 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOxford Iiit Pets
Papers and Code
When Generative Augmentation Hurts: A Benchmark Study of GAN and Diffusion Models for Bias Correction in AI Classification Systems
Mar 17, 2026Generative models are widely used to compensate for class imbalance in AI training pipelines, yet their failure modes under low-data conditions are poorly understood. This paper reports a controlled benchmark comparing three augmentation strategies applied to a fine-grained animal classification task: traditional transforms, FastGAN, and Stable Diffusion 1.5 fine-tuned with Low-Rank Adaptation (LoRA). Using the Oxford-IIIT Pet Dataset with eight artificially underrepresented breeds, we find that FastGAN augmentation does not merely underperform at very low training set sizes but actively increases classifier bias, with a statistically significant large effect across three random seeds (bias gap increase: +20.7%, Cohen's d = +5.03, p = 0.013). The effect size here is large enough to give confidence in the direction of the finding despite the small number of seeds. Feature embedding analysis using t-distributed Stochastic Neighbor Embedding reveals that FastGAN images for severe-minority breeds form tight isolated clusters outside the real image distribution, a pattern consistent with mode collapse. Stable Diffusion with Low-Rank Adaptation produced the best results overall, achieving the highest macro F1 (0.9125 plus or minus 0.0047) and a 13.1% reduction in the bias gap relative to the unaugmented baseline. The data suggest a sample-size boundary somewhere between 20 and 50 training images per class below which GAN augmentation becomes harmful in this setting, though further work across additional domains is needed to establish where that boundary sits more precisely. All experiments run on a consumer-grade GPU with 6 to 8 GB of memory, with no cloud compute required.
BiGain: Unified Token Compression for Joint Generation and Classification
Mar 12, 2026Acceleration methods for diffusion models (e.g., token merging or downsampling) typically optimize synthesis quality under reduced compute, yet often ignore discriminative capacity. We revisit token compression with a joint objective and present BiGain, a training-free, plug-and-play framework that preserves generation quality while improving classification in accelerated diffusion models. Our key insight is frequency separation: mapping feature-space signals into a frequency-aware representation disentangles fine detail from global semantics, enabling compression that respects both generative fidelity and discriminative utility. BiGain reflects this principle with two frequency-aware operators: (1) Laplacian-gated token merging, which encourages merges among spectrally smooth tokens while discouraging merges of high-contrast tokens, thereby retaining edges and textures; and (2) Interpolate-Extrapolate KV Downsampling, which downsamples keys/values via a controllable interextrapolation between nearest and average pooling while keeping queries intact, thereby conserving attention precision. Across DiT- and U-Net-based backbones and ImageNet-1K, ImageNet-100, Oxford-IIIT Pets, and COCO-2017, our operators consistently improve the speed-accuracy trade-off for diffusion-based classification, while maintaining or enhancing generation quality under comparable acceleration. For instance, on ImageNet-1K, with 70% token merging on Stable Diffusion 2.0, BiGain increases classification accuracy by 7.15% while improving FID by 0.34 (1.85%). Our analyses indicate that balanced spectral retention, preserving high-frequency detail and low/mid-frequency semantics, is a reliable design rule for token compression in diffusion models. To our knowledge, BiGain is the first framework to jointly study and advance both generation and classification under accelerated diffusion, supporting lower-cost deployment.
Fine-Grained Cat Breed Recognition with Global Context Vision Transformer
Feb 07, 2026Accurate identification of cat breeds from images is a challenging task due to subtle differences in fur patterns, facial structure, and color. In this paper, we present a deep learning-based approach for classifying cat breeds using a subset of the Oxford-IIIT Pet Dataset, which contains high-resolution images of various domestic breeds. We employed the Global Context Vision Transformer (GCViT) architecture-tiny for cat breed recognition. To improve model generalization, we used extensive data augmentation, including rotation, horizontal flipping, and brightness adjustment. Experimental results show that the GCViT-Tiny model achieved a test accuracy of 92.00% and validation accuracy of 94.54%. These findings highlight the effectiveness of transformer-based architectures for fine-grained image classification tasks. Potential applications include veterinary diagnostics, animal shelter management, and mobile-based breed recognition systems. We also provide a hugging face demo at https://huggingface.co/spaces/bfarhad/cat-breed-classifier.
