 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindows Pe Malware
Papers and Code
FARM: Few-shot Adaptive Malware Family Classification under Concept Drift
Jan 25, 2026Malware classification models often face performance degradation due to concept drift, arising from evolving threat landscapes and the emergence of novel malware families. This paper presents FARM (Few-shot Adaptive Recognition of Malware), a framework designed to detect and adapt to both covariate and label drift in Windows Portable Executable (PE) malware classification. FARM leverages a triplet autoencoder to project samples into a discriminative latent space, enabling unsupervised drift detection via DBSCAN clustering and dynamic thresholding. For rapid adaptation, it employs few-shot learning using prototype-based classification, requiring only a handful of labeled samples. FARM also supports full retraining when enough drifted samples accumulate, updating the latent space for long-term integration. Experiments on the BenchMFC dataset demonstrate that FARM improves classification performance under covariate drift by 5.6\%, and achieves an average F1 score of 0.85 on unseen malware families using only few-shot adaptation, which further increases to 0.94 after retraining. These results highlight FARM's robustness and adaptability in dynamic malware detection environments under limited supervision.
Enhancing Decision-Making in Windows PE Malware Classification During Dataset Shifts with Uncertainty Estimation
Dec 20, 2025Artificial intelligence techniques have achieved strong performance in classifying Windows Portable Executable (PE) malware, but their reliability often degrades under dataset shifts, leading to misclassifications with severe security consequences. To address this, we enhance an existing LightGBM (LGBM) malware detector by integrating Neural Networks (NN), PriorNet, and Neural Network Ensembles, evaluated across three benchmark datasets: EMBER, BODMAS, and UCSB. The UCSB dataset, composed mainly of packed malware, introduces a substantial distributional shift relative to EMBER and BODMAS, making it a challenging testbed for robustness. We study uncertainty-aware decision strategies, including probability thresholding, PriorNet, ensemble-derived estimates, and Inductive Conformal Evaluation (ICE). Our main contribution is the use of ensemble-based uncertainty estimates as Non-Conformity Measures within ICE, combined with a novel threshold optimisation method. On the UCSB dataset, where the shift is most severe, the state-of-the-art probability-based ICE (SOTA) yields an incorrect acceptance rate (IA%) of 22.8%. In contrast, our method reduces this to 16% a relative reduction of about 30% while maintaining competitive correct acceptance rates (CA%). These results demonstrate that integrating ensemble-based uncertainty with conformal prediction provides a more reliable safeguard against misclassifications under extreme dataset shifts, particularly in the presence of packed malware, thereby offering practical benefits for real-world security operations.
* 20 pages
Dynamic Malware Classification of Windows PE Files using CNNs and Greyscale Images Derived from Runtime API Call Argument Conversion
May 30, 2025



Malware detection and classification remains a topic of concern for cybersecurity, since it is becoming common for attackers to use advanced obfuscation on their malware to stay undetected. Conventional static analysis is not effective against polymorphic and metamorphic malware as these change their appearance without modifying their behavior, thus defying the analysis by code structure alone. This makes it important to use dynamic detection that monitors malware behavior at runtime. In this paper, we present a dynamic malware categorization framework that extracts API argument calls at the runtime execution of Windows Portable Executable (PE) files. Extracting and encoding the dynamic features of API names, argument return values, and other relative features, we convert raw behavioral data to temporal patterns. To enhance feature portrayal, the generated patterns are subsequently converted into grayscale pictures using a magma colormap. These improved photos are used to teach a Convolutional Neural Network (CNN) model discriminative features, which allows for reliable and accurate malware classification. Results from experiments indicate that our method, with an average accuracy of 98.36% is effective in classifying different classes of malware and benign by integrating dynamic analysis and deep learning. It not only achieves high classification accuracy but also demonstrates significant resilience against typical evasion strategies.
Multimodal Techniques for Malware Classification
Jan 19, 2025



