 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Vehicle Re Identification
Papers and Code
CORE-ReID V2: Advancing the Domain Adaptation for Object Re-Identification with Optimized Training and Ensemble Fusion
Aug 06, 2025This study presents CORE-ReID V2, an enhanced framework building upon CORE-ReID. The new framework extends its predecessor by addressing Unsupervised Domain Adaptation (UDA) challenges in Person ReID and Vehicle ReID, with further applicability to Object ReID. During pre-training, CycleGAN is employed to synthesize diverse data, bridging image characteristic gaps across different domains. In the fine-tuning, an advanced ensemble fusion mechanism, consisting of the Efficient Channel Attention Block (ECAB) and the Simplified Efficient Channel Attention Block (SECAB), enhances both local and global feature representations while reducing ambiguity in pseudo-labels for target samples. Experimental results on widely used UDA Person ReID and Vehicle ReID datasets demonstrate that the proposed framework outperforms state-of-the-art methods, achieving top performance in Mean Average Precision (mAP) and Rank-k Accuracy (Top-1, Top-5, Top-10). Moreover, the framework supports lightweight backbones such as ResNet18 and ResNet34, ensuring both scalability and efficiency. Our work not only pushes the boundaries of UDA-based Object ReID but also provides a solid foundation for further research and advancements in this domain. Our codes and models are available at https://github.com/TrinhQuocNguyen/CORE-ReID-V2.
* AI Sens. 2025, Submission received: 8 May 2025 / Revised: 4 June 2025 / Accepted: 30 June 2025 / Published: 4 July 2025. 3042-5999/1/1/4
Revisiting Multi-Granularity Representation via Group Contrastive Learning for Unsupervised Vehicle Re-identification
Oct 29, 2024



Vehicle re-identification (Vehicle ReID) aims at retrieving vehicle images across disjoint surveillance camera views. The majority of vehicle ReID research is heavily reliant upon supervisory labels from specific human-collected datasets for training. When applied to the large-scale real-world scenario, these models will experience dreadful performance declines due to the notable domain discrepancy between the source dataset and the target. To address this challenge, in this paper, we propose an unsupervised vehicle ReID framework (MGR-GCL). It integrates a multi-granularity CNN representation for learning discriminative transferable features and a contrastive learning module responsible for efficient domain adaptation in the unlabeled target domain. Specifically, after training the proposed Multi-Granularity Representation (MGR) on the labeled source dataset, we propose a group contrastive learning module (GCL) to generate pseudo labels for the target dataset, facilitating the domain adaptation process. We conducted extensive experiments and the results demonstrated our superiority against existing state-of-the-art methods.
A Comprehensive Survey on Deep-Learning-based Vehicle Re-Identification: Models, Data Sets and Challenges
Jan 19, 2024Vehicle re-identification (ReID) endeavors to associate vehicle images collected from a distributed network of cameras spanning diverse traffic environments. This task assumes paramount importance within the spectrum of vehicle-centric technologies, playing a pivotal role in deploying Intelligent Transportation Systems (ITS) and advancing smart city initiatives. Rapid advancements in deep learning have significantly propelled the evolution of vehicle ReID technologies in recent years. Consequently, undertaking a comprehensive survey of methodologies centered on deep learning for vehicle re-identification has become imperative and inescapable. This paper extensively explores deep learning techniques applied to vehicle ReID. It outlines the categorization of these methods, encompassing supervised and unsupervised approaches, delves into existing research within these categories, introduces datasets and evaluation criteria, and delineates forthcoming challenges and potential research directions. This comprehensive assessment examines the landscape of deep learning in vehicle ReID and establishes a foundation and starting point for future works. It aims to serve as a complete reference by highlighting challenges and emerging trends, fostering advancements and applications in vehicle ReID utilizing deep learning models.
Large-scale Fully-Unsupervised Re-Identification
Jul 26, 2023



Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.
