 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDssn
Papers and Code
Hyperspectral Remote Sensing Images Salient Object Detection: The First Benchmark Dataset and Baseline
Apr 03, 2025



The objective of hyperspectral remote sensing image salient object detection (HRSI-SOD) is to identify objects or regions that exhibit distinct spectrum contrasts with the background. This area holds significant promise for practical applications; however, progress has been limited by a notable scarcity of dedicated datasets and methodologies. To bridge this gap and stimulate further research, we introduce the first HRSI-SOD dataset, termed HRSSD, which includes 704 hyperspectral images and 5327 pixel-level annotated salient objects. The HRSSD dataset poses substantial challenges for salient object detection algorithms due to large scale variation, diverse foreground-background relations, and multi-salient objects. Additionally, we propose an innovative and efficient baseline model for HRSI-SOD, termed the Deep Spectral Saliency Network (DSSN). The core of DSSN is the Cross-level Saliency Assessment Block, which performs pixel-wise attention and evaluates the contributions of multi-scale similarity maps at each spatial location, effectively reducing erroneous responses in cluttered regions and emphasizes salient regions across scales. Additionally, the High-resolution Fusion Module combines bottom-up fusion strategy and learned spatial upsampling to leverage the strengths of multi-scale saliency maps, ensuring accurate localization of small objects. Experiments on the HRSSD dataset robustly validate the superiority of DSSN, underscoring the critical need for specialized datasets and methodologies in this domain. Further evaluations on the HSOD-BIT and HS-SOD datasets demonstrate the generalizability of the proposed method. The dataset and source code are publicly available at https://github.com/laprf/HRSSD.
Improving Semi-Supervised Semantic Segmentation with Dual-Level Siamese Structure Network
Jul 26, 2023Semi-supervised semantic segmentation (SSS) is an important task that utilizes both labeled and unlabeled data to reduce expenses on labeling training examples. However, the effectiveness of SSS algorithms is limited by the difficulty of fully exploiting the potential of unlabeled data. To address this, we propose a dual-level Siamese structure network (DSSN) for pixel-wise contrastive learning. By aligning positive pairs with a pixel-wise contrastive loss using strong augmented views in both low-level image space and high-level feature space, the proposed DSSN is designed to maximize the utilization of available unlabeled data. Additionally, we introduce a novel class-aware pseudo-label selection strategy for weak-to-strong supervision, which addresses the limitations of most existing methods that do not perform selection or apply a predefined threshold for all classes. Specifically, our strategy selects the top high-confidence prediction of the weak view for each class to generate pseudo labels that supervise the strong augmented views. This strategy is capable of taking into account the class imbalance and improving the performance of long-tailed classes. Our proposed method achieves state-of-the-art results on two datasets, PASCAL VOC 2012 and Cityscapes, outperforming other SSS algorithms by a significant margin.
* ACM MM 2023 accpeted
Improved, Deterministic Smoothing for L1 Certified Robustness
Mar 17, 2021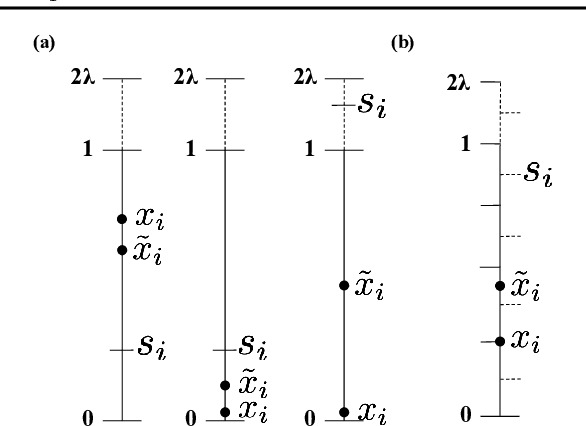
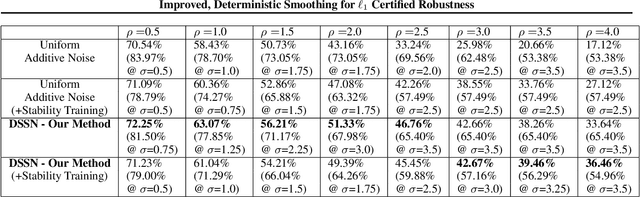
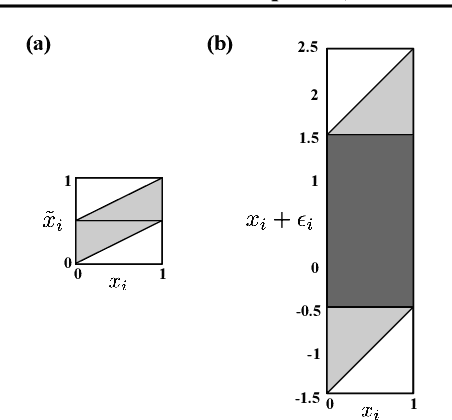
Randomized smoothing is a general technique for computing sample-dependent robustness guarantees against adversarial attacks for deep classifiers. Prior works on randomized smoothing against L_1 adversarial attacks use additive smoothing noise and provide probabilistic robustness guarantees. In this work, we propose a non-additive and deterministic smoothing method, Deterministic Smoothing with Splitting Noise (DSSN). To develop DSSN, we first develop SSN, a randomized method which involves generating each noisy smoothing sample by first randomly splitting the input space and then returning a representation of the center of the subdivision occupied by the input sample. In contrast to uniform additive smoothing, the SSN certification does not require the random noise components used to be independent. Thus, smoothing can be done effectively in just one dimension and can therefore be efficiently derandomized for quantized data (e.g., images). To the best of our knowledge, this is the first work to provide deterministic "randomized smoothing" for a norm-based adversarial threat model while allowing for an arbitrary classifier (i.e., a deep model) to be used as a base classifier and without requiring an exponential number of smoothing samples. On CIFAR-10 and ImageNet datasets, we provide substantially larger L_1 robustness certificates compared to prior works, establishing a new state-of-the-art. The determinism of our method also leads to significantly faster certificate computation.
