 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Pipeline for Preprocessing and Segmenting Cardiac Magnetic Resonance of Single Ventricle Patients from an Image Registry
Mar 21, 2023
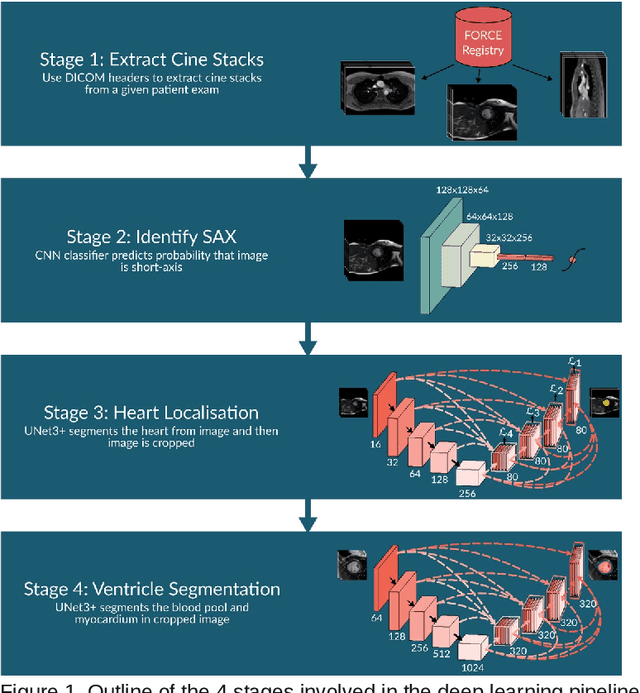
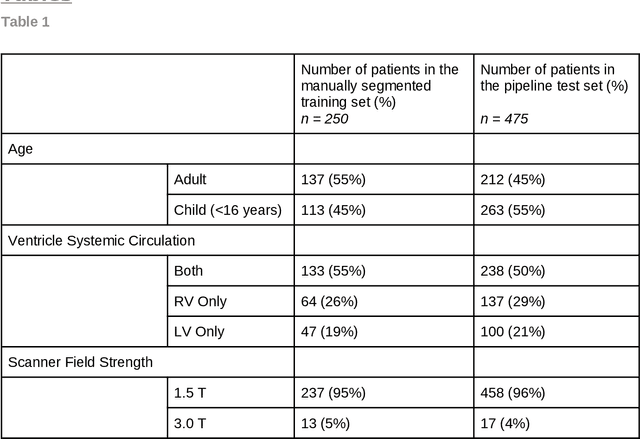
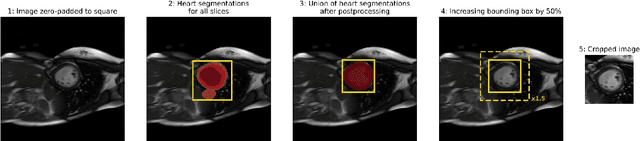
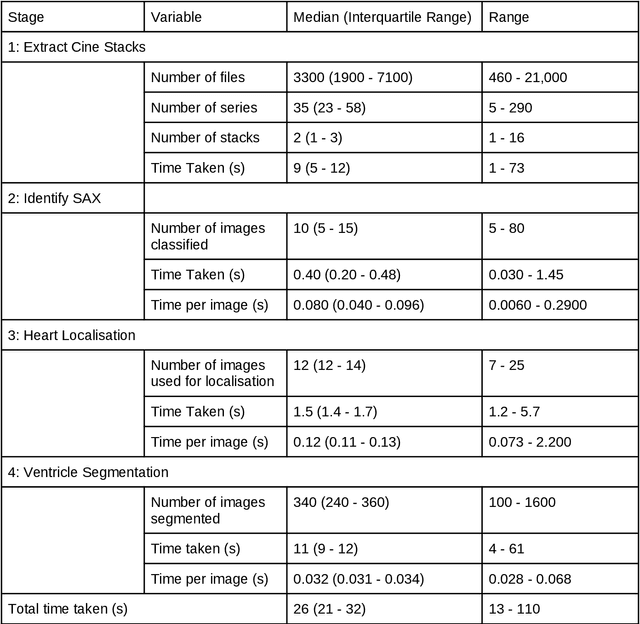
Purpose: To develop and evaluate an end-to-end deep learning pipeline for segmentation and analysis of cardiac magnetic resonance images to provide core-lab processing for a multi-centre registry of Fontan patients. Materials and Methods: This retrospective study used training (n = 175), validation (n = 25) and testing (n = 50) cardiac magnetic resonance image exams collected from 13 institutions in the UK, US and Canada. The data was used to train and evaluate a pipeline containing three deep-learning models. The pipeline's performance was assessed on the Dice and IoU score between the automated and reference standard manual segmentation. Cardiac function values were calculated from both the automated and manual segmentation and evaluated using Bland-Altman analysis and paired t-tests. The overall pipeline was further evaluated qualitatively on 475 unseen patient exams. Results: For the 50 testing dataset, the pipeline achieved a median Dice score of 0.91 (0.89-0.94) for end-diastolic volume, 0.86 (0.82-0.89) for end-systolic volume, and 0.74 (0.70-0.77) for myocardial mass. The deep learning-derived end-diastolic volume, end-systolic volume, myocardial mass, stroke volume and ejection fraction had no statistical difference compared to the same values derived from manual segmentation with p values all greater than 0.05. For the 475 unseen patient exams, the pipeline achieved 68% adequate segmentation in both systole and diastole, 26% needed minor adjustments in either systole or diastole, 5% needed