ConMAE: Contour Guided MAE for Unsupervised Vehicle Re-Identification
Feb 11, 2023Vehicle re-identification is a cross-view search task by matching the same target vehicle from different perspectives. It serves an important role in road-vehicle collaboration and intelligent road control. With the large-scale and dynamic road environment, the paradigm of supervised vehicle re-identification shows limited scalability because of the heavy reliance on large-scale annotated datasets. Therefore, the unsupervised vehicle re-identification with stronger cross-scene generalization ability has attracted more attention. Considering that Masked Autoencoder (MAE) has shown excellent performance in self-supervised learning, this work designs a Contour Guided Masked Autoencoder for Unsupervised Vehicle Re-Identification (ConMAE), which is inspired by extracting the informative contour clue to highlight the key regions for cross-view correlation. ConMAE is implemented by preserving the image blocks with contour pixels and randomly masking the blocks with smooth textures. In addition, to improve the quality of pseudo labels of vehicles for unsupervised re-identification, we design a label softening strategy and adaptively update the label with the increase of training steps. We carry out experiments on VeRi-776 and VehicleID datasets, and a significant performance improvement is obtained by the comparison with the state-of-the-art unsupervised vehicle re-identification methods. The code is available on the website of https://github.com/2020132075/ConMAE.
Triplet Contrastive Learning for Unsupervised Vehicle Re-identification
Jan 23, 2023



Part feature learning is a critical technology for finegrained semantic understanding in vehicle re-identification. However, recent unsupervised re-identification works exhibit serious gradient collapse issues when directly modeling the part features and global features. To address this problem, in this paper, we propose a novel Triplet Contrastive Learning framework (TCL) which leverages cluster features to bridge the part features and global features. Specifically, TCL devises three memory banks to store the features according to their attributes and proposes a proxy contrastive loss (PCL) to make contrastive learning between adjacent memory banks, thus presenting the associations between the part and global features as a transition of the partcluster and cluster-global associations. Since the cluster memory bank deals with all the instance features, it can summarize them into a discriminative feature representation. To deeply exploit the instance information, TCL proposes two additional loss functions. For the inter-class instance, a hybrid contrastive loss (HCL) re-defines the sample correlations by approaching the positive cluster features and leaving the all negative instance features. For the intra-class instances, a weighted regularization cluster contrastive loss (WRCCL) refines the pseudo labels by penalizing the mislabeled images according to the instance similarity. Extensive experiments show that TCL outperforms many state-of-the-art unsupervised vehicle re-identification approaches. The code will be available at https://github.com/muzishen/TCL.
VehicleGAN: Pair-flexible Pose Guided Image Synthesis for Vehicle Re-identification
Nov 27, 2023



Vehicle Re-identification (Re-ID) has been broadly studied in the last decade; however, the different camera view angle leading to confused discrimination in the feature subspace for the vehicles of various poses, is still challenging for the Vehicle Re-ID models in the real world. To promote the Vehicle Re-ID models, this paper proposes to synthesize a large number of vehicle images in the target pose, whose idea is to project the vehicles of diverse poses into the unified target pose so as to enhance feature discrimination. Considering that the paired data of the same vehicles in different traffic surveillance cameras might be not available in the real world, we propose the first Pair-flexible Pose Guided Image Synthesis method for Vehicle Re-ID, named as VehicleGAN in this paper, which works for both supervised and unsupervised settings without the knowledge of geometric 3D models. Because of the feature distribution difference between real and synthetic data, simply training a traditional metric learning based Re-ID model with data-level fusion (i.e., data augmentation) is not satisfactory, therefore we propose a new Joint Metric Learning (JML) via effective feature-level fusion from both real and synthetic data. Intensive experimental results on the public VeRi-776 and VehicleID datasets prove the accuracy and effectiveness of our proposed VehicleGAN and JML.
