 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangled Unsupervised Image Translation via Restricted Information Flow
Nov 26, 2021
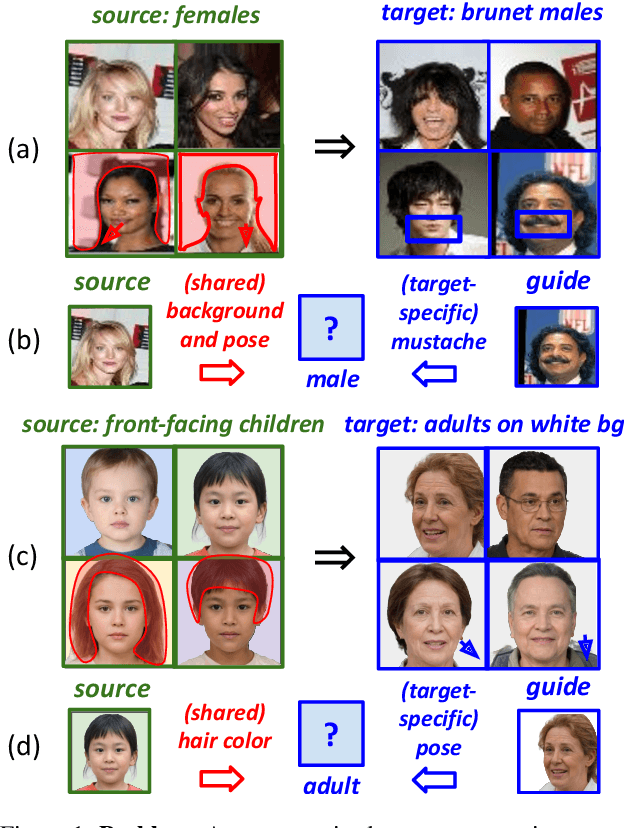
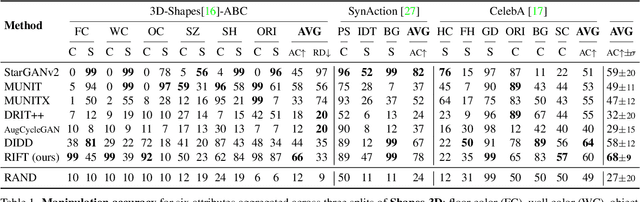
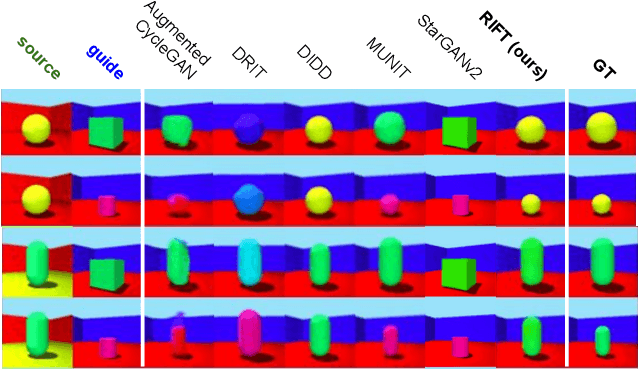
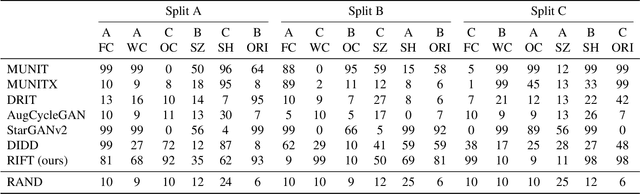
Unsupervised image-to-image translation methods aim to map images from one domain into plausible examples from another domain while preserving structures shared across two domains. In the many-to-many setting, an additional guidance example from the target domain is used to determine domain-specific attributes of the generated image. In the absence of attribute annotations, methods have to infer which factors are specific to each domain from data during training. Many state-of-art methods hard-code the desired shared-vs-specific split into their architecture, severely restricting the scope of the problem. In this paper, we propose a new method that does not rely on such inductive architectural biases, and infers which attributes are domain-specific from data by constraining information flow through the network using translation honesty losses and a penalty on the capacity of domain-specific embedding. We show that the proposed method achieves consistently high manipulation accuracy across two synthetic and one natural dataset spanning a wide variety of domain-specific and shared attributes.
