 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mixture of Diffusers for scene composition and high resolution image generation
Feb 05, 2023
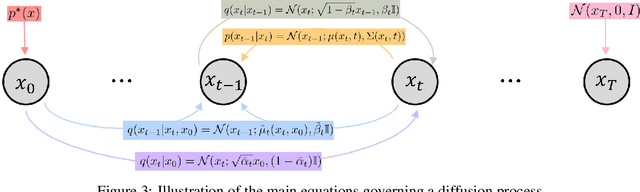

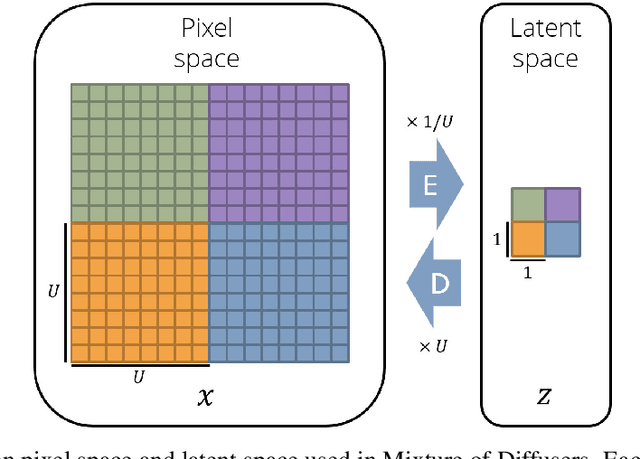

Diffusion methods have been proven to be very effective to generate images while conditioning on a text prompt. However, and although the quality of the generated images is unprecedented, these methods seem to struggle when trying to generate specific image compositions. In this paper we present Mixture of Diffusers, an algorithm that builds over existing diffusion models to provide a more detailed control over composition. By harmonizing several diffusion processes acting on different regions of a canvas, it allows generating larger images, where the location of each object and style is controlled by a separate diffusion process.
Context-Aware Chart Element Detection
May 07, 2023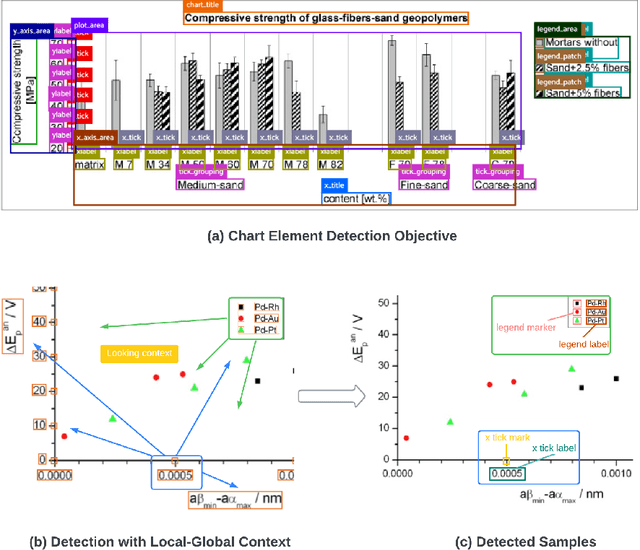
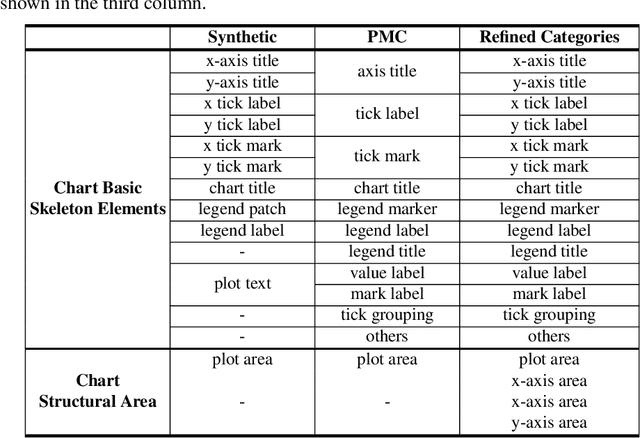
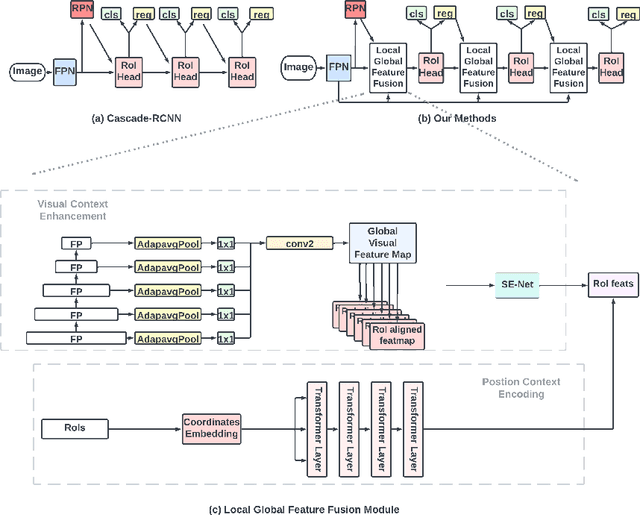
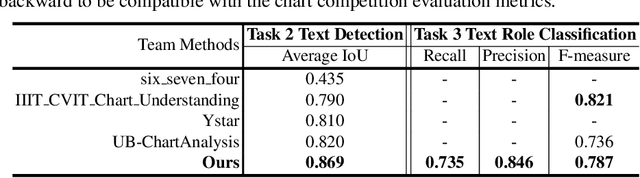
As a prerequisite of chart data extraction, the accurate detection of chart basic elements is essential and mandatory. In contrast to object detection in the general image domain, chart element detection relies heavily on context information as charts are highly structured data visualization formats. To address this, we propose a novel method CACHED, which stands