 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Gesture Recognition
Papers and Code
SHANDS: A Multi-View Dataset and Benchmark for Surgical Hand-Gesture and Error Recognition Toward Medical Training
Mar 27, 2026In surgical training for medical students, proficiency development relies on expert-led skill assessment, which is costly, time-limited, difficult to scale, and its expertise remains confined to institutions with available specialists. Automated AI-based assessment offers a viable alternative, but progress is constrained by the lack of datasets containing realistic trainee errors and the multi-view variability needed to train robust computer vision approaches. To address this gap, we present Surgical-Hands (SHands), a large-scale multi-view video dataset for surgical hand-gesture and error recognition for medical training. \textsc{SHands} captures linear incision and suturing using five RGB cameras from complementary viewpoints, performed by 52 participants (20 experts and 32 trainees), each completing three standardized trials per procedure. The videos are annotated at the frame level with 15 gesture primitives and include a validated taxonomy of 8 trainee error types, enabling both gesture recognition and error detection. We further define standardized evaluation protocols for single-view, multi-view, and cross-view generalization, and benchmark state-of-the-art deep learning models on the dataset. SHands is publicly released to support the development of robust and scalable AI systems for surgical training grounded in clinically curated domain knowledge.
MiDAS: A Multimodal Data Acquisition System and Dataset for Robot-Assisted Minimally Invasive Surgery
Feb 12, 2026Background: Robot-assisted minimally invasive surgery (RMIS) research increasingly relies on multimodal data, yet access to proprietary robot telemetry remains a major barrier. We introduce MiDAS, an open-source, platform-agnostic system enabling time-synchronized, non-invasive multimodal data acquisition across surgical robotic platforms. Methods: MiDAS integrates electromagnetic and RGB-D hand tracking, foot pedal sensing, and surgical video capturing without requiring proprietary robot interfaces. We validated MiDAS on the open-source Raven-II and the clinical da Vinci Xi by collecting multimodal datasets of peg transfer and hernia repair suturing tasks performed by surgical residents. Correlation analysis and downstream gesture recognition experiments were conducted. Results: External hand and foot sensing closely approximated internal robot kinematics and non-invasive motion signals achieved gesture recognition performance comparable to proprietary telemetry. Conclusion: MiDAS enables reproducible multimodal RMIS data collection and is released with annotated datasets, including the first multimodal dataset capturing hernia repair suturing on high-fidelity simulation models.
End to End AI System for Surgical Gesture Sequence Recognition and Clinical Outcome Prediction
Nov 14, 2025Fine-grained analysis of intraoperative behavior and its impact on patient outcomes remain a longstanding challenge. We present Frame-to-Outcome (F2O), an end-to-end system that translates tissue dissection videos into gesture sequences and uncovers patterns associated with postoperative outcomes. Leveraging transformer-based spatial and temporal modeling and frame-wise classification, F2O robustly detects consecutive short (~2 seconds) gestures in the nerve-sparing step of robot-assisted radical prostatectomy (AUC: 0.80 frame-level; 0.81 video-level). F2O-derived features (gesture frequency, duration, and transitions) predicted postoperative outcomes with accuracy comparable to human annotations (0.79 vs. 0.75; overlapping 95% CI). Across 25 shared features, effect size directions were concordant with small differences (~ 0.07), and strong correlation (r = 0.96, p < 1e-14). F2O also captured key patterns linked to erectile function recovery, including prolonged tissue peeling and reduced energy use. By enabling automatic interpretable assessment, F2O establishes a foundation for data-driven surgical feedback and prospective clinical decision support.
Multi-Modal Gesture Recognition from Video and Surgical Tool Pose Information via Motion Invariants
Mar 19, 2025



Recognizing surgical gestures in real-time is a stepping stone towards automated activity recognition, skill assessment, intra-operative assistance, and eventually surgical automation. The current robotic surgical systems provide us with rich multi-modal data such as video and kinematics. While some recent works in multi-modal neural networks learn the relationships between vision and kinematics data, current approaches treat kinematics information as independent signals, with no underlying relation between tool-tip poses. However, instrument poses are geometrically related, and the underlying geometry can aid neural networks in learning gesture representation. Therefore, we propose combining motion invariant measures (curvature and torsion) with vision and kinematics data using a relational graph network to capture the underlying relations between different data streams. We show that gesture recognition improves when combining invariant signals with tool position, achieving 90.3\% frame-wise accuracy on the JIGSAWS suturing dataset. Our results show that motion invariant signals coupled with position are better representations of gesture motion compared to traditional position and quaternion representations. Our results highlight the need for geometric-aware modeling of kinematics for gesture recognition.
Zero-shot Prompt-based Video Encoder for Surgical Gesture Recognition
Mar 28, 2024



