 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalt And Pepper Noise Removal
Papers and Code
Recursive Threshold Median Filter and Autoencoder for Salt-and-Pepper Denoising: SSIM analysis of Images and Entropy Maps
Nov 15, 2025This paper studies the removal of salt-and-pepper noise from images using median filter (MF) and simple three-layer autoencoder (AE) within recursive threshold algorithm. The performance of denoising is assessed with two metrics: the standard Structural Similarity Index SSIMImg of restored and clean images and a newly applied metric SSIMMap - the SSIM of entropy maps of these images computed via 2D Sample Entropy in sliding windows. We shown that SSIMMap is more sensitive to blur and local intensity transitions and complements SSIMImg. Experiments on low- and high-resolution grayscales images demonstrate that recursive threshold MF robustly restores images even under strong noise (50-60 %), whereas simple AE is only capable of restoring images with low levels of noise (<30 %). We propose two scalable schemes: (i) 2MF, which uses two MFs with different window sizes and a final thresholding step, effective for highlighting sharp local details at low resolution; and (ii) MFs-AE, which aggregates features from multiple MFs via an AE and is beneficial for restoring the overall scene structure at higher resolution. Owing to its simplicity and computational efficiency, MF remains preferable for deployment on resource-constrained platforms (edge/IoT), whereas AE underperforms without prior denoising. The results also validate the practical value of SSIMMap for objective blur assessment and denoising parameter tuning.
Adaptive Weight Modified Riesz Mean Filter For High-Density Salt and Pepper Noise Removal
Apr 28, 2025This paper introduces a novel filter, the Adaptive Weight Modified Riesz Mean Filter (AWMRmF), designed for the effective removal of high-density salt and pepper noise (SPN). AWMRmF integrates a pixel weight function and adaptivity condition inspired by the Different Adaptive Modified Riesz Mean Filter (DAMRmF). In my simulations, I evaluated the performance of AWMRmF against established filters such as Adaptive Frequency Median Filter (AFMF), Adaptive Weighted Mean Filter (AWMF), Adaptive Cesaro Mean Filter (ACmF), Adaptive Riesz Mean Filter (ARmF), and Improved Adaptive Weighted Mean Filter (IAWMF). The assessment was conducted on 26 typical test images, varying noise levels from 60% to 95%. The findings indicate that, in terms of both Peak Signal to Noise Ratio (PSNR) and Structural Similarity (SSIM) metrics, AWMRmF outperformed other state-of-the-art filters. Furthermore, AWMRmF demonstrated superior performance in mean PSNR and SSIM results as well.
Assessing The Impact of CNN Auto Encoder-Based Image Denoising on Image Classification Tasks
Apr 16, 2024



Images captured from the real world are often affected by different types of noise, which can significantly impact the performance of Computer Vision systems and the quality of visual data. This study presents a novel approach for defect detection in casting product noisy images, specifically focusing on submersible pump impellers. The methodology involves utilizing deep learning models such as VGG16, InceptionV3, and other models in both the spatial and frequency domains to identify noise types and defect status. The research process begins with preprocessing images, followed by applying denoising techniques tailored to specific noise categories. The goal is to enhance the accuracy and robustness of defect detection by integrating noise detection and denoising into the classification pipeline. The study achieved remarkable results using VGG16 for noise type classification in the frequency domain, achieving an accuracy of over 99%. Removal of salt and pepper noise resulted in an average SSIM of 87.9, while Gaussian noise removal had an average SSIM of 64.0, and periodic noise removal yielded an average SSIM of 81.6. This comprehensive approach showcases the effectiveness of the deep AutoEncoder model and median filter, for denoising strategies in real-world industrial applications. Finally, our study reports significant improvements in binary classification accuracy for defect detection compared to previous methods. For the VGG16 classifier, accuracy increased from 94.6% to 97.0%, demonstrating the effectiveness of the proposed noise detection and denoising approach. Similarly, for the InceptionV3 classifier, accuracy improved from 84.7% to 90.0%, further validating the benefits of integrating noise analysis into the classification pipeline.
All-optical image denoising using a diffractive visual processor
Sep 17, 2023Image denoising, one of the essential inverse problems, targets to remove noise/artifacts from input images. In general, digital image denoising algorithms, executed on computers, present latency due to several iterations implemented in, e.g., graphics processing units (GPUs). While deep learning-enabled methods can operate non-iteratively, they also introduce latency and impose a significant computational burden, leading to increased power consumption. Here, we introduce an analog diffractive image denoiser to all-optically and non-iteratively clean various forms of noise and artifacts from input images - implemented at the speed of light propagation within a thin diffractive visual processor. This all-optical image denoiser comprises passive transmissive layers optimized using deep learning to physically scatter the optical modes that represent various noise features, causing them to miss the output image Field-of-View (FoV) while retaining the object features of interest. Our results show that these diffractive denoisers can efficiently remove salt and pepper noise and image rendering-related spatial artifacts from input phase or intensity images while achieving an output power efficiency of ~30-40%. We experimentally demonstrated the effectiveness of this analog denoiser architecture using a 3D-printed diffractive visual processor operating at the terahertz spectrum. Owing to their speed, power-efficiency, and minimal computational overhead, all-optical diffractive denoisers can be transformative for various image display and projection systems, including, e.g., holographic displays.