for Context-Aware Chart Element Detection, by integrating a local-global context fusion module consisting of visual context enhancement and positional context encoding with the Cascade R-CNN framework. To improve the generalization of our method for broader applicability, we refine the existing chart element categorization and standardized 18 classes for chart basic elements, excluding plot elements. Our CACHED method, with the updated category of chart elements, achieves state-of-the-art performance in our experiments, underscoring the importance of context in chart element detection. Extending our method to the bar plot detection task, we obtain the best result on the PMC test dataset.
DCELANM-Net:Medical Image Segmentation based on Dual Channel Efficient Layer Aggregation Network with Learner
Apr 19, 2023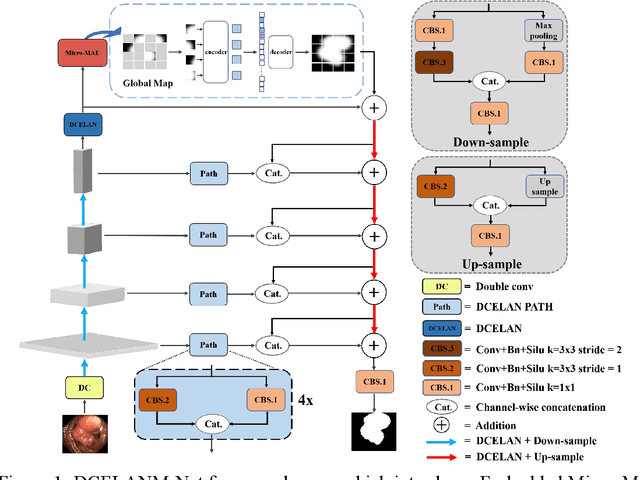

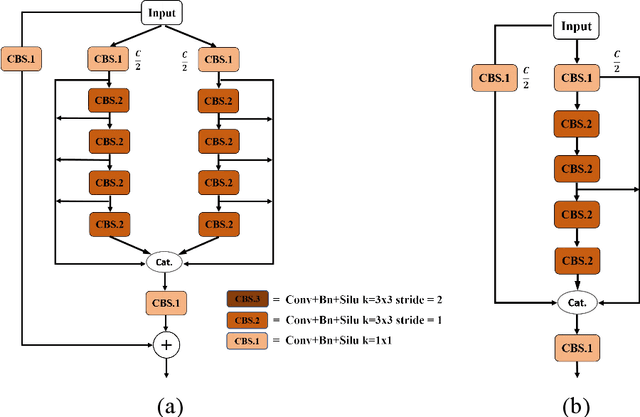
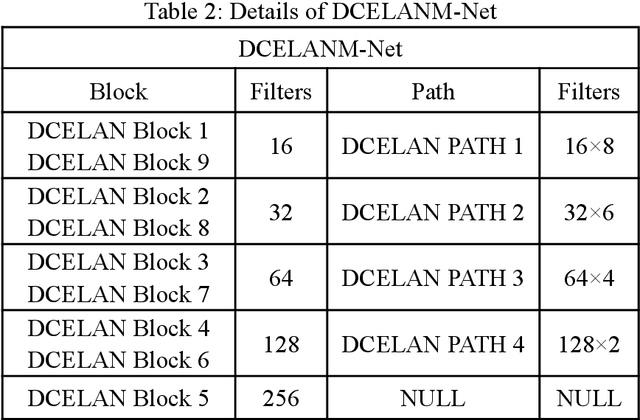
The DCELANM-Net structure, which this article offers, is a model that ingeniously combines a Dual Channel Efficient Layer Aggregation Network (DCELAN) and a Micro Masked Autoencoder (Micro-MAE). On the one hand, for the DCELAN, the features are more effectively fitted by deepening the network structure; the deeper network can successfully learn and fuse the features, which can more accurately locate the local feature information; and the utilization of each layer of channels is more effectively improved