Comparative analysis of segmentation and generative models for fingerprint retrieval task
Sep 13, 2022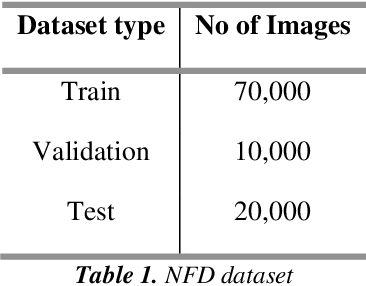
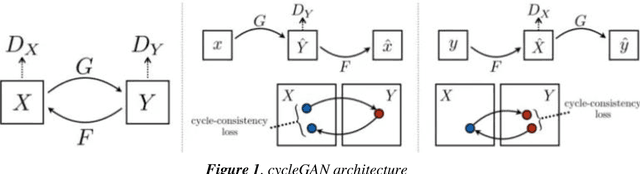
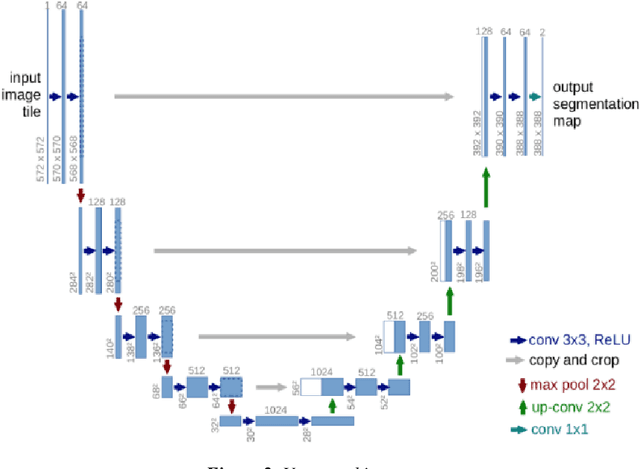
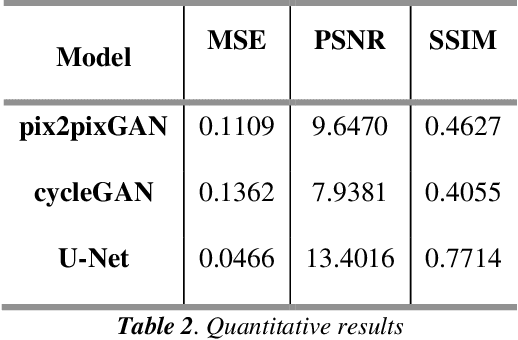
Biometric Authentication like Fingerprints has become an integral part of the modern technology for authentication and verification of users. It is pervasive in more ways than most of us are aware of. However, these fingerprint images deteriorate in quality if the fingers are dirty, wet, injured or when sensors malfunction. Therefore, extricating the original fingerprint by removing the noise and inpainting it to restructure the image is crucial for its authentication. Hence, this paper proposes a deep learning approach to address these issues using Generative (GAN) and Segmentation models. Qualitative and Quantitative comparison has been done between pix2pixGAN and cycleGAN (generative models) as well as U-net (segmentation model). To train the model, we created our own dataset NFD - Noisy Fingerprint Dataset meticulously with different backgrounds along with scratches in some images to make it more realistic and robust. In our research, the u-net model performed better than the GAN networks
2BiVQA: Double Bi-LSTM based Video Quality Assessment of UGC Videos
Aug 31, 2022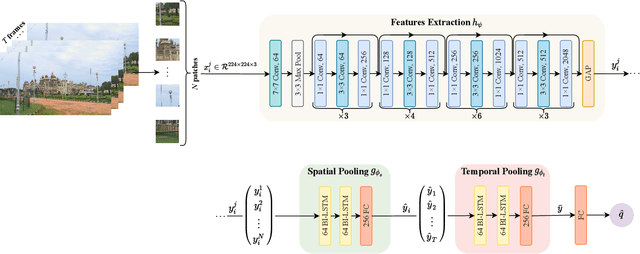
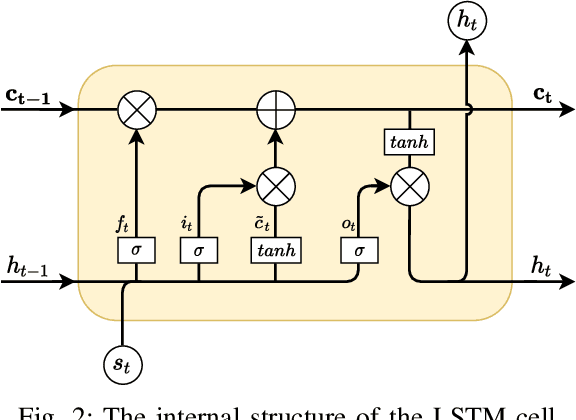
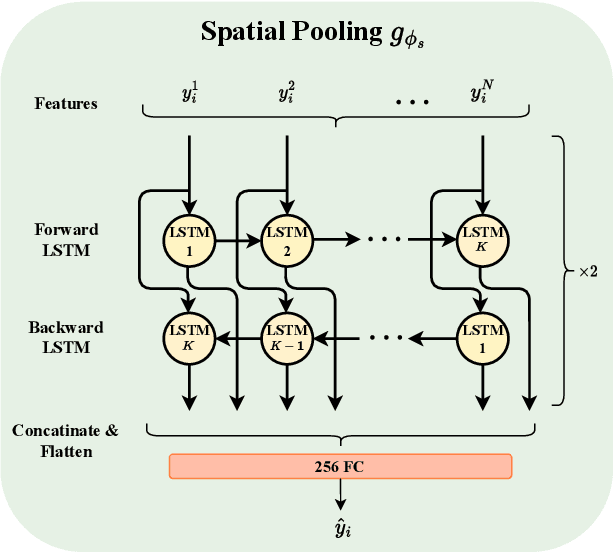
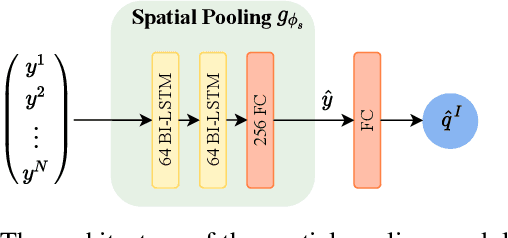
Recently, with the growing popularity of mobile devices as well as video sharing platforms (e.g., YouTube, Facebook, TikTok, and Twitch), User-Generated Content (UGC) videos have become increasingly common and now account for a large portion of multimedia traffic on the internet. Unlike professionally generated videos produced by filmmakers and videographers, typically, UGC videos contain multiple authentic distortions, generally introduced during capture and processing by naive users. Quality prediction of UGC videos is of paramount importance to optimize and monitor their processing in hosting platforms, such as their coding, transcoding, and streaming. However, blind quality prediction of UGC is quite challenging because the degradations of UGC videos are unknown and very diverse, in addition to the unavailability of pristine reference. Therefore, in this paper, we propose an accurate and efficient Blind Video Quality Assessment (BVQA) model for UGC videos, which we name 2BiVQA for double Bi-LSTM Video Quality Assessment. 