 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNtu RGB D 120 Motion Similarity
Papers and Code
Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition
Nov 28, 2024In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal representations. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the discriminative representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The code is available at https://github.com/firework8/ProtoGCN.
Frequency Guidance Matters: Skeletal Action Recognition by Frequency-Aware Mixed Transformer
Jul 17, 2024Recently, transformers have demonstrated great potential for modeling long-term dependencies from skeleton sequences and thereby gained ever-increasing attention in skeleton action recognition. However, the existing transformer-based approaches heavily rely on the naive attention mechanism for capturing the spatiotemporal features, which falls short in learning discriminative representations that exhibit similar motion patterns. To address this challenge, we introduce the Frequency-aware Mixed Transformer (FreqMixFormer), specifically designed for recognizing similar skeletal actions with subtle discriminative motions. First, we introduce a frequency-aware attention module to unweave skeleton frequency representations by embedding joint features into frequency attention maps, aiming to distinguish the discriminative movements based on their frequency coefficients. Subsequently, we develop a mixed transformer architecture to incorporate spatial features with frequency features to model the comprehensive frequency-spatial patterns. Additionally, a temporal transformer is proposed to extract the global correlations across frames. Extensive experiments show that FreqMiXFormer outperforms SOTA on 3 popular skeleton action recognition datasets, including NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Spatial Temporal Graph Attention Network for Skeleton-Based Action Recognition
Aug 18, 2022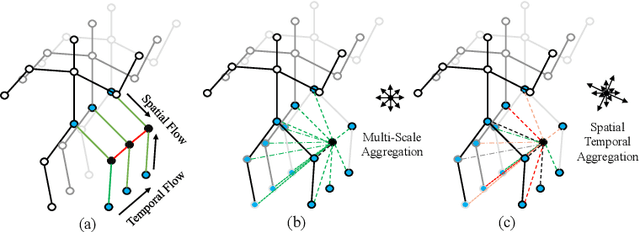
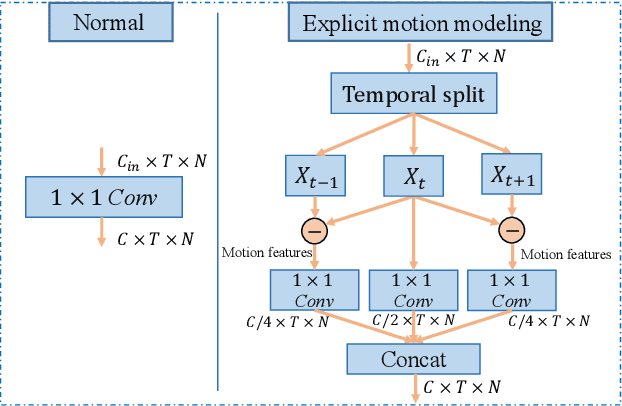
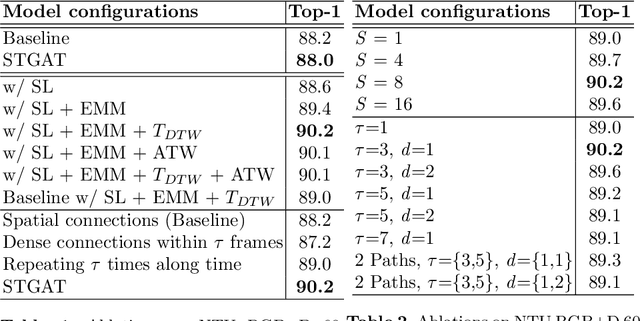
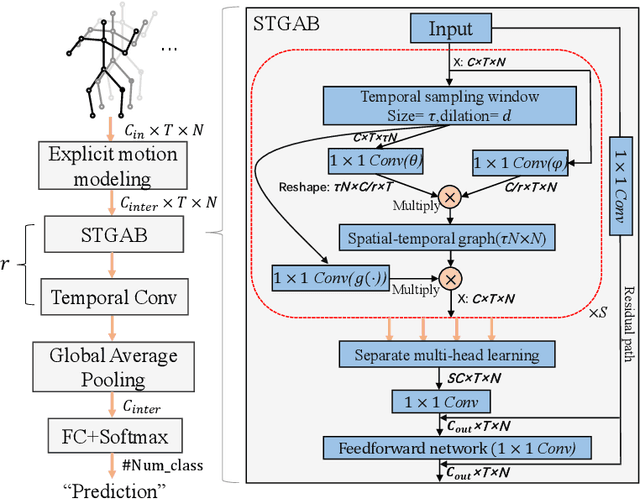
It's common for current methods in skeleton-based action recognition to mainly consider capturing long-term temporal dependencies as skeleton sequences are typically long (>128 frames), which forms a challenging problem for previous approaches. In such conditions, short-term dependencies are few formally considered, which are critical for classifying similar actions. Most current approaches are consisted of interleaving spatial-only modules and temporal-only modules, where direct information flow among joints in adjacent frames are hindered, thus inferior to capture short-term motion and distinguish similar action pairs. To handle this limitation, we propose a general framework, coined as STGAT, to model cross-spacetime information flow. It equips the spatial-only modules with spatial-temporal modeling for regional perception. While STGAT is theoretically effective for spatial-temporal modeling, we propose three simple modules to reduce local spatial-temporal feature redundancy and further release the potential of STGAT, which (1) narrow the scope of self-attention mechanism, (2) dynamically weight joints along temporal dimension, and (3) separate subtle motion from static features, respectively. As a robust feature extractor, STGAT generalizes better upon classifying similar actions than previous methods, witnessed by both qualitative and quantitative results. STGAT achieves state-of-the-art performance on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400. Code is released.
Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Apr 28, 2020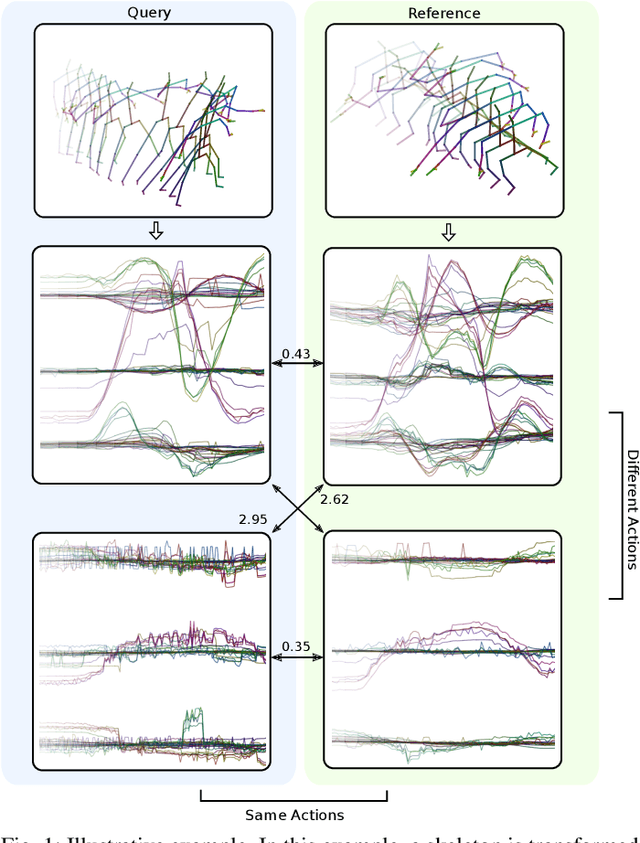
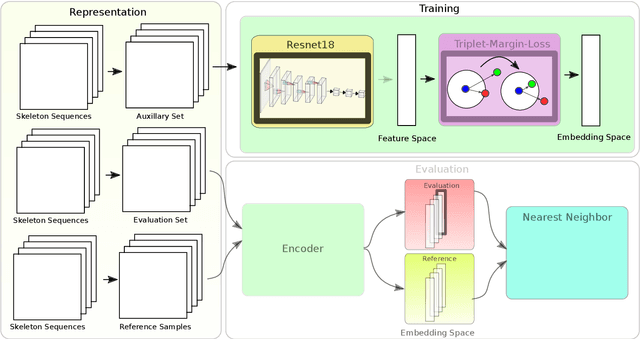
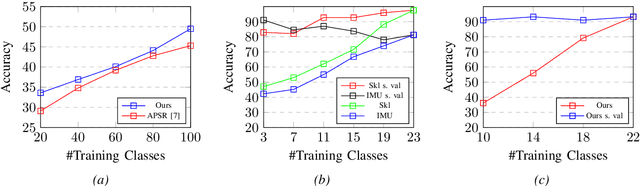
Recognizing an activity with a single reference sample using metric learning approaches is a promising research field. The majority of few-shot methods focus on object recognition or face-identification. We follow a metric learning approach to reduce the action recognition problem to a nearest neighbor search in embedding space. We encode signals on a signal level into images and then extract features using a deep residual CNN. Using triplet loss, we learn a feature embedding. The resulting encoder transforms features into an embedding space in which closer distances encode similar actions while higher distances encode different actions. Our approach based on a signal-level formulation remains flexible across a variety of modalities while outperforming the baseline on the large scale NTU RGB+D 120 dataset for the One-Shot action recognition protocol by 4.2%. Further, we show generalization on experiments using the UTD-MHAD dataset for inertial data and the Simitate dataset for motion capturing data. Furthermore, our inter-joint and inter-sensor experiments suggest good capabilities on previously unseen joint and sensor setups.