 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Text Classification
Multilingual text classification is the process of categorizing text documents in multiple languages into predefined categories.
Papers and Code
On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey
Jul 28, 2025Text embeddings have attracted growing interest due to their effectiveness across a wide range of natural language processing (NLP) tasks, such as retrieval, classification, clustering, bitext mining, and summarization. With the emergence of pretrained language models (PLMs), general-purpose text embeddings (GPTE) have gained significant traction for their ability to produce rich, transferable representations. The general architecture of GPTE typically leverages PLMs to derive dense text representations, which are then optimized through contrastive learning on large-scale pairwise datasets. In this survey, we provide a comprehensive overview of GPTE in the era of PLMs, focusing on the roles PLMs play in driving its development. We first examine the fundamental architecture and describe the basic roles of PLMs in GPTE, i.e., embedding extraction, expressivity enhancement, training strategies, learning objectives, and data construction. Then, we describe advanced roles enabled by PLMs, such as multilingual support, multimodal integration, code understanding, and scenario-specific adaptation. Finally, we highlight potential future research directions that move beyond traditional improvement goals, including ranking integration, safety considerations, bias mitigation, structural information incorporation, and the cognitive extension of embeddings. This survey aims to serve as a valuable reference for both newcomers and established researchers seeking to understand the current state and future potential of GPTE.
GLAP: General contrastive audio-text pretraining across domains and languages
Jun 12, 2025



Contrastive Language Audio Pretraining (CLAP) is a widely-used method to bridge the gap between audio and text domains. Current CLAP methods enable sound and music retrieval in English, ignoring multilingual spoken content. To address this, we introduce general language audio pretraining (GLAP), which expands CLAP with multilingual and multi-domain abilities. GLAP demonstrates its versatility by achieving competitive performance on standard audio-text retrieval benchmarks like Clotho and AudioCaps, while significantly surpassing existing methods in speech retrieval and classification tasks. Additionally, GLAP achieves strong results on widely used sound-event zero-shot benchmarks, while simultaneously outperforming previous methods on speech content benchmarks. Further keyword spotting evaluations across 50 languages emphasize GLAP's advanced multilingual capabilities. Finally, multilingual sound and music understanding is evaluated across four languages. Checkpoints and Source: https://github.com/xiaomi-research/dasheng-glap.
NLPnorth @ TalentCLEF 2025: Comparing Discriminative, Contrastive, and Prompt-Based Methods for Job Title and Skill Matching
Jun 23, 2025Matching job titles is a highly relevant task in the computational job market domain, as it improves e.g., automatic candidate matching, career path prediction, and job market analysis. Furthermore, aligning job titles to job skills can be considered an extension to this task, with similar relevance for the same downstream tasks. In this report, we outline NLPnorth's submission to TalentCLEF 2025, which includes both of these tasks: Multilingual Job Title Matching, and Job Title-Based Skill Prediction. For both tasks we compare (fine-tuned) classification-based, (fine-tuned) contrastive-based, and prompting methods. We observe that for Task A, our prompting approach performs best with an average of 0.492 mean average precision (MAP) on test data, averaged over English, Spanish, and German. For Task B, we obtain an MAP of 0.290 on test data with our fine-tuned classification-based approach. Additionally, we made use of extra data by pulling all the language-specific titles and corresponding \emph{descriptions} from ESCO for each job and skill. Overall, we find that the largest multilingual language models perform best for both tasks. Per the provisional results and only counting the unique teams, the ranking on Task A is 5$^{\text{th}}$/20 and for Task B 3$^{\text{rd}}$/14.
MFTCXplain: A Multilingual Benchmark Dataset for Evaluating the Moral Reasoning of LLMs through Hate Speech Multi-hop Explanation
Jun 23, 2025Ensuring the moral reasoning capabilities of Large Language Models (LLMs) is a growing concern as these systems are used in socially sensitive tasks. Nevertheless, current evaluation benchmarks present two major shortcomings: a lack of annotations that justify moral classifications, which limits transparency and interpretability; and a predominant focus on English, which constrains the assessment of moral reasoning across diverse cultural settings. In this paper, we introduce MFTCXplain, a multilingual benchmark dataset for evaluating the moral reasoning of LLMs via hate speech multi-hop explanation using Moral Foundation Theory (MFT). The dataset comprises 3,000 tweets across Portuguese, Italian, Persian, and English, annotated with binary hate speech labels, moral categories, and text span-level rationales. Empirical results highlight a misalignment between LLM outputs and human annotations in moral reasoning tasks. While LLMs perform well in hate speech detection (F1 up to 0.836), their ability to predict moral sentiments is notably weak (F1 < 0.35). Furthermore, rationale alignment remains limited mainly in underrepresented languages. These findings show the limited capacity of current LLMs to internalize and reflect human moral reasoning.
