 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePidray
Papers and Code
GSA-YOLO: A High-Efficiency Framework via Structured Sparsity and Adaptive Knowledge Distillation for Real-Time X-ray Security Inspection
May 20, 2026X-ray security inspection requires accurate real-time detection of prohibited items, but existing models often struggle to balance the challenges of severe occlusion, complex clutter, and strict speed requirements. To overcome these challenges, this paper proposes GSA-YOLO, a novel lightweight framework built upon the YOLOv8n architecture, specifically engineered to enhance detection robustness and inference efficiency. GSA-YOLO strategically integrates structured sparsity and adaptive knowledge transfer through three core components: Group Lasso (GL) applied to the network neck for robust feature extraction; Sparse Structure Selection (SSS) applied to the detection head for significant model slimming; and an Adaptive Knowledge Distillation (Ada-KD) mechanism for comprehensive accuracy recovery. This integrated approach synergistically enhances feature representation while pruning redundant channels, maximizing model efficiency without sacrificing performance. Rigorous evaluations on the HiXray and PIDray datasets confirm GSA-YOLO's comprehensive capability, achieving a leading inference speed of 189.62 FPS, accompanied by a reduction in computational cost from 8.7G to 8.0G. Crucially, GSA-YOLO secures mAP50:95 results of 0.531 and 0.679 on HiXray and PIDray, demonstrating 2.4% and 1.8% improvements over the baseline, respectively. Compared to other models, GSA-YOLO exhibits enhanced accuracy while maintaining computational efficiency, making it a promising solution for practical X-ray security inspection.
Illicit object detection in X-ray imaging using deep learning techniques: A comparative evaluation
Jul 23, 2025Automated X-ray inspection is crucial for efficient and unobtrusive security screening in various public settings. However, challenges such as object occlusion, variations in the physical properties of items, diversity in X-ray scanning devices, and limited training data hinder accurate and reliable detection of illicit items. Despite the large body of research in the field, reported experimental evaluations are often incomplete, with frequently conflicting outcomes. To shed light on the research landscape and facilitate further research, a systematic, detailed, and thorough comparative evaluation of recent Deep Learning (DL)-based methods for X-ray object detection is conducted. For this, a comprehensive evaluation framework is developed, composed of: a) Six recent, large-scale, and widely used public datasets for X-ray illicit item detection (OPIXray, CLCXray, SIXray, EDS, HiXray, and PIDray), b) Ten different state-of-the-art object detection schemes covering all main categories in the literature, including generic Convolutional Neural Network (CNN), custom CNN, generic transformer, and hybrid CNN-transformer architectures, and c) Various detection (mAP50 and mAP50:95) and time/computational-complexity (inference time (ms), parameter size (M), and computational load (GFLOPS)) metrics. A thorough analysis of the results leads to critical observations and insights, emphasizing key aspects such as: a) Overall behavior of the object detection schemes, b) Object-level detection performance, c) Dataset-specific observations, and d) Time efficiency and computational complexity analysis. To support reproducibility of the reported experimental results, the evaluation code and model weights are made publicly available at https://github.com/jgenc/xray-comparative-evaluation.
Prohibited Items Segmentation via Occlusion-aware Bilayer Modeling
Jun 13, 2025



Instance segmentation of prohibited items in security X-ray images is a critical yet challenging task. This is mainly caused by the significant appearance gap between prohibited items in X-ray images and natural objects, as well as the severe overlapping among objects in X-ray images. To address these issues, we propose an occlusion-aware instance segmentation pipeline designed to identify prohibited items in X-ray images. Specifically, to bridge the representation gap, we integrate the Segment Anything Model (SAM) into our pipeline, taking advantage of its rich priors and zero-shot generalization capabilities. To address the overlap between prohibited items, we design an occlusion-aware bilayer mask decoder module that explicitly models the occlusion relationships. To supervise occlusion estimation, we manually annotated occlusion areas of prohibited items in two large-scale X-ray image segmentation datasets, PIDray and PIXray. We then reorganized these additional annotations together with the original information as two occlusion-annotated datasets, PIDray-A and PIXray-A. Extensive experimental results on these occlusion-annotated datasets demonstrate the effectiveness of our proposed method. The datasets and codes are available at: https://github.com/Ryh1218/Occ
X-ray illicit object detection using hybrid CNN-transformer neural network architectures
May 01, 2025In the field of X-ray security applications, even the smallest details can significantly impact outcomes. Objects that are heavily occluded or intentionally concealed pose a great challenge for detection, whether by human observation or through advanced technological applications. While certain Deep Learning (DL) architectures demonstrate strong performance in processing local information, such as Convolutional Neural Networks (CNNs), others excel in handling distant information, e.g., transformers. In X-ray security imaging the literature has been dominated by the use of CNN-based methods, while the integration of the two aforementioned leading architectures has not been sufficiently explored. In this paper, various hybrid CNN-transformer architectures are evaluated against a common CNN object detection baseline, namely YOLOv8. In particular, a CNN (HGNetV2) and a hybrid CNN-transformer (Next-ViT-S) backbone are combined with different CNN/transformer detection heads (YOLOv8 and RT-DETR). The resulting architectures are comparatively evaluated on three challenging public X-ray inspection datasets, namely EDS, HiXray, and PIDray. Interestingly, while the YOLOv8 detector with its default backbone (CSP-DarkNet53) is generally shown to be advantageous on the HiXray and PIDray datasets, when a domain distribution shift is incorporated in the X-ray images (as happens in the EDS datasets), hybrid CNN-transformer architectures exhibit increased robustness. Detailed comparative evaluation results, including object-level detection performance and object-size error analysis, demonstrate the strengths and weaknesses of each architectural combination and suggest guidelines for future research. The source code and network weights of the models employed in this study are available at https://github.com/jgenc/xray-comparative-evaluation.
Open-Vocabulary X-ray Prohibited Item Detection via Fine-tuning CLIP
Jun 16, 2024