major adjustments, and the cropping model only failed in 0.4%. Conclusion: Deep learning pipeline can provide standardised 'core-lab' segmentation for Fontan patients. This pipeline can now be applied to the >4500 cardiac magnetic resonance exams currently in the FORCE registry as well as any new patients that are recruited.
ULIP-2: Towards Scalable Multimodal Pre-training For 3D Understanding
May 14, 2023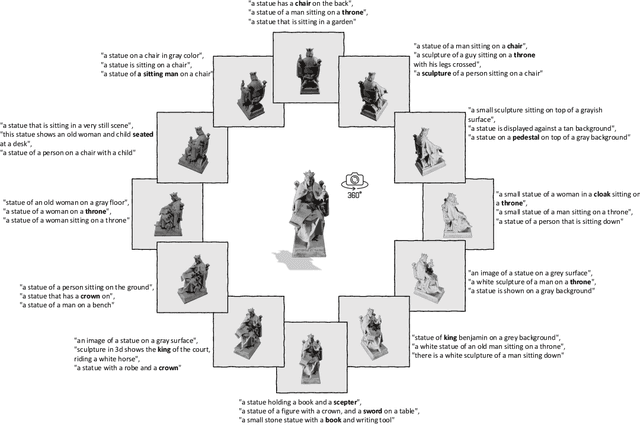

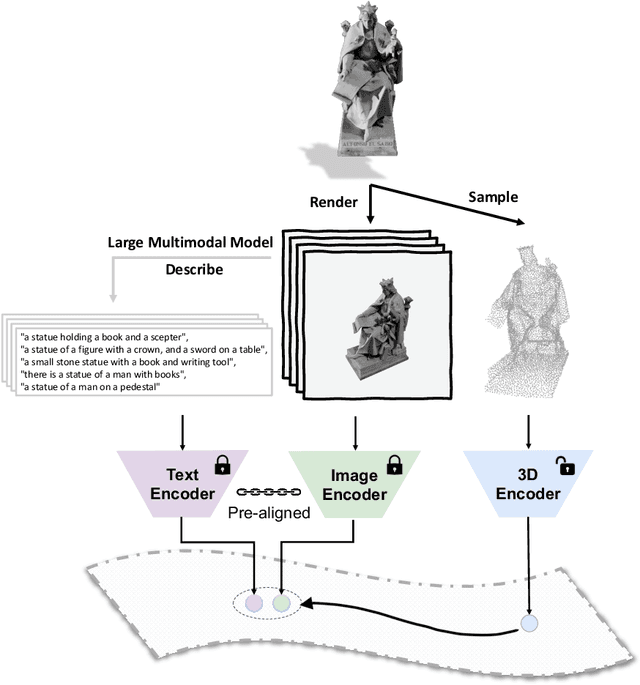
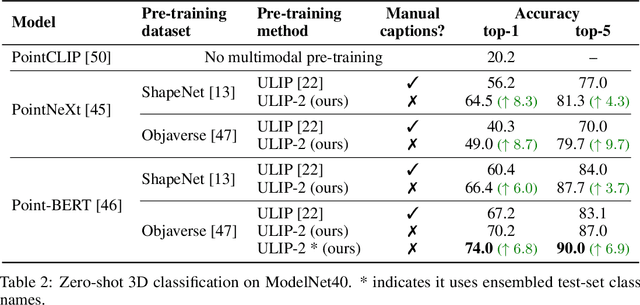
Recent advancements in multimodal pre-training methods have shown promising efficacy in 3D representation learning by aligning features across 3D modality, their 2D counterpart modality, and corresponding language modality. However, the methods used by existing multimodal pre-training frameworks to gather multimodal data for 3D applications lack scalability and comprehensiveness, potentially constraining the full potential of multimodal learning. The main bottleneck lies in the language modality's scalability and comprehensiveness. To address this bottleneck, we introduce ULIP-2, a multimodal pre-training framework that leverages state-of-the-art multimodal large language models (LLMs) pre-trained on extensive knowledge to automatically generate holistic language counterparts for 3D objects. We conduct experiments on two large-scale datasets, Objaverse and ShapeNet55, and release our generated three-modality triplet datasets (3D Point Cloud - Image - Language), named "ULIP-Objaverse Triplets" and "ULIP-ShapeNet Triplets". ULIP-2 requires only 3D data itself and eliminates the need for any manual annotation effort, demonstrating its scalability; and ULIP-2 achieves remarkable improvements on downstream zero-shot classification on ModelNet40 (74% Top1 Accuracy). Moreover, ULIP-2 sets a new record on the real-world