Purpose: Surgical video is an important data stream for gesture recognition. Thus, robust visual encoders for those data-streams is similarly important. Methods: Leveraging the Bridge-Prompt framework, we fine-tune a pre-trained vision-text model (CLIP) for gesture recognition in surgical videos. This can utilize extensive outside video data such as text, but also make use of label meta-data and weakly supervised contrastive losses. Results: Our experiments show that prompt-based video encoder outperforms standard encoders in surgical gesture recognition tasks. Notably, it displays strong performance in zero-shot scenarios, where gestures/tasks that were not provided during the encoder training phase are included in the prediction phase. Additionally, we measure the benefit of inclusion text descriptions in the feature extractor training schema. Conclusion: Bridge-Prompt and similar pre-trained+fine-tuned video encoder models present significant visual representation for surgical robotics, especially in gesture recognition tasks. Given the diverse range of surgical tasks (gestures), the ability of these models to zero-shot transfer without the need for any task (gesture) specific retraining makes them invaluable.
Multimodal Transformers for Real-Time Surgical Activity Prediction
Mar 11, 2024



Real-time recognition and prediction of surgical activities are fundamental to advancing safety and autonomy in robot-assisted surgery. This paper presents a multimodal transformer architecture for real-time recognition and prediction of surgical gestures and trajectories based on short segments of kinematic and video data. We conduct an ablation study to evaluate the impact of fusing different input modalities and their representations on gesture recognition and prediction performance. We perform an end-to-end assessment of the proposed architecture using the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) dataset. Our model outperforms the state-of-the-art (SOTA) with 89.5\% accuracy for gesture prediction through effective fusion of kinematic features with spatial and contextual video features. It achieves the real-time performance of 1.1-1.3ms for processing a 1-second input window by relying on a computationally efficient model.
Hierarchical Semi-Supervised Learning Framework for Surgical Gesture Segmentation and Recognition Based on Multi-Modality Data
Jul 31, 2023



Segmenting and recognizing surgical operation trajectories into distinct, meaningful gestures is a critical preliminary step in surgical workflow analysis for robot-assisted surgery. This step is necessary for facilitating learning from demonstrations for autonomous robotic surgery, evaluating surgical skills, and so on. In this work, we develop a hierarchical semi-supervised learning framework for surgical gesture segmentation using multi-modality data (i.e. kinematics and vision data). More specifically, surgical tasks are initially segmented based on distance characteristics-based profiles and variance characteristics-based profiles constructed using kinematics data. Subsequently, a Transformer-based network with a pre-trained `ResNet-18' backbone is used to extract visual features from the surgical operation videos. By combining the potential segmentation points obtained from both modalities, we can determine the final segmentation points. Furthermore, gesture recognition can be implemented based on supervised learning. The proposed approach has been evaluated using data from the publicly available JIGSAWS database, including Suturing, Needle Passing, and Knot Tying tasks. The results reveal an average F1 score of 0.623 for segmentation and an accuracy of 0.856 for recognition.
Evaluating the Task Generalization of Temporal Convolutional Networks for Surgical Gesture and Motion Recognition using Kinematic Data
Jun 28, 2023