A deep convolutional neural network for salt-and-pepper noise removal using selective convolutional blocks
Feb 10, 2023In recent years, there has been an unprecedented upsurge in applying deep learning approaches, specifically convolutional neural networks (CNNs), to solve image denoising problems, owing to their superior performance. However, CNNs mostly rely on Gaussian noise, and there is a conspicuous lack of exploiting CNNs for salt-and-pepper (SAP) noise reduction. In this paper, we proposed a deep CNN model, namely SeConvNet, to suppress SAP noise in gray-scale and color images. To meet this objective, we introduce a new selective convolutional (SeConv) block. SeConvNet is compared to state-of-the-art SAP denoising methods using extensive experiments on various common datasets. The results illustrate that the proposed SeConvNet model effectively restores images corrupted by SAP noise and surpasses all its counterparts at both quantitative criteria and visual effects, especially at high and very high noise densities.
A Two-stage Method for Non-extreme Value Salt-and-Pepper Noise Removal
Jun 20, 2022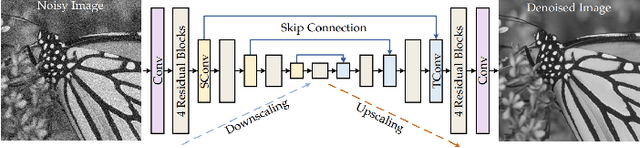


There are several previous methods based on neural network can have great performance in denoising salt and pepper noise. However, those methods are based on a hypothesis that the value of salt and pepper noise is exactly 0 and 255. It is not true in the real world. The result of those methods deviate sharply when the value is different from 0 and 255. To overcome this weakness, our method aims at designing a convolutional neural network to detect the noise pixels in a wider range of value and then a filter is used to modify pixel value to 0, which is beneficial for further filtering. Additionally, another convolutional neural network is used to conduct the denoising and restoration work.
Salt and pepper noise removal method based on stationary Framelet transform with non-convex sparsity regularization
Nov 02, 2021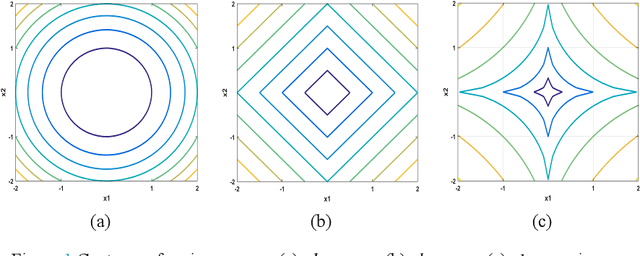
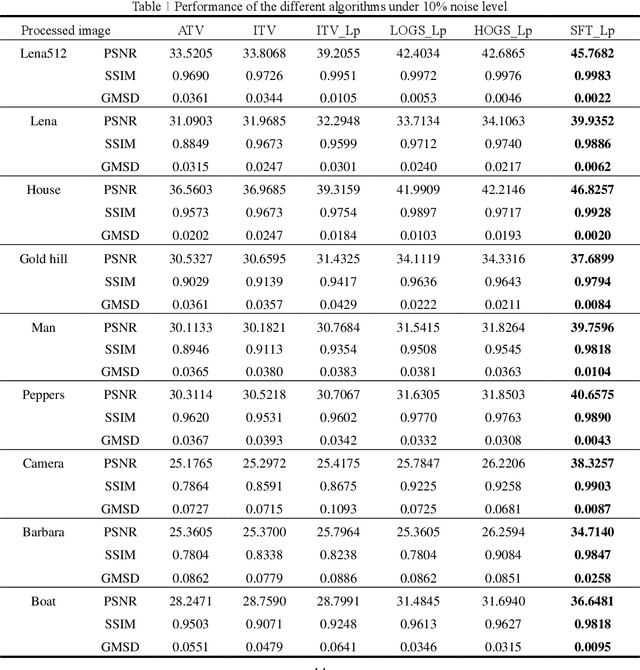
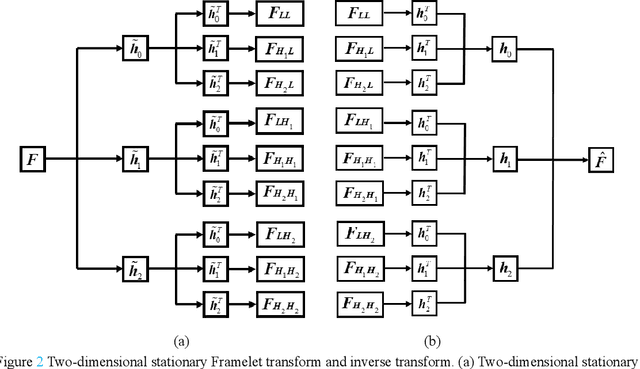
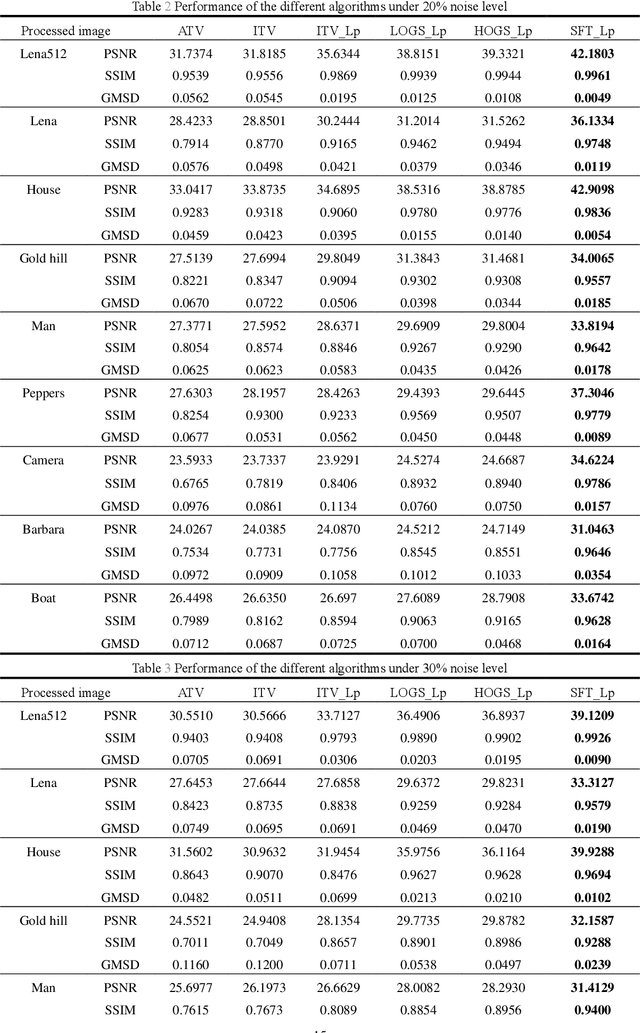
