 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSudoku Solver
Sudoku solver is a program that solves Sudoku puzzles by filling in the missing numbers based on the rules of the game.
Papers and Code
DiBS: Diffusion-Informed Branch Selection
Jun 02, 2026Sudoku is a representative constraint satisfaction problem that requires global structural reasoning under strict discrete constraints. The existing works of solving Sudoku mainly focus on two dominant approaches, i.e., traditional heuristic and deep learning solver. However, they suffer from two complementary limitations: learning-based solvers lack hard correctness guarantees, while complete symbolic solvers are still prone to long-tail search. To address these shortcomings, we propose a novel diffusion model-guided approach, termed as DiBS, for the branch selection search process. Specifically, DiBS keeps the symbolic solver complete and uses the diffusion model as a branch-ordering guide. The core method is ranking candidate values under the current partial assignment and lightweight consistency signal. Furthermore, we provide an in-depth theoretical proof to reveal how it works and why it works. Experiments on the challenging Royle 17-clue Sudoku benchmark show that our DiBS substantially reduces search cost relative to strong heuristic baselines, especially in nodes, backtracks, and long-tail percentiles. Besides, these results confirm that learned global guidance is effective on hard instances where branch-order mistakes are most expensive. All codes are available at https://github.com/shanxierdan/DiBS.
Solve the Loop: Attractor Models for Language and Reasoning
May 12, 2026Looped Transformers offer a promising alternative to purely feed-forward computation by iteratively refining latent representations, improving language modeling and reasoning. Yet recurrent architectures remain unstable to train, costly to optimize and deploy, and constrained to small, fixed recurrence depths. We introduce Attractor Models, in which a backbone module first proposes output embeddings, then an attractor module refines them by solving for the fixed point, with gradients obtained through implicit differentiation. Thus, training memory remains constant in effective depth, and iterations are chosen adaptively by convergence. Empirically, Attractor Models outperform existing models across two regimes, large-scale language-model pretraining and reasoning with tiny models. In language modeling, Attractor Models deliver a Pareto improvement over standard Transformers and stable looped models across sizes, improving perplexity by up to 46.6% and downstream accuracy by up to 19.7% while reducing training cost. Notably, a 770M Attractor Model outperforms a 1.3B Transformer trained on twice as many tokens. On challenging reasoning tasks, we show that our model with only 27M parameters and approximately 1000 examples achieves 91.4% accuracy on Sudoku-Extreme and 93.1% on Maze-Hard, scaling favorably where frontier models like Claude and GPT o3, fail completely, and specialized recursive reasoners collapse at larger sizes. Lastly, we show that Attractor Models exhibit a novel phenomenon, which we call equilibrium internalization: fixed-point training places the model's initial output embedding near equilibrium, allowing the solver to be removed at inference time with little degradation. Together, these results suggest that Attractor Models make iterative refinement scalable by turning recurrence into a computation the model can learn to internalize.
Loom: A Scalable Analytical Neural Computer Architecture
Apr 09, 2026We present Loom, a computer architecture that executes programs compiled from C inside a looped transformer whose weights are derived analytically. The architecture implements a 22-opcode instruction set in 8 transformer layers. Each forward pass executes one instruction; the model is applied iteratively until the program counter reaches zero. The full machine state resides in a single tensor $X \in \mathbb{R}^{d \times n}$ of fixed size, and every step has fixed cost for fixed $d$ and $n$, independent of program length or execution history. The default configuration uses $d = 155$ and $n = 1024$, yielding 4.7 million parameters and 928 instruction slots. A compact configuration at $d = 146$ and $n = 512$ suffices for a 9$\times$9 Sudoku solver (284 instructions). The weights are program-independent: programs live in the state tensor, and the same fixed-weight model executes any compiled program. We make Loom source code publicly available at https://github.com/mkturkcan/Loom.
AS2 -- Attention-Based Soft Answer Sets: An End-to-End Differentiable Neuro-Soft-Symbolic Reasoning Architecture
Mar 19, 2026Neuro-symbolic artificial intelligence (AI) systems typically couple a neural perception module to a discrete symbolic solver through a non-differentiable boundary, preventing constraint-satisfaction feedback from reaching the perception encoder during training. We introduce AS2 (Attention-Based Soft Answer Sets), a fully differentiable neuro-symbolic architecture that replaces the discrete solver with a soft, continuous approximation of the Answer Set Programming (ASP) immediate consequence operator $T_P$. AS2 maintains per-position probability distributions over a finite symbol domain throughout the forward pass and trains end-to-end by minimizing the fixed-point residual of a probabilistic lift of $T_P$, thereby differentiating through the constraint check without invoking an external solver at either training or inference time. The architecture is entirely free of conventional positional embeddings. Instead, it encodes problem structure through constraint-group membership embeddings that directly reflect the declarative ASP specification, making the model agnostic to arbitrary position indexing. On Visual Sudoku, AS2 achieves 99.89% cell accuracy and 100% constraint satisfaction (verified by Clingo) across 1,000 test boards, using a greedy constrained decoding procedure that requires no external solver. On MNIST Addition with $N \in \{2, 4, 8\}$ addends, AS2 achieves digit accuracy above 99.7% across all scales. These results demonstrate that a soft differentiable fixpoint operator, combined with constraint-aware attention and declarative constraint specification, can match or exceed pipeline and solver-based neuro-symbolic systems while maintaining full end-to-end differentiability.