2BiVQA metric consists of three main blocks, including a pre-trained Convolutional Neural Network (CNN) to extract discriminative features from image patches, which are then fed into two Recurrent Neural Networks (RNNs) for spatial and temporal pooling. Specifically, we use two Bi-directional Long Short Term Memory (Bi-LSTM) networks, the first is used to capture short-range dependencies between image patches, while the second allows capturing long-range dependencies between frames to account for the temporal memory effect. Experimental results on recent large-scale UGC video quality datasets show that 2BiVQA achieves high performance at a lower computational cost than state-of-the-art models. The source code of our 2BiVQA metric is made publicly available at: https://github.com/atelili/2BiVQA.
Contrastive Feature Learning for Fault Detection and Diagnostics in Railway Applications
Aug 28, 2022


A railway is a complex system comprising multiple infrastructure and rolling stock assets. To operate the system safely, reliably, and efficiently, the condition many components needs to be monitored. To automate this process, data-driven fault detection and diagnostics models can be employed. In practice, however, the performance of data-driven models can be compromised if the training dataset is not representative of all possible future conditions. We propose to approach this problem by learning a feature representation that is, on the one hand, invariant to operating or environmental factors but, on the other hand, sensitive to changes in the asset's health condition. We evaluate how contrastive learning can be employed on supervised and unsupervised fault detection and diagnostics tasks given real condition monitoring datasets within a railway system - one image dataset from infrastructure assets and one time-series dataset from rolling stock assets. First, we evaluate the performance of supervised contrastive feature learning on a railway sleeper defect classification task given a labeled image dataset. Second, we evaluate the performance of unsupervised contrastive feature learning without access to faulty samples on an anomaly detection task given a railway wheel dataset. Here, we test the hypothesis of whether a feature encoder's sensitivity to degradation is also sensitive to novel fault patterns in the data. Our results demonstrate that contrastive feature learning improves the performance on the supervised classification task regarding sleepers compared to a state-of-the-art method. Moreover, on the anomaly detection task concerning the railway wheels, the detection of shelling defects is improved compared to state-of-the-art methods.
