 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Resource Named Entity Recognition
Papers and Code
LGSE: Lexically Grounded Subword Embedding Initialization for Low-Resource Language Adaptation
Mar 23, 2026Adapting pretrained language models to low-resource, morphologically rich languages remains a significant challenge. Existing vocabulary expansion methods typically rely on arbitrarily segmented subword units, resulting in fragmented lexical representations and loss of critical morphological information. To address this limitation, we propose the Lexically Grounded Subword Embedding Initialization (LGSE) framework, which introduces morphologically informed segmentation for initializing embeddings of novel tokens. Instead of using random vectors or arbitrary subwords, LGSE decomposes words into their constituent morphemes and constructs semantically coherent embeddings by averaging pretrained subword or FastText-based morpheme representations. When a token cannot be segmented into meaningful morphemes, its embedding is constructed using character n-gram representations to capture structural information. During Language-Adaptive Pretraining, we apply a regularization term that penalizes large deviations of newly introduced embeddings from their initialized values, preserving alignment with the original pretrained embedding space while enabling adaptation to the target language. To isolate the effect of initialization, we retain the original pre-trained model vocabulary and tokenizer and update only the new embeddings during adaptation. We evaluate LGSE on three NLP tasks: Question Answering, Named Entity Recognition, and Text Classification, in two morphologically rich, low-resource languages: Amharic and Tigrinya, where morphological segmentation resources are available. Experimental results show that LGSE consistently outperforms baseline methods across all tasks, demonstrating the effectiveness of morphologically grounded embedding initialization for improving representation quality in underrepresented languages. Project resources are available in the GitHub link.
AWED-FiNER: Agents, Web applications, and Expert Detectors for Fine-grained Named Entity Recognition across 36 Languages for 6.6 Billion Speakers
Jan 15, 2026We introduce AWED-FiNER, an open-source ecosystem designed to bridge the gap in Fine-grained Named Entity Recognition (FgNER) for 36 global languages spoken by more than 6.6 billion people. While Large Language Models (LLMs) dominate general Natural Language Processing (NLP) tasks, they often struggle with low-resource languages and fine-grained NLP tasks. AWED-FiNER provides a collection of agentic toolkits, web applications, and several state-of-the-art expert models that provides FgNER solutions across 36 languages. The agentic tools enable to route multilingual text to specialized expert models and fetch FgNER annotations within seconds. The web-based platforms provide ready-to-use FgNER annotation service for non-technical users. Moreover, the collection of language specific extremely small sized open-source state-of-the-art expert models facilitate offline deployment in resource contraint scenerios including edge devices. AWED-FiNER covers languages spoken by over 6.6 billion people, including a specific focus on vulnerable languages such as Bodo, Manipuri, Bishnupriya, and Mizo. The resources can be accessed here: Agentic Tool (https://github.com/PrachuryyaKaushik/AWED-FiNER), Web Application (https://hf.co/spaces/prachuryyaIITG/AWED-FiNER), and 49 Expert Detector Models (https://hf.co/collections/prachuryyaIITG/awed-finer).
Scalable Construction of a Lung Cancer Knowledge Base: Profiling Semantic Reasoning in LLMs
Jan 05, 2026The integration of Large Language Models (LLMs) into biomedical research offers new opportunities for domainspecific reasoning and knowledge representation. However, their performance depends heavily on the semantic quality of training data. In oncology, where precision and interpretability are vital, scalable methods for constructing structured knowledge bases are essential for effective fine-tuning. This study presents a pipeline for developing a lung cancer knowledge base using Open Information Extraction (OpenIE). The process includes: (1) identifying medical concepts with the MeSH thesaurus; (2) filtering open-access PubMed literature with permissive licenses (CC0); (3) extracting (subject, relation, object) triplets using OpenIE method; and (4) enriching triplet sets with Named Entity Recognition (NER) to ensure biomedical relevance. The resulting triplet sets provide a domain-specific, large-scale, and noise-aware resource for fine-tuning LLMs. We evaluated T5 models finetuned on this dataset through Supervised Semantic Fine-Tuning. Comparative assessments with ROUGE and BERTScore show significantly improved performance and semantic coherence, demonstrating the potential of OpenIE-derived resources as scalable, low-cost solutions for enhancing biomedical NLP.
Do LLMs Judge Distantly Supervised Named Entity Labels Well? Constructing the JudgeWEL Dataset
Jan 01, 2026We present judgeWEL, a dataset for named entity recognition (NER) in Luxembourgish, automatically labelled and subsequently verified using large language models (LLM) in a novel pipeline. Building datasets for under-represented languages remains one of the major bottlenecks in natural language processing, where the scarcity of resources and linguistic particularities make large-scale annotation costly and potentially inconsistent. To address these challenges, we propose and evaluate a novel approach that leverages Wikipedia and Wikidata as structured sources of weak supervision. By exploiting internal links within Wikipedia articles, we infer entity types based on their corresponding Wikidata entries, thereby generating initial annotations with minimal human intervention. Because such links are not uniformly reliable, we mitigate noise by employing and comparing several LLMs to identify and retain only high-quality labelled sentences. The resulting corpus is approximately five times larger than the currently available Luxembourgish NER dataset and offers broader and more balanced coverage across entity categories, providing a substantial new resource for multilingual and low-resource NER research.