Fine-grained activity recognition enables explainable analysis of procedures for skill assessment, autonomy, and error detection in robot-assisted surgery. However, existing recognition models suffer from the limited availability of annotated datasets with both kinematic and video data and an inability to generalize to unseen subjects and tasks. Kinematic data from the surgical robot is particularly critical for safety monitoring and autonomy, as it is unaffected by common camera issues such as occlusions and lens contamination. We leverage an aggregated dataset of six dry-lab surgical tasks from a total of 28 subjects to train activity recognition models at the gesture and motion primitive (MP) levels and for separate robotic arms using only kinematic data. The models are evaluated using the LOUO (Leave-One-User-Out) and our proposed LOTO (Leave-One-Task-Out) cross validation methods to assess their ability to generalize to unseen users and tasks respectively. Gesture recognition models achieve higher accuracies and edit scores than MP recognition models. But, using MPs enables the training of models that can generalize better to unseen tasks. Also, higher MP recognition accuracy can be achieved by training separate models for the left and right robot arms. For task-generalization, MP recognition models perform best if trained on similar tasks and/or tasks from the same dataset.
Bounded Future MS-TCN++ for surgical gesture recognition
Oct 05, 2022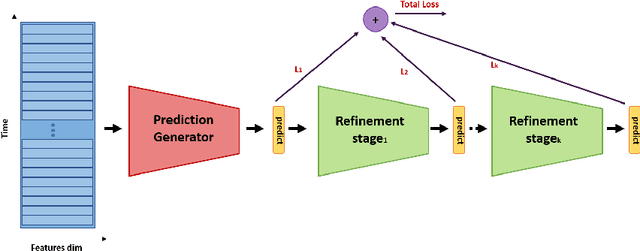

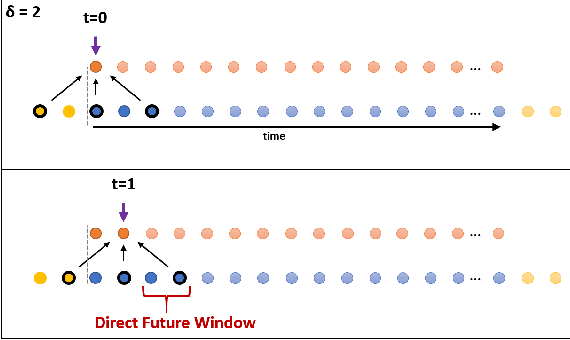
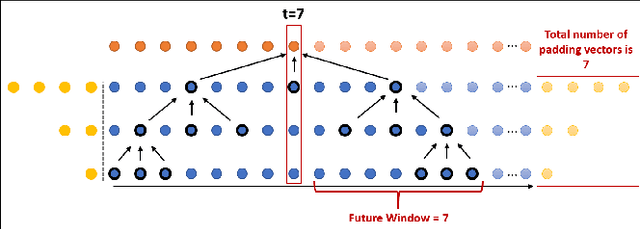
In recent times there is a growing development of video based applications for surgical purposes. Part of these applications can work offline after the end of the procedure, other applications must react immediately. However, there are cases where the response should be done during the procedure but some delay is acceptable. In the literature, the online-offline performance gap is known. Our goal in this study was to learn the performance-delay trade-off and design an MS-TCN++-based algorithm that can utilize this trade-off. To this aim, we used our open surgery simulation data-set containing 96 videos of 24 participants that perform a suturing task on a variable tissue simulator. In this study, we used video data captured from the side view. The Networks were trained to identify the performed surgical gestures. The naive approach is to reduce the MS-TCN++ depth, as a result, the receptive field is reduced, and also the number of required future frames is also reduced. We showed that this method is sub-optimal, mainly in the small delay cases. The second method was to limit the accessible future in each temporal convolution. This way, we have flexibility in the network design and as a result, we achieve significantly better performance than in the naive approach.
Towards Interpretable Motion-level Skill Assessment in Robotic Surgery
Nov 10, 2023



Purpose: We study the relationship between surgical gestures and motion primitives in dry-lab surgical exercises towards a deeper understanding of surgical activity at fine-grained levels and interpretable feedback in skill assessment. Methods: We analyze the motion primitive sequences of gestures in the JIGSAWS dataset and identify inverse motion primitives in those sequences. Inverse motion primitives are defined as sequential actions on the same object by the same tool that effectively negate each other. We also examine the correlation between surgical skills (measured by GRS scores) and the number and total durations of inverse motion primitives in the dry-lab trials of Suturing, Needle Passing, and Knot Tying tasks. Results: We find that the sequence of motion primitives used to perform gestures can help detect labeling errors in surgical gestures. Inverse motion primitives are often used as recovery actions to correct the position or orientation of objects or may be indicative of other issues such as with depth perception. The number and total durations of inverse motion primitives in trials are also strongly correlated with lower GRS scores in the Suturing and Knot Tying tasks. Conclusion: The sequence and pattern of motion primitives could be used to provide interpretable feedback in surgical skill assessment. Combined with an action recognition model, the explainability of automated skill assessment can be improved by showing video clips of the inverse motion primitives of inefficient or problematic movements.