Prototypical Contrastive Learning-based CLIP Fine-tuning for Object Re-identification
Oct 26, 2023This work aims to adapt large-scale pre-trained vision-language models, such as contrastive language-image pretraining (CLIP), to enhance the performance of object reidentification (Re-ID) across various supervision settings. Although prompt learning has enabled a recent work named CLIP-ReID to achieve promising performance, the underlying mechanisms and the necessity of prompt learning remain unclear due to the absence of semantic labels in ReID tasks. In this work, we first analyze the role prompt learning in CLIP-ReID and identify its limitations. Based on our investigations, we propose a simple yet effective approach to adapt CLIP for supervised object Re-ID. Our approach directly fine-tunes the image encoder of CLIP using a prototypical contrastive learning (PCL) loss, eliminating the need for prompt learning. Experimental results on both person and vehicle Re-ID datasets demonstrate the competitiveness of our method compared to CLIP-ReID. Furthermore, we extend our PCL-based CLIP fine-tuning approach to unsupervised scenarios, where we achieve state-of-the art performance.
Camera-Tracklet-Aware Contrastive Learning for Unsupervised Vehicle Re-Identification
Sep 14, 2021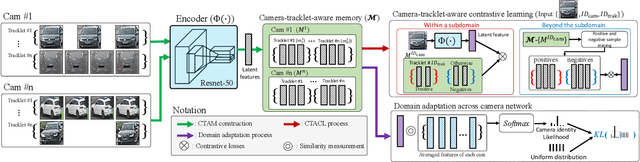
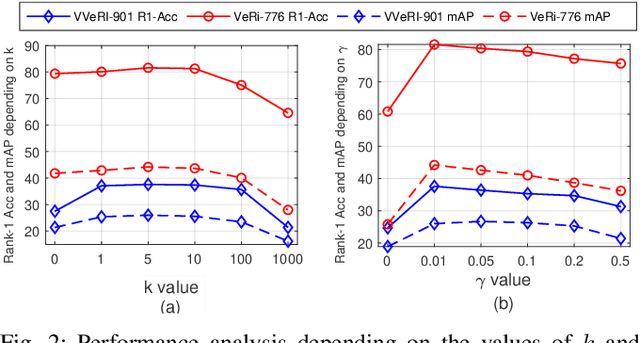
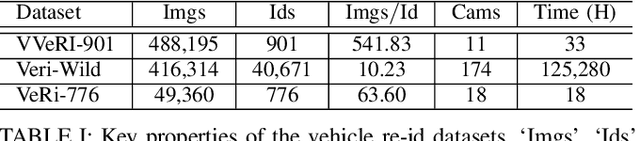
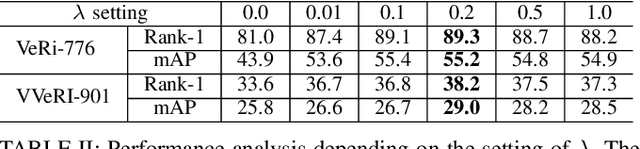
Recently, vehicle re-identification methods based on deep learning constitute remarkable achievement. However, this achievement requires large-scale and well-annotated datasets. In constructing the dataset, assigning globally available identities (Ids) to vehicles captured from a great number of cameras is labour-intensive, because it needs to consider their subtle appearance differences or viewpoint variations. In this paper, we propose camera-tracklet-aware contrastive learning (CTACL) using the multi-camera tracklet information without vehicle identity labels. The proposed CTACL divides an unlabelled domain, i.e., entire vehicle images, into multiple camera-level subdomains and conducts contrastive learning within and beyond the subdomains. The positive and negative samples for contrastive learning are defined using tracklet Ids of each camera. Additionally, the domain adaptation across camera networks is introduced to improve the generalisation performance of learnt representations and alleviate the performance degradation resulted from the domain gap between the subdomains. We demonstrate the effectiveness of our approach on video-based and image-based vehicle Re-ID datasets. Experimental results show that the proposed method outperforms the recent state-of-the-art unsupervised vehicle Re-ID methods. The source code for this paper is publicly available on `https://github.com/andreYoo/CTAM-CTACL-VVReID.git'.