NagaNLP: Bootstrapping NLP for Low-Resource Nagamese Creole with Human-in-the-Loop Synthetic Data
Dec 14, 2025The vast majority of the world's languages, particularly creoles like Nagamese, remain severely under-resourced in Natural Language Processing (NLP), creating a significant barrier to their representation in digital technology. This paper introduces NagaNLP, a comprehensive open-source toolkit for Nagamese, bootstrapped through a novel methodology that relies on LLM-driven but human-validated synthetic data generation. We detail a multi-stage pipeline where an expert-guided LLM (Gemini) generates a candidate corpus, which is then refined and annotated by native speakers. This synthetic-hybrid approach yielded a 10K pair conversational dataset and a high-quality annotated corpus for foundational tasks. To assess the effectiveness of our methodology, we trained both discriminative and generative models. Our fine-tuned XLM-RoBERTa-base model establishes a new benchmark for Nagamese, achieving a 93.81\% accuracy (0.90 F1-Macro) on Part-of-Speech tagging and a 0.75 F1-Macro on Named Entity Recognition, massively outperforming strong zero-shot baselines. Furthermore, we fine-tuned a Llama-3.2-3B Instruct model, named NagaLLaMA, which demonstrates superior performance on conversational tasks, achieving a Perplexity of 3.85, an order of magnitude improvement over its few-shot counterpart (96.76). We release the NagaNLP toolkit, including all datasets, models, and code, providing a foundational resource for a previously underserved language and a reproducible framework for reducing data scarcity in other low-resource contexts.
Local LLM Ensembles for Zero-shot Portuguese Named Entity Recognition
Dec 10, 2025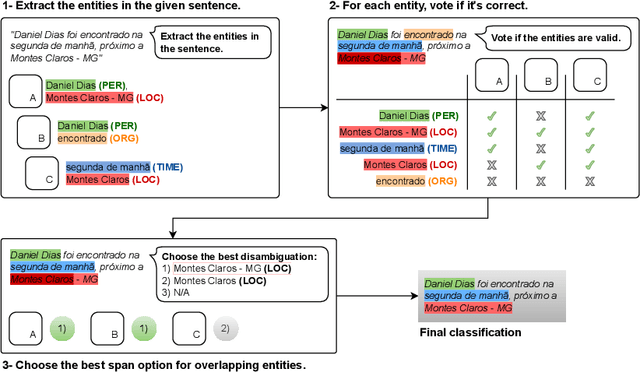
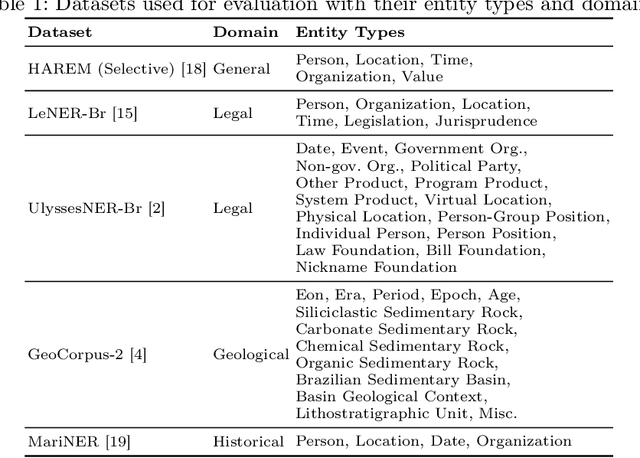
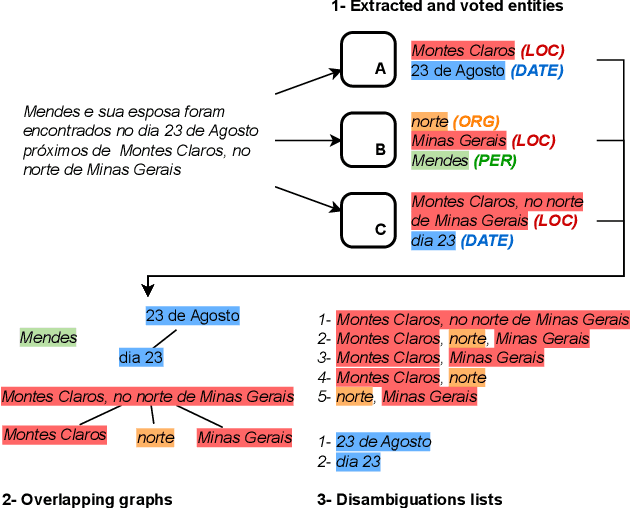
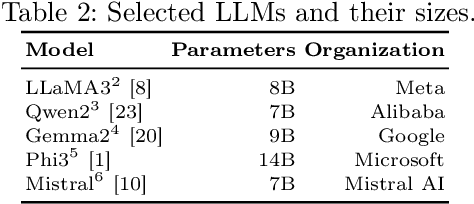
Large Language Models (LLMs) excel in many Natural Language Processing (NLP) tasks through in-context learning but often under-perform in Named Entity Recognition (NER), especially for lower-resource languages like Portuguese. While open-weight LLMs enable local deployment, no single model dominates all tasks, motivating ensemble approaches. However, existing LLM ensembles focus on text generation or classification, leaving NER under-explored. In this context, this work proposes a novel three-step ensemble pipeline for zero-shot NER using similarly capable, locally run LLMs. Our method outperforms individual LLMs in four out of five Portuguese NER datasets by leveraging a heuristic to select optimal model combinations with minimal annotated data. Moreover, we show that ensembles obtained on different source datasets generally outperform individual LLMs in cross-dataset configurations, potentially eliminating the need for annotated data for the current task. Our work advances scalable, low-resource, and zero-shot NER by effectively combining multiple small LLMs without fine-tuning. Code is available at https://github.com/Joao-Luz/local-llm-ner-ensemble.