Multimodal Zero-Shot Framework for Deepfake Hate Speech Detection in Low-Resource Languages
Jun 10, 2025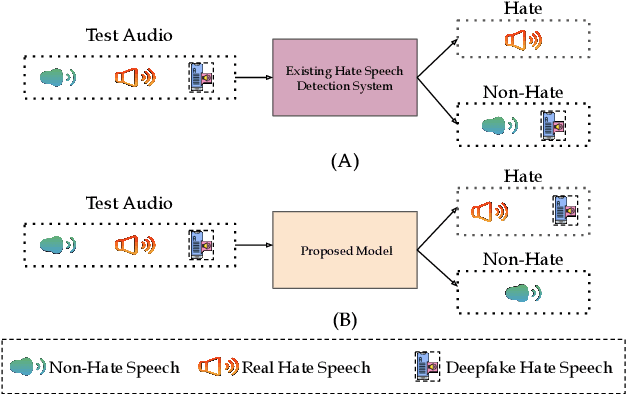
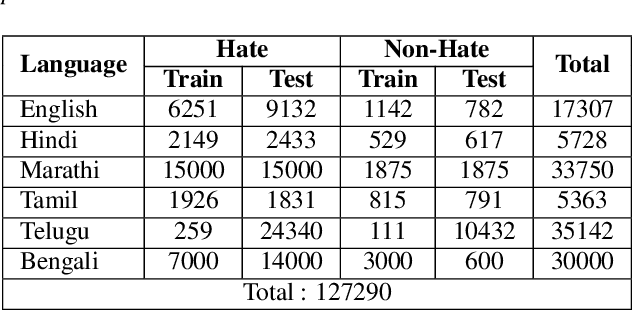
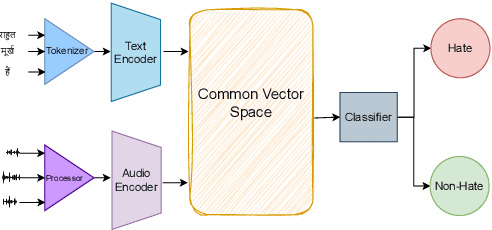
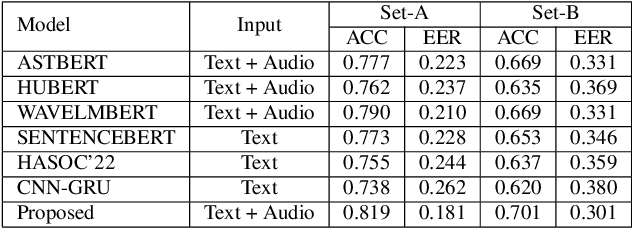
This paper introduces a novel multimodal framework for hate speech detection in deepfake audio, excelling even in zero-shot scenarios. Unlike previous approaches, our method uses contrastive learning to jointly align audio and text representations across languages. We present the first benchmark dataset with 127,290 paired text and synthesized speech samples in six languages: English and five low-resource Indian languages (Hindi, Bengali, Marathi, Tamil, Telugu). Our model learns a shared semantic embedding space, enabling robust cross-lingual and cross-modal classification. Experiments on two multilingual test sets show our approach outperforms baselines, achieving accuracies of 0.819 and 0.701, and generalizes well to unseen languages. This demonstrates the advantage of combining modalities for hate speech detection in synthetic media, especially in low-resource settings where unimodal models falter. The Dataset is available at https://www.iab-rubric.org/resources.