Foundation Model Insights and a Multi-Model Approach for Superior Fine-Grained One-shot Subset Selection
Jun 17, 2025



One-shot subset selection serves as an effective tool to reduce deep learning training costs by identifying an informative data subset based on the information extracted by an information extractor (IE). Traditional IEs, typically pre-trained on the target dataset, are inherently dataset-dependent. Foundation models (FMs) offer a promising alternative, potentially mitigating this limitation. This work investigates two key questions: (1) Can FM-based subset selection outperform traditional IE-based methods across diverse datasets? (2) Do all FMs perform equally well as IEs for subset selection? Extensive experiments uncovered surprising insights: FMs consistently outperform traditional IEs on fine-grained datasets, whereas their advantage diminishes on coarse-grained datasets with noisy labels. Motivated by these finding, we propose RAM-APL (RAnking Mean-Accuracy of Pseudo-class Labels), a method tailored for fine-grained image datasets. RAM-APL leverages multiple FMs to enhance subset selection by exploiting their complementary strengths. Our approach achieves state-of-the-art performance on fine-grained datasets, including Oxford-IIIT Pet, Food-101, and Caltech-UCSD Birds-200-2011.
Escaping The Big Data Paradigm in Self-Supervised Representation Learning
Feb 25, 2025



The reliance on large-scale datasets and extensive computational resources has become a major barrier to advancing representation learning in vision, especially in data-scarce domains. In this paper, we address the critical question: Can we escape the big data paradigm in self-supervised representation learning from images? We introduce SCOTT (Sparse Convolutional Tokenizer for Transformers), a shallow tokenization architecture that is compatible with Masked Image Modeling (MIM) tasks. SCOTT injects convolutional inductive biases into Vision Transformers (ViTs), enhancing their efficacy in small-scale data regimes. Alongside, we propose to train on a Joint-Embedding Predictive Architecture within a MIM framework (MIM-JEPA), operating in latent representation space to capture more semantic features. Our approach enables ViTs to be trained from scratch on datasets orders of magnitude smaller than traditionally required --without relying on massive external datasets for pretraining. We validate our method on three small-size, standard-resoultion, fine-grained datasets: Oxford Flowers-102, Oxford IIIT Pets-37, and ImageNet-100. Despite the challenges of limited data and high intra-class similarity, frozen SCOTT models pretrained with MIM-JEPA significantly outperform fully supervised methods and achieve competitive results with SOTA approaches that rely on large-scale pretraining, complex image augmentations and bigger model sizes. By demonstrating that robust off-the-shelf representations can be learned with limited data, compute, and model sizes, our work paves the way for computer applications in resource constrained environments such as medical imaging or robotics. Our findings challenge the prevailing notion that vast amounts of data are indispensable for effective representation learning in vision, offering a new pathway toward more accessible and inclusive advancements in the field.
ReViT: Enhancing Vision Transformers with Attention Residual Connections for Visual Recognition
Feb 17, 2024



Vision Transformer (ViT) self-attention mechanism is characterized by feature collapse in deeper layers, resulting in the vanishing of low-level visual features. However, such features can be helpful to accurately represent and identify elements within an image and increase the accuracy and robustness of vision-based recognition systems. Following this rationale, we propose a novel residual attention learning method for improving ViT-based architectures, increasing their visual feature diversity and model robustness. In this way, the proposed network can capture and preserve significant low-level features, providing more details about the elements within the scene being analyzed. The effectiveness and robustness of the presented method are evaluated on five image classification benchmarks, including ImageNet1k, CIFAR10, CIFAR100, Oxford Flowers-102, and Oxford-IIIT Pet, achieving improved performances. Additionally, experiments on the COCO2017 dataset show that the devised approach discovers and incorporates semantic and spatial relationships for object detection and instance segmentation when implemented into spatial-aware transformer models.