PIFu for the Real World: A Self-supervised Framework to Reconstruct Dressed Human from Single-view Images
Aug 23, 2022
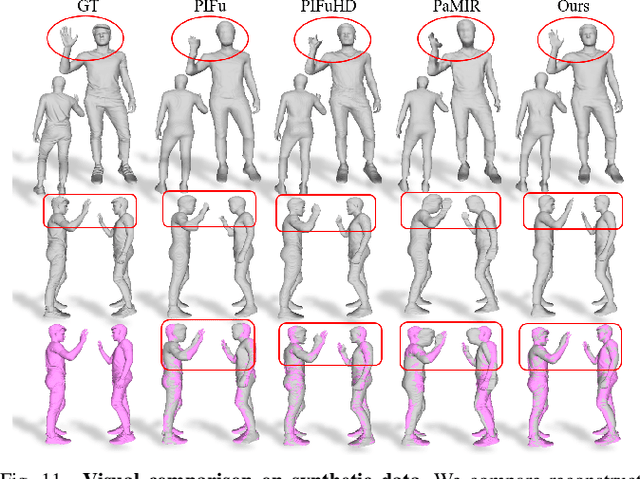
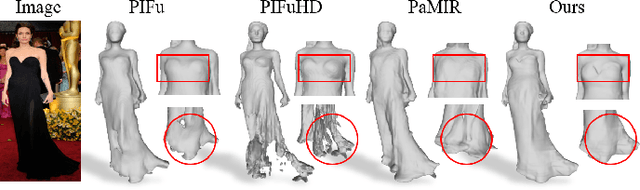
It is very challenging to accurately reconstruct sophisticated human geometry caused by various poses and garments from a single image. Recently, works based on pixel-aligned implicit function (PIFu) have made a big step and achieved state-of-the-art fidelity on image-based 3D human digitization. However, the training of PIFu relies heavily on expensive and limited 3D ground truth data (i.e. synthetic data), thus hindering its generalization to more diverse real world images. In this work, we propose an end-to-end self-supervised network named SelfPIFu to utilize abundant and diverse in-the-wild images, resulting in largely improved reconstructions when tested on unconstrained in-the-wild images. At the core of SelfPIFu is the depth-guided volume-/surface-aware signed distance fields (SDF) learning, which enables self-supervised learning of a PIFu without access to GT mesh. The whole framework consists of a normal estimator, a depth estimator, and a SDF-based PIFu and better utilizes extra depth GT during training. Extensive experiments demonstrate the effectiveness of our self-supervised framework and the superiority of using depth as input. On synthetic data, our Intersection-Over-Union (IoU) achieves to 93.5%, 18% higher compared with PIFuHD. For in-the-wild images, we conduct user studies on the reconstructed results, the selection rate of our results is over 68% compared with other state-of-the-art methods.