Ground Truth Generation for Multilingual Historical NLP using LLMs
Nov 18, 2025



Historical and low-resource NLP remains challenging due to limited annotated data and domain mismatches with modern, web-sourced corpora. This paper outlines our work in using large language models (LLMs) to create ground-truth annotations for historical French (16th-20th centuries) and Chinese (1900-1950) texts. By leveraging LLM-generated ground truth on a subset of our corpus, we were able to fine-tune spaCy to achieve significant gains on period-specific tests for part-of-speech (POS) annotations, lemmatization, and named entity recognition (NER). Our results underscore the importance of domain-specific models and demonstrate that even relatively limited amounts of synthetic data can improve NLP tools for under-resourced corpora in computational humanities research.
* 13 pages, 5 tables, 1 figure
Multilingual BERT language model for medical tasks: Evaluation on domain-specific adaptation and cross-linguality
Oct 31, 2025In multilingual healthcare applications, the availability of domain-specific natural language processing(NLP) tools is limited, especially for low-resource languages. Although multilingual bidirectional encoder representations from transformers (BERT) offers a promising motivation to mitigate the language gap, the medical NLP tasks in low-resource languages are still underexplored. Therefore, this study investigates how further pre-training on domain-specific corpora affects model performance on medical tasks, focusing on three languages: Dutch, Romanian and Spanish. In terms of further pre-training, we conducted four experiments to create medical domain models. Then, these models were fine-tuned on three downstream tasks: Automated patient screening in Dutch clinical notes, named entity recognition in Romanian and Spanish clinical notes. Results show that domain adaptation significantly enhanced task performance. Furthermore, further differentiation of domains, e.g. clinical and general biomedical domains, resulted in diverse performances. The clinical domain-adapted model outperformed the more general biomedical domain-adapted model. Moreover, we observed evidence of cross-lingual transferability. Moreover, we also conducted further investigations to explore potential reasons contributing to these performance differences. These findings highlight the feasibility of domain adaptation and cross-lingual ability in medical NLP. Within the low-resource language settings, these findings can provide meaningful guidance for developing multilingual medical NLP systems to mitigate the lack of training data and thereby improve the model performance.
Low-Resource Fine-Tuning for Multi-Task Structured Information Extraction with a Billion-Parameter Instruction-Tuned Model
Sep 10, 2025Deploying large language models (LLMs) for structured data extraction in domains such as financial compliance reporting, legal document analytics, and multilingual knowledge base construction is often impractical for smaller teams due to the high cost of running large architectures and the difficulty of preparing large, high-quality datasets. Most recent instruction-tuning studies focus on seven-billion-parameter or larger models, leaving limited evidence on whether much smaller models can work reliably under low-resource, multi-task conditions. This work presents ETLCH, a billion-parameter LLaMA-based model fine-tuned with low-rank adaptation on only a few hundred to one thousand samples per task for JSON extraction, knowledge graph extraction, and named entity recognition. Despite its small scale, ETLCH outperforms strong baselines across most evaluation metrics, with substantial gains observed even at the lowest data scale. These findings demonstrate that well-tuned small models can deliver stable and accurate structured outputs at a fraction of the computational cost, enabling cost-effective and reliable information extraction pipelines in resource-constrained environments.
Can maiBERT Speak for Maithili?
Sep 18, 2025Natural Language Understanding (NLU) for low-resource languages remains a major challenge in NLP due to the scarcity of high-quality data and language-specific models. Maithili, despite being spoken by millions, lacks adequate computational resources, limiting its inclusion in digital and AI-driven applications. To address this gap, we introducemaiBERT, a BERT-based language model pre-trained specifically for Maithili using the Masked Language Modeling (MLM) technique. Our model is trained on a newly constructed Maithili corpus and evaluated through a news classification task. In our experiments, maiBERT achieved an accuracy of 87.02%, outperforming existing regional models like NepBERTa and HindiBERT, with a 0.13% overall accuracy gain and 5-7% improvement across various classes. We have open-sourced maiBERT on Hugging Face enabling further fine-tuning for downstream tasks such as sentiment analysis and Named Entity Recognition (NER).