The threat of malware is a serious concern for computer networks and systems, highlighting the need for accurate classification techniques. In this research, we experiment with multimodal machine learning approaches for malware classification, based on the structured nature of the Windows Portable Executable (PE) file format. Specifically, we train Support Vector Machine (SVM), Long Short-Term Memory (LSTM), and Convolutional Neural Network (CNN) models on features extracted from PE headers, we train these same models on features extracted from the other sections of PE files, and train each model on features extracted from the entire PE file. We then train SVM models on each of the nine header-sections combinations of these baseline models, using the output layer probabilities of the component models as feature vectors. We compare the baseline cases to these multimodal combinations. In our experiments, we find that the best of the multimodal models outperforms the best of the baseline cases, indicating that it can be advantageous to train separate models on distinct parts of Windows PE files.
On the Effectiveness of Adversarial Samples against Ensemble Learning-based Windows PE Malware Detectors
Sep 25, 2023



Recently, there has been a growing focus and interest in applying machine learning (ML) to the field of cybersecurity, particularly in malware detection and prevention. Several research works on malware analysis have been proposed, offering promising results for both academic and practical applications. In these works, the use of Generative Adversarial Networks (GANs) or Reinforcement Learning (RL) can aid malware creators in crafting metamorphic malware that evades antivirus software. In this study, we propose a mutation system to counteract ensemble learning-based detectors by combining GANs and an RL model, overcoming the limitations of the MalGAN model. Our proposed FeaGAN model is built based on MalGAN by incorporating an RL model called the Deep Q-network anti-malware Engines Attacking Framework (DQEAF). The RL model addresses three key challenges in performing adversarial attacks on Windows Portable Executable malware, including format preservation, executability preservation, and maliciousness preservation. In the FeaGAN model, ensemble learning is utilized to enhance the malware detector's evasion ability, with the generated adversarial patterns. The experimental results demonstrate that 100\% of the selected mutant samples preserve the format of executable files, while certain successes in both executability preservation and maliciousness preservation are achieved, reaching a stable success rate.
Assemblage: Automatic Binary Dataset Construction for Machine Learning
May 07, 2024



Binary code is pervasive, and binary analysis is a key task in reverse engineering, malware classification, and vulnerability discovery. Unfortunately, while there exist large corpuses of malicious binaries, obtaining high-quality corpuses of benign binaries for modern systems has proven challenging (e.g., due to licensing issues). Consequently, machine learning based pipelines for binary analysis utilize either costly commercial corpuses (e.g., VirusTotal) or open-source binaries (e.g., coreutils) available in limited quantities. To address these issues, we present Assemblage: an extensible cloud-based distributed system that crawls, configures, and builds Windows PE binaries to obtain high-quality binary corpuses suitable for training state-of-the-art models in binary analysis. We have run Assemblage on AWS over the past year, producing 890k Windows PE and 428k Linux ELF binaries across 29 configurations. Assemblage is designed to be both reproducible and extensible, enabling users to publish "recipes" for their datasets, and facilitating the extraction of a wide array of features. We evaluated Assemblage by using its data to train modern learning-based pipelines for compiler provenance and binary function similarity. Our results illustrate the practical need for robust corpuses of high-quality Windows PE binaries in training modern learning-based binary analyses. Assemblage can be downloaded from https://assemblage-dataset.net
A Survey on Cross-Architectural IoT Malware Threat Hunting
Jun 09, 2023



In recent years, the increase in non-Windows malware threats had turned the focus of the cybersecurity community. Research works on hunting Windows PE-based malwares are maturing, whereas the developments on Linux malware threat hunting are relatively scarce. With the advent of the Internet of Things (IoT) era, smart devices that are getting integrated into human life have become a hackers highway for their malicious activities. The IoT devices employ various Unix-based architectures that follow ELF (Executable and Linkable Format) as their standard binary file specification. This study aims at providing a comprehensive survey on the latest developments in cross-architectural IoT malware detection and classification approaches. Aided by a modern taxonomy, we discuss the feature representations, feature extraction techniques, and machine learning models employed in the surveyed works. We further provide more insights on the practical challenges involved in cross-architectural IoT malware threat hunting and discuss various avenues to instill potential future research.
* https://ieeexplore.ieee.org/abstract/document/9462110
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version)
Feb 02, 2024



