 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End AI System for Surgical Gesture Sequence Recognition and Clinical Outcome Prediction
Nov 14, 2025Fine-grained analysis of intraoperative behavior and its impact on patient outcomes remain a longstanding challenge. We present Frame-to-Outcome (F2O), an end-to-end system that translates tissue dissection videos into gesture sequences and uncovers patterns associated with postoperative outcomes. Leveraging transformer-based spatial and temporal modeling and frame-wise classification, F2O robustly detects consecutive short (~2 seconds) gestures in the nerve-sparing step of robot-assisted radical prostatectomy (AUC: 0.80 frame-level; 0.81 video-level). F2O-derived features (gesture frequency, duration, and transitions) predicted postoperative outcomes with accuracy comparable to human annotations (0.79 vs. 0.75; overlapping 95% CI). Across 25 shared features, effect size directions were concordant with small differences (~ 0.07), and strong correlation (r = 0.96, p < 1e-14). F2O also captured key patterns linked to erectile function recovery, including prolonged tissue peeling and reduced energy use. By enabling automatic interpretable assessment, F2O establishes a foundation for data-driven surgical feedback and prospective clinical decision support.
StarBASE-GP: Biologically-Guided Automated Machine Learning for Genotype-to-Phenotype Association Analysis
May 28, 2025


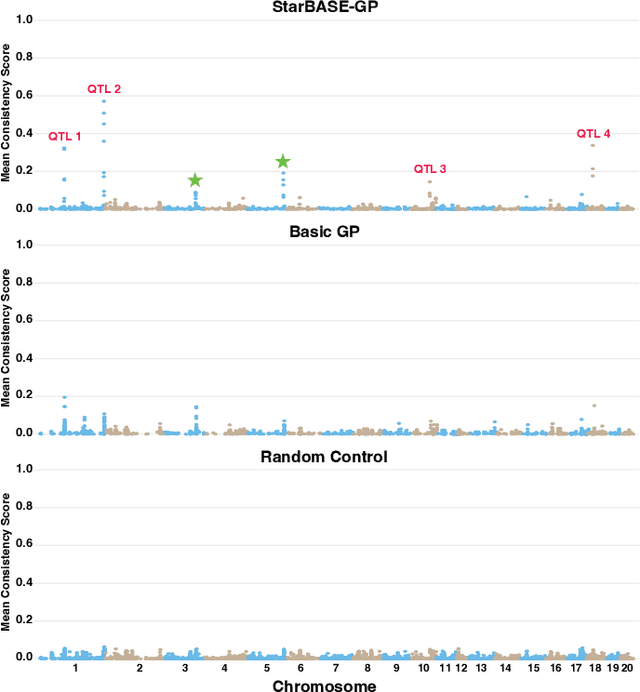
We present the Star-Based Automated Single-locus and Epistasis analysis tool - Genetic Programming (StarBASE-GP), an automated framework for discovering meaningful genetic variants associated with phenotypic variation in large-scale genomic datasets. StarBASE-GP uses a genetic programming-based multi-objective optimization strategy to evolve machine learning pipelines that simultaneously maximize explanatory power (r2) and minimize pipeline complexity. Biological domain knowledge is integrated at multiple stages, including the use of nine inheritance encoding strategies to model deviations from additivity, a custom linkage disequilibrium pruning node that minimizes redundancy among features, and a dynamic variant recommendation system that prioritizes informative candidates for pipeline inclusion. We evaluate StarBASE-GP on a cohort of Rattus norvegicus (brown rat) to identify variants associated with body mass index, benchmarking its performance against a random baseline and a biologically naive version of the tool. StarBASE-GP consistently evolves Pareto fronts with superior performance, yielding higher accuracy in identifying both ground truth and novel quantitative trait loci, highlighting relevant targets for future validation. By incorporating evolutionary search and relevant biological theory into a flexible automated machine learning framework, StarBASE-GP demonstrates robust potential for advancing variant discovery in complex traits.
Faster Convergence with Lexicase Selection in Tree-based Automated Machine Learning
Feb 01, 2023In many evolutionary computation systems, parent selection methods can affect, among other things, convergence to a solution. In this paper, we present a study comparing the role of two commonly used parent selection methods in evolving machine learning pipelines in an automated machine learning system called Tree-based Pipeline Optimization Tool (TPOT). Specifically, we demonstrate, using experiments on multiple datasets, that lexicase selection leads to significantly faster convergence as compared to NSGA-II in TPOT. We also compare the exploration of parts of the search space by these selection methods using a trie data structure that contains information about the pipelines explored in a particular run.