 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentsEval: Clinically Faithful Evaluation of Medical Imaging Reports via Multi-Agent Reasoning
Jan 23, 2026Evaluating the clinical correctness and reasoning fidelity of automatically generated medical imaging reports remains a critical yet unresolved challenge. Existing evaluation methods often fail to capture the structured diagnostic logic that underlies radiological interpretation, resulting in unreliable judgments and limited clinical relevance. We introduce AgentsEval, a multi-agent stream reasoning framework that emulates the collaborative diagnostic workflow of radiologists. By dividing the evaluation process into interpretable steps including criteria definition, evidence extraction, alignment, and consistency scoring, AgentsEval provides explicit reasoning traces and structured clinical feedback. We also construct a multi-domain perturbation-based benchmark covering five medical report datasets with diverse imaging modalities and controlled semantic variations. Experimental results demonstrate that AgentsEval delivers clinically aligned, semantically faithful, and interpretable evaluations that remain robust under paraphrastic, semantic, and stylistic perturbations. This framework represents a step toward transparent and clinically grounded assessment of medical report generation systems, fostering trustworthy integration of large language models into clinical practice.
PIFu for the Real World: A Self-supervised Framework to Reconstruct Dressed Human from Single-view Images
Aug 23, 2022
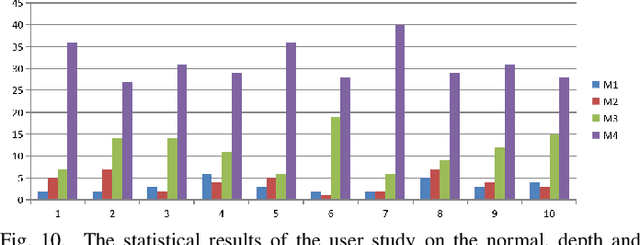
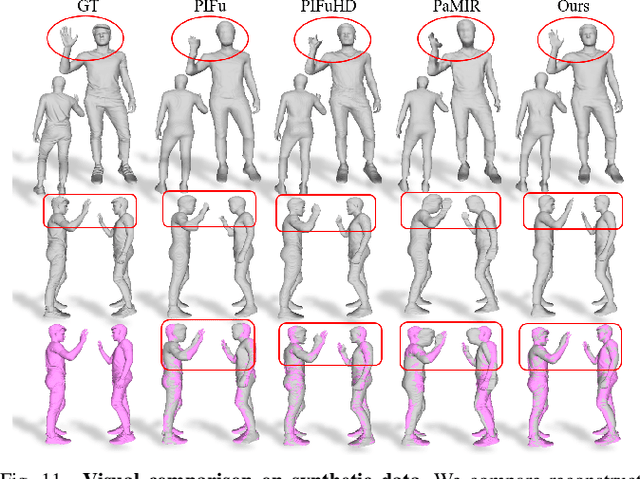
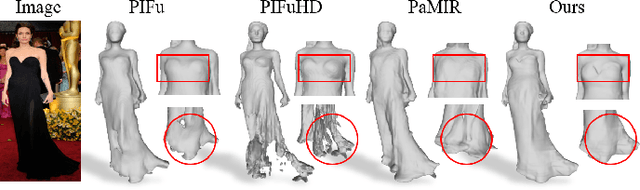
It is very challenging to accurately reconstruct sophisticated human geometry caused by various poses and garments from a single image. Recently, works based on pixel-aligned implicit function (PIFu) have made a big step and achieved state-of-the-art fidelity on image-based 3D human digitization. However, the training of PIFu relies heavily on expensive and limited 3D ground truth data (i.e. synthetic data), thus hindering its generalization to more diverse real world images. In this work, we propose an end-to-end self-supervised network named SelfPIFu to utilize abundant and diverse in-the-wild images, resulting in largely improved reconstructions when tested on unconstrained in-the-wild images. At the core of SelfPIFu is the depth-guided volume-/surface-aware signed distance fields (SDF) learning, which enables self-supervised learning of a PIFu without access to GT mesh. The whole framework consists of a normal estimator, a depth estimator, and a SDF-based PIFu and better utilizes extra depth GT during training. Extensive experiments demonstrate the effectiveness of our self-supervised framework and the superiority of using depth as input. On synthetic data, our Intersection-Over-Union (IoU) achieves to 93.5%, 18% higher compared with PIFuHD. For in-the-wild images, we conduct user studies on the reconstructed results, the selection rate of our results is over 68% compared with other state-of-the-art methods.