 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-Shot Object Detection via Synthetic Features with Optimal Transport
Aug 30, 2023
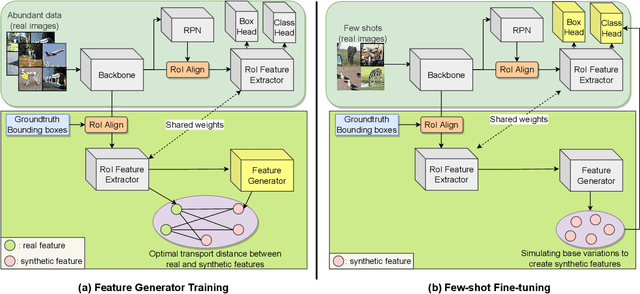
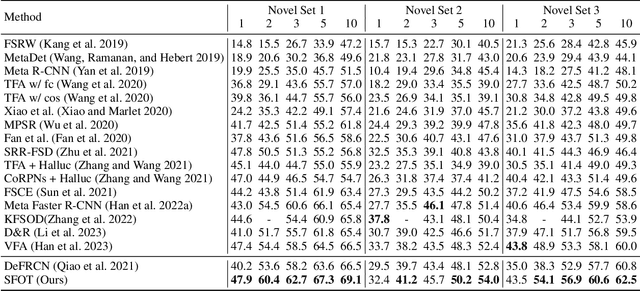
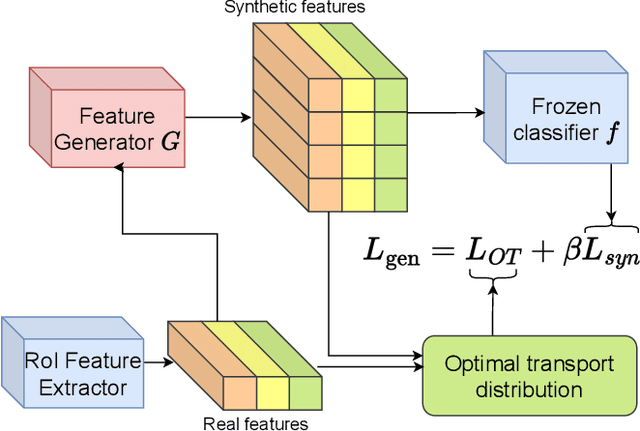
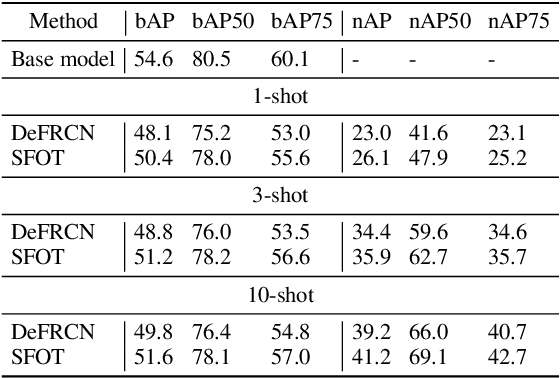
Few-shot object detection aims to simultaneously localize and classify the objects in an image with limited training samples. However, most existing few-shot object detection methods focus on extracting the features of a few samples of novel classes that lack diversity. Hence, they may not be sufficient to capture the data distribution. To address that limitation, in this paper, we propose a novel approach in which we train a generator to generate synthetic data for novel classes. Still, directly training a generator on the novel class is not effective due to the lack of novel data. To overcome that issue, we leverage the large-scale dataset of base classes. Our overarching goal is to train a generator that captures the data variations of the base dataset. We then transform the captured variations into novel classes by generating synthetic data with the trained generator. To encourage the generator to capture data variations on base classes, we propose to train the generator with an optimal transport loss that minimizes the optimal transport distance between the distributions of real and synthetic data. Extensive experiments on two benchmark datasets demonstrate that the proposed method outperforms the state of the art. Source code will be available.