MMAFFBen: A Multilingual and Multimodal Affective Analysis Benchmark for Evaluating LLMs and VLMs
May 30, 2025



Large language models and vision-language models (which we jointly call LMs) have transformed NLP and CV, demonstrating remarkable potential across various fields. However, their capabilities in affective analysis (i.e. sentiment analysis and emotion detection) remain underexplored. This gap is largely due to the absence of comprehensive evaluation benchmarks, and the inherent complexity of affective analysis tasks. In this paper, we introduce MMAFFBen, the first extensive open-source benchmark for multilingual multimodal affective analysis. MMAFFBen encompasses text, image, and video modalities across 35 languages, covering four key affective analysis tasks: sentiment polarity, sentiment intensity, emotion classification, and emotion intensity. Moreover, we construct the MMAFFIn dataset for fine-tuning LMs on affective analysis tasks, and further develop MMAFFLM-3b and MMAFFLM-7b based on it. We evaluate various representative LMs, including GPT-4o-mini, providing a systematic comparison of their affective understanding capabilities. This project is available at https://github.com/lzw108/MMAFFBen.
mSTEB: Massively Multilingual Evaluation of LLMs on Speech and Text Tasks
Jun 10, 2025Large Language models (LLMs) have demonstrated impressive performance on a wide range of tasks, including in multimodal settings such as speech. However, their evaluation is often limited to English and a few high-resource languages. For low-resource languages, there is no standardized evaluation benchmark. In this paper, we address this gap by introducing mSTEB, a new benchmark to evaluate the performance of LLMs on a wide range of tasks covering language identification, text classification, question answering, and translation tasks on both speech and text modalities. We evaluated the performance of leading LLMs such as Gemini 2.0 Flash and GPT-4o (Audio) and state-of-the-art open models such as Qwen 2 Audio and Gemma 3 27B. Our evaluation shows a wide gap in performance between high-resource and low-resource languages, especially for languages spoken in Africa and Americas/Oceania. Our findings show that more investment is needed to address their under-representation in LLMs coverage.
JNLP at SemEval-2025 Task 11: Cross-Lingual Multi-Label Emotion Detection Using Generative Models
May 19, 2025With the rapid advancement of global digitalization, users from different countries increasingly rely on social media for information exchange. In this context, multilingual multi-label emotion detection has emerged as a critical research area. This study addresses SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection. Our paper focuses on two sub-tracks of this task: (1) Track A: Multi-label emotion detection, and (2) Track B: Emotion intensity. To tackle multilingual challenges, we leverage pre-trained multilingual models and focus on two architectures: (1) a fine-tuned BERT-based classification model and (2) an instruction-tuned generative LLM. Additionally, we propose two methods for handling multi-label classification: the base method, which maps an input directly to all its corresponding emotion labels, and the pairwise method, which models the relationship between the input text and each emotion category individually. Experimental results demonstrate the strong generalization ability of our approach in multilingual emotion recognition. In Track A, our method achieved Top 4 performance across 10 languages, ranking 1st in Hindi. In Track B, our approach also secured Top 5 performance in 7 languages, highlighting its simplicity and effectiveness\footnote{Our code is available at https://github.com/yingjie7/mlingual_multilabel_emo_detection.
OMNIGUARD: An Efficient Approach for AI Safety Moderation Across Modalities
May 29, 2025



The emerging capabilities of large language models (LLMs) have sparked concerns about their immediate potential for harmful misuse. The core approach to mitigate these concerns is the detection of harmful queries to the model. Current detection approaches are fallible, and are particularly susceptible to attacks that exploit mismatched generalization of model capabilities (e.g., prompts in low-resource languages or prompts provided in non-text modalities such as image and audio). To tackle this challenge, we propose OMNIGUARD, an approach for detecting harmful prompts across languages and modalities. Our approach (i) identifies internal representations of an LLM/MLLM that are aligned across languages or modalities and then (ii) uses them to build a language-agnostic or modality-agnostic classifier for detecting harmful prompts. OMNIGUARD improves harmful prompt classification accuracy by 11.57\% over the strongest baseline in a multilingual setting, by 20.44\% for image-based prompts, and sets a new SOTA for audio-based prompts. By repurposing embeddings computed during generation, OMNIGUARD is also very efficient ($\approx 120 \times$ faster than the next fastest baseline). Code and data are available at: https://github.com/vsahil/OmniGuard.
Low-Resource Language Processing: An OCR-Driven Summarization and Translation Pipeline
May 16, 2025This paper presents an end-to-end suite for multilingual information extraction and processing from image-based documents. The system uses Optical Character Recognition (Tesseract) to extract text in languages such as English, Hindi, and Tamil, and then a pipeline involving large language model APIs (Gemini) for cross-lingual translation, abstractive summarization, and re-translation into a target language. Additional modules add sentiment analysis (TensorFlow), topic classification (Transformers), and date extraction (Regex) for better document comprehension. Made available in an accessible Gradio interface, the current research shows a real-world application of libraries, models, and APIs to close the language gap and enhance access to information in image media across different linguistic environments