Salt and pepper noise removal is a common inverse problem in image processing. Traditional denoising methods have two limitations. First, noise characteristics are often not described accurately. For example, the noise location information is often ignored and the sparsity of the salt and pepper noise is often described by L1 norm, which cannot illustrate the sparse variables clearly. Second, conventional methods separate the contaminated image into a recovered image and a noise part, thus resulting in recovering an image with unsatisfied smooth parts and detail parts. In this study, we introduce a noise detection strategy to determine the position of the noise, and a non-convex sparsity regularization depicted by Lp quasi-norm is employed to describe the sparsity of the noise, thereby addressing the first limitation. The morphological component analysis framework with stationary Framelet transform is adopted to decompose the processed image into cartoon, texture, and noise parts to resolve the second limitation. Then, the alternating direction method of multipliers (ADMM) is employed to solve the proposed model. Finally, experiments are conducted to verify the proposed method and compare it with some current state-of-the-art denoising methods. The experimental results show that the proposed method can remove salt and pepper noise while preserving the details of the processed image.
End-to-End Unsupervised Document Image Blind Denoising
May 19, 2021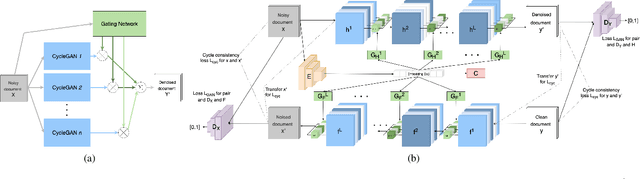
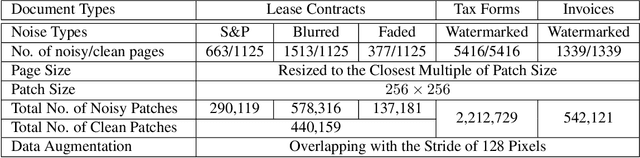
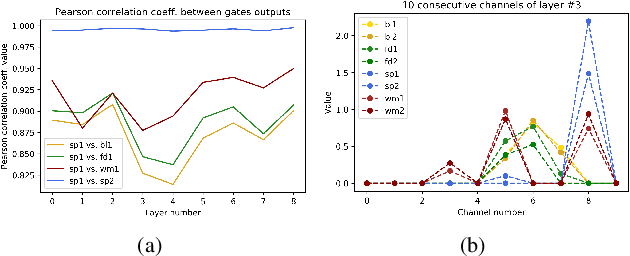
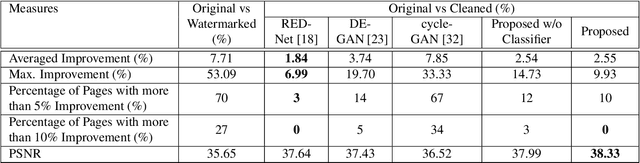
Removing noise from scanned pages is a vital step before their submission to optical character recognition (OCR) system. Most available image denoising methods are supervised where the pairs of noisy/clean pages are required. However, this assumption is rarely met in real settings. Besides, there is no single model that can remove various noise types from documents. Here, we propose a unified end-to-end unsupervised deep learning model, for the first time, that can effectively remove multiple types of noise, including salt \& pepper noise, blurred and/or faded text, as well as watermarks from documents at various levels of intensity. We demonstrate that the proposed model significantly improves the quality of scanned images and the OCR of the pages on several test datasets.