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable Image Classification
Nov 30, 2023



Prototypical-part interpretable methods, e.g., ProtoPNet, enhance interpretability by connecting classification predictions to class-specific training prototypes, thereby offering an intuitive insight into their decision-making. Current methods rely on a discriminative classifier trained with point-based learning techniques that provide specific values for prototypes. Such prototypes have relatively low representation power due to their sparsity and potential redundancy, with each prototype containing no variability measure. In this paper, we present a new generative learning of prototype distributions, named Mixture of Gaussian-distributed Prototypes (MGProto), which are represented by Gaussian mixture models (GMM). Such an approach enables the learning of more powerful prototype representations since each learned prototype will own a measure of variability, which naturally reduces the sparsity given the spread of the distribution around each prototype, and we also integrate a prototype diversity objective function into the GMM optimisation to reduce redundancy. Incidentally, the generative nature of MGProto offers a new and effective way for detecting out-of-distribution samples. To improve the compactness of MGProto, we further propose to prune Gaussian-distributed prototypes with a low prior. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art classification and OoD detection performances with encouraging interpretability results.
Directly Optimizing IoU for Bounding Box Localization
Apr 14, 2023Object detection has seen remarkable progress in recent years with the introduction of Convolutional Neural Networks (CNN). Object detection is a multi-task learning problem where both the position of the objects in the images as well as their classes needs to be correctly identified. The idea here is to maximize the overlap between the ground-truth bounding boxes and the predictions i.e. the Intersection over Union (IoU). In the scope of work seen currently in this domain, IoU is approximated by using the Huber loss as a proxy but this indirect method does not leverage the IoU information and treats the bounding box as four independent, unrelated terms of regression. This is not true for a bounding box where the four coordinates are highly correlated and hold a semantic meaning when taken together. The direct optimization of the IoU is not possible due to its non-convex and non-differentiable nature. In this paper, we have formulated a novel loss namely, the Smooth IoU, which directly optimizes the IoUs for the bounding boxes. This loss has been evaluated on the Oxford IIIT Pets, Udacity self-driving car, PASCAL VOC, and VWFS Car Damage datasets and has shown performance gains over the standard Huber loss.
Scale Equivariant U-Net
Oct 10, 2022

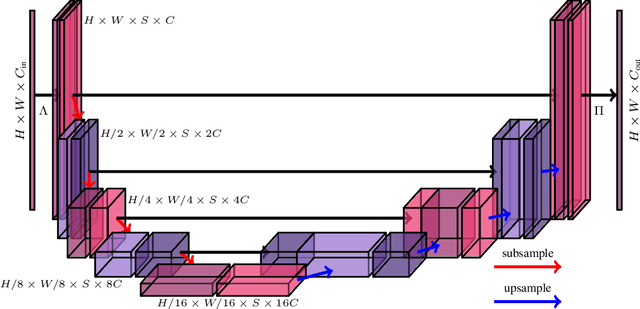
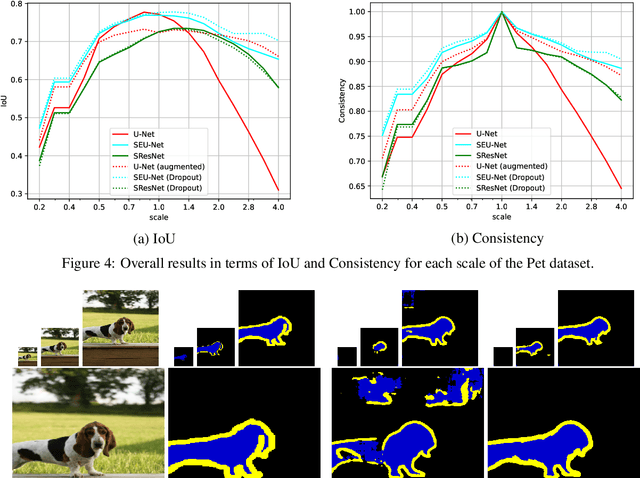