by widening the network structure and residual connections. We adopted Micro-MAE as the learner of the model. In addition to being straightforward in its methodology, it also offers a self-supervised learning method, which has the benefit of being incredibly scaleable for the model.
LatentAugment: Dynamically Optimized Latent Probabilities of Data Augmentation
May 04, 2023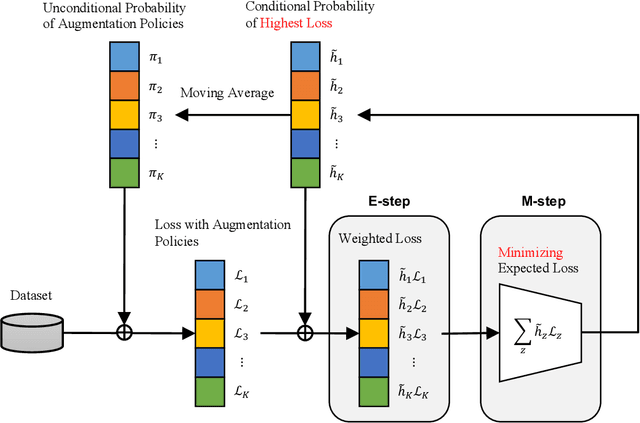

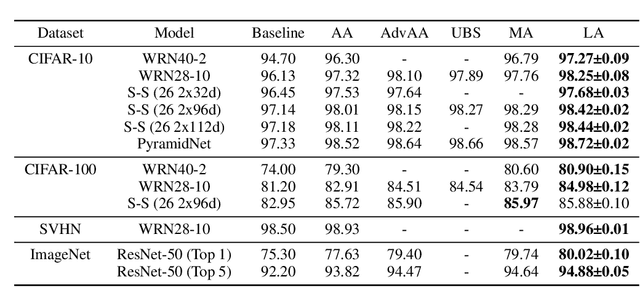
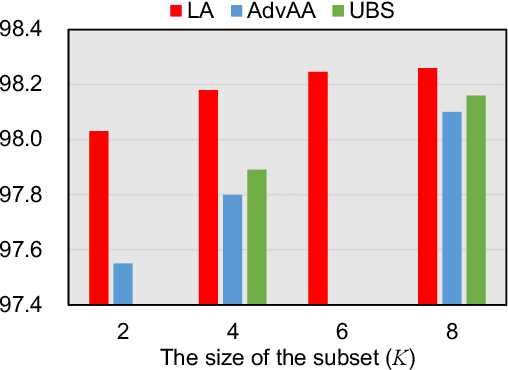
Although data augmentation is a powerful technique for improving the performance of image classification tasks, it is difficult to identify the best augmentation policy. The optimal augmentation policy, which is the latent variable, cannot be directly observed. To address this problem, this study proposes $\textit{LatentAugment}$, which estimates the latent probability of optimal augmentation. The proposed method is appealing in that it can dynamically optimize the augmentation strategies for each input and model parameter in learning iterations. Theoretical analysis shows that LatentAugment is a general model that includes other augmentation methods as special cases, and it is simple and computationally efficient in comparison with existing augmentation methods. Experimental results show that the proposed LatentAugment has higher test accuracy than previous augmentation methods on the CIFAR-10, CIFAR-100, SVHN, and ImageNet datasets.
