 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Model Generalization for Monocular 3D Object Detection
Paper and Code
May 28, 2022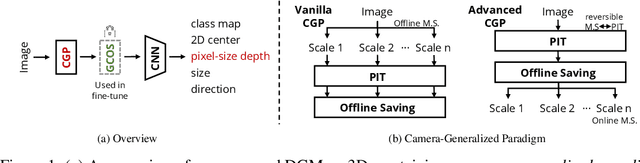

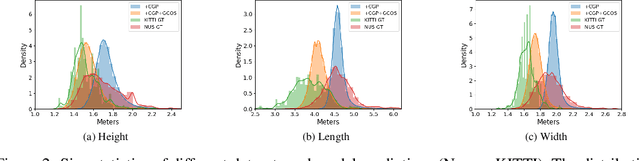
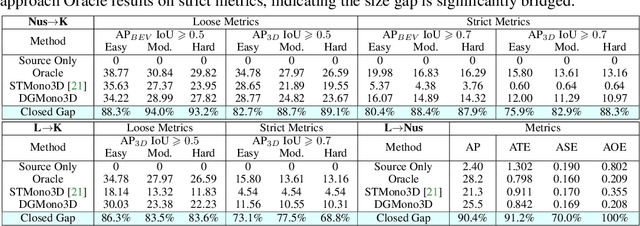
Monocular 3D object detection (Mono3D) has achieved tremendous improvements with emerging large-scale autonomous driving datasets and the rapid development of deep learning techniques. However, caused by severe domain gaps (e.g., the field of view (FOV), pixel size, and object size among datasets), Mono3D detectors have difficulty in generalization, leading to drastic performance degradation on unseen domains. To solve these issues, we combine the position-invariant transform and multi-scale training with the pixel-size depth strategy to construct an effective unified camera-generalized paradigm (CGP). It fully considers discrepancies in the FOV and pixel size of images captured by different cameras. Moreover, we further investigate the obstacle in quantitative metrics when cross-dataset inference through an exhaustive systematic study. We discern that the size bias of prediction leads to a colossal failure. Hence, we propose the 2D-3D geometry-consistent object scaling strategy (GCOS) to bridge the gap via an instance-level augment. Our method called DGMono3D achieves remarkable performance on all evaluated datasets and surpasses the SoTA unsupervised domain adaptation scheme even without utilizing data on the target domain.