In neural networks, the property of being equivariant to transformations improves generalization when the corresponding symmetry is present in the data. In particular, scale-equivariant networks are suited to computer vision tasks where the same classes of objects appear at different scales, like in most semantic segmentation tasks. Recently, convolutional layers equivariant to a semigroup of scalings and translations have been proposed. However, the equivariance of subsampling and upsampling has never been explicitly studied even though they are necessary building blocks in some segmentation architectures. The U-Net is a representative example of such architectures, which includes the basic elements used for state-of-the-art semantic segmentation. Therefore, this paper introduces the Scale Equivariant U-Net (SEU-Net), a U-Net that is made approximately equivariant to a semigroup of scales and translations through careful application of subsampling and upsampling layers and the use of aforementioned scale-equivariant layers. Moreover, a scale-dropout is proposed in order to improve generalization to different scales in approximately scale-equivariant architectures. The proposed SEU-Net is trained for semantic segmentation of the Oxford Pet IIIT and the DIC-C2DH-HeLa dataset for cell segmentation. The generalization metric to unseen scales is dramatically improved in comparison to the U-Net, even when the U-Net is trained with scale jittering, and to a scale-equivariant architecture that does not perform upsampling operators inside the equivariant pipeline. The scale-dropout induces better generalization on the scale-equivariant models in the Pet experiment, but not on the cell segmentation experiment.
Towards Fine-grained Image Classification with Generative Adversarial Networks and Facial Landmark Detection
Aug 28, 2021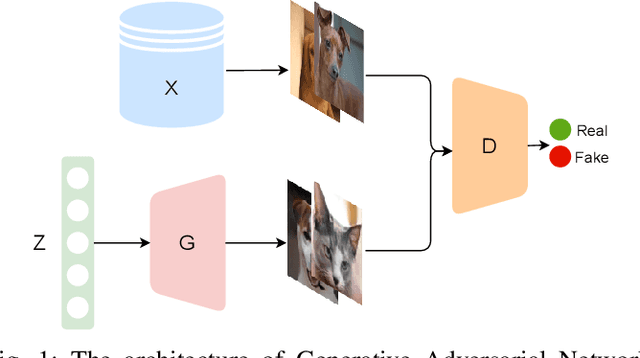
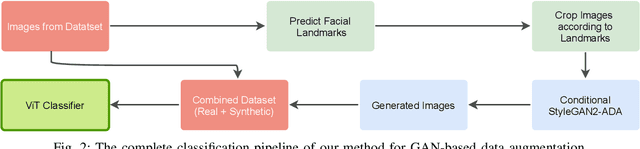


Fine-grained classification remains a challenging task because distinguishing categories needs learning complex and local differences. Diversity in the pose, scale, and position of objects in an image makes the problem even more difficult. Although the recent Vision Transformer models achieve high performance, they need an extensive volume of input data. To encounter this problem, we made the best use of GAN-based data augmentation to generate extra dataset instances. Oxford-IIIT Pets was our dataset of choice for this experiment. It consists of 37 breeds of cats and dogs with variations in scale, poses, and lighting, which intensifies the difficulty of the classification task. Furthermore, we enhanced the performance of the recent Generative Adversarial Network (GAN), StyleGAN2-ADA model to generate more realistic images while preventing overfitting to the training set. We did this by training a customized version of MobileNetV2 to predict animal facial landmarks; then, we cropped images accordingly. Lastly, we combined the synthetic images with the original dataset and compared our proposed method with standard GANs augmentation and no augmentation with different subsets of training data. We validated our work by evaluating the accuracy of fine-grained image classification on the recent Vision Transformer (ViT) Model.