 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-aided Parametric Sparse Channel Estimation for Terahertz Massive MIMO Systems
May 12, 2024Terahertz (THz) communications is considered as one of key solutions to support extremely high data demand in 6G. One main difficulty of the THz communication is the severe signal attenuation caused by the foliage loss, oxygen/atmospheric absorption, body and hand losses. To compensate for the severe path loss, multiple-input-multiple-output (MIMO) antenna array-based beamforming has been widely used. Since the beams should be aligned with the signal propagation path to achieve the maximum beamforming gain, acquisition of accurate channel knowledge, i.e., channel estimation, is of great importance. An aim of this paper is to propose a new type of deep learning (DL)-based parametric channel estimation technique. In our work, DL figures out the mapping function between the received pilot signal and the sparse channel parameters characterizing the spherical domain channel. By exploiting the long short-term memory (LSTM), we can efficiently extract the temporally correlated features of sparse channel parameters and thus make an accurate estimation with relatively small pilot overhead. From the numerical experiments, we show that the proposed scheme is effective in estimating the near-field THz MIMO channel in THz downlink environments.
Role of Sensing and Computer Vision in 6G Wireless Communications
May 07, 2024Recently, we are witnessing the remarkable progress and widespread adoption of sensing technologies in autonomous driving, robotics, and metaverse. Considering the rapid advancement of computer vision (CV) technology to analyze the sensing information, we anticipate a proliferation of wireless applications exploiting the sensing and CV technologies in 6G. In this article, we provide a holistic overview of the sensing and CV-aided wireless communications (SVWC) framework for 6G. By analyzing the high-resolution sensing information through the powerful CV techniques, SVWC can quickly and accurately understand the wireless environments and then perform the wireless tasks. To demonstrate the efficacy of SVWC, we design the whole process of SVWC including the sensing dataset collection, DL model training, and execution of realistic wireless tasks. From the numerical evaluations on 6G communication scenarios, we show that SVWC achieves considerable performance gains over the conventional 5G systems in terms of positioning accuracy, data rate, and access latency.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Enhanced Facet Generation with LLM Editing
Mar 25, 2024In information retrieval, facet identification of a user query is an important task. If a search service can recognize the facets of a user's query, it has the potential to offer users a much broader range of search results. Previous studies can enhance facet prediction by leveraging retrieved documents and related queries obtained through a search engine. However, there are challenges in extending it to other applications when a search engine operates as part of the model. First, search engines are constantly updated. Therefore, additional information may change during training and test, which may reduce performance. The second challenge is that public search engines cannot search for internal documents. Therefore, a separate search system needs to be built to incorporate documents from private domains within the company. We propose two strategies that focus on a framework that can predict facets by taking only queries as input without a search engine. The first strategy is multi-task learning to predict SERP. By leveraging SERP as a target instead of a source, the proposed model deeply understands queries without relying on external modules. The second strategy is to enhance the facets by combining Large Language Model (LLM) and the small model. Overall performance improves when small model and LLM are combined rather than facet generation individually.
Towards Intelligent Millimeter and Terahertz Communication for 6G: Computer Vision-aided Beamforming
Sep 06, 2022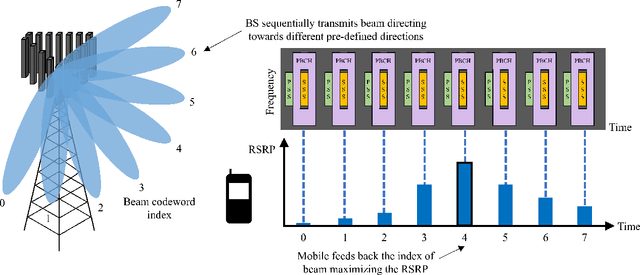
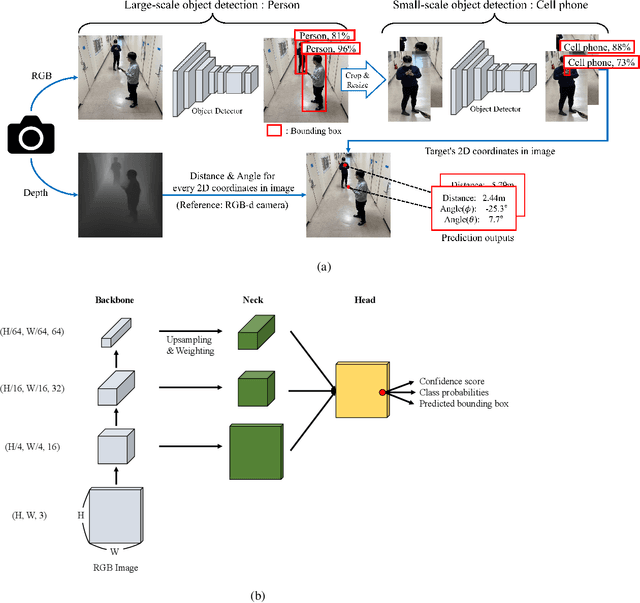
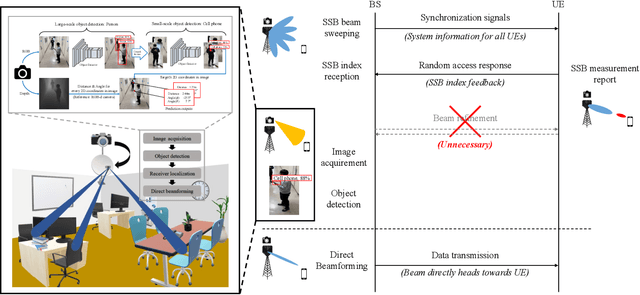

Beamforming technique realized by the multiple-input-multiple-output (MIMO) antenna arrays has been widely used to compensate for the severe path loss in the millimeter wave (mmWave) bands. In 5G NR system, the beam sweeping and beam refinement are employed to find out the best beam codeword aligned to the mobile. Due to the complicated handshaking and finite resolution of the codebook, today's 5G-based beam management strategy is ineffective in various scenarios in terms of the data rate, energy consumption, and also processing latency. An aim of this article is to introduce a new type of beam management framework based on the computer vision (CV) technique. In this framework referred to as computer vision-aided beam management (CVBM), a camera attached to the BS captures the image and then the deep learning-based object detector identifies the 3D location of the mobile. Since the base station can directly set the beam direction without codebook quantization and feedback delay, CVBM achieves the significant beamforming gain and latency reduction. Using the specially designed dataset called Vision Objects for Beam Management (VOBEM), we demonstrate that CVBM achieves more than 40% improvement in the beamforming gain and 40% reduction in the beam training overhead over the 5G NR beam management.
