 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoemotions
Papers and Code
The Silent Vote: Improving Zero-Shot LLM Reliability by Aggregating Semantic Neighborhoods
May 10, 2026Large Language Models are increasingly used as zero-shot classifiers in complex reasoning tasks. However, standard constrained decoding suffers from a phenomenon we define as Renormalization Bias. When a model is restricted to a small set of target labels, the standard softmax operation discards the probability mass assigned to semantic synonyms in the original distribution. This loss of information, which we call the Silent Vote, results in artificial overconfidence and poor calibration. We propose Semantic Softmax, an inference-time layer that recovers this lost information by aggregating the scores of the semantic neighborhood surrounding each target label. We evaluate this approach on Qwen-3 and Phi-4-mini models using GoEmotions and Civil Comments datasets. Our results demonstrate consistent improvements across all evaluation metrics: Semantic Softmax substantially reduces Expected Calibration Error (ECE) and Brier Score, while simultaneously enhancing discriminative performance in terms of AUROC and Macro-F1. By accounting for linguistic nuances, our method provides a more calibrated and accurate alternative for zero-shot classification.
Multilingual Multi-Label Emotion Classification at Scale with Synthetic Data
Apr 14, 2026Emotion classification in multilingual settings remains constrained by the scarcity of annotated data: existing corpora are predominantly English, single-label, and cover few languages. We address this gap by constructing a large-scale synthetic training corpus of over 1M multi-label samples (50k per language) across 23 languages: Arabic, Bengali, Dutch, English, French, German, Hindi, Indonesian, Italian, Japanese, Korean, Mandarin, Polish, Portuguese, Punjabi, Russian, Spanish, Swahili, Tamil, Turkish, Ukrainian, Urdu, and Vietnamese, covering 11 emotion categories using culturally-adapted generation and programmatic quality filtering. We train and compare six multilingual transformer encoders, from DistilBERT (135M parameters) to XLM-R-Large (560M parameters), under identical conditions. On our in-domain test set, XLM-R-Large achieves 0.868 F1-micro and 0.987 AUC-micro. To validate against human-annotated data, we evaluate all models zero-shot on GoEmotions (English) and SemEval-2018 Task 1 E-c (English, Arabic, Spanish). On threshold-free ranking metrics, XLM-R-Large matches or exceeds English-only specialist models, tying on AP-micro (0.636) and LRAP (0.804) while surpassing on AUC-micro (0.810 vs. 0.787), while natively supporting all 23 languages. The best base-sized model is publicly available at https://huggingface.co/tabularisai/multilingual-emotion-classification
SentiFuse: Deep Multi-model Fusion Framework for Robust Sentiment Extraction
Feb 01, 2026Sentiment analysis models exhibit complementary strengths, yet existing approaches lack a unified framework for effective integration. We present SentiFuse, a flexible and model-agnostic framework that integrates heterogeneous sentiment models through a standardization layer and multiple fusion strategies. Our approach supports decision-level fusion, feature-level fusion, and adaptive fusion, enabling systematic combination of diverse models. We conduct experiments on three large-scale social-media datasets: Crowdflower, GoEmotions, and Sentiment140. These experiments show that SentiFuse consistently outperforms individual models and naive ensembles. Feature-level fusion achieves the strongest overall effectiveness, yielding up to 4\% absolute improvement in F1 score over the best individual model and simple averaging, while adaptive fusion enhances robustness on challenging cases such as negation, mixed emotions, and complex sentiment expressions. These results demonstrate that systematically leveraging model complementarity yields more accurate and reliable sentiment analysis across diverse datasets and text types.
Fine-Grained Emotion Detection on GoEmotions: Experimental Comparison of Classical Machine Learning, BiLSTM, and Transformer Models
Jan 26, 2026Fine-grained emotion recognition is a challenging multi-label NLP task due to label overlap and class imbalance. In this work, we benchmark three modeling families on the GoEmotions dataset: a TF-IDF-based logistic regression system trained with binary relevance, a BiLSTM with attention, and a BERT model fine-tuned for multi-label classification. Experiments follow the official train/validation/test split, and imbalance is mitigated using inverse-frequency class weights. Across several metrics, namely Micro-F1, Macro-F1, Hamming Loss, and Subset Accuracy, we observe that logistic regression attains the highest Micro-F1 of 0.51, while BERT achieves the best overall balance surpassing the official paper's reported results, reaching Macro-F1 0.49, Hamming Loss 0.036, and Subset Accuracy 0.36. This suggests that frequent emotions often rely on surface lexical cues, whereas contextual representations improve performance on rarer emotions and more ambiguous examples.