ScanObjectNN benchmark (91.5% Overall Accuracy) while utilizing only 1.4 million parameters(~10x fewer than current SOTA), signifying a breakthrough in scalable multimodal 3D representation learning without human annotations. The code and datasets are available at https://github.com/salesforce/ULIP.
Population-based JPEG Image Compression: Problem Re-Formulation
Dec 13, 2022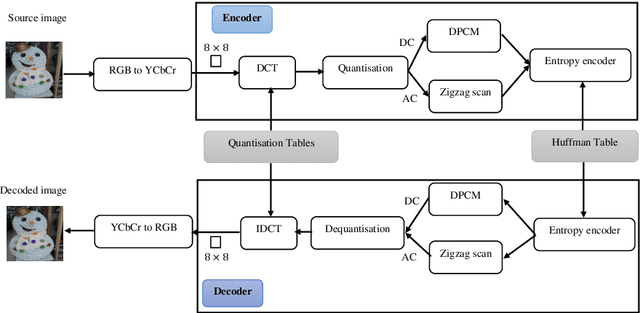
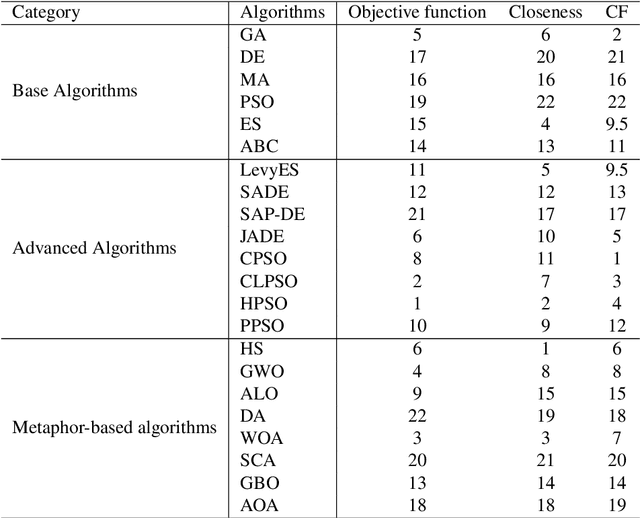
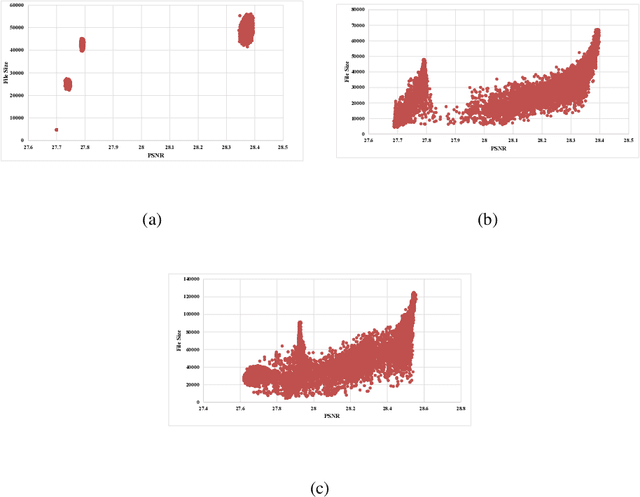

The JPEG standard is widely used in different image processing applications. One of the main components of the JPEG standard is the quantisation table (QT) since it plays a vital role in the image properties such as image quality and file size. In recent years, several efforts based on population-based metaheuristic (PBMH) algorithms have been performed to find the proper QT(s) for a specific image, although they do not take into consideration the user's opinion. Take an android developer as an example, who prefers a small-size image, while the optimisation process results in a high-quality image, leading to a huge file size. Another pitfall of the current works is a lack of comprehensive coverage, meaning that the QT(s) can not provide all possible combinations of file size and quality. Therefore, this paper aims to propose three distinct contributions. First, to include the user's opinion in the compression process, the file size of the output image can be controlled by a user in advance. Second, to tackle the lack of comprehensive coverage, we suggest a novel representation. Our proposed representation can not only provide more comprehensive coverage but also find the proper value for the quality factor for a specific image without any background knowledge. Both changes in representation and objective function are independent of the search strategies