Unsupervised Vehicle Re-Identification via Self-supervised Metric Learning using Feature Dictionary
Mar 03, 2021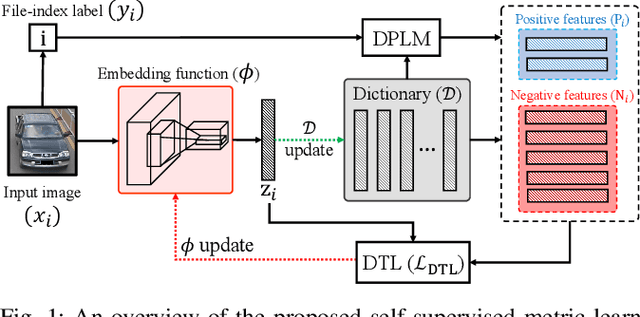
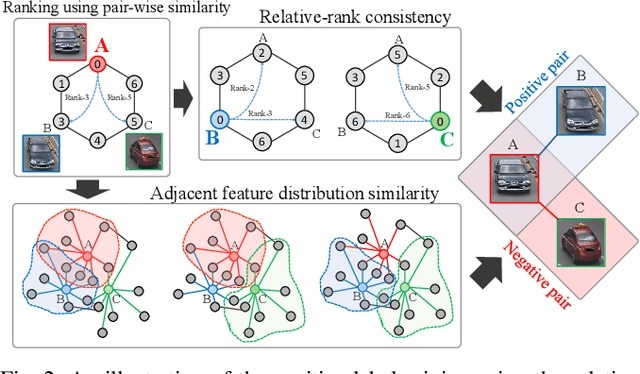
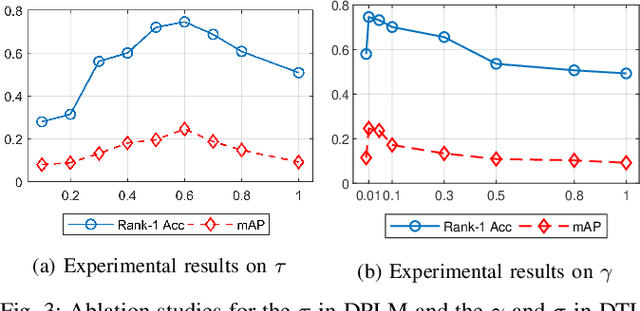
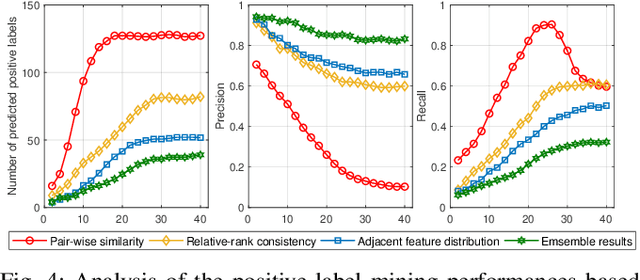
The key challenge of unsupervised vehicle re-identification (Re-ID) is learning discriminative features from unlabelled vehicle images. Numerous methods using domain adaptation have achieved outstanding performance, but those methods still need a labelled dataset as a source domain. This paper addresses an unsupervised vehicle Re-ID method, which no need any types of a labelled dataset, through a Self-supervised Metric Learning (SSML) based on a feature dictionary. Our method initially extracts features from vehicle images and stores them in a dictionary. Thereafter, based on the dictionary, the proposed method conducts dictionary-based positive label mining (DPLM) to search for positive labels. Pair-wise similarity, relative-rank consistency, and adjacent feature distribution similarity are jointly considered to find images that may belong to the same vehicle of a given probe image. The results of DPLM are applied to dictionary-based triplet loss (DTL) to improve the discriminativeness of learnt features and to refine the quality of the results of DPLM progressively. The iterative process with DPLM and DTL boosts the performance of unsupervised vehicle Re-ID. Experimental results demonstrate the effectiveness of the proposed method by producing promising vehicle Re-ID performance without a pre-labelled dataset. The source code for this paper is publicly available on `https://github.com/andreYoo/VeRI_SSML_FD.git'.