 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTal Corpus
Papers and Code
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022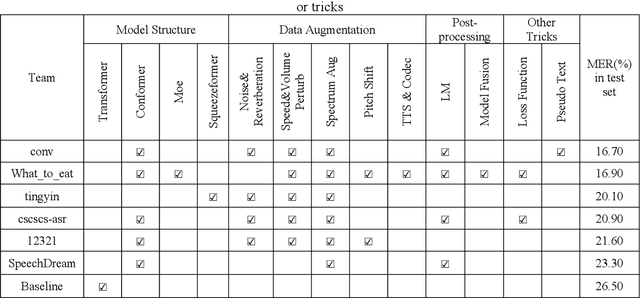
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
Exploiting Cross-domain And Cross-Lingual Ultrasound Tongue Imaging Features For Elderly And Dysarthric Speech Recognition
Jun 15, 2022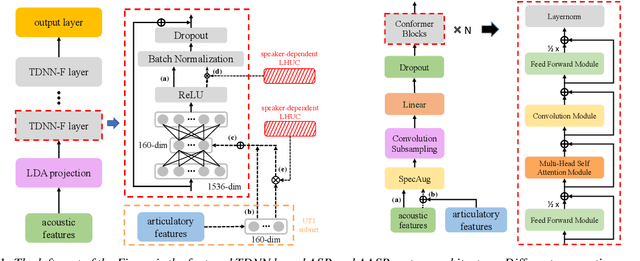
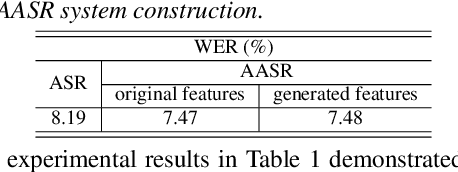
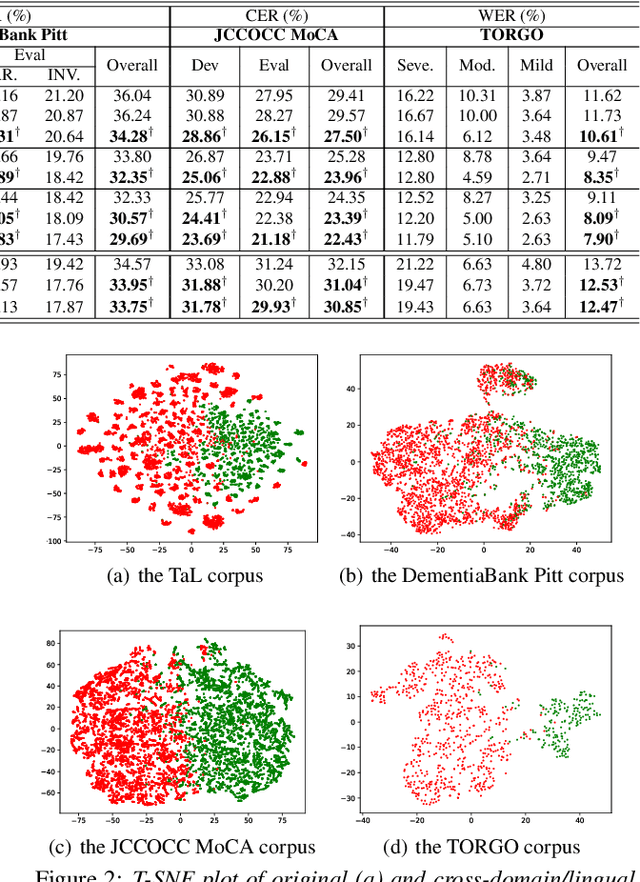
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems designed for normal speech. Their practical application to atypical task domains such as elderly and disordered speech across languages is often limited by the difficulty in collecting such specialist data from target speakers. This paper presents a cross-domain and cross-lingual A2A inversion approach that utilizes the parallel audio, visual and ultrasound tongue imaging (UTI) data of the 24-hour TaL corpus in A2A model pre-training before being cross-domain and cross-lingual adapted to three datasets across two languages: the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora; and the English TORGO dysarthric speech data, to produce UTI based articulatory features. Experiments conducted on three tasks suggested incorporating the generated articulatory features consistently outperformed the baseline hybrid TDNN and Conformer based end-to-end systems constructed using acoustic features only by statistically significant word error rate or character error rate reductions up to 2.64%, 1.92% and 1.21% absolute (8.17%, 7.89% and 13.28% relative) after data augmentation and speaker adaptation were applied.