and can be used with any type of population-based metaheuristic (PBMH) algorithm. Therefore, as the third contribution, we also provide a comprehensive benchmark on 22 state-of-the-art and recently-introduced PBMH algorithms on our new formulation of JPEG image compression. Our extensive experiments on different benchmark images and in terms of different criteria show that our novel formulation for JPEG image compression can work effectively.
CoPR: Towards Accurate Visual Localization With Continuous Place-descriptor Regression
Apr 14, 2023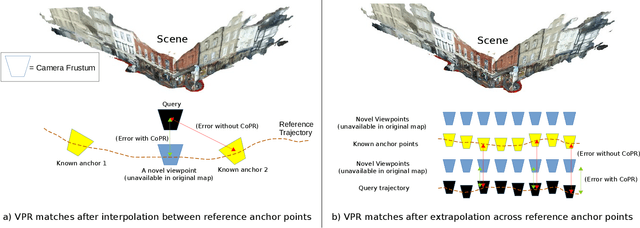
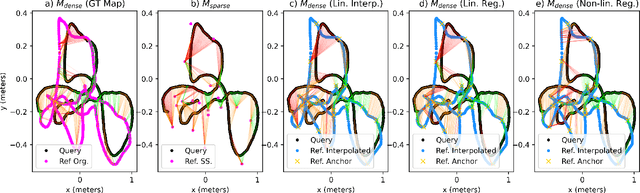
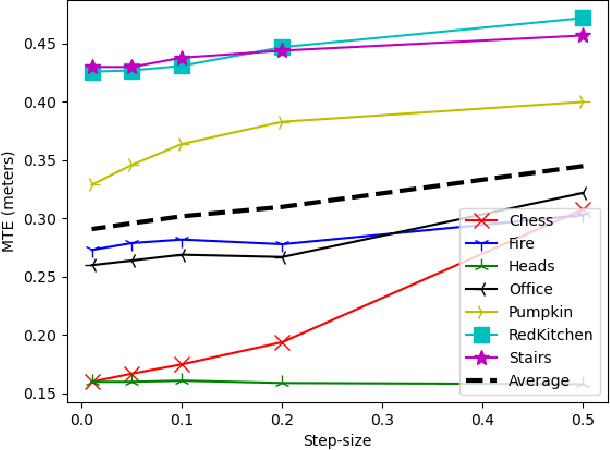

Visual Place Recognition (VPR) is an image-based localization method that estimates the camera location of a query image by retrieving the most similar reference image from a map of geo-tagged reference images. In this work, we look into two fundamental bottlenecks for its localization accuracy: reference map sparseness and viewpoint invariance. Firstly, the reference images for VPR are only available at sparse poses in a map, which enforces an upper bound on the maximum achievable localization accuracy through VPR. We therefore propose Continuous Place-descriptor Regression (CoPR) to densify the map and improve localization accuracy. We study various interpolation and extrapolation models to regress additional VPR feature descriptors from only the existing references. Secondly, we compare different feature encoders and show that CoPR presents value for all of them. We evaluate our models on three existing public datasets and report on average around 30% improvement in VPR-based localization accuracy using CoPR, on top of the 15% increase by using a viewpoint-variant loss for the feature encoder. The complementary relation between CoPR and Relative Pose Estimation is also discussed.