Can Continuous-Time Diffusion Models Generate and Solve Globally Constrained Discrete Problems? A Study on Sudoku
Jan 28, 2026Can standard continuous-time generative models represent distributions whose support is an extremely sparse, globally constrained discrete set? We study this question using completed Sudoku grids as a controlled testbed, treating them as a subset of a continuous relaxation space. We train flow-matching and score-based models along a Gaussian probability path and compare deterministic (ODE) sampling, stochastic (SDE) sampling, and DDPM-style discretizations derived from the same continuous-time training. Unconditionally, stochastic sampling substantially outperforms deterministic flows; score-based samplers are the most reliable among continuous-time methods, and DDPM-style ancestral sampling achieves the highest validity overall. We further show that the same models can be repurposed for guided generation: by repeatedly sampling completions under clamped clues and stopping when constraints are satisfied, the model acts as a probabilistic Sudoku solver. Although far less sample-efficient than classical solvers and discrete-geometry-aware diffusion methods, these experiments demonstrate that classic diffusion/flow formulations can assign non-zero probability mass to globally constrained combinatorial structures and can be used for constraint satisfaction via stochastic search.
Efficient Neuro-Symbolic Learning of Constraints and Objective
Aug 28, 2025In the ongoing quest for hybridizing discrete reasoning with neural nets, there is an increasing interest in neural architectures that can learn how to solve discrete reasoning or optimization problems from natural inputs, a task that Large Language Models seem to struggle with. Objectives: We introduce a differentiable neuro-symbolic architecture and a loss function dedicated to learning how to solve NP-hard reasoning problems. Methods: Our new probabilistic loss allows for learning both the constraints and the objective, thus delivering a complete model that can be scrutinized and completed with side constraints. By pushing the combinatorial solver out of the training loop, our architecture also offers scalable training while exact inference gives access to maximum accuracy. Results: We empirically show that it can efficiently learn how to solve NP-hard reasoning problems from natural inputs. On three variants of the Sudoku benchmark -- symbolic, visual, and many-solution --, our approach requires a fraction of training time of other hybrid methods. On a visual Min-Cut/Max-cut task, it optimizes the regret better than a Decision-Focused-Learning regret-dedicated loss. Finally, it efficiently learns the energy optimization formulation of the large real-world problem of designing proteins.
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants
May 22, 2025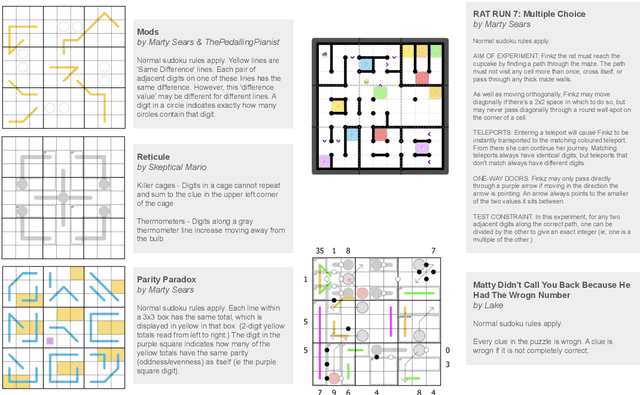
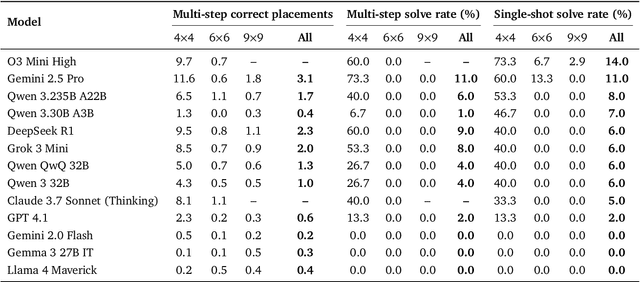

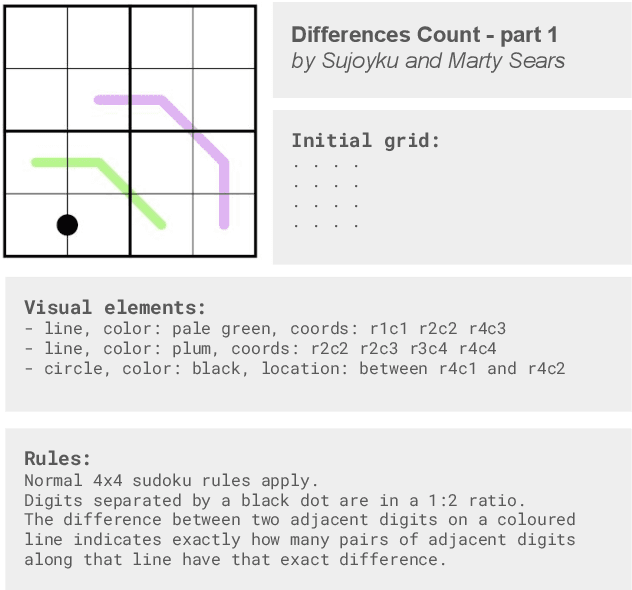
Existing reasoning benchmarks for large language models (LLMs) frequently fail to capture authentic creativity, often rewarding memorization of previously observed patterns. We address this shortcoming with Sudoku-Bench, a curated benchmark of challenging and unconventional Sudoku variants specifically selected to evaluate creative, multi-step logical reasoning. Sudoku variants form an unusually effective domain for reasoning research: each puzzle introduces unique or subtly interacting constraints, making memorization infeasible and requiring solvers to identify novel logical breakthroughs (``break-ins''). Despite their diversity, Sudoku variants maintain a common and compact structure, enabling clear and consistent evaluation. Sudoku-Bench includes a carefully chosen puzzle set, a standardized text-based puzzle representation, and flexible tools compatible with thousands of publicly available puzzles -- making it easy to extend into a general research environment. Baseline experiments show that state-of-the-art LLMs solve fewer than 15\% of puzzles unaided, highlighting significant opportunities to advance long-horizon, strategic reasoning capabilities.