Noise2Kernel: Adaptive Self-Supervised Blind Denoising using a Dilated Convolutional Kernel Architecture
Dec 07, 2020
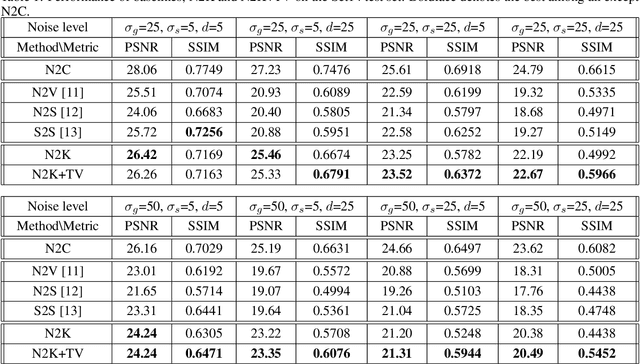
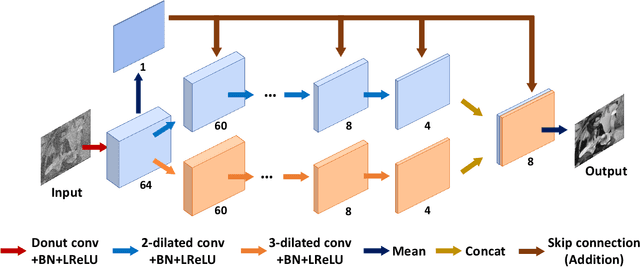

With the advent of recent advances in unsupervised learning, efficient training of a deep network for image denoising without pairs of noisy and clean images has become feasible. However, most current unsupervised denoising methods are built on the assumption of zero-mean noise under the signal-independent condition. This assumption causes blind denoising techniques to suffer brightness shifting problems on images that are greatly corrupted by extreme noise such as salt-and-pepper noise. Moreover, most blind denoising methods require a random masking scheme for training to ensure the invariance of the denoising process. In this paper, we propose a dilated convolutional network that satisfies an invariant property, allowing efficient kernel-based training without random masking. We also propose an adaptive self-supervision loss to circumvent the requirement of zero-mean constraint, which is specifically effective in removing salt-and-pepper or hybrid noise where a prior knowledge of noise statistics is not readily available. We demonstrate the efficacy of the proposed method by comparing it with state-of-the-art denoising methods using various examples.
NAMF: A Non-local Adaptive Mean Filter for Salt-and-Pepper Noise Removal
Oct 17, 2019

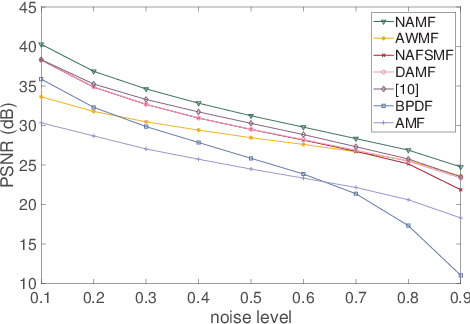
In this paper, a non-local adaptive mean filter (NAMF) is proposed, which can eliminate all levels of salt-and-pepper (SAP) noise. NAMF can be divided into two stages: (1) SAP noise detection; (2) SAP noise elimination. For a given pixel, firstly, we compare it with the maximum or minimum gray value of the noisy image, if it equals then we use a window with adaptive size to further determine whether it is noisy, and the noiseless pixel will be left. Secondly, the noisy pixel will be replaced by the combination of its neighboring pixels. And finally we use a SAP noise based non-local mean filter to further restore it. Our experimental results show that NAMF outperforms state-of-the-art methods in terms of quality for restoring image at all SAP noise levels.