AMDNet23: A combined deep Contour-based Convolutional Neural Network and Long Short Term Memory system to diagnose Age-related Macular Degeneration
Aug 30, 2023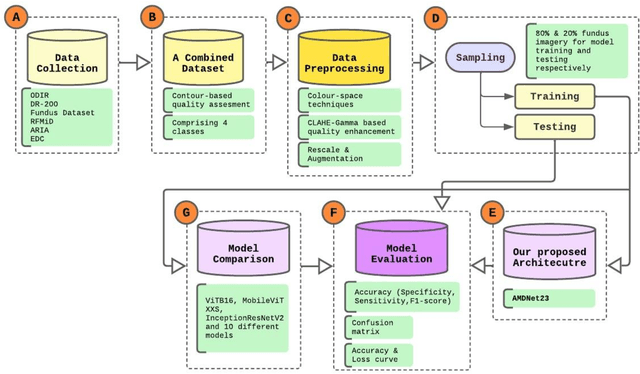
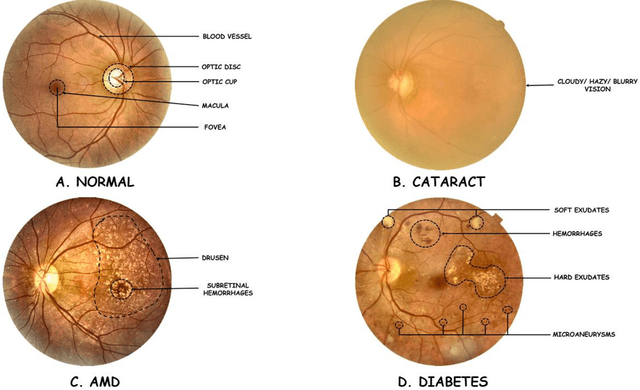
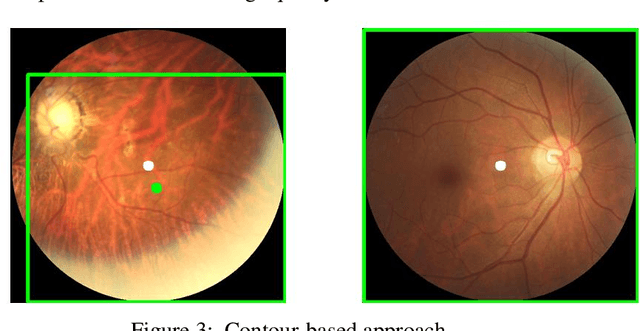
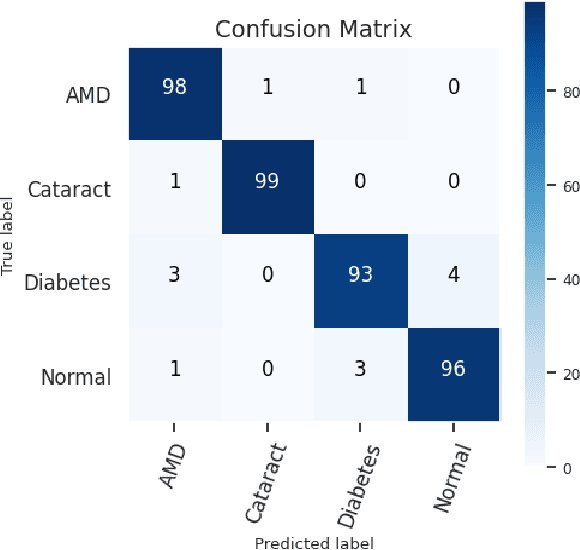
In light of the expanding population, an automated framework of disease detection can assist doctors in the diagnosis of ocular diseases, yields accurate, stable, rapid outcomes, and improves the success rate of early detection. The work initially intended the enhancing the quality of fundus images by employing an adaptive contrast enhancement algorithm (CLAHE) and Gamma correction. In the preprocessing techniques, CLAHE elevates the local contrast of the fundus image and gamma correction increases the intensity of relevant features. This study operates on a AMDNet23 system of deep learning that combined the neural networks made up of convolutions (CNN) and short-term and long-term memory (LSTM) to automatically detect aged macular degeneration (AMD) disease from fundus ophthalmology. In this mechanism, CNN is utilized for extracting features and LSTM is utilized to detect the extracted features. The dataset of this research is collected from multiple sources and afterward applied quality assessment techniques, 2000 experimental fundus images encompass four distinct classes equitably. The proposed hybrid deep AMDNet23 model demonstrates to detection of AMD ocular disease and the experimental result achieved an accuracy 96.50%, specificity 99.32%, sensitivity 96.5%, and F1-score 96.49.0%. The system achieves state-of-the-art findings on fundus imagery datasets to diagnose AMD ocular disease and findings effectively potential of our method.