TALCS: An Open-Source Mandarin-English Code-Switching Corpus and a Speech Recognition Baseline
Jun 27, 2022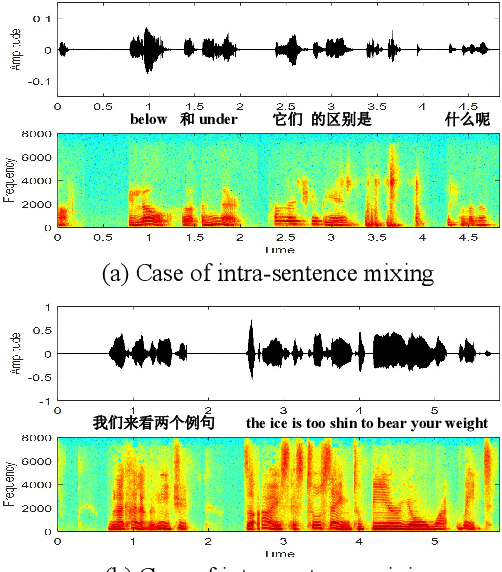
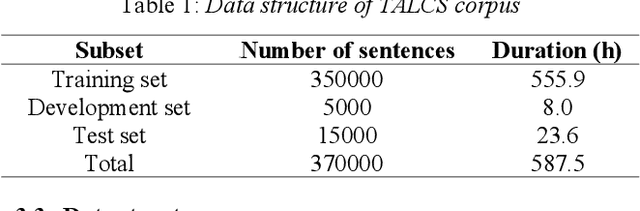
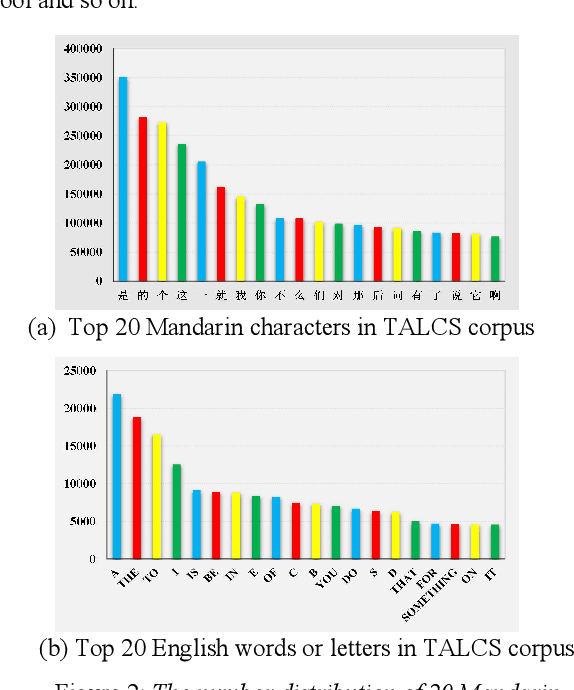
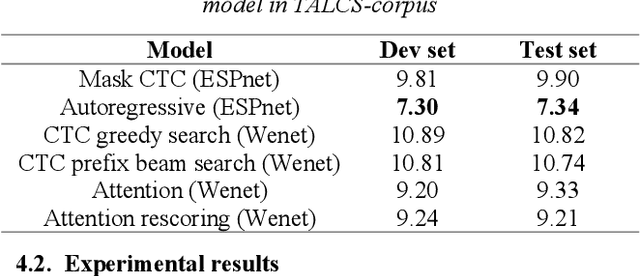
This paper introduces a new corpus of Mandarin-English code-switching speech recognition--TALCS corpus, suitable for training and evaluating code-switching speech recognition systems. TALCS corpus is derived from real online one-to-one English teaching scenes in TAL education group, which contains roughly 587 hours of speech sampled at 16 kHz. To our best knowledge, TALCS corpus is the largest well labeled Mandarin-English code-switching open source automatic speech recognition (ASR) dataset in the world. In this paper, we will introduce the recording procedure in detail, including audio capturing devices and corpus environments. And the TALCS corpus is freely available for download under the permissive license1. Using TALCS corpus, we conduct ASR experiments in two popular speech recognition toolkits to make a baseline system, including ESPnet and Wenet. The Mixture Error Rate (MER) performance in the two speech recognition toolkits is compared in TALCS corpus. The experimental results implies that the quality of audio recordings and transcriptions are promising and the baseline system is workable.