Evaluating SAT and SMT Solvers on Large-Scale Sudoku Puzzles
Jan 15, 2025Modern SMT solvers have revolutionized the approach to constraint satisfaction problems by integrating advanced theory reasoning and encoding techniques. In this work, we evaluate the performance of modern SMT solvers in Z3, CVC5 and DPLL(T) against a standard SAT solver in DPLL. By benchmarking these solvers on novel, diverse 25x25 Sudoku puzzles of various difficulty levels created by our improved Sudoku generator, we examine the impact of advanced theory reasoning and encoding techniques. Our findings demonstrate that modern SMT solvers significantly outperform classical SAT solvers. This work highlights the evolution of logical solvers and exemplifies the utility of SMT solvers in addressing large-scale constraint satisfaction problems.
Causal Language Modeling Can Elicit Search and Reasoning Capabilities on Logic Puzzles
Sep 16, 2024



Causal language modeling using the Transformer architecture has yielded remarkable capabilities in Large Language Models (LLMs) over the last few years. However, the extent to which fundamental search and reasoning capabilities emerged within LLMs remains a topic of ongoing debate. In this work, we study if causal language modeling can learn a complex task such as solving Sudoku puzzles. To solve a Sudoku, the model is first required to search over all empty cells of the puzzle to decide on a cell to fill and then apply an appropriate strategy to fill the decided cell. Sometimes, the application of a strategy only results in thinning down the possible values in a cell rather than concluding the exact value of the cell. In such cases, multiple strategies are applied one after the other to fill a single cell. We observe that Transformer models trained on this synthetic task can indeed learn to solve Sudokus (our model solves $94.21\%$ of the puzzles fully correctly) when trained on a logical sequence of steps taken by a solver. We find that training Transformers with the logical sequence of steps is necessary and without such training, they fail to learn Sudoku. We also extend our analysis to Zebra puzzles (known as Einstein puzzles) and show that the model solves $92.04 \%$ of the puzzles fully correctly. In addition, we study the internal representations of the trained Transformer and find that through linear probing, we can decode information about the set of possible values in any given cell from them, pointing to the presence of a strong reasoning engine implicit in the Transformer weights.
Neuro-Symbolic Sudoku Solver
Jul 02, 2023



Deep Neural Networks have achieved great success in some of the complex tasks that humans can do with ease. These include image recognition/classification, natural language processing, game playing etc. However, modern Neural Networks fail or perform poorly when trained on tasks that can be solved easily using backtracking and traditional algorithms. Therefore, we use the architecture of the Neuro Logic Machine (NLM) and extend its functionality to solve a 9X9 game of Sudoku. To expand the application of NLMs, we generate a random grid of cells from a dataset of solved games and assign up to 10 new empty cells. The goal of the game is then to find a target value ranging from 1 to 9 and fill in the remaining empty cells while maintaining a valid configuration. In our study, we showcase an NLM which is capable of obtaining 100% accuracy for solving a Sudoku with empty cells ranging from 3 to 10. The purpose of this study is to demonstrate that NLMs can also be used for solving complex problems and games like Sudoku. We also analyze the behaviour of NLMs with a backtracking algorithm by comparing the convergence time using a graph plot on the same problem. With this study we show that Neural Logic Machines can be trained on the tasks that traditional Deep Learning architectures fail using Reinforcement Learning. We also aim to propose the importance of symbolic learning in explaining the systematicity in the hybrid model of NLMs.