 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWolof Speech Recognition
Papers and Code
Speech Language Models for Under-Represented Languages: Insights from Wolof
Sep 18, 2025We present our journey in training a speech language model for Wolof, an underrepresented language spoken in West Africa, and share key insights. We first emphasize the importance of collecting large-scale, spontaneous, high-quality speech data, and show that continued pretraining HuBERT on this dataset outperforms both the base model and African-centric models on ASR. We then integrate this speech encoder into a Wolof LLM to train the first Speech LLM for this language, extending its capabilities to tasks such as speech translation. Furthermore, we explore training the Speech LLM to perform multi-step Chain-of-Thought before transcribing or translating. Our results show that the Speech LLM not only improves speech recognition but also performs well in speech translation. The models and the code will be openly shared.
Kallaama: A Transcribed Speech Dataset about Agriculture in the Three Most Widely Spoken Languages in Senegal
Apr 02, 2024This work is part of the Kallaama project, whose objective is to produce and disseminate national languages corpora for speech technologies developments, in the field of agriculture. Except for Wolof, which benefits from some language data for natural language processing, national languages of Senegal are largely ignored by language technology providers. However, such technologies are keys to the protection, promotion and teaching of these languages. Kallaama focuses on the 3 main spoken languages by Senegalese people: Wolof, Pulaar and Sereer. These languages are widely spoken by the population, with around 10 million of native Senegalese speakers, not to mention those outside the country. However, they remain under-resourced in terms of machine-readable data that can be used for automatic processing and language technologies, all the more so in the agricultural sector. We release a transcribed speech dataset containing 125 hours of recordings, about agriculture, in each of the above-mentioned languages. These resources are specifically designed for Automatic Speech Recognition purpose, including traditional approaches. To build such technologies, we provide textual corpora in Wolof and Pulaar, and a pronunciation lexicon containing 49,132 entries from the Wolof dataset.
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023



We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
Fast Development of ASR in African Languages using Self Supervised Speech Representation Learning
Mar 16, 2021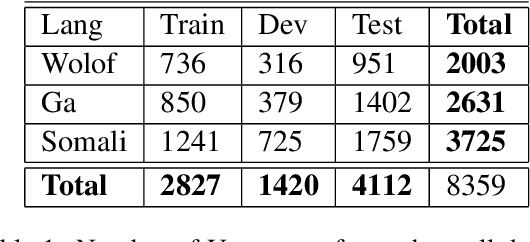
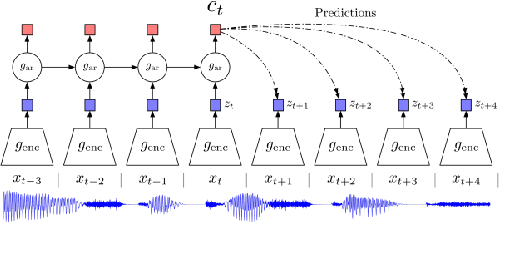
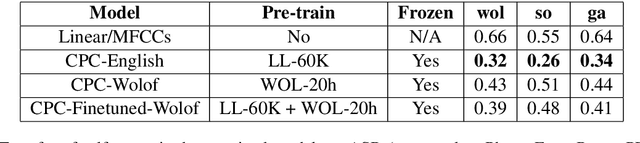
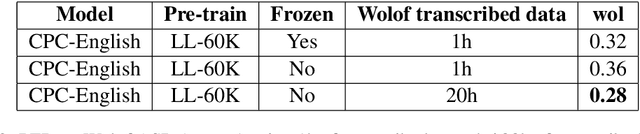
This paper describes the results of an informal collaboration launched during the African Master of Machine Intelligence (AMMI) in June 2020. After a series of lectures and labs on speech data collection using mobile applications and on self-supervised representation learning from speech, a small group of students and the lecturer continued working on automatic speech recognition (ASR) project for three languages: Wolof, Ga, and Somali. This paper describes how data was collected and ASR systems developed with a small amount (1h) of transcribed speech as training data. In these low resource conditions, pre-training a model on large amounts of raw speech was fundamental for the efficiency of ASR systems developed.
