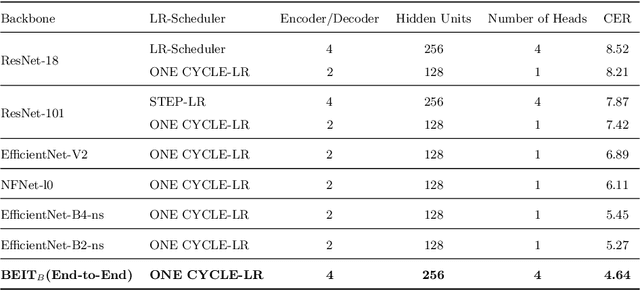
This research is the second phase in a series of investigations on developing an Optical Character Recognition (OCR) of Arabic historical documents and examining how different modeling procedures interact with the problem. The first research studied the effect of Transformers on our custom-built Arabic dataset. One of the downsides of the first research was the size of the training data, a mere 15000 images from our 30 million images, due to lack of resources. Also, we add an image enhancement layer, time and space optimization, and Post-Correction layer to aid the model in predicting the correct word for the correct context. Notably, we propose an end-to-end text recognition approach using Vision Transformers as an encoder, namely BEIT, and vanilla Transformer as a decoder, eliminating CNNs for feature extraction and reducing the model's complexity. The experiments show that our end-to-end model outperforms Convolutions Backbones. The model attained a CER of 4.46%.