Forward-Forward Contrastive Learning
May 04, 2023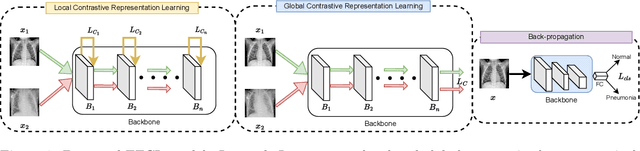
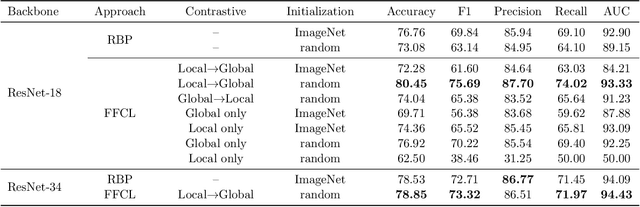
Medical image classification is one of the most important tasks for computer-aided diagnosis. Deep learning models, particularly convolutional neural networks, have been successfully used for disease classification from medical images, facilitated by automated feature learning. However, the diverse imaging modalities and clinical pathology make it challenging to construct generalized and robust classifications. Towards improving the model performance, we propose a novel pretraining approach, namely Forward Forward Contrastive Learning (FFCL), which leverages the Forward-Forward Algorithm in a contrastive learning framework--both locally and globally. Our experimental results on the chest X-ray dataset indicate that the proposed FFCL achieves superior performance (3.69% accuracy over ImageNet pretrained ResNet-18) over existing pretraining models in the pneumonia classification task. Moreover, extensive ablation experiments support the particular local and global contrastive pretraining design in FFCL.
Learning Sentinel-2 reflectance dynamics for data-driven assimilation and forecasting
May 05, 2023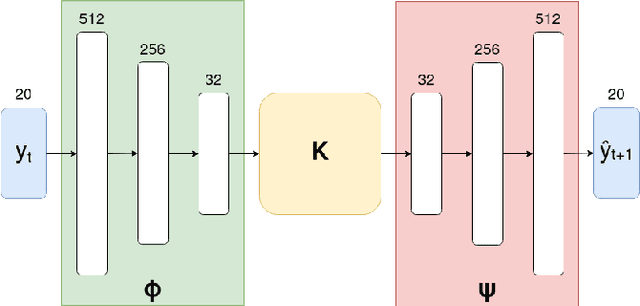
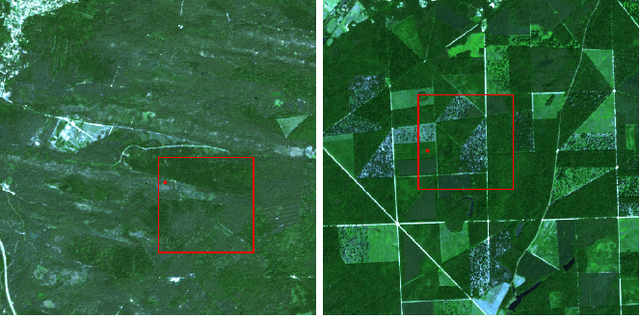
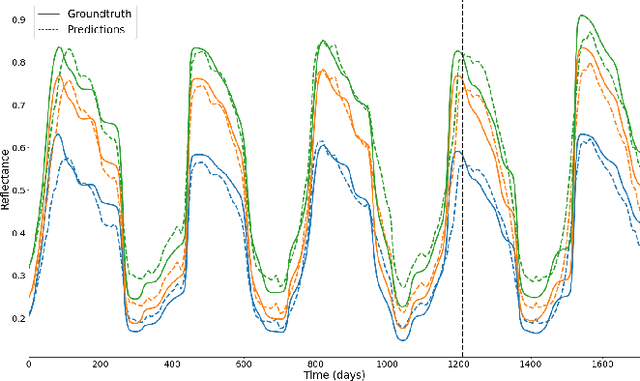

Over the last few years, massive amounts of satellite multispectral and hyperspectral images covering the Earth's surface have been made publicly available for scientific purpose, for example through the European Copernicus project. Simultaneously, the development of self-supervised learning (SSL) methods has sparked great interest in the remote sensing community, enabling to learn latent representations from unlabeled data to help treating downstream tasks for which there is few annotated examples, such as