Hyperspectral Image Super-resolution with Deep Priors and Degradation Model Inversion
Jan 24, 2022
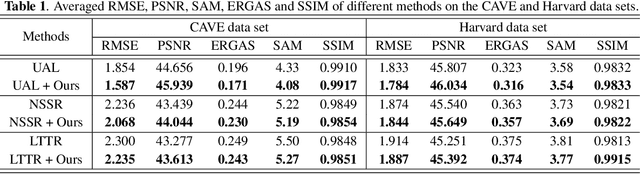
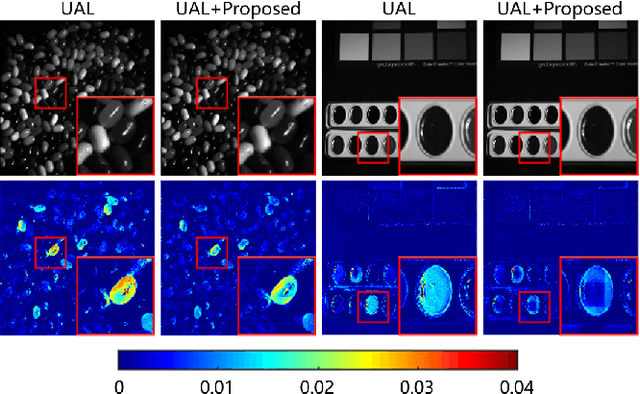
To overcome inherent hardware limitations of hyperspectral imaging systems with respect to their spatial resolution, fusion-based hyperspectral image (HSI) super-resolution is attracting increasing attention. This technique aims to fuse a low-resolution (LR) HSI and a conventional high-resolution (HR) RGB image in order to obtain an HR HSI. Recently, deep learning architectures have been used to address the HSI super-resolution problem and have achieved remarkable performance. However, they ignore the degradation model even though this model has a clear physical interpretation and may contribute to improve the performance. We address this problem by proposing a method that, on the one hand, makes use of the linear degradation model in the data-fidelity term of the objective function and, on the other hand, utilizes the output of a convolutional neural network for designing a deep prior regularizer in spectral and spatial gradient domains. Experiments show the performance improvement achieved with this strategy.
Memory Efficient Patch-based Training for INR-based GANs
Jul 04, 2022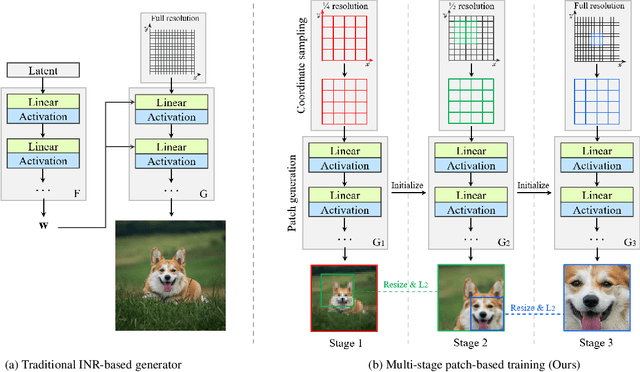
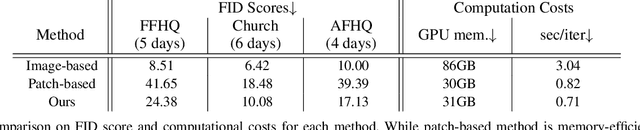


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
PanorAMS: Automatic Annotation for Detecting Objects in Urban Context
Aug 31, 2022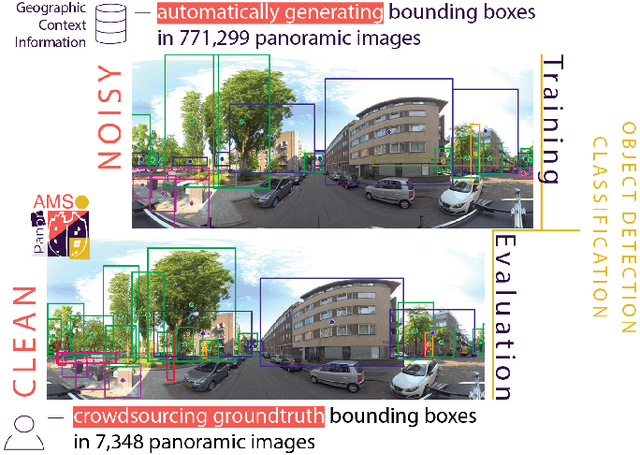

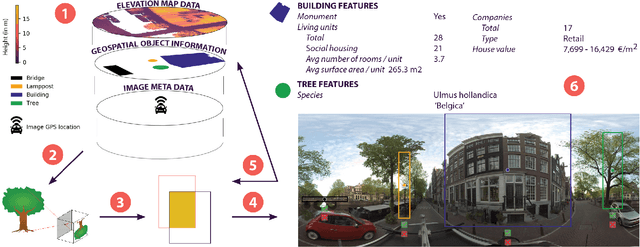
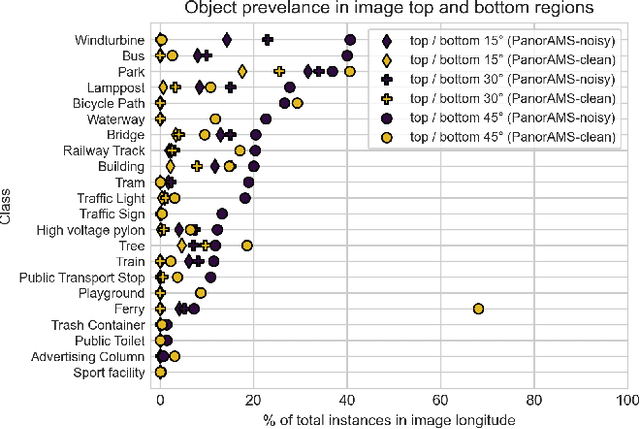
Large collections of geo-referenced panoramic images are freely available for cities across the globe, as well as detailed maps with location and meta-data on a great variety of urban objects. They provide a potentially rich source of information on urban objects, but manual annotation for object detection is costly, laborious and difficult. Can we utilize such multimedia sources to automatically annotate street level images as an inexpensive alternative to manual labeling? With the PanorAMS framework we introduce