 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Desnowing
Papers and Code
Wavelet-Enhanced Desnowing: A Novel Single Image Restoration Approach for Traffic Surveillance under Adverse Weather Conditions
Mar 03, 2025Image restoration under adverse weather conditions refers to the process of removing degradation caused by weather particles while improving visual quality. Most existing deweathering methods rely on increasing the network scale and data volume to achieve better performance which requires more expensive computing power. Also, many methods lack generalization for specific applications. In the traffic surveillance screener, the main challenges are snow removal and veil effect elimination. In this paper, we propose a wavelet-enhanced snow removal method that use a Dual-Tree Complex Wavelet Transform feature enhancement module and a dynamic convolution acceleration module to address snow degradation in surveillance images. We also use a residual learning restoration module to remove veil effects caused by rain, snow, and fog. The proposed architecture extracts and analyzes information from snow-covered regions, significantly improving snow removal performance. And the residual learning restoration module removes veiling effects in images, enhancing clarity and detail. Experiments show that it performs better than some popular desnowing methods. Our approach also demonstrates effectiveness and accuracy when applied to real traffic surveillance images.
End-to-end Inception-Unet based Generative Adversarial Networks for Snow and Rain Removals
Nov 07, 2024



The superior performance introduced by deep learning approaches in removing atmospheric particles such as snow and rain from a single image; favors their usage over classical ones. However, deep learning-based approaches still suffer from challenges related to the particle appearance characteristics such as size, type, and transparency. Furthermore, due to the unique characteristics of rain and snow particles, single network based deep learning approaches struggle in handling both degradation scenarios simultaneously. In this paper, a global framework that consists of two Generative Adversarial Networks (GANs) is proposed where each handles the removal of each particle individually. The architectures of both desnowing and deraining GANs introduce the integration of a feature extraction phase with the classical U-net generator network which in turn enhances the removal performance in the presence of severe variations in size and appearance. Furthermore, a realistic dataset that contains pairs of snowy images next to their groundtruth images estimated using a low-rank approximation approach; is presented. The experiments show that the proposed desnowing and deraining approaches achieve significant improvements in comparison to the state-of-the-art approaches when tested on both synthetic and realistic datasets.
Restorer: Solving Multiple Image Restoration Tasks with One Set of Parameters
Jun 18, 2024



Although there are many excellent solutions in image restoration, the fact that they are specifically designed for a single image restoration task may prevent them from being state-of-the-art (SOTA) in other types of image restoration tasks. While some approaches require considering multiple image restoration tasks, they are still not sufficient for the requirements of the real world and may suffer from the task confusion issue. In this work, we focus on designing a unified and effective solution for multiple image restoration tasks including deraining, desnowing, defogging, deblurring, denoising, and low-light enhancement. Based on the above purpose, we propose a Transformer network Restorer with U-Net architecture. In order to effectively deal with degraded information in multiple image restoration tasks, we need a more comprehensive attention mechanism. Thus, we design all-axis attention (AAA) through stereo embedding and 3D convolution, which can simultaneously model the long-range dependencies in both spatial and channel dimensions, capturing potential correlations among all axis. Moreover, we propose a Restorer based on textual prompts. Compared to previous methods that employ learnable queries, textual prompts bring explicit task priors to solve the task confusion issue arising from learnable queries and introduce interactivity. Based on these designs, Restorer demonstrates SOTA or comparable performance in multiple image restoration tasks compared to universal image restoration frameworks and methods specifically designed for these individual tasks. Meanwhile, Restorer is faster during inference. The above results along with the real-world test results show that Restorer has the potential to serve as a backbone for multiple real-world image restoration tasks.
Star-Net: Improving Single Image Desnowing Model With More Efficient Connection and Diverse Feature Interaction
Mar 17, 2023Compared to other severe weather image restoration tasks, single image desnowing is a more challenging task. This is mainly due to the diversity and irregularity of snow shape, which makes it extremely difficult to restore images in snowy scenes. Moreover, snow particles also have a veiling effect similar to haze or mist. Although current works can effectively remove snow particles with various shapes, they also bring distortion to the restored image. To address these issues, we propose a novel single image desnowing network called Star-Net. First, we design a Star type Skip Connection (SSC) to establish information channels for all different scale features, which can deal with the complex shape of snow particles.Second, we present a Multi-Stage Interactive Transformer (MIT) as the base module of Star-Net, which is designed to better understand snow particle shapes and to address image distortion by explicitly modeling a variety of important image recovery features. Finally, we propose a Degenerate Filter Module (DFM) to filter the snow particle and snow fog residual in the SSC on the spatial and channel domains. Extensive experiments show that our Star-Net achieves state-of-the-art snow removal performances on three standard snow removal datasets and retains the original sharpness of the images.
