 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroGen$^+$: Self-Guided High-Quality Data Generation in Efficient Zero-Shot Learning
Paper and Code
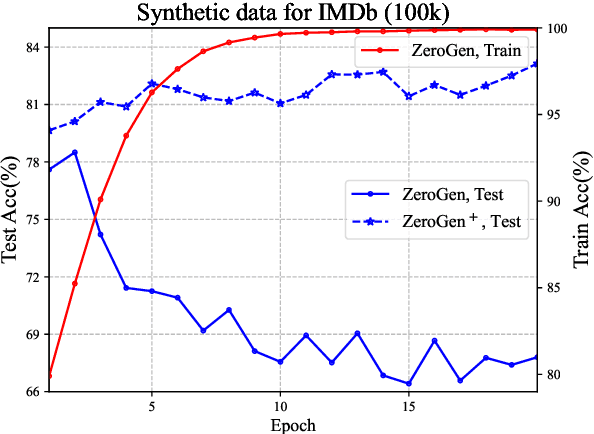
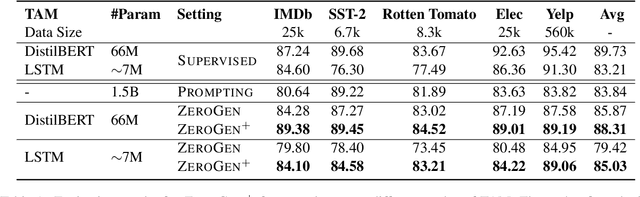
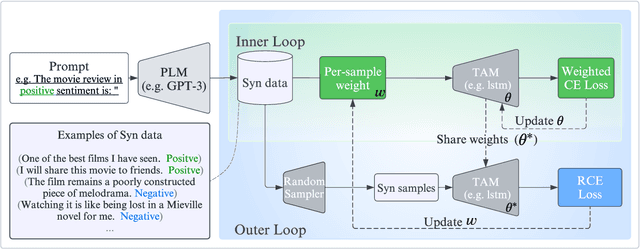
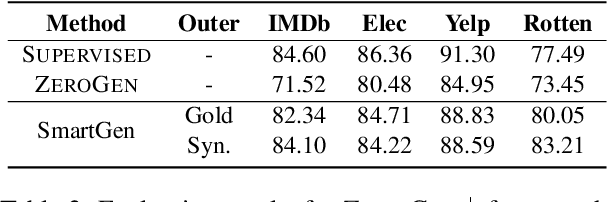
Nowadays, owing to the superior capacity of the large pre-trained language models (PLM), the PLM-based zero-shot learning has shown promising performances on various natural language processing tasks. There are emerging interests in further exploring the zero-shot learning potential of PLMs. Among them, ZeroGen attempts to purely use PLM to generate data and train a tiny model without relying on any task-specific annotation. Despite its remarkable results, we observe that the synthesized data from PLM contains a significant portion of samples with low quality, overfitting on such data greatly hampers the performance of the trained model and makes it unreliable for deployment.Since no gold data is accessible in zero-shot scenario, it is hard to perform model/data selection to prevent overfitting to the low-quality data. To address this problem, we propose a noise-robust bi-level re-weighting framework which is able to learn the per-sample weights measuring the data quality without requiring any gold data. With the learnt weights, clean subsets of different sizes can then be sampled to train the task model. We theoretically and empirically verify our method is able to construct synthetic dataset with good quality. Our method yeilds a 7.1% relative improvement than ZeroGen on average accuracy across five different established text classification tasks.