interpolation, forecasting or unmixing. Following this line, we train a deep learning model inspired from the Koopman operator theory to model long-term reflectance dynamics in an unsupervised way. We show that this trained model, being differentiable, can be used as a prior for data assimilation in a straightforward way. Our datasets, which are composed of Sentinel-2 multispectral image time series, are publicly released with several levels of treatment.
OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer
Feb 09, 2023
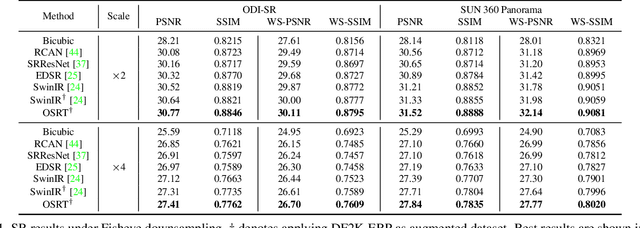
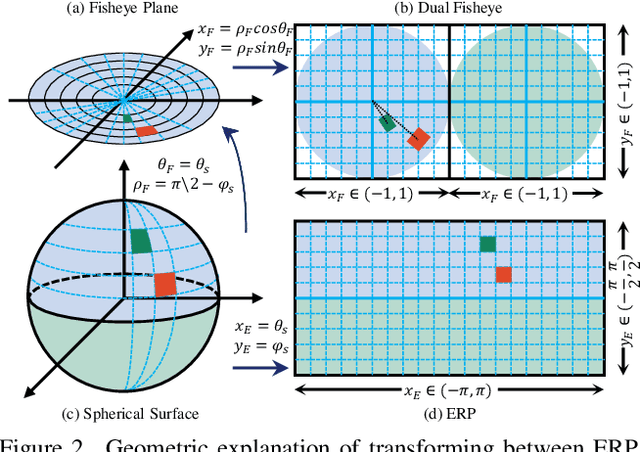
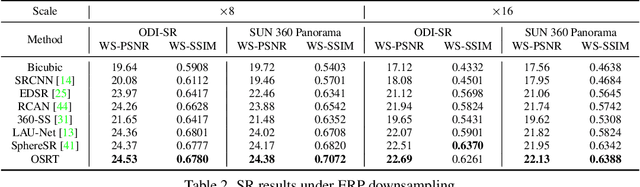
Omnidirectional images (ODIs) have obtained lots of research interest for immersive experiences. Although ODIs require extremely high resolution to capture details of the entire scene, the resolutions of most ODIs are insufficient. Previous methods attempt to solve this issue by image super-resolution (SR) on equirectangular projection (ERP) images. However, they omit geometric properties of ERP in the degradation process, and their models can hardly generalize to real ERP images. In this paper, we propose Fisheye downsampling, which mimics the real-world imaging process and synthesizes more realistic low-resolution samples. Then we design a distortion-aware Transformer (OSRT) to modulate ERP distortions continuously and self-adaptively. Without a cumbersome process, OSRT outperforms previous methods by about 0.2dB on PSNR. Moreover, we propose a convenient data augmentation strategy, which synthesizes pseudo ERP images from plain images. This simple strategy can alleviate the over-fitting problem of large networks and significantly boost the performance of ODISR. Extensive experiments have demonstrated the state-of-the-art performance of our OSRT. Codes and models will be available at https://github.com/Fanghua-Yu/OSRT.
