 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyft Level 5 Prediction
Papers and Code
Semantic Map Learning of Traffic Light to Lane Assignment based on Motion Data
Sep 28, 2023Understanding which traffic light controls which lane is crucial to navigate intersections safely. Autonomous vehicles commonly rely on High Definition (HD) maps that contain information about the assignment of traffic lights to lanes. The manual provisioning of this information is tedious, expensive, and not scalable. To remedy these issues, our novel approach derives the assignments from traffic light states and the corresponding motion patterns of vehicle traffic. This works in an automated way and independently of the geometric arrangement. We show the effectiveness of basic statistical approaches for this task by implementing and evaluating a pattern-based contribution method. In addition, our novel rejection method includes accompanying safety considerations by leveraging statistical hypothesis testing. Finally, we propose a dataset transformation to re-purpose available motion prediction datasets for semantic map learning. Our publicly available API for the Lyft Level 5 dataset enables researchers to develop and evaluate their own approaches.
BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning
Oct 16, 2023



Prediction, decision-making, and motion planning are essential for autonomous driving. In most contemporary works, they are considered as individual modules or combined into a multi-task learning paradigm with a shared backbone but separate task heads. However, we argue that they should be integrated into a comprehensive framework. Although several recent approaches follow this scheme, they suffer from complicated input representations and redundant framework designs. More importantly, they can not make long-term predictions about future driving scenarios. To address these issues, we rethink the necessity of each module in an autonomous driving task and incorporate only the required modules into a minimalist autonomous driving framework. We propose BEVGPT, a generative pre-trained large model that integrates driving scenario prediction, decision-making, and motion planning. The model takes the bird's-eye-view (BEV) images as the only input source and makes driving decisions based on surrounding traffic scenarios. To ensure driving trajectory feasibility and smoothness, we develop an optimization-based motion planning method. We instantiate BEVGPT on Lyft Level 5 Dataset and use Woven Planet L5Kit for realistic driving simulation. The effectiveness and robustness of the proposed framework are verified by the fact that it outperforms previous methods in 100% decision-making metrics and 66% motion planning metrics. Furthermore, the ability of our framework to accurately generate BEV images over the long term is demonstrated through the task of driving scenario prediction. To the best of our knowledge, this is the first generative pre-trained large model for autonomous driving prediction, decision-making, and motion planning with only BEV images as input.
Context-Aware Timewise VAEs for Real-Time Vehicle Trajectory Prediction
Feb 21, 2023



Real-time, accurate prediction of human steering behaviors has wide applications, from developing intelligent traffic systems to deploying autonomous driving systems in both real and simulated worlds. In this paper, we present ContextVAE, a context-aware approach for multi-modal vehicle trajectory prediction. Built upon the backbone architecture of a timewise variational autoencoder, ContextVAE employs a dual attention mechanism for observation encoding that accounts for the environmental context information and the dynamic agents' states in a unified way. By utilizing features extracted from semantic maps during agent state encoding, our approach takes into account both the social features exhibited by agents on the scene and the physical environment constraints to generate map-compliant and socially-aware trajectories. We perform extensive testing on the nuScenes prediction challenge, Lyft Level 5 dataset and Waymo Open Motion Dataset to show the effectiveness of our approach and its state-of-the-art performance. In all tested datasets, ContextVAE models are fast to train and provide high-quality multi-modal predictions in real-time.
Stochastic MPC with Multi-modal Predictions for Traffic Intersections
Sep 26, 2021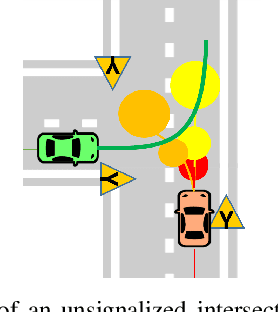
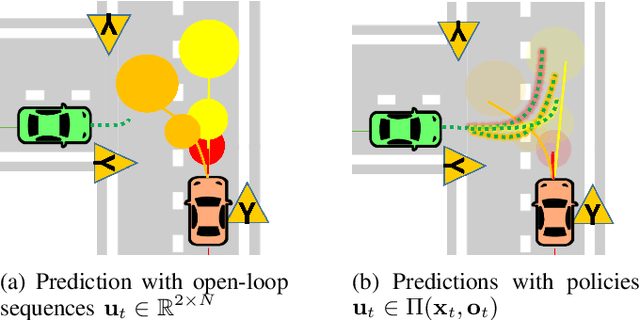
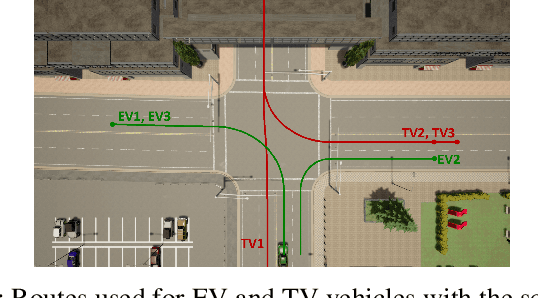
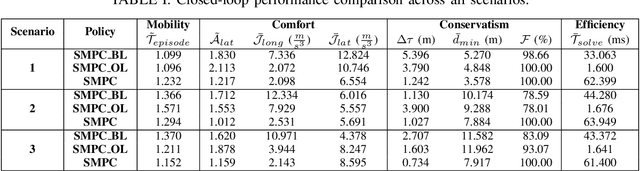
We propose a Stochastic MPC (SMPC) formulation for autonomous driving at traffic intersections which incorporates multi-modal predictions of surrounding vehicles for collision avoidance constraints. The multi-modal predictions are obtained with Gaussian Mixture Models (GMM) and constraints are formulated as chance-constraints. Our main theoretical contribution is a SMPC formulation that optimizes over a novel feedback policy class designed to exploit additional structure in the GMM predictions, and that is amenable to convex programming. The use of feedback policies for prediction is motivated by the need for reduced conservatism in handling multi-modal predictions of the surrounding vehicles, especially prevalent in traffic intersection scenarios. We evaluate our algorithm along axes of mobility, comfort, conservatism and computational efficiency at a simulated intersection in CARLA. Our simulations use a kinematic bicycle model and multimodal predictions trained on a subset of the Lyft Level 5 prediction dataset. To demonstrate the impact of optimizing over feedback policies, we compare our algorithm with two SMPC baselines that handle multi-modal collision avoidance chance constraints by optimizing over open-loop sequences.