a method to automatically generate bounding box annotations for panoramic images based on urban context information. Following this method, we acquire large-scale, albeit noisy, annotations for an urban dataset solely from open data sources in a fast and automatic manner. The dataset covers the City of Amsterdam and includes over 14 million noisy bounding box annotations of 22 object categories present in 771,299 panoramic images. For many objects further fine-grained information is available, obtained from geospatial meta-data, such as building value, function and average surface area. Such information would have been difficult, if not impossible, to acquire via manual labeling based on the image alone. For detailed evaluation, we introduce an efficient crowdsourcing protocol for bounding box annotations in panoramic images, which we deploy to acquire 147,075 ground-truth object annotations for a subset of 7,348 images, the PanorAMS-clean dataset. For our PanorAMS-noisy dataset, we provide an extensive analysis of the noise and how different types of noise affect image classification and object detection performance. We make both datasets, PanorAMS-noisy and PanorAMS-clean, benchmarks and tools presented in this paper openly available.
Mitigating Both Covariate and Conditional Shift for Domain Generalization
Sep 17, 2022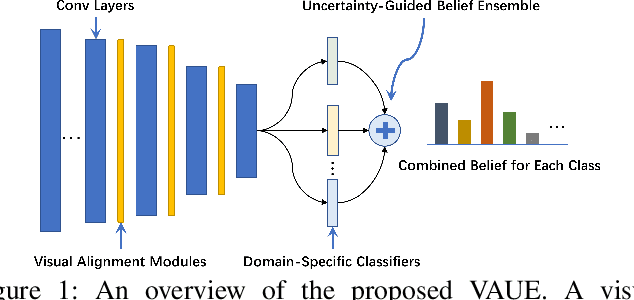
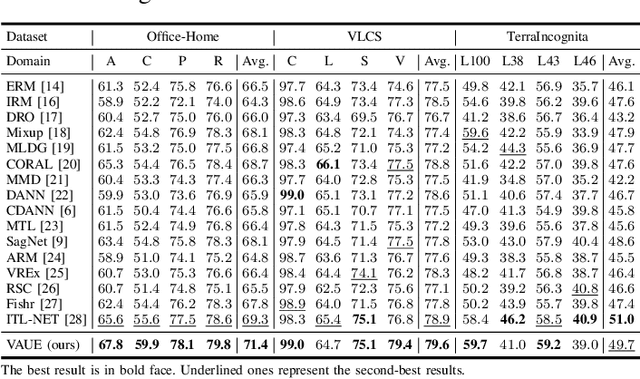
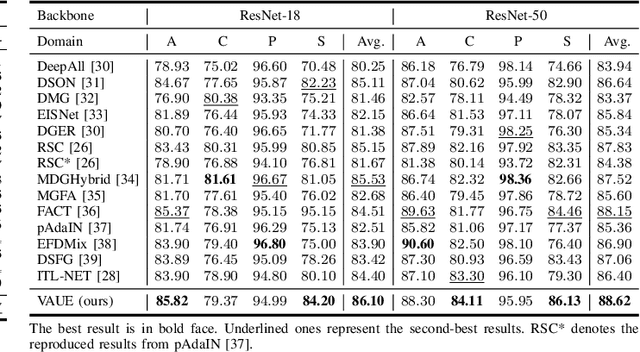
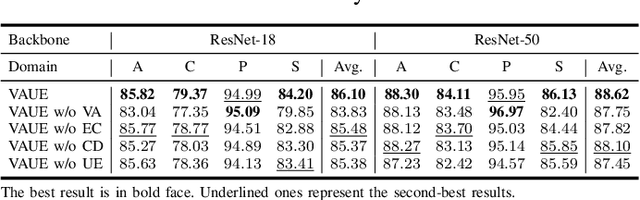
Domain generalization (DG) aims to learn a model on several source domains, hoping that the model can generalize well to unseen target domains. The distribution shift between domains contains the covariate shift and conditional shift, both of which the model must be able to handle for better generalizability. In this paper, a novel DG method is proposed to deal with the distribution shift via Visual Alignment and Uncertainty-guided belief Ensemble (VAUE). Specifically, for the covariate shift, a visual alignment module is designed to align the distribution of image style to a common empirical Gaussian distribution so that the