SnowFormer: Scale-aware Transformer via Context Interaction for Single Image Desnowing
Aug 23, 2022
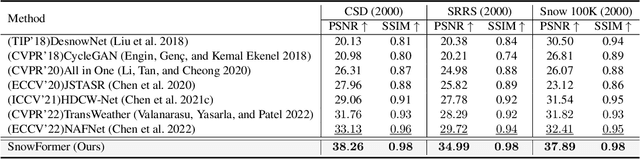
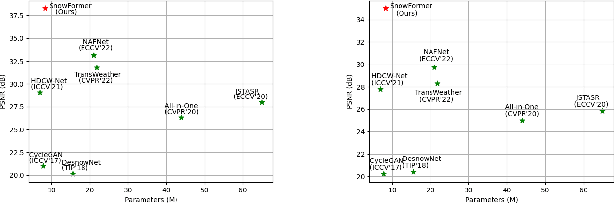
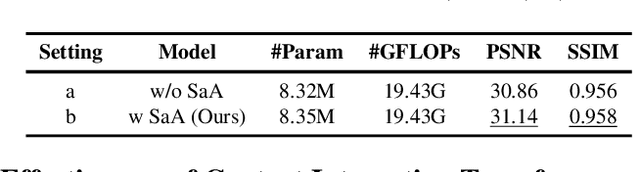
Single image desnowing is a common yet challenging task. The complex snow degradations and diverse degradation scales demand strong representation ability. In order for the desnowing network to see various snow degradations and model the context interaction of local details and global information, we propose a powerful architecture dubbed as SnowFormer. First, it performs Scale-aware Feature Aggregation in the encoder to capture rich snow information of various degradations. Second, in order to tackle with large-scale degradation, it uses a novel Context Interaction Transformer Block in the decoder, which conducts context interaction of local details and global information from previous scale-aware feature aggregation in global context interaction. And the introduction of local context interaction improves recovery of scene details. Third, we devise a Heterogeneous Feature Projection Head which progressively fuse features from both the encoder and decoder and project the refined feature into the clean image. Extensive experiments demonstrate that the proposed SnowFormer achieves significant improvements over other SOTA methods. Compared with SOTA single image desnowing method HDCW-Net, it boosts the PSNR metric by 9.2dB on the CSD testset. Moreover, it also achieves a 5.13dB increase in PSNR compared with general image restoration architecture NAFNet, which verifies the strong representation ability of our SnowFormer for snow removal task. The code is released in \url{https://github.com/Ephemeral182/SnowFormer}.
Cross-Stitched Multi-task Dual Recursive Networks for Unified Single Image Deraining and Desnowing
Nov 15, 2022



We present the Cross-stitched Multi-task Unified Dual Recursive Network (CMUDRN) model targeting the task of unified deraining and desnowing in a multi-task learning setting. This unified model borrows from the basic Dual Recursive Network (DRN) architecture developed by Cai et al. The proposed model makes use of cross-stitch units that enable multi-task learning across two separate DRN models, each tasked for single image deraining and desnowing, respectively. By fixing cross-stitch units at several layers of basic task-specific DRN networks, we perform multi-task learning over the two separate DRN models. To enable blind image restoration, on top of these structures we employ a simple neural fusion scheme which merges the output of each DRN. The separate task-specific DRN models and the fusion scheme are simultaneously trained by enforcing local and global supervision. Local supervision is applied on the two DRN submodules, and global supervision is applied on the data fusion submodule of the proposed model. Consequently, we both enable feature sharing across task-specific DRN models and control the image restoration behavior of the DRN submodules. An ablation study shows the strength of the hypothesized CMUDRN model, and experiments indicate that its performance is comparable or better than baseline DRN models on the single image deraining and desnowing tasks. Moreover, CMUDRN enables blind image restoration for the two underlying image restoration tasks, by unifying task-specific image restoration pipelines via a naive parametric fusion scheme. The CMUDRN implementation is available at https://github.com/VCL3D/CMUDRN.