X-ray prohibited item detection is an essential component of security check and categories of prohibited item are continuously increasing in accordance with the latest laws. Previous works all focus on close-set scenarios, which can only recognize known categories used for training and often require time-consuming as well as labor-intensive annotations when learning novel categories, resulting in limited real-world applications. Although the success of vision-language models (e.g. CLIP) provides a new perspectives for open-set X-ray prohibited item detection, directly applying CLIP to X-ray domain leads to a sharp performance drop due to domain shift between X-ray data and general data used for pre-training CLIP. To address aforementioned challenges, in this paper, we introduce distillation-based open-vocabulary object detection (OVOD) task into X-ray security inspection domain by extending CLIP to learn visual representations in our specific X-ray domain, aiming to detect novel prohibited item categories beyond base categories on which the detector is trained. Specifically, we propose X-ray feature adapter and apply it to CLIP within OVOD framework to develop OVXD model. X-ray feature adapter containing three adapter submodules of bottleneck architecture, which is simple but can efficiently integrate new knowledge of X-ray domain with original knowledge, further bridge domain gap and promote alignment between X-ray images and textual concepts. Extensive experiments conducted on PIXray and PIDray datasets demonstrate that proposed method performs favorably against other baseline OVOD methods in detecting novel categories in X-ray scenario. It outperforms previous best result by 15.2 AP50 and 1.5 AP50 on PIXray and PIDray with achieving 21.0 AP50 and 27.8 AP50 respectively.
SegLoc: Visual Self-supervised Learning Scheme for Dense Prediction Tasks of Security Inspection X-ray Images
Oct 21, 2023



Lately, remarkable advancements of artificial intelligence have been attributed to the integration of self-supervised learning (SSL) scheme. Despite impressive achievements within natural language processing (NLP), SSL in computer vision has not been able to stay on track comparatively. Recently, integration of contrastive learning on top of existing visual SSL models has established considerable progress, thereby being able to outperform supervised counterparts. Nevertheless, the improvements were mostly limited to classification tasks; moreover, few studies have evaluated visual SSL models in real-world scenarios, while the majority considered datasets containing class-wise portrait images, notably ImageNet. Thus, here, we have considered dense prediction tasks on security inspection x-ray images to evaluate our proposed model Segmentation Localization (SegLoc). Based upon the model Instance Localization (InsLoc), our model has managed to address one of the most challenging downsides of contrastive learning, i.e., false negative pairs of query embeddings. To do so, our pre-training dataset is synthesized by cutting, transforming, then pasting labeled segments, as foregrounds, from an already existing labeled dataset (PIDray) onto instances, as backgrounds, of an unlabeled dataset (SIXray;) further, we fully harness the labels through integration of the notion, one queue per class, into MoCo-v2 memory bank, avoiding false negative pairs. Regarding the task in question, our approach has outperformed random initialization method by 3% to 6%, while having underperformed supervised initialization, in AR and AP metrics at different IoU values for 20 to 30 pre-training epochs.
Self-Supervised One-Shot Learning for Automatic Segmentation of StyleGAN Images
Mar 17, 2023