covariate shift can be eliminated in the visual space. For the conditional shift, we adopt an uncertainty-guided belief ensemble strategy based on the subjective logic and Dempster-Shafer theory. The conditional distribution given a test sample is estimated by the dynamic combination of that of source domains. Comprehensive experiments are conducted to demonstrate the superior performance of the proposed method on four widely used datasets, i.e., Office-Home, VLCS, TerraIncognita, and PACS.
Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
Oct 11, 2021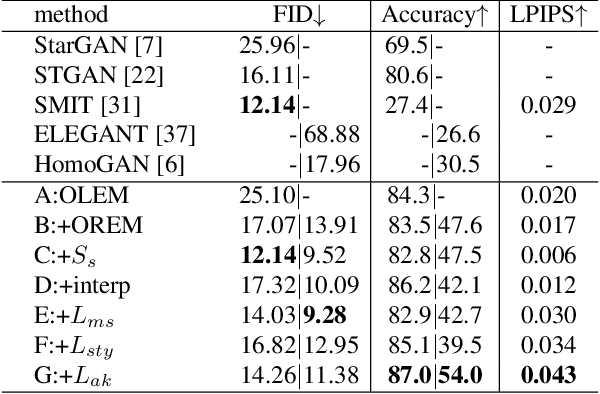
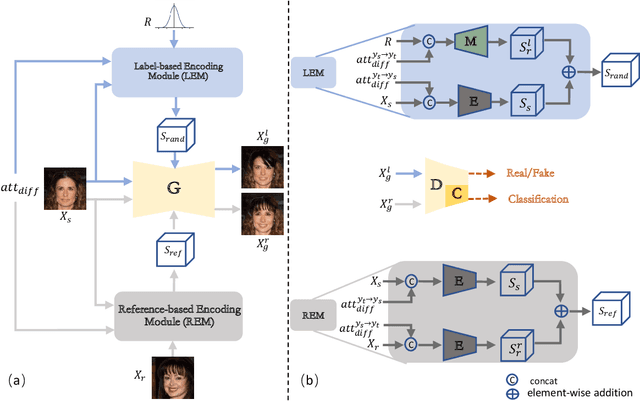


The image-to-image translation (I2IT) model takes a target label or a reference image as the input, and changes a source into the specified target domain. The two types of synthesis, either label- or reference-based, have substantial differences. Particularly, the label-based synthesis reflects the common characteristics of the target domain, and the reference-based shows the specific style similar to the reference. This paper intends to bridge the gap between them in the task of multi-attribute I2IT. We design the label- and reference-based encoding modules (LEM and REM) to compare the domain differences. They first transfer the source image and target label (or reference) into a common embedding space, by providing the opposite directions through the attribute difference vector. Then the two embeddings are simply fused together to form the latent code S_rand (or S_ref), reflecting the domain style differences, which is injected into each layer of the generator by SPADE. To link LEM and REM, so that two types of results benefit each other, we encourage the two latent codes to be close, and set up the cycle consistency between the forward and backward translations on them. Moreover, the interpolation between the S_rand and S_ref is also used to synthesize an extra image. Experiments show that label- and reference-based synthesis are indeed mutually promoted, so that we can have the diverse results from LEM, and high quality results with the similar style of the reference.