Collaboratively boosting data-driven deep learning and knowledge-guided ontological reasoning for semantic segmentation of remote sensing imagery
Oct 06, 2020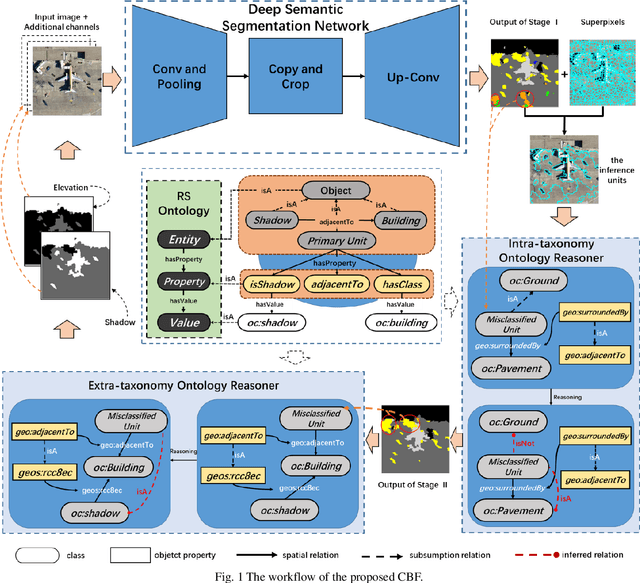

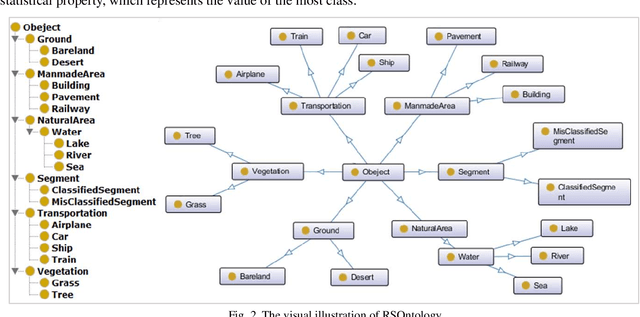
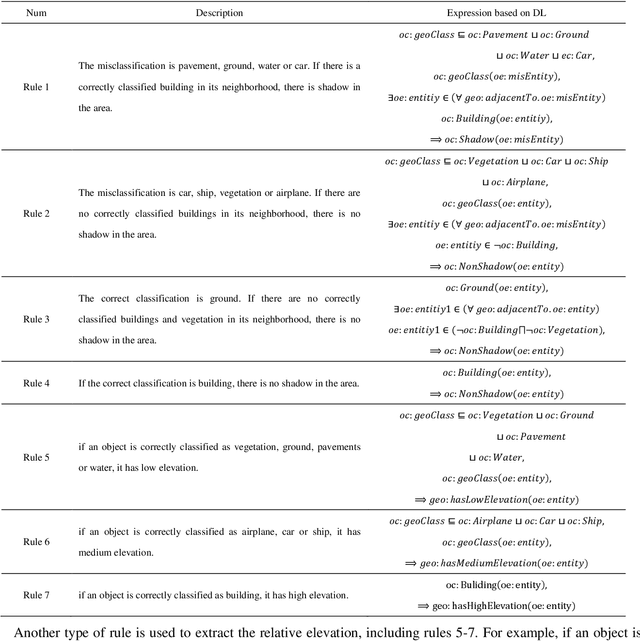
As one kind of architecture from the deep learning family, deep semantic segmentation network (DSSN) achieves a certain degree of success on the semantic segmentation task and obviously outperforms the traditional methods based on hand-crafted features. As a classic data-driven technique, DSSN can be trained by an end-to-end mechanism and competent for employing the low-level and mid-level cues (i.e., the discriminative image structure) to understand images, but lacks the high-level inference ability. By contrast, human beings have an excellent inference capacity and can be able to reliably interpret the RS imagery only when human beings master the basic RS domain knowledge. In literature, ontological modeling and reasoning is an ideal way to imitate and employ the domain knowledge of human beings, but is still rarely explored and adopted in the RS domain. To remedy the aforementioned critical limitation of DSSN, this paper proposes a collaboratively boosting framework (CBF) to combine data-driven deep learning module and knowledge-guided ontological reasoning module in an iterative way.