We propose a framework for the automatic one-shot segmentation of synthetic images generated by a StyleGAN. Our framework is based on the observation that the multi-scale hidden features in the GAN generator hold useful semantic information that can be utilized for automatic on-the-fly segmentation of the generated images. Using these features, our framework learns to segment synthetic images using a self-supervised contrastive clustering algorithm that projects the hidden features into a compact space for per-pixel classification. This novel contrastive learner is based on using a pixel-wise swapped prediction loss for image segmentation that leads to faster learning of the feature vectors for one-shot segmentation. We have tested our implementation on a number of standard benchmarks to yield a segmentation performance that not only outperforms the semi-supervised baseline methods by an average wIoU margin of 1.02% but also improves the inference speeds by a factor of 4.5. Finally, we also show the results of using the proposed one-shot learner in implementing BagGAN, a framework for producing annotated synthetic baggage X-ray scans for threat detection. This framework was trained and tested on the PIDRay baggage benchmark to yield a performance comparable to its baseline segmenter based on manual annotations.
PIDray: A Large-scale X-ray Benchmark for Real-World Prohibited Item Detection
Nov 19, 2022Automatic security inspection relying on computer vision technology is a challenging task in real-world scenarios due to many factors, such as intra-class variance, class imbalance, and occlusion. Most previous methods rarely touch the cases where the prohibited items are deliberately hidden in messy objects because of the scarcity of large-scale datasets, hindering their applications. To address this issue and facilitate related research, we present a large-scale dataset, named PIDray, which covers various cases in real-world scenarios for prohibited item detection, especially for deliberately hidden items. In specific, PIDray collects 124,486 X-ray images for $12$ categories of prohibited items, and each image is manually annotated with careful inspection, which makes it, to our best knowledge, to largest prohibited items detection dataset to date. Meanwhile, we propose a general divide-and-conquer pipeline to develop baseline algorithms on PIDray. Specifically, we adopt the tree-like structure to suppress the influence of the long-tailed issue in the PIDray dataset, where the first course-grained node is tasked with the binary classification to alleviate the influence of head category, while the subsequent fine-grained node is dedicated to the specific tasks of the tail categories. Based on this simple yet effective scheme, we offer strong task-specific baselines across object detection, instance segmentation, and multi-label classification tasks and verify the generalization ability on common datasets (e.g., COCO and PASCAL VOC). Extensive experiments on PIDray demonstrate that the proposed method performs favorably against current state-of-the-art methods, especially for deliberately hidden items. Our benchmark and codes will be released at https://github.com/lutao2021/PIDray.
Towards Real-World Prohibited Item Detection: A Large-Scale X-ray Benchmark
Aug 16, 2021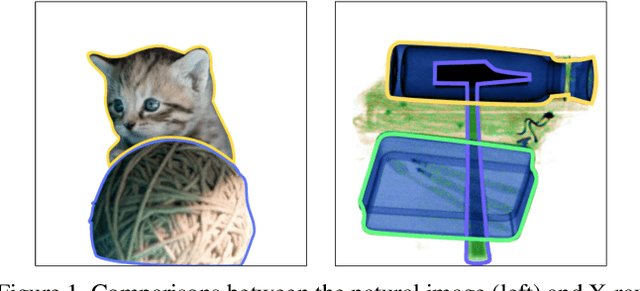

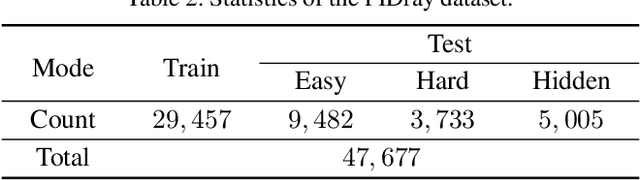
Automatic security inspection using computer vision technology is a challenging task in real-world scenarios due to various factors, including intra-class variance, class imbalance, and occlusion. Most of the previous methods rarely solve the cases that the prohibited items are deliberately hidden in messy objects due to the lack of large-scale datasets, restricted their applications in real-world scenarios. Towards real-world prohibited item detection, we collect a large-scale dataset, named as PIDray, which covers various cases in real-world scenarios for prohibited item detection, especially for deliberately hidden items. With an intensive amount of effort, our dataset contains $12$ categories of prohibited items in $47,677$ X-ray images with high-quality annotated segmentation masks and bounding boxes. To the best of our knowledge, it is the largest prohibited items detection dataset to date. Meanwhile, we design the selective dense attention network (SDANet) to construct a strong baseline, which consists of the dense attention module and the dependency refinement module. The dense attention module formed by the spatial and channel-wise dense attentions, is designed to learn the discriminative features to boost the performance. The dependency refinement module is used to exploit the dependencies of multi-scale features. Extensive experiments conducted on the collected PIDray dataset demonstrate that the proposed method performs favorably against the state-of-the-art methods, especially for detecting the deliberately hidden items.