Machine learning (ML) plays a pivotal role in detecting malicious software. Despite the high F1-scores reported in numerous studies reaching upwards of 0.99, the issue is not completely solved. Malware detectors often experience performance decay due to constantly evolving operating systems and attack methods, which can render previously learned knowledge insufficient for accurate decision-making on new inputs. This paper argues that commonly reported results are inflated due to two pervasive sources of experimental bias in the detection task: spatial bias caused by data distributions that are not representative of a real-world deployment; and temporal bias caused by incorrect time splits of data, leading to unrealistic configurations. To address these biases, we introduce a set of constraints for fair experiment design, and propose a new metric, AUT, for classifier robustness in real-world settings. We additionally propose an algorithm designed to tune training data to enhance classifier performance. Finally, we present TESSERACT, an open-source framework for realistic classifier comparison. Our evaluation encompasses both traditional ML and deep learning methods, examining published works on an extensive Android dataset with 259,230 samples over a five-year span. Additionally, we conduct case studies in the Windows PE and PDF domains. Our findings identify the existence of biases in previous studies and reveal that significant performance enhancements are possible through appropriate, periodic tuning. We explore how mitigation strategies may support in achieving a more stable and better performance over time by employing multiple strategies to delay performance decay.
Instance Attack:An Explanation-based Vulnerability Analysis Framework Against DNNs for Malware Detection
Sep 06, 2022

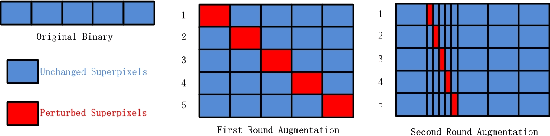
Deep neural networks (DNNs) are increasingly being applied in malware detection and their robustness has been widely debated. Traditionally an adversarial example generation scheme relies on either detailed model information (gradient-based methods) or lots of samples to train a surrogate model, neither of which are available in most scenarios. We propose the notion of the instance-based attack. Our scheme is interpretable and can work in a black-box environment. Given a specific binary example and a malware classifier, we use the data augmentation strategies to produce enough data from which we can train a simple interpretable model. We explain the detection model by displaying the weight of different parts of the specific binary. By analyzing the explanations, we found that the data subsections play an important role in Windows PE malware detection. We proposed a new function preserving transformation algorithm that can be applied to data subsections. By employing the binary-diversification techniques that we proposed, we eliminated the influence of the most weighted part to generate adversarial examples. Our algorithm can fool the DNNs in certain cases with a success rate of nearly 100\%. Our method outperforms the state-of-the-art method . The most important aspect is that our method operates in black-box settings and the results can be validated with domain knowledge. Our analysis model can assist people in improving the robustness of malware detectors.
Efficient Malware Analysis Using Metric Embeddings
Dec 05, 2022In this paper, we explore the use of metric learning to embed Windows PE files in a low-dimensional vector space for downstream use in a variety of applications, including malware detection, family classification, and malware attribute tagging. Specifically, we enrich labeling on malicious and benign PE files using computationally expensive, disassembly-based malicious capabilities. Using these capabilities, we derive several different types of metric embeddings utilizing an embedding neural network trained via contrastive loss, Spearman rank correlation, and combinations thereof. We then examine performance on a variety of transfer tasks performed on the EMBER and SOREL datasets, demonstrating that for several tasks, low-dimensional, computationally efficient metric embeddings maintain performance with little decay, which offers the potential to quickly retrain for a variety of transfer tasks at significantly reduced storage overhead. We conclude with an examination of practical considerations for the use of our proposed embedding approach, such as robustness to adversarial evasion and introduction of task-specific auxiliary objectives to improve performance on mission critical tasks.