ACNPU: A 4.75TOPS/W 1080P@30FPS Super Resolution Accelerator with Decoupled Asymmetric Convolution
Aug 30, 2023Deep learning-driven superresolution (SR) outperforms traditional techniques but also faces the challenge of high complexity and memory bandwidth. This challenge leads many accelerators to opt for simpler and shallow models like FSRCNN, compromising performance for real-time needs, especially for resource-limited edge devices. This paper proposes an energy-efficient SR accelerator, ACNPU, to tackle this challenge. The ACNPU enhances image quality by 0.34dB with a 27-layer model, but needs 36\% less complexity than FSRCNN, while maintaining a similar model size, with the \textit{decoupled asymmetric convolution and split-bypass structure}. The hardware-friendly 17K-parameter model enables \textit{holistic model fusion} instead of localized layer fusion to remove external DRAM access of intermediate feature maps. The on-chip memory bandwidth is further reduced with the \textit{input stationary flow} and \textit{parallel-layer execution} to reduce power consumption. Hardware is regular and easy to control to support different layers by \textit{processing elements (PEs) clusters with reconfigurable input and uniform data flow}. The implementation in the 40 nm CMOS process consumes 2333 K gate counts and 198KB SRAMs. The ACNPU achieves 31.7 FPS and 124.4 FPS for x2 and x4 scales Full-HD generation, respectively, which attains 4.75 TOPS/W energy efficiency.
LayerDiffusion: Layered Controlled Image Editing with Diffusion Models
May 30, 2023
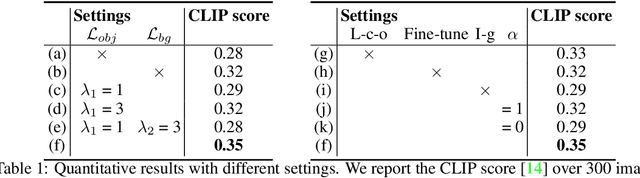
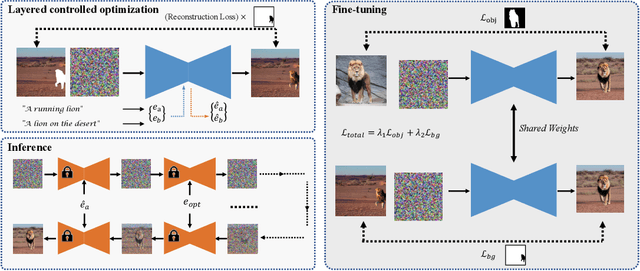

Text-guided image editing has recently experienced rapid development. However, simultaneously performing multiple editing actions on a single image, such as background replacement and specific subject attribute changes, while maintaining consistency between the subject and the background remains challenging. In this paper, we propose LayerDiffusion, a semantic-based layered controlled image editing method. Our method enables non-rigid editing and attribute modification of specific subjects while preserving their unique characteristics and seamlessly integrating them into new backgrounds. We leverage a large-scale text-to-image model and employ a layered controlled optimization strategy combined with layered diffusion training. During the diffusion process, an iterative guidance strategy is used to generate a final image that aligns with the textual description. Experimental results demonstrate the effectiveness of our method in generating highly coherent images that closely align with the given textual description. The edited images maintain a high similarity to the features of the input image and surpass the performance of current leading image editing methods. LayerDiffusion opens up new possibilities for controllable image editing.