Text-Conditional Contextualized Avatars For Zero-Shot Personalization
Apr 14, 2023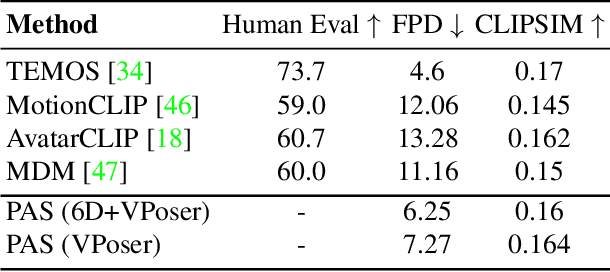
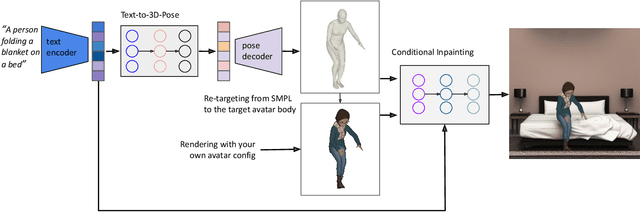
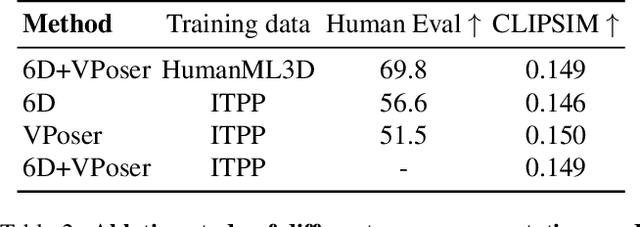
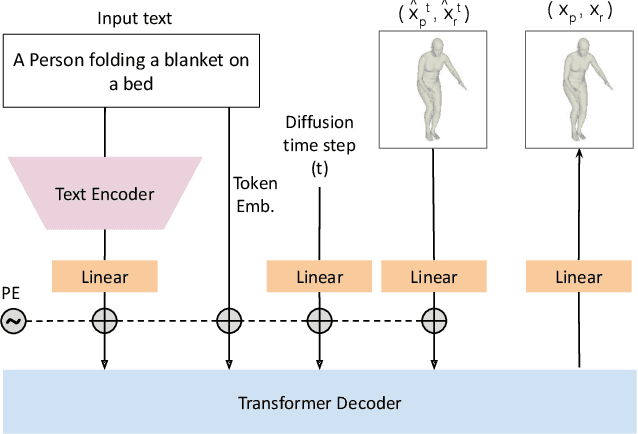
Recent large-scale text-to-image generation models have made significant improvements in the quality, realism, and diversity of the synthesized images and enable users to control the created content through language. However, the personalization aspect of these generative models is still challenging and under-explored. In this work, we propose a pipeline that enables personalization of image generation with avatars capturing a user's identity in a delightful way. Our pipeline is zero-shot, avatar texture and style agnostic, and does not require training on the avatar at all - it is scalable to millions of users who can generate a scene with their avatar. To render the avatar in a pose faithful to the given text prompt, we propose a novel text-to-3D pose diffusion model trained on a curated large-scale dataset of in-the-wild human poses improving the performance of the SOTA text-to-motion models significantly. We show, for the first time, how to leverage large-scale image datasets to learn human 3D pose parameters and overcome the limitations of motion capture datasets.
