 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Paper and Code
Aug 21, 2022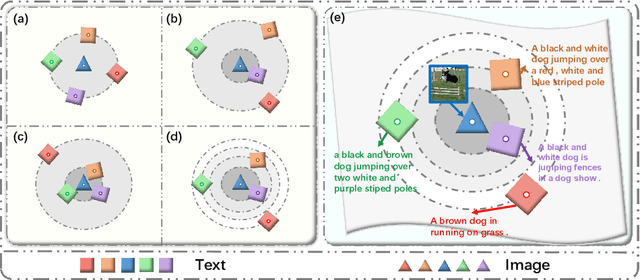
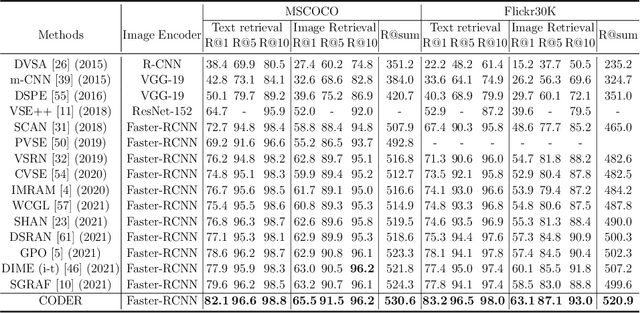
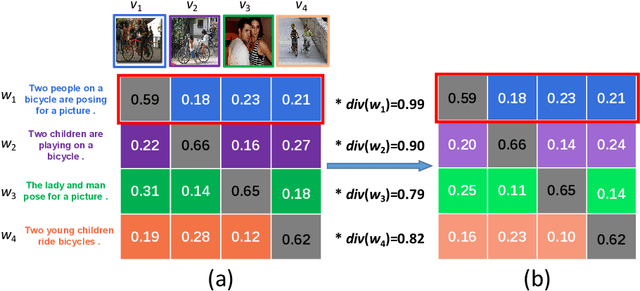
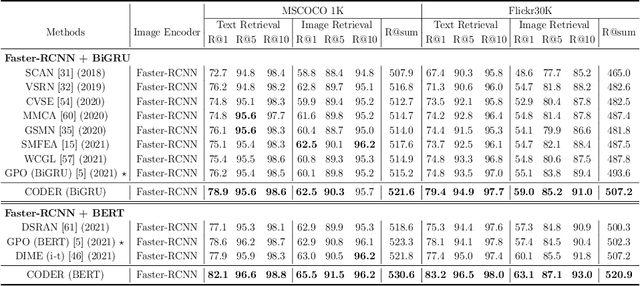
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.