A Novel Explainable Artificial Intelligence Model in Image Classification problem
Jul 09, 2023
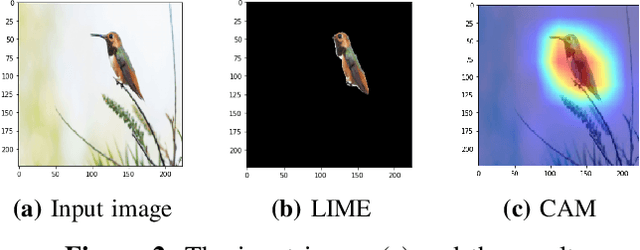
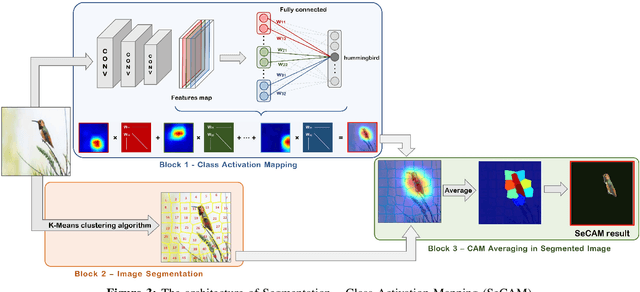
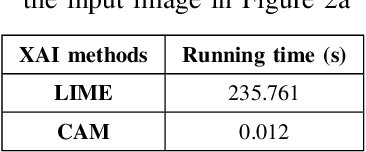
In recent years, artificial intelligence is increasingly being applied widely in many different fields and has a profound and direct impact on human life. Following this is the need to understand the principles of the model making predictions. Since most of the current high-precision models are black boxes, neither the AI scientist nor the end-user deeply understands what's going on inside these models. Therefore, many algorithms are studied for the purpose of explaining AI models, especially those in the problem of image classification in the field of computer vision such as LIME, CAM, GradCAM. However, these algorithms still have limitations such as LIME's long execution time and CAM's confusing interpretation of concreteness and clarity. Therefore, in this paper, we propose a new method called Segmentation - Class Activation Mapping (SeCAM) that combines the advantages of these algorithms above, while at the same time overcoming their disadvantages. We tested this algorithm with various models, including ResNet50, Inception-v3, VGG16 from ImageNet Large Scale Visual Recognition Challenge (ILSVRC) data set. Outstanding results when the algorithm has met all the requirements for a specific explanation in a remarkably concise time.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023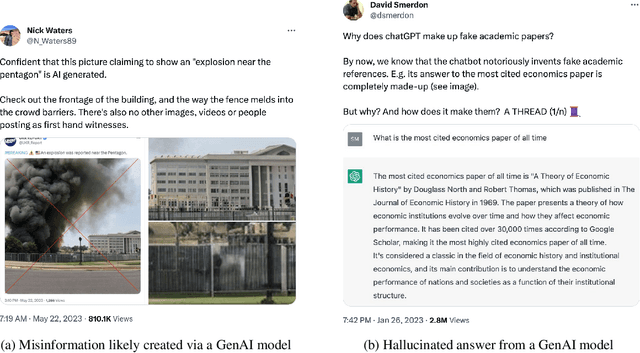
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
360-Degree Panorama Generation from Few Unregistered NFoV Images
Aug 28, 2023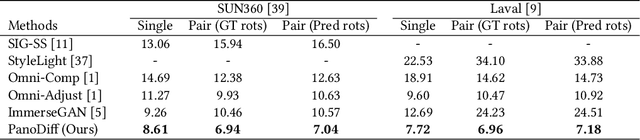
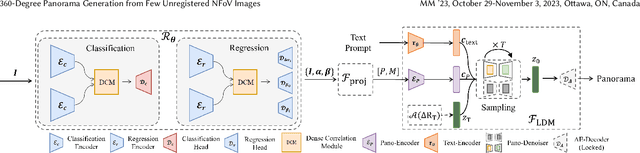
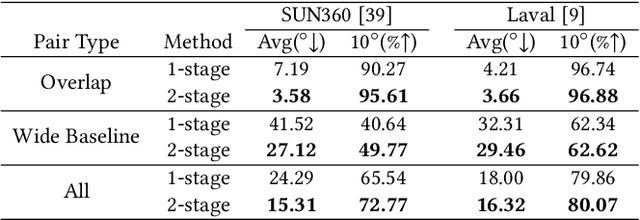
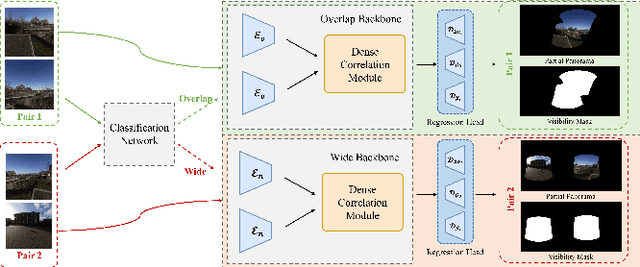
360$^\circ$ panoramas are extensively utilized as environmental light sources in computer graphics. However, capturing a 360$^\circ$ $\times$ 180$^\circ$ panorama poses challenges due to the necessity of specialized and costly equipment, and additional human resources. Prior studies develop various learning-based generative methods to synthesize panoramas from a single