EmplifAI: a Fine-grained Dataset for Japanese Empathetic Medical Dialogues in 28 Emotion Labels
Jan 15, 2026This paper introduces EmplifAI, a Japanese empathetic dialogue dataset designed to support patients coping with chronic medical conditions. They often experience a wide range of positive and negative emotions (e.g., hope and despair) that shift across different stages of disease management. EmplifAI addresses this complexity by providing situation-based dialogues grounded in 28 fine-grained emotion categories, adapted and validated from the GoEmotions taxonomy. The dataset includes 280 medically contextualized situations and 4125 two-turn dialogues, collected through crowdsourcing and expert review. To evaluate emotional alignment in empathetic dialogues, we assessed model predictions on situation--dialogue pairs using BERTScore across multiple large language models (LLMs), achieving F1 scores of 0.83. Fine-tuning a baseline Japanese LLM (LLM-jp-3.1-13b-instruct4) with EmplifAI resulted in notable improvements in fluency, general empathy, and emotion-specific empathy. Furthermore, we compared the scores assigned by LLM-as-a-Judge and human raters on dialogues generated by multiple LLMs to validate our evaluation pipeline and discuss the insights and potential risks derived from the correlation analysis.
Measuring and Fostering Peace through Machine Learning and Artificial Intelligence
Jan 08, 2026We used machine learning and artificial intelligence: 1) to measure levels of peace in countries from news and social media and 2) to develop on-line tools that promote peace by helping users better understand their own media diet. For news media, we used neural networks to measure levels of peace from text embeddings of on-line news sources. The model, trained on one news media dataset also showed high accuracy when used to analyze a different news dataset. For social media, such as YouTube, we developed other models to measure levels of social dimensions important in peace using word level (GoEmotions) and context level (Large Language Model) methods. To promote peace, we note that 71% of people 20-40 years old daily view most of their news through short videos on social media. Content creators of these videos are biased towards creating videos with emotional activation, making you angry to engage you, to increase clicks. We developed and tested a Chrome extension, MirrorMirror, which provides real-time feedback to YouTube viewers about the peacefulness of the media they are watching. Our long term goal is for MirrorMirror to evolve into an open-source tool for content creators, journalists, researchers, platforms, and individual users to better understand the tone of their media creation and consumption and its effects on viewers. Moving beyond simple engagement metrics, we hope to encourage more respectful, nuanced, and informative communication.
EmoLoom-2B: Fast Base-Model Screening for Emotion Classification and VAD with Lexicon-Weak Supervision and KV-Off Evaluation
Jan 03, 2026We introduce EmoLoom-2B, a lightweight and reproducible pipeline that turns small language models under 2B parameters into fast screening candidates for joint emotion classification and Valence-Arousal-Dominance prediction. To ensure protocol-faithful and fair evaluation, we unify data loading, training, and inference under a single JSON input-output contract and remove avoidable variance by adopting KV-off decoding as the default setting. We incorporate two orthogonal semantic regularizers: a VAD-preserving constraint that aligns generated text with target VAD triples, and a lightweight external appraisal classifier that provides training-time guidance on goal attainment, controllability, certainty, and fairness without injecting long rationales. To improve polarity sensitivity, we introduce Valence Flip augmentation based on mirrored emotional pairs. During supervised fine-tuning, we apply A/B mixture sampling with entropy-aware temperature scheduling to balance coverage and convergence. Using Qwen-1.8B-Chat as the base model, EmoLoom-2B achieves strong performance on GoEmotions and EmpatheticDialogues, and demonstrates robust cross-corpus generalization on DailyDialog. The proposed recipe is budget-aware, auditable, and re-entrant, serving as a dependable screening pass before heavier training or multimodal fusion.
Based on Data Balancing and Model Improvement for Multi-Label Sentiment Classification Performance Enhancement