SegForestNet: Spatial-Partitioning-Based Aerial Image Segmentation
Feb 03, 2023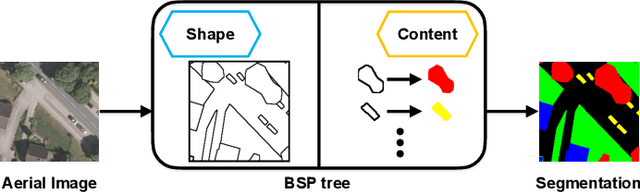

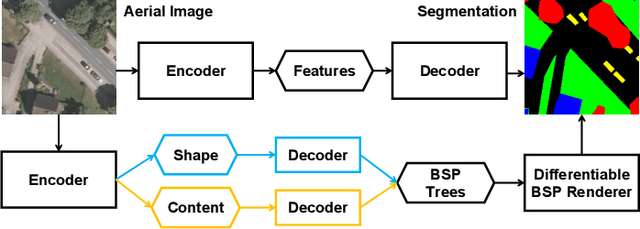
Aerial image analysis, specifically the semantic segmentation thereof, is the basis for applications such as automatically creating and updating maps, tracking city growth, or tracking deforestation. In true orthophotos, which are often used in these applications, many objects and regions can be approximated well by polygons. However, this fact is rarely exploited by state-of-the-art semantic segmentation models. Instead, most models allow unnecessary degrees of freedom in their predictions by allowing arbitrary region shapes. We therefore present a refinement of our deep learning model which predicts binary space partitioning trees, an efficient polygon representation. The refinements include a new feature decoder architecture and a new differentiable BSP tree renderer which both avoid vanishing gradients. Additionally, we designed a novel loss function specifically designed to improve the spatial partitioning defined by the predicted trees. Furthermore, our expanded model can predict multiple trees at once and thus can predict class-specific segmentations. Taking all modifications together, our model achieves state-of-the-art performance while using up to 60% fewer model parameters when using a small backbone model or up to 20% fewer model parameters when using a large backbone model.
EasyPortrait - Face Parsing and Portrait Segmentation Dataset
Apr 26, 2023
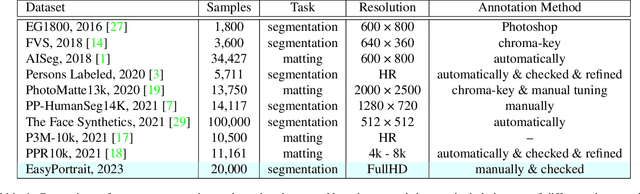
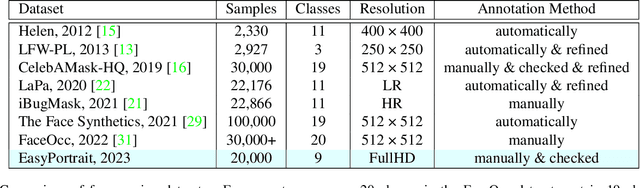

Recently, due to COVID-19 and the growing demand for remote work, video conferencing apps have become especially widespread. The most valuable features of video chats are real-time background removal and face beautification. While solving these tasks, computer vision researchers face the problem of having relevant data for the training stage. There is no large dataset with high-quality labeled and diverse images of people in front of a laptop or smartphone camera to train a lightweight model without additional approaches. To boost the progress in this area, we provide a new image dataset, EasyPortrait, for portrait segmentation and face parsing tasks. It contains 20,000 primarily indoor photos of 8,377 unique users, and fine-grained segmentation masks separated into 9 classes. Images are collected and labeled from crowdsourcing platforms. Unlike most face parsing datasets, in EasyPortrait, the beard is not considered part of the skin mask, and the inside area of the mouth is separated from the teeth. These features allow using EasyPortrait for skin enhancement and teeth whitening tasks. This paper describes the pipeline for creating a large-scale and clean image segmentation dataset using crowdsourcing platforms without additional synthetic data. Moreover, we trained several models on EasyPortrait and showed experimental results. Proposed dataset and trained models are publicly available.