Narrow Field-of-View (NFoV) image, but they are limited in alterable input patterns, generation quality, and controllability. To address these issues, we propose a novel pipeline called PanoDiff, which efficiently generates complete 360$^\circ$ panoramas using one or more unregistered NFoV images captured from arbitrary angles. Our approach has two primary components to overcome the limitations. Firstly, a two-stage angle prediction module to handle various numbers of NFoV inputs. Secondly, a novel latent diffusion-based panorama generation model uses incomplete panorama and text prompts as control signals and utilizes several geometric augmentation schemes to ensure geometric properties in generated panoramas. Experiments show that PanoDiff achieves state-of-the-art panoramic generation quality and high controllability, making it suitable for applications such as content editing.
Energy-Based Cross Attention for Bayesian Context Update in Text-to-Image Diffusion Models
Jun 16, 2023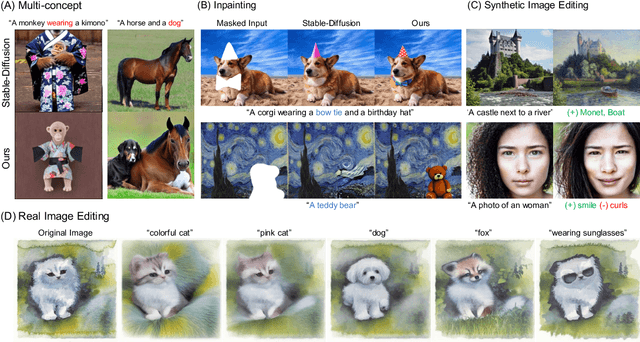
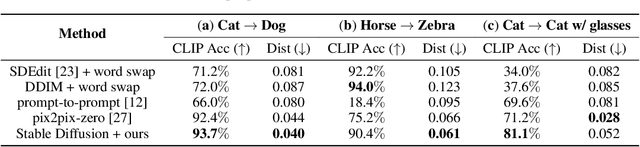
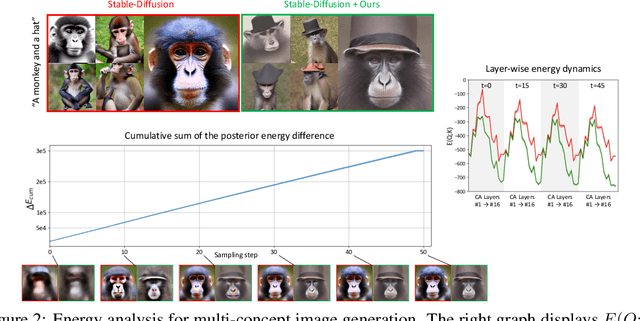

Despite the remarkable performance of text-to-image diffusion models in image generation tasks, recent studies have raised the issue that generated images sometimes cannot capture the intended semantic contents of the text prompts, which phenomenon is often called semantic misalignment. To address this, here we present a novel energy-based model (EBM) framework. Specifically, we first formulate EBMs of latent image representations and text embeddings in each cross-attention layer of the denoising autoencoder. Then, we obtain the gradient of the log posterior of context vectors, which can be updated and transferred to the subsequent cross-attention layer, thereby implicitly minimizing a nested hierarchy of energy functions. Our latent EBMs further allow zero-shot compositional generation as a linear combination of cross-attention outputs from different contexts. Using extensive experiments, we demonstrate that the proposed method is highly effective in handling various image generation tasks, including multi-concept generation, text-guided image inpainting, and real and synthetic image editing.