Nov 19, 2025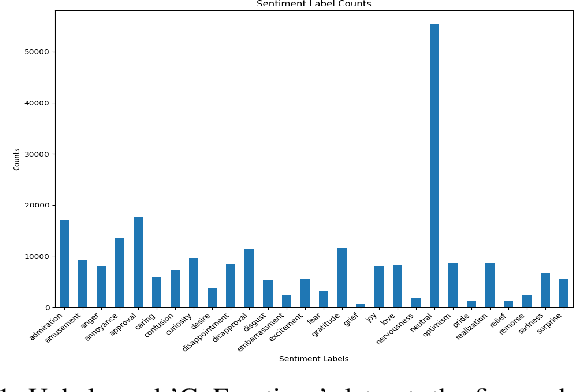
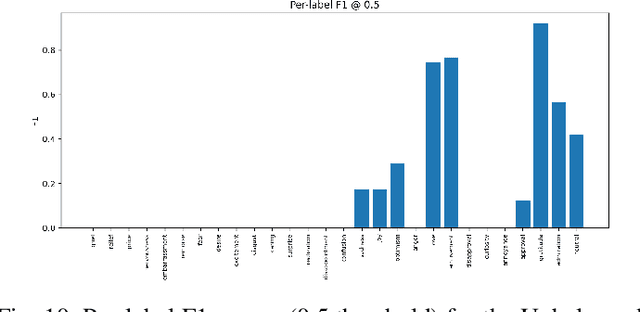
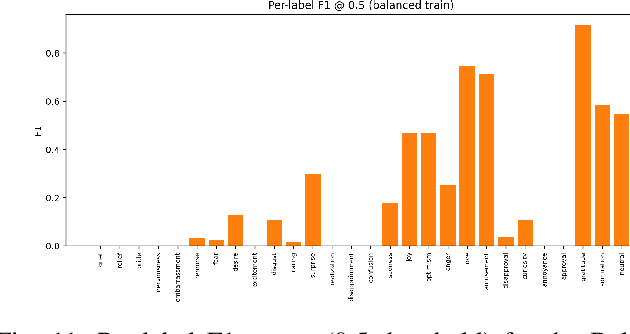
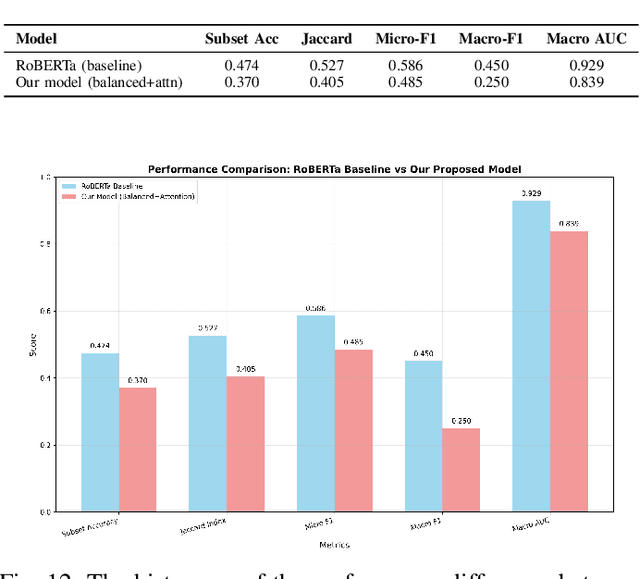
Multi-label sentiment classification plays a vital role in natural language processing by detecting multiple emotions within a single text. However, existing datasets like GoEmotions often suffer from severe class imbalance, which hampers model performance, especially for underrepresented emotions. To address this, we constructed a balanced multi-label sentiment dataset by integrating the original GoEmotions data, emotion-labeled samples from Sentiment140 using a RoBERTa-base-GoEmotions model, and manually annotated texts generated by GPT-4 mini. Our data balancing strategy ensured an even distribution across 28 emotion categories. Based on this dataset, we developed an enhanced multi-label classification model that combines pre-trained FastText embeddings, convolutional layers for local feature extraction, bidirectional LSTM for contextual learning, and an attention mechanism to highlight sentiment-relevant words. A sigmoid-activated output layer enables multi-label prediction, and mixed precision training improves computational efficiency. Experimental results demonstrate significant improvements in accuracy, precision, recall, F1-score, and AUC compared to models trained on imbalanced data, highlighting the effectiveness of our approach.
Emo Pillars: Knowledge Distillation to Support Fine-Grained Context-Aware and Context-Less Emotion Classification
Apr 23, 2025



Most datasets for sentiment analysis lack context in which an opinion was expressed, often crucial for emotion understanding, and are mainly limited by a few emotion categories. Foundation large language models (LLMs) like GPT-4 suffer from over-predicting emotions and are too resource-intensive. We design an LLM-based data synthesis pipeline and leverage a large model, Mistral-7b, for the generation of training examples for more accessible, lightweight BERT-type encoder models. We focus on enlarging the semantic diversity of examples and propose grounding the generation into a corpus of narratives to produce non-repetitive story-character-centered utterances with unique contexts over 28 emotion classes. By running 700K inferences in 450 GPU hours, we contribute with the dataset of 100K contextual and also 300K context-less examples to cover both scenarios. We use it for fine-tuning pre-trained encoders, which results in several Emo Pillars models. We show that Emo Pillars models are highly adaptive to new domains when tuned to specific tasks such as GoEmotions, ISEAR, IEMOCAP, and EmoContext, reaching the SOTA performance on the first three. We also validate our dataset, conducting statistical analysis and human evaluation, and confirm the success of our measures in utterance diversification (although less for the neutral class) and context personalization, while pointing out the need for improved handling of out-of-taxonomy labels within the pipeline.
AI with Emotions: Exploring Emotional Expressions in Large Language Models
Apr 22, 2025



The human-level performance of Large Language Models (LLMs) across various tasks has raised expectations for the potential of Artificial Intelligence (AI) to possess emotions someday. To explore the capability of current LLMs to express emotions in their outputs, we conducted an experiment using several LLMs (OpenAI GPT, Google Gemini, Meta Llama3, and Cohere Command R+) to role-play as agents answering questions with specified emotional states. We defined the emotional states using Russell's Circumplex model, a well-established framework that characterizes emotions along the sleepy-activated (arousal) and pleasure-displeasure (valence) axes. We chose this model for its simplicity, utilizing two continuous parameters, which allows for better controllability in applications involving continuous changes in emotional states. The responses generated were evaluated using a sentiment analysis model, independent of the LLMs, trained on the GoEmotions dataset. The evaluation showed that the emotional states of the generated answers were consistent with the specifications, demonstrating the LLMs' capability for emotional expression. This indicates the potential for LLM-based AI agents to simulate emotions, opening up a wide range of applications for emotion-based interactions, such as advisors or consultants who can provide advice or opinions with a personal touch.