Detection of Alzheimer's Disease using MRI scans based on Inertia Tensor and Machine Learning
Apr 26, 2023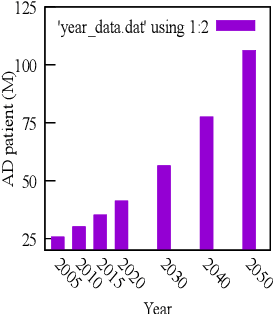
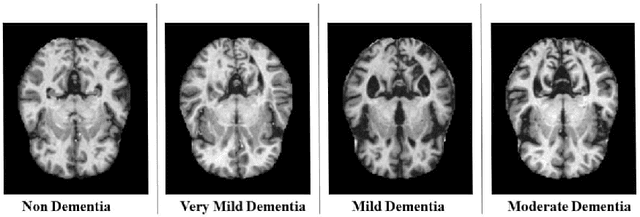
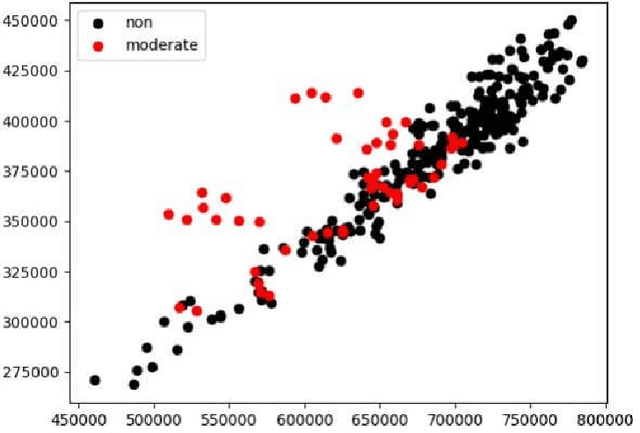
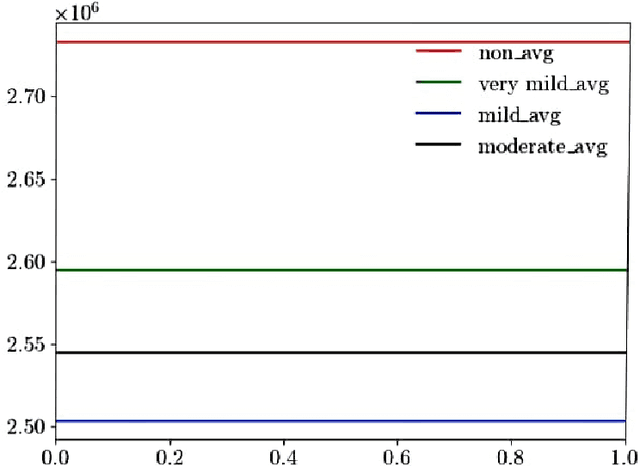
Alzheimer's Disease is a devastating neurological disorder that is increasingly affecting the elderly population. Early and accurate detection of Alzheimer's is crucial for providing effective treatment and support for patients and their families. In this study, we present a novel approach for detecting four different stages of Alzheimer's disease from MRI scan images based on inertia tensor analysis and machine learning. From each available MRI scan image for different classes of Dementia, we first compute a very simple 2 x 2 matrix, using the techniques of forming a moment of inertia tensor, which is largely used in different physical problems. Using the properties of the obtained inertia tensor and their eigenvalues, along with some other machine learning techniques, we were able to significantly classify the different types of Dementia. This process provides a new and unique approach to identifying and classifying different types of images using machine learning, with a classification accuracy of (90%) achieved. Our proposed method not only has the potential to be more cost-effective than current methods but also provides a new physical insight into the disease by reducing the dimension of the image matrix. The results of our study highlight the potential of this approach for advancing the field of Alzheimer's disease detection and improving patient outcomes.