Towards High-Frequency Tracking and Fast Edge-Aware Optimization
Sep 02, 2023This dissertation advances the state of the art for AR/VR tracking systems by increasing the tracking frequency by orders of magnitude and proposes an efficient algorithm for the problem of edge-aware optimization. AR/VR is a natural way of interacting with computers, where the physical and digital worlds coexist. We are on the cusp of a radical change in how humans perform and interact with computing. Humans are sensitive to small misalignments between the real and the virtual world, and tracking at kilo-Hertz frequencies becomes essential. Current vision-based systems fall short, as their tracking frequency is implicitly limited by the frame-rate of the camera. This thesis presents a prototype system which can track at orders of magnitude higher than the state-of-the-art methods using multiple commodity cameras. The proposed system exploits characteristics of the camera traditionally considered as flaws, namely rolling shutter and radial distortion. The experimental evaluation shows the effectiveness of the method for various degrees of motion. Furthermore, edge-aware optimization is an indispensable tool in the computer vision arsenal for accurate filtering of depth-data and image-based rendering, which is increasingly being used for content creation and geometry processing for AR/VR. As applications increasingly demand higher resolution and speed, there exists a need to develop methods that scale accordingly. This dissertation proposes such an edge-aware optimization framework which is efficient, accurate, and algorithmically scales well, all of which are much desirable traits not found jointly in the state of the art. The experiments show the effectiveness of the framework in a multitude of computer vision tasks such as computational photography and stereo.
Enhancing Landmark Detection in Cluttered Real-World Scenarios with Vision Transformers
Aug 25, 2023
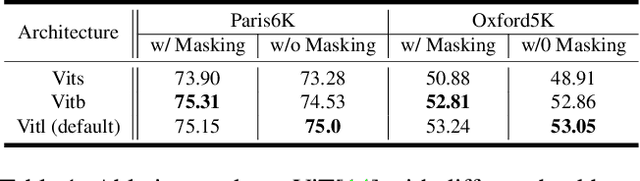
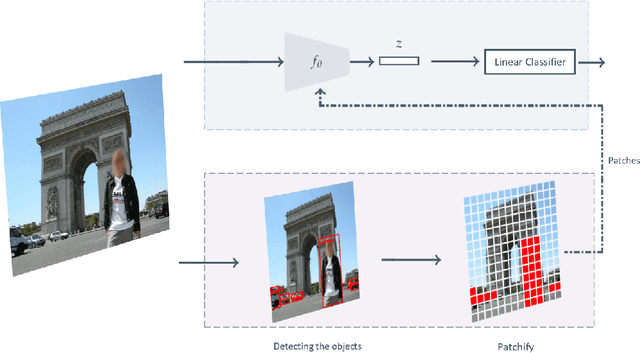

Visual place recognition tasks often encounter significant challenges in landmark detection due to the presence of irrelevant objects such as humans, cars, and trees, despite the remarkable progress achieved by previous models, especially in the context of transformers. To address this issue, we propose a novel method that effectively leverages the strengths of vision transformers. By employing a meticulous selection process, our approach identifies and isolates specific patches within the image that correspond to occluding objects. To evaluate the efficacy of our method, we created augmented datasets and conducted comprehensive testing. The results demonstrate the superior accuracy achieved by our proposed approach. This research contributes to the advancement of landmark detection in visual place recognition and shows the potential of leveraging vision transformers to overcome challenges posed by cluttered real-world scenarios.