Towards Deep Learning-aided Wireless Channel Estimation and Channel State Information Feedback for 6G
Sep 05, 2022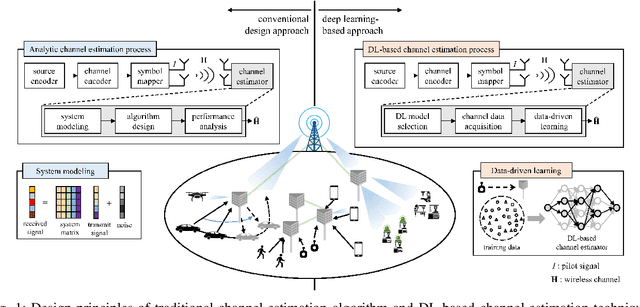
Deep learning (DL), a branch of artificial intelligence (AI) techniques, has shown great promise in various disciplines such as image classification and segmentation, speech recognition, language translation, among others. This remarkable success of DL has stimulated increasing interest in applying this paradigm to wireless channel estimation in recent years. Since DL principles are inductive in nature and distinct from the conventional rule-based algorithms, when one tries to use DL technique to the channel estimation, one might easily get stuck and confused by so many knobs to control and small details to be aware of. The primary purpose of this paper is to discuss key issues and possible solutions in DL-based wireless channel estimation and channel state information (CSI) feedback including the DL model selection, training data acquisition, and neural network design for 6G. Specifically, we present several case studies together with the numerical experiments to demonstrate the effectiveness of the DL-based wireless channel estimation framework.
S-Walk: Accurate and Scalable Session-based Recommendationwith Random Walks
Jan 04, 2022
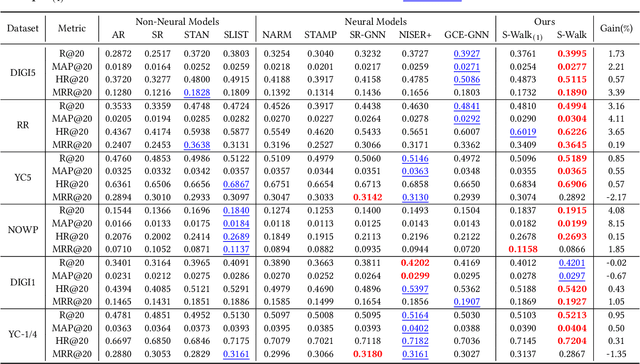
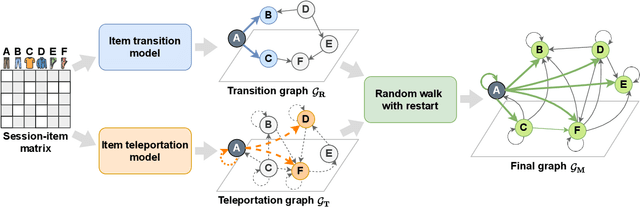
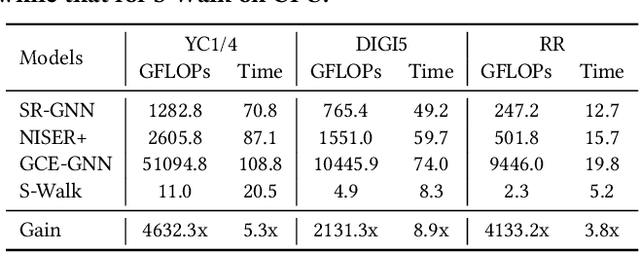
Session-based recommendation (SR) predicts the next items from a sequence of previous items consumed by an anonymous user. Most existing SR models focus only on modeling intra-session characteristics but pay less attention to inter-session relationships of items, which has the potential to improve accuracy. Another critical aspect of recommender systems is computational efficiency and scalability, considering practical feasibility in commercial applications. To account for both accuracy and scalability, we propose a novel session-based recommendation with a random walk, namely S-Walk. Precisely, S-Walk effectively captures intra- and inter-session correlations by handling high-order relationships among items using random walks with restart (RWR). By adopting linear models with closed-form solutions for transition and teleportation matrices that constitute RWR, S-Walk is highly efficient and scalable. Extensive experiments demonstrate that S-Walk achieves comparable or state-of-the-art performance in various metrics on four benchmark datasets. Moreover, the model learned by S-Walk can be highly compressed without sacrificing accuracy, conducting two or more orders of magnitude faster inference than existing DNN-based models, making it suitable for large-scale commercial systems.