MSP-Former: Multi-Scale Projection Transformer for Single Image Desnowing
Jul 17, 2022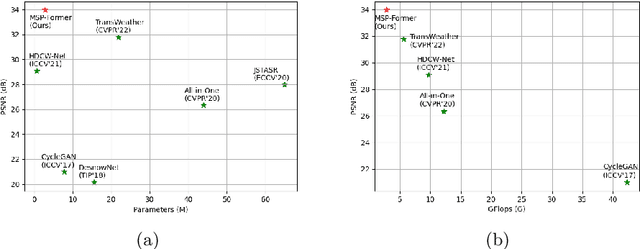
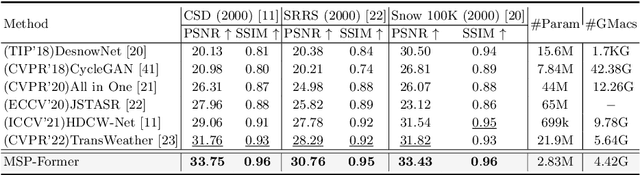

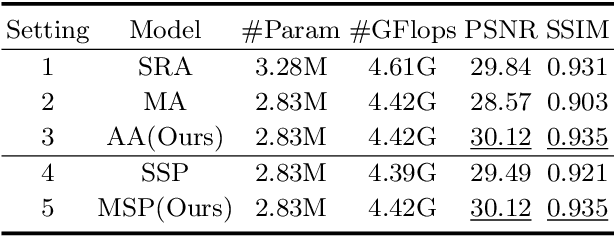
Image restoration of snow scenes in severe weather is a difficult task. Snow images have complex degradations and are cluttered over clean images, changing the distribution of clean images. The previous methods based on CNNs are challenging to remove perfectly in restoring snow scenes due to their local inductive biases' lack of a specific global modeling ability. In this paper, we apply the vision transformer to the task of snow removal from a single image. Specifically, we propose a parallel network architecture split along the channel, performing local feature refinement and global information modeling separately. We utilize a channel shuffle operation to combine their respective strengths to enhance network performance. Second, we propose the MSP module, which utilizes multi-scale avgpool to aggregate information of different sizes and simultaneously performs multi-scale projection self-attention on multi-head self-attention to improve the representation ability of the model under different scale degradations. Finally, we design a lightweight and simple local capture module, which can refine the local capture capability of the model. In the experimental part, we conduct extensive experiments to demonstrate the superiority of our method. We compared the previous snow removal methods on three snow scene datasets. The experimental results show that our method surpasses the state-of-the-art methods with fewer parameters and computation. We achieve substantial growth by 1.99dB and SSIM 0.03 on the CSD test dataset. On the SRRS and Snow100K datasets, we also increased PSNR by 2.47dB and 1.62dB compared with the Transweather approach and improved by 0.03 in SSIM. In the visual comparison section, our MSP-Former also achieves better visual effects than existing methods, proving the usability of our method.