Polygonizer: An auto-regressive building delineator
Apr 08, 2023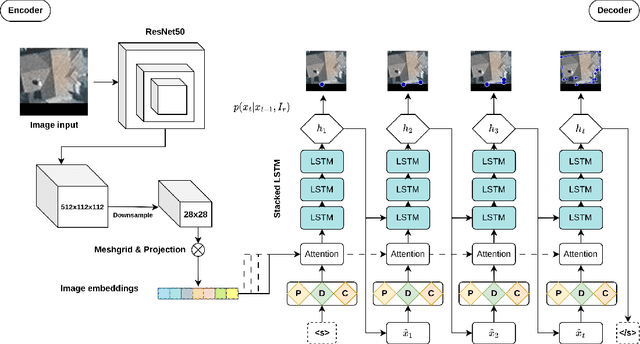


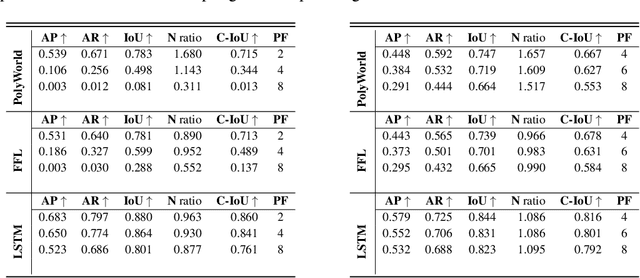
In geospatial planning, it is often essential to represent objects in a vectorized format, as this format easily translates to downstream tasks such as web development, graphics, or design. While these problems are frequently addressed using semantic segmentation, which requires additional post-processing to vectorize objects in a non-trivial way, we present an Image-to-Sequence model that allows for direct shape inference and is ready for vector-based workflows out of the box. We demonstrate the model's performance in various ways, including perturbations to the image input that correspond to variations or artifacts commonly encountered in remote sensing applications. Our model outperforms prior works when using ground truth bounding boxes (one object per image), achieving the lowest maximum tangent angle error.
Spatiotemporal Graph Convolutional Recurrent Neural Network Model for Citywide Air Pollution Forecasting
Apr 25, 2023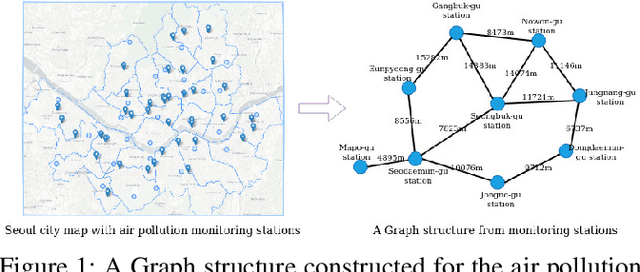
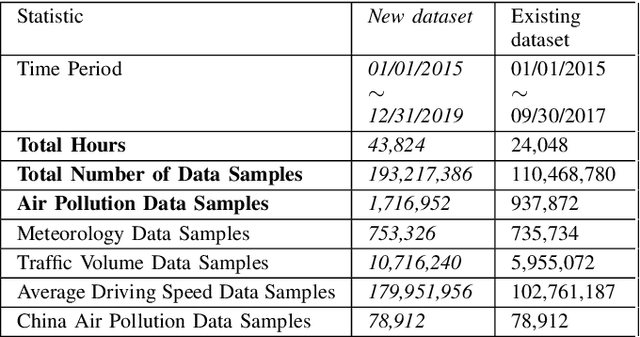
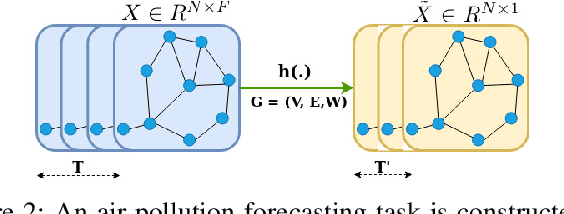
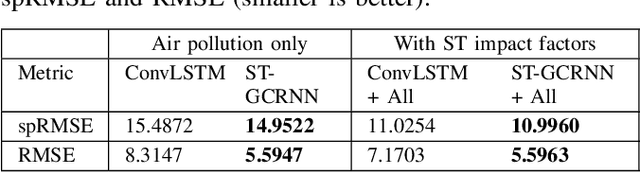
Citywide Air Pollution Forecasting tries to precisely predict the air quality multiple hours ahead for the entire city. This topic is challenged since air pollution varies in a spatiotemporal manner and depends on many complicated factors. Our previous research has solved the problem by considering the whole city as an image and leveraged a Convolutional Long Short-Term Memory (ConvLSTM) model to learn the spatiotemporal features. However, an image-based representation may not be ideal as air pollution and other impact factors have natural graph structures. In this research, we argue that a Graph Convolutional Network (GCN) can efficiently represent the spatial features of air quality readings in the whole city. Specially, we extend the ConvLSTM model to a Spatiotemporal Graph Convolutional Recurrent Neural Network (Spatiotemporal GCRNN) model by tightly integrating a GCN architecture into an RNN structure for efficient learning spatiotemporal characteristics of air quality values and their influential factors. Our extensive experiments prove the proposed model has a better performance compare to the state-of-the-art ConvLSTM model for air pollution predicting while the number of parameters is much smaller. Moreover, our approach is also superior to a hybrid GCN-based method in a real-world air pollution dataset.
Hypernymization of named entity-rich captions for grounding-based multi-modal pretraining
Apr 25, 2023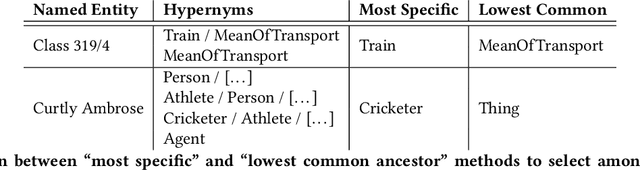

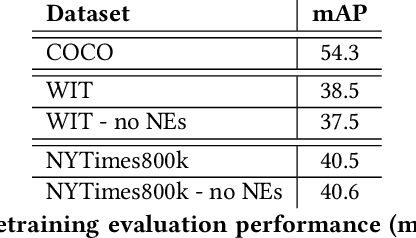
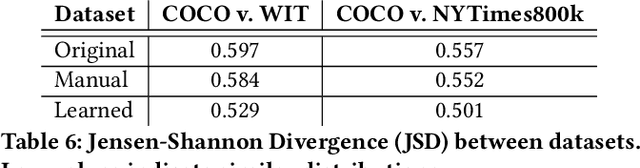
Named entities are ubiquitous in text that naturally accompanies images, especially in domains such as news or Wikipedia articles. In previous work, named entities have been identified as a likely reason for low performance of image-text retrieval models pretrained on Wikipedia and evaluated on named entities-free benchmark datasets. Because they are rarely mentioned, named entities could be challenging to model. They also represent missed learning opportunities for self-supervised models: the link between named entity and object in the image may be missed by the model, but it would not be if the object were mentioned using a more common term. In this work, we investigate hypernymization as a way to deal with named entities for pretraining grounding-based multi-modal models and for fine-tuning on open-vocabulary detection. We propose two ways to perform hypernymization: (1) a ``manual'' pipeline relying on a comprehensive ontology of concepts, and (2) a ``learned'' approach where we train a language model to learn to perform hypernymization. We run experiments on data from Wikipedia and from The New York Times. We report improved pretraining performance on objects of interest following hypernymization, and we show the promise of hypernymization on open-vocabulary detection, specifically on classes not seen during training.