GPT4MIA: Utilizing Geneative Pre-trained Transformer (GPT-3) as A Plug-and-Play Transductive Model for Medical Image Analysis
Feb 17, 2023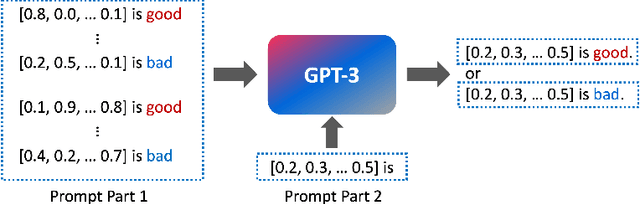
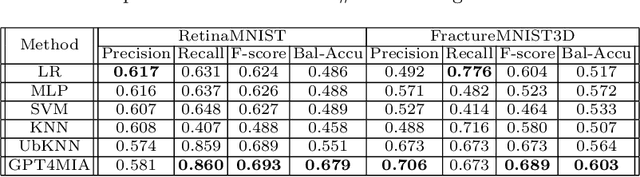
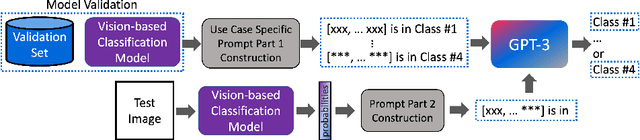
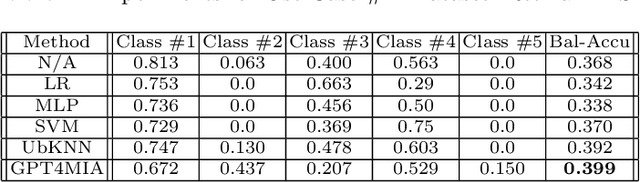
In this paper, we propose a novel approach (called GPT4MIA) that utilizes Generative Pre-trained Transformer (GPT) as a plug-and-play transductive inference tool for medical image analysis (MIA). We provide theoretical analysis on why a large pre-trained language model such as GPT-3 can be used as a plug-and-play transductive inference model for MIA. At the methodological level, we develop several technical treatments to improve the efficiency and effectiveness of GPT4MIA, including better prompt structure design, sample selection, and prompt ordering of representative samples/features. We present two concrete use cases (with workflow) of GPT4MIA: (1) detecting prediction errors and (2) improving prediction accuracy, working in conjecture with well-established vision-based models for image classification (e.g., ResNet). Experiments validate that our proposed method is effective for these two tasks. We further discuss the opportunities and challenges in utilizing Transformer-based large language models for broader MIA applications.
Evaluation of Data Augmentation and Loss Functions in Semantic Image Segmentation for Drilling Tool Wear Detection
Feb 10, 2023

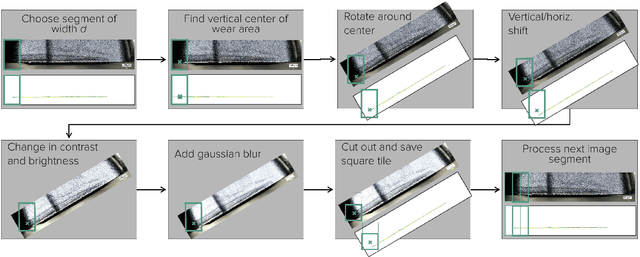
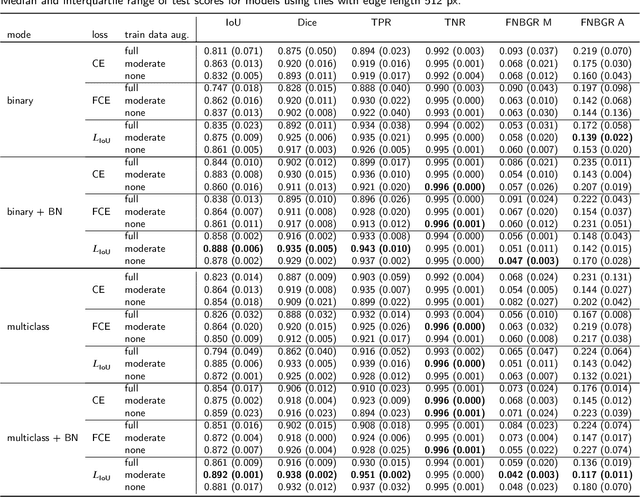
Tool wear monitoring is crucial for quality control and cost reduction in manufacturing processes, of which drilling applications are one example. In this paper, we present a U-Net based semantic image segmentation pipeline, deployed on microscopy images of cutting inserts, for the purpose of wear detection. The wear area is differentiated in two different types, resulting in a multiclass classification problem. Joining the two wear types in one general wear class, on the other hand, allows the problem to be formulated as a binary classification task. Apart from the comparison of the binary and multiclass problem, also different loss functions, i. e., Cross Entropy, Focal Cross Entropy, and a loss based on the Intersection over Union (IoU), are investigated. Furthermore, models are trained on image tiles of different sizes, and augmentation techniques of varying intensities are deployed. We find, that the best performing models are binary models, trained on data with moderate augmentation and an IoU-based loss function.