Towards Efficient Single Image Dehazing and Desnowing
Apr 19, 2022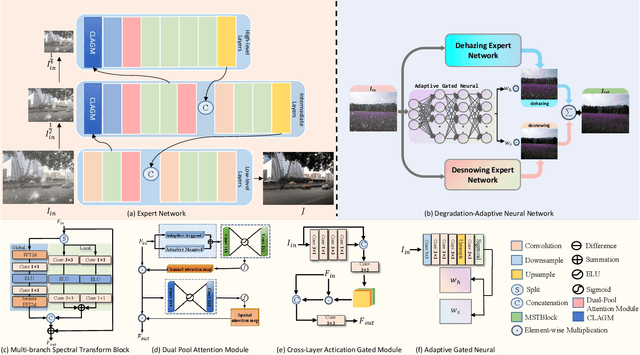
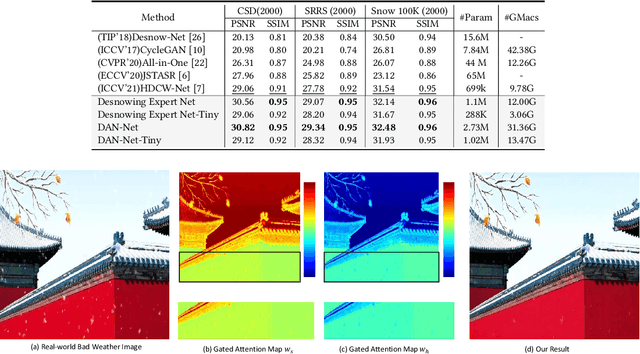

Removing adverse weather conditions like rain, fog, and snow from images is a challenging problem. Although the current recovery algorithms targeting a specific condition have made impressive progress, it is not flexible enough to deal with various degradation types. We propose an efficient and compact image restoration network named DAN-Net (Degradation-Adaptive Neural Network) to address this problem, which consists of multiple compact expert networks with one adaptive gated neural. A single expert network efficiently addresses specific degradation in nasty winter scenes relying on the compact architecture and three novel components. Based on the Mixture of Experts strategy, DAN-Net captures degradation information from each input image to adaptively modulate the outputs of task-specific expert networks to remove various adverse winter weather conditions. Specifically, it adopts a lightweight Adaptive Gated Neural Network to estimate gated attention maps of the input image, while different task-specific experts with the same topology are jointly dispatched to process the degraded image. Such novel image restoration pipeline handles different types of severe weather scenes effectively and efficiently. It also enjoys the benefit of coordinate boosting in which the whole network outperforms each expert trained without coordination. Extensive experiments demonstrate that the presented manner outperforms the state-of-the-art single-task methods on image quality and has better inference efficiency. Furthermore, we have collected the first real-world winter scenes dataset to evaluate winter image restoration methods, which contains various hazy and snowy images snapped in winter. Both the dataset and source code will be publicly available.
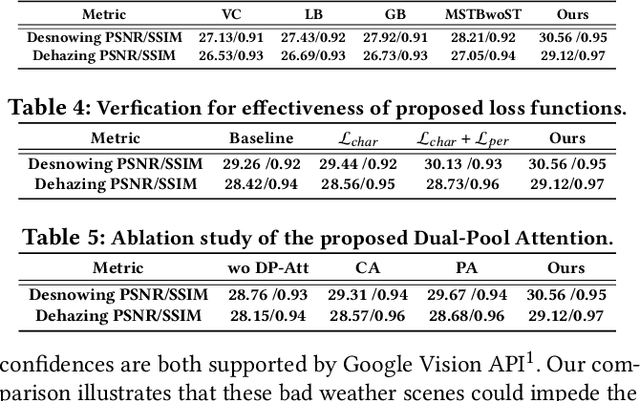
Dual-former: Hybrid Self-attention Transformer for Efficient Image Restoration
Oct 03, 2022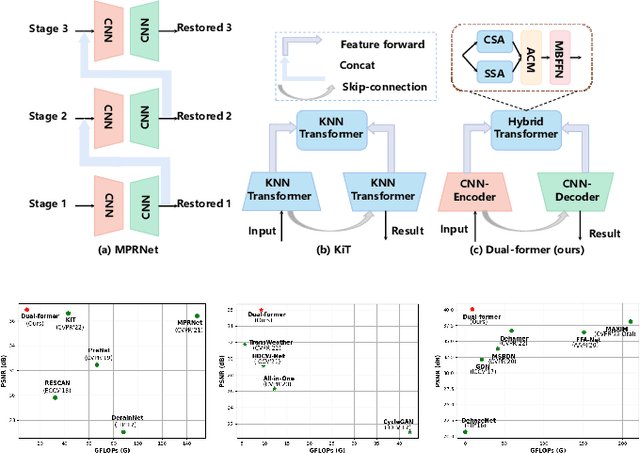

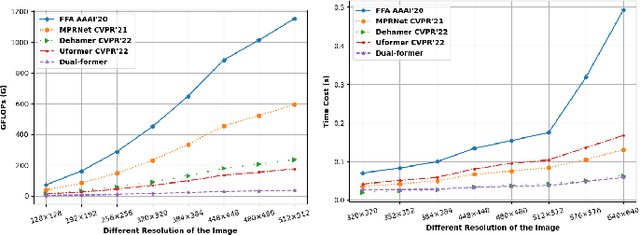
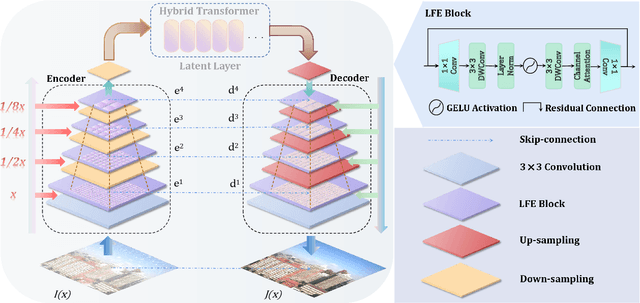
Recently, image restoration transformers have achieved comparable performance with previous state-of-the-art CNNs. However, how to efficiently leverage such architectures remains an open problem. In this work, we present Dual-former whose critical insight is to combine the powerful global modeling ability of self-attention modules and the local modeling ability of convolutions in an