Parameter Space Factorization for Zero-Shot Learning across Tasks and Languages
Jan 30, 2020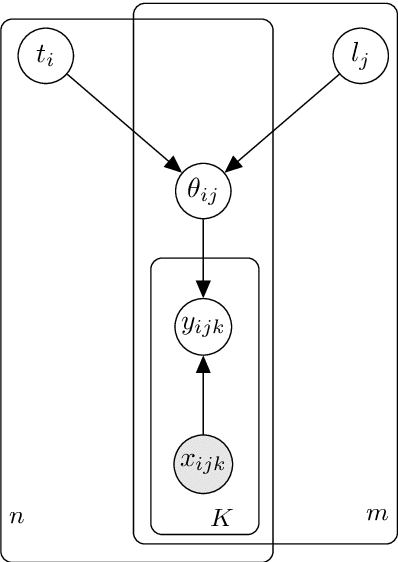

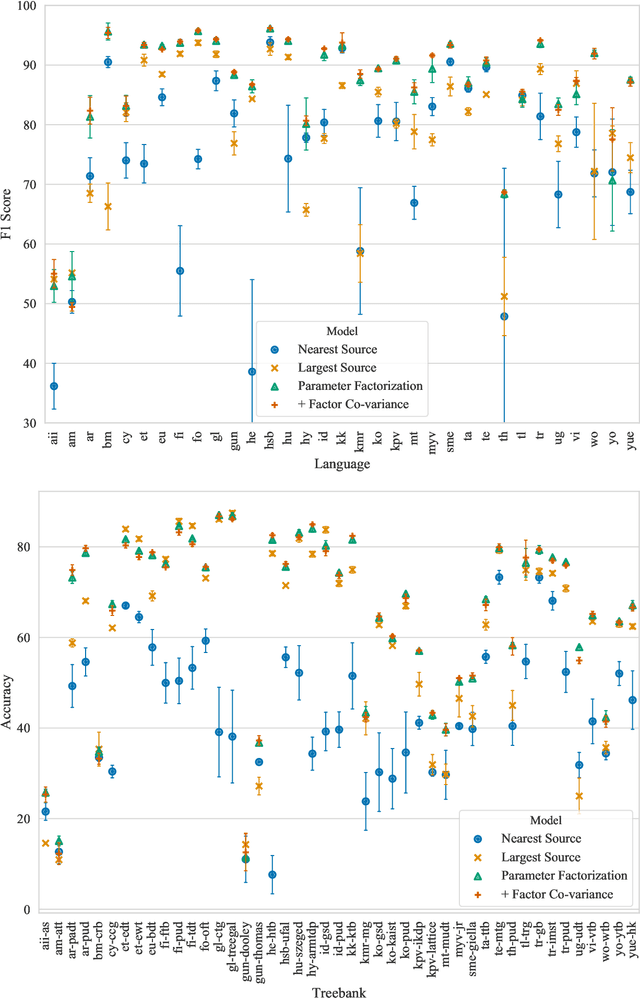
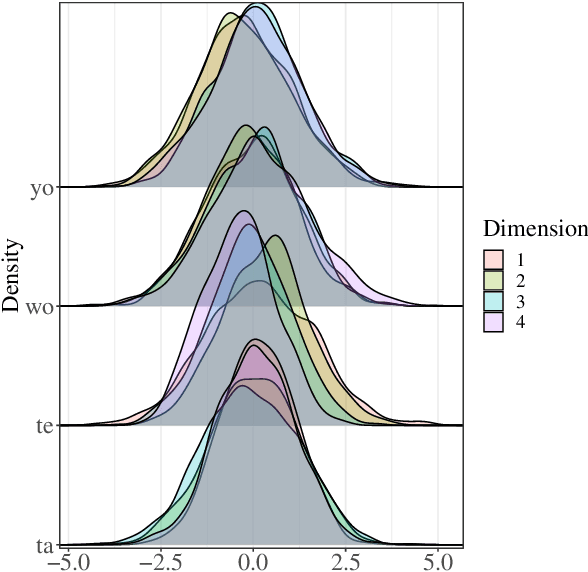
Most combinations of NLP tasks and language varieties lack in-domain examples for supervised training because of the paucity of annotated data. How can neural models make sample-efficient generalizations from task-language combinations with available data to low-resource ones? In this work, we propose a Bayesian generative model for the space of neural parameters. We assume that this space can be factorized into latent variables for each language and each task. We infer the posteriors over such latent variables based on data from seen task-language combinations through variational inference. This enables zero-shot classification on unseen combinations at prediction time. For instance, given training data for named entity recognition (NER) in Vietnamese and for part-of-speech (POS) tagging in Wolof, our model can perform accurate predictions for NER in Wolof. In particular, we experiment with a typologically diverse sample of 33 languages from 4 continents and 11 families, and show that our model yields comparable or better results than state-of-the-art, zero-shot cross-lingual transfer methods; it increases performance by 4.49 points for POS tagging and 7.73 points for NER on average compared to the strongest baseline.