TaL: a synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos
Nov 19, 2020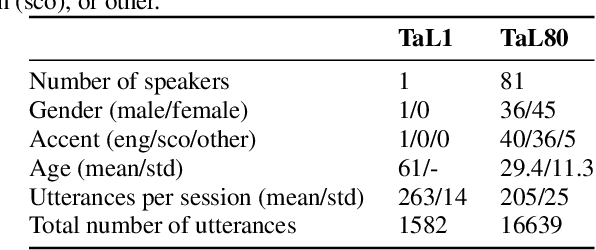
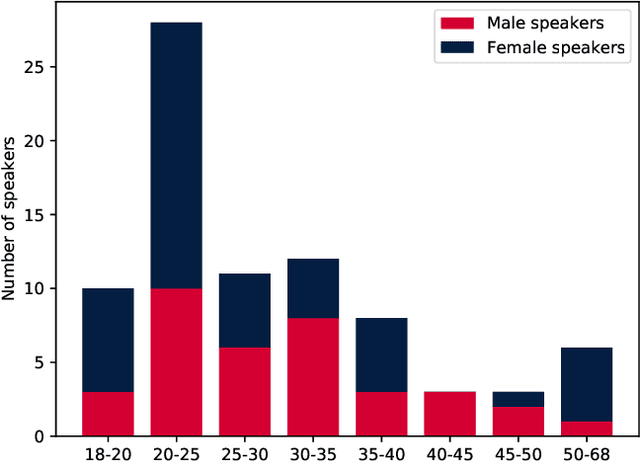
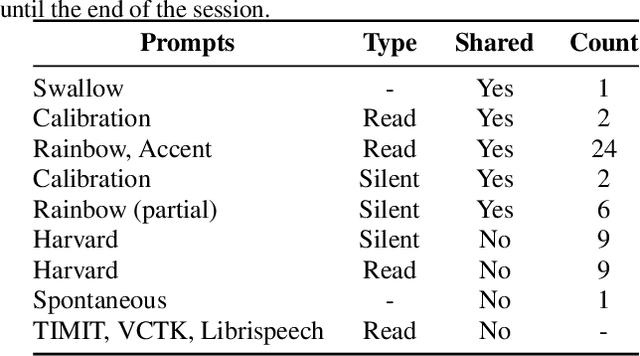

We present the Tongue and Lips corpus (TaL), a multi-speaker corpus of audio, ultrasound tongue imaging, and lip videos. TaL consists of two parts: TaL1 is a set of six recording sessions of one professional voice talent, a male native speaker of English; TaL80 is a set of recording sessions of 81 native speakers of English without voice talent experience. Overall, the corpus contains 24 hours of parallel ultrasound, video, and audio data, of which approximately 13.5 hours are speech. This paper describes the corpus and presents benchmark results for the tasks of speech recognition, speech synthesis (articulatory-to-acoustic mapping), and automatic synchronisation of ultrasound to audio. The TaL corpus is publicly available under the CC BY-NC 4.0 license.