overall architecture. With convolution-based Local Feature Extraction modules equipped in the encoder and the decoder, we only adopt a novel Hybrid Transformer Block in the latent layer to model the long-distance dependence in spatial dimensions and handle the uneven distribution between channels. Such a design eliminates the substantial computational complexity in previous image restoration transformers and achieves superior performance on multiple image restoration tasks. Experiments demonstrate that Dual-former achieves a 1.91dB gain over the state-of-the-art MAXIM method on the Indoor dataset for single image dehazing while consuming only 4.2% GFLOPs as MAXIM. For single image deraining, it exceeds the SOTA method by 0.1dB PSNR on the average results of five datasets with only 21.5% GFLOPs. Dual-former also substantially surpasses the latest desnowing method on various datasets, with fewer parameters.
DRT: A Lightweight Single Image Deraining Recursive Transformer
Apr 25, 2022
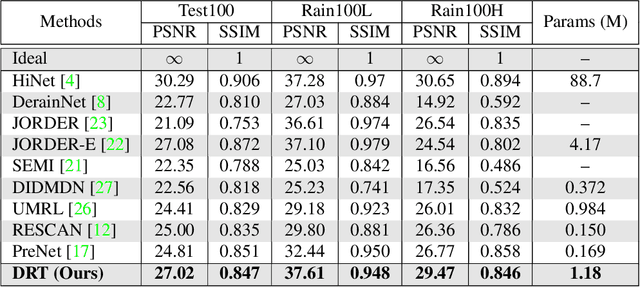
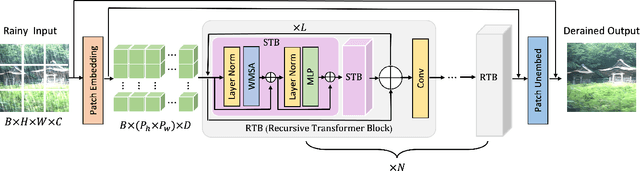
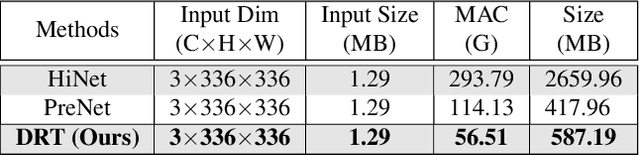
Over parameterization is a common technique in deep learning to help models learn and generalize sufficiently to the given task; nonetheless, this often leads to enormous network structures and consumes considerable computing resources during training. Recent powerful transformer-based deep learning models on vision tasks usually have heavy parameters and bear training difficulty. However, many dense-prediction low-level computer vision tasks, such as rain streak removing, often need to be executed on devices with limited computing power and memory in practice. Hence, we introduce a recursive local window-based self-attention structure with residual connections and propose deraining a recursive transformer (DRT), which enjoys the superiority of the transformer but requires a small amount of computing resources. In particular, through recursive architecture, our proposed model uses only 1.3% of the number of parameters of the current best performing model in deraining while exceeding the state-of-the-art methods on the Rain100L benchmark by at least 0.33 dB. Ablation studies also investigate the impact of recursions on derain outcomes. Moreover, since the model contains no deliberate design for deraining, it can also be applied to other image restoration tasks. Our experiment shows that it can achieve competitive results on desnowing. The source